
Leerpad
Wetenschapper op het gebied van machine learning in Python
85 Hr
In dit artikel verkennen we een belangrijke techniek in statistiek en machine learning: bootstrapping. Bootstrapping ontleent zijn naam aan de uitdrukking ‘jezelf aan je eigen veters omhoog trekken’, omdat de statistische techniek je in staat stelt heel veel te doen met heel weinig. Met bootstrapping kun je van een verdeling met willekeurige vorm of grootte een nieuwe verdeling van hersteekproeven maken en deze nieuwe verdeling gebruiken om de werkelijke kansverdeling te benaderen. Daarom is bootstrapping een bijzonder effectieve manier om maatstaven voor nauwkeurigheid, zoals bias, variantie, betrouwbaarheidsintervallen en predictiefout, toe te kennen aan steekproefschattingen.
Voordat we beginnen: als je geïnteresseerd bent in data science, overweeg dan deze DataCamp-cursussen over data science en statistiek, zoals onze skill track Statistical Inference in R en onze cursus Foundations of Inference in Python.
Laten we beginnen met bootstrapping op de juiste plek te positioneren tussen hersteekproefmethoden. Hoewel er verschillende soorten hersteekproefmethoden zijn, hebben ze één belangrijk ding gemeen: ze bootsen het steekproefproces na. We gebruiken een hersteekproefmethode omdat het niet praktisch is om steeds nieuwe steekproeven uit onze populatie van interesse te nemen; hersteekproeven zijn een soort snelkoppeling.
Als we bijvoorbeeld iets over onze doelpopulatie willen begrijpen, overwegen we misschien een enquête en hopen we op duizend reacties. Maar niemand gaat dezelfde enquête duizend keer in dezelfde doelgroep uitzetten. Vanwege deze praktische beperking gebruiken we een hersteekproefmethode om statistieken over onze steekproef te genereren, zoals de standaardfout.
Er zijn vier hoofdtypen hersteekproefmethoden. Het is de moeite waard om de andere hersteekproefmethoden te noemen, omdat ze een gemeenschappelijke geschiedenis delen van statistische innovatie en verbetering. In het bijzonder is bootstrapping ontwikkeld als een uitbreiding, aanpassing of verbetering van de jackknife-methode.
Het is nuttig om in het bijzonder kort over de jackknife te praten, omdat de jackknife een voorloper is van bootstrapping en bootstrapping werd geïntroduceerd als een soort uitbreiding en verbetering op de jackknife, die in de jaren 50 werd ontwikkeld toen computers ongeveer één kilobyte geheugen hadden.
De jackknife is een leave-one-out-hersteekproefmethode die een statistiek van interesse berekent; dit gebeurt successief of iteratief totdat elke observatie is verwijderd. Bij de jackknife is het aantal hersteekproeven beperkt tot het aantal observaties, en mede daardoor presteert de jackknife wat minder bij kleine steekproeven. Jackknife is ook wat beperkt qua soorten data die gebruikt kunnen worden. Daar staat tegenover dat, in tegenstelling tot de bootstrap, de jackknife elke keer reproduceerbaar is.
Bootstrapping kent een breed scala aan toepassingen in zowel statistiek als machine learning. Een van de meest voorkomende toepassingen is het schatten van betrouwbaarheidsintervallen wanneer de onderliggende verdeling onbekend is of wanneer steekproeven klein zijn. Deze mogelijkheid maakt bootstrapping bijzonder waardevol in situaties waarin traditionele parametrische methoden mogelijk niet geschikt zijn.
Daarnaast wordt bootstrapping vaak gebruikt bij hypothesetoetsing en modelvalidatie, waar het kan helpen de robuustheid van de voorspellingen van een model te evalueren. In machine learning ligt bootstrapping ten grondslag aan de populaire ensemblemethode bagging, die in modellen zoals random forests wordt gebruikt om de nauwkeurigheid te verbeteren door de variantie te verminderen.
Om bootstrapping te illustreren hebben we een programmeertaal zoals R nodig, omdat die ons in staat stelt meerdere hersteekproefdatasets te genereren; zonder programmeeromgeving zou het proces te tijdrovend en complex zijn om handmatig uit te voeren. In dit artikel bekijken we hoe we betrouwbaarheidsintervallen kunnen bootstrappen voor een verdeling en ook voor een lineaire regressie met behulp van de Fish Market-dataset op Kaggle.
Voordat we echt naar bootstrapping kijken, is het handig om eerst vertrouwd te raken met het idee van steekproeven met teruglegging. De base R-functie sample() neemt hier minimaal twee argumenten die expliciet moeten worden opgegeven in de aanroep: x en size. x bepaalt de lijst of het bereik aan waarden waaruit we een steekproef trekken en size bepaalt de grootte van onze steekproef. Er is een extra argument dat vaak expliciet wordt gespecificeerd, namelijk het argument replace. Tenzij anders bepaald, staat standaard replace = FALSE ingesteld.
Bootstrapping is steekproeven met teruglegging. Als we met teruglegging steekproeven trekken, vervangen we de waarde na elke trekking. Elke trekking is dus onafhankelijk van de vorige waarde. Als we zonder teruglegging steekproeven trekken, vervangen we waarden niet; zodra een waarde is gekozen, kan die niet opnieuw worden gekozen. We kunnen dan zeggen dat twee steekproefwaarden niet onafhankelijk zijn en dat de uitkomst van de ene trekking de mogelijkheden van de volgende beïnvloedt. Een gevolg hiervan is dat we geen steekproefgrootte kunnen kiezen die groter is dan de grootte van de invoervector, tenzij we replace = TRUE specificeren. Bootstrapping loopt hier niet tegenaan en we kunnen een gebootstrapte hersteekproefdataset genereren die veel groter is dan onze oorspronkelijke.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Laten we nu onze dataset downloaden en vanuit onze downloadmap in RStudio inlezen met de functie read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Om te beginnen maken we eerst een histogram van de vierkantswortel van het visgewicht om onze verdeling te zien. Deze verdeling is, zoals we kunnen zien, verre van normaal, of een Gaussische verdeling. Als iets, dan is hij enigszins bimodaal.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")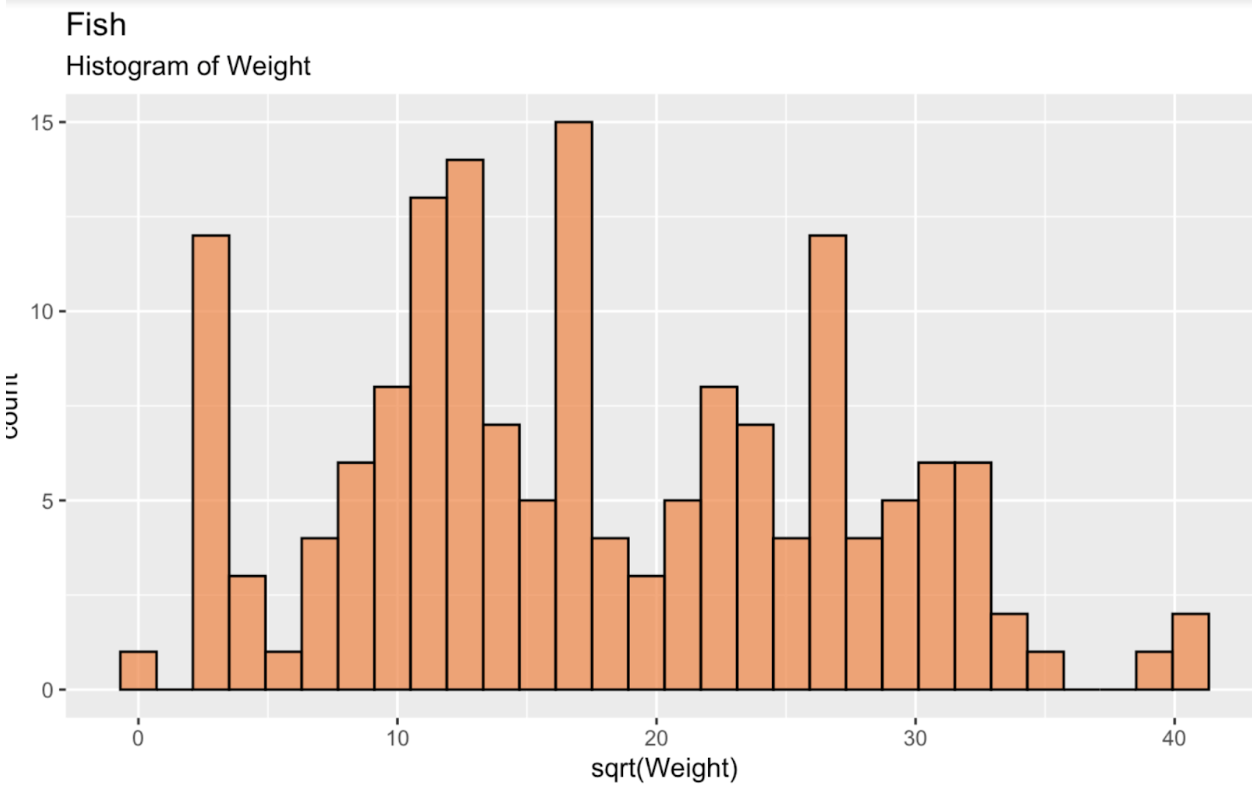
Histogram van visgewicht. Afbeelding door de auteur.
We kunnen in R bootstrappen met het infer-pakket uit de tidymodels-bibliotheek. Als we deze tabel naar onze console printen, krijgen we een data frame met de gewenste statistiek voor elke replicatie. Wanneer we van deze replicaties een nieuwe verdeling maken, zal die verdeling normaal zijn, waaruit we betrouwbaarheidsintervallen kunnen genereren.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")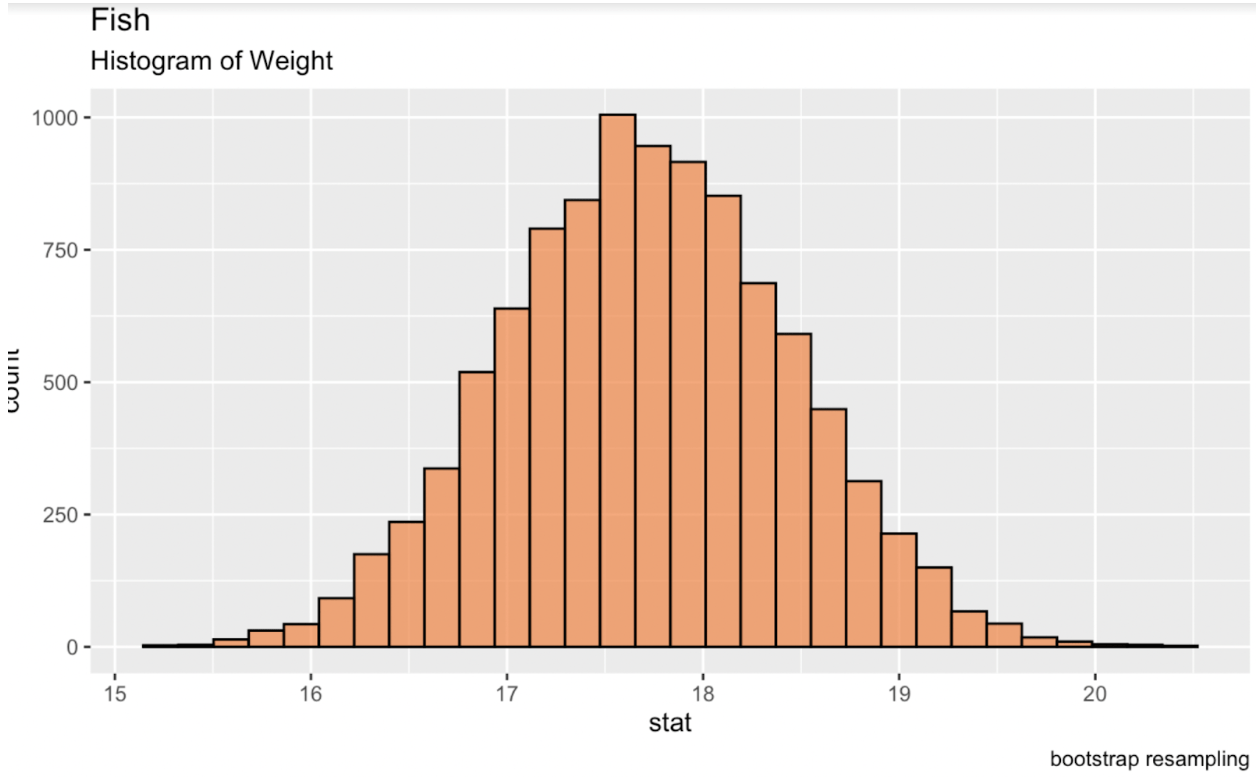 Histogram van de gebootstrapte gemiddelde visgewichten. Afbeelding door de auteur.
Histogram van de gebootstrapte gemiddelde visgewichten. Afbeelding door de auteur.
Lineaire regressie, de hoeksteen van statistische modellering, wordt gebruikt om de relatie tussen één of meer onafhankelijke variabelen en een afhankelijke variabele te laten zien. Bij het werken met regressiemodellen is het gebruikelijk om de onzekerheid rond onze schattingen te beoordelen. Een manier om dit te doen is door betrouwbaarheidsintervallen voor lineaire regressie te berekenen, die een bereik geven waarbinnen de echte parameter, zoals het gemiddelde, waarschijnlijk valt. Hier maken we betrouwbaarheidsintervallen met bootstrapping, en we maken ook betrouwbaarheidsintervallen met de normale benaderingsmethode, ook wel het Wald-betrouwbaarheidsinterval genoemd.
In de context van lineaire regressie houdt bootstrap-hersteekproeven in dat er willekeurig uit de dataset wordt getrokken om meerdere bootstrap-steekproeven te creëren. We passen vervolgens op elke steekproef een regressiemodel. Ten slotte gebruiken we de verdeling van de modelcoëfficiënten over deze steekproeven om betrouwbaarheidsintervallen te schatten. In de onderstaande code gebruiken we de functie bootstraps() uit het tidymodels-pakket om bootstrap-hersteekproeven uit te voeren op onze dataset. Vervolgens maken we histogrammen om het bereik aan waarden te tonen dat in onze bootstrap-hersteekproeven voorkomt voor de intercept- en gewichtcoëfficiënten.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')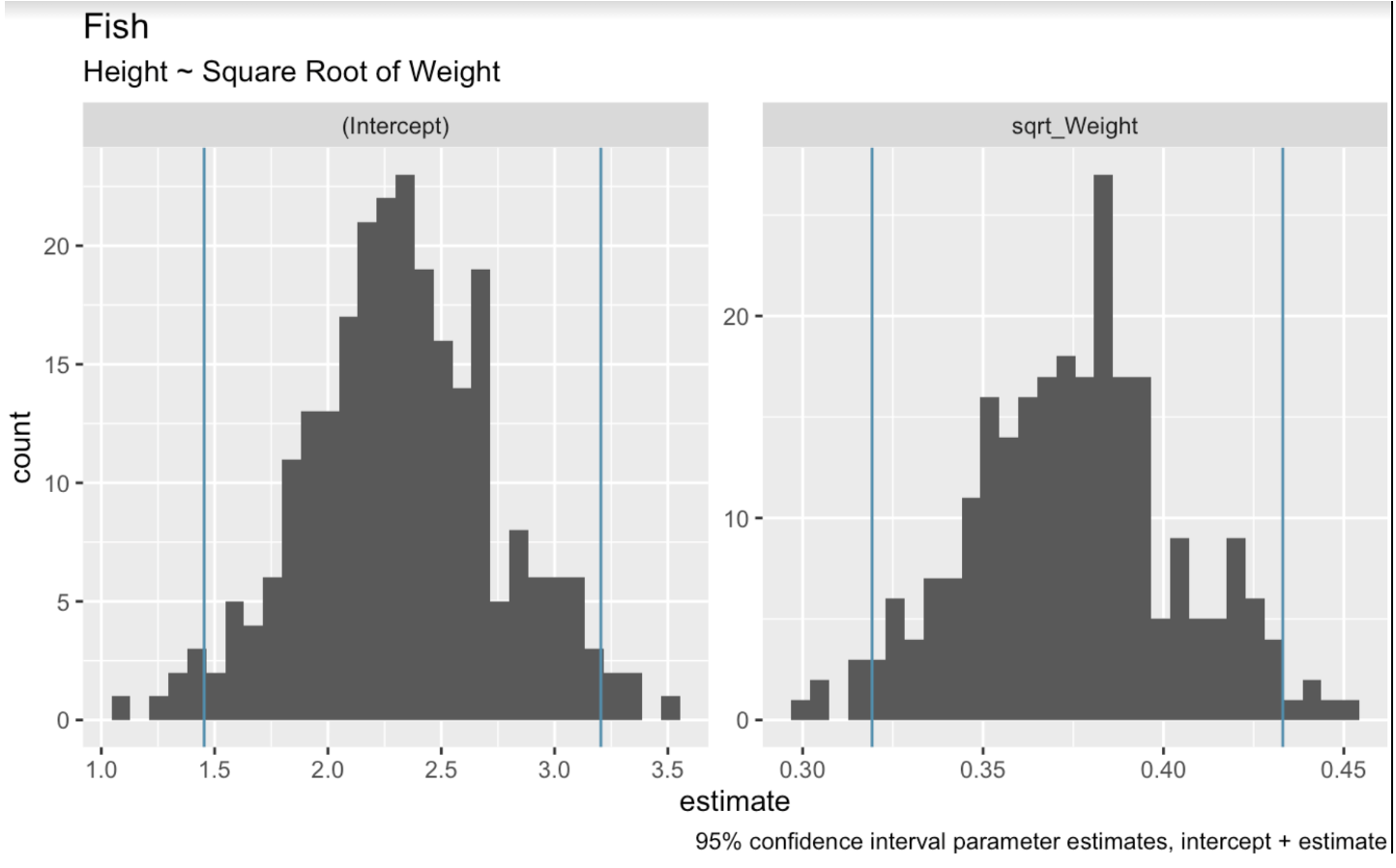
Gebootstrapte coëfficiënten van een lineair model. Afbeelding door de auteur.
Wanneer we onze mogelijke regressielijnen plotten, knippen we de meest extreme lijnen aan beide uiteinden af om een 95%-interval te krijgen. De functie int_pctl() maakt dit eenvoudig.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Als laatste stap maken we nu betrouwbaarheidsintervallen die worden gegenereerd met de meer theoretische, gesloten-formulevergelijkingen. We kunnen de parameters vinden door summary() van ons lineaire modelobject aan te roepen.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Hier is de geschatte coëfficiënt voor de variabele sqrt_Weight 0,37569. De standaardfout voor sqrt_Weight is 0,02186. Het aantal vrijheidsgraden is 157 (wat 159 observaties in onze dataset minus twee geschatte parameters is). En de t-waarde voor een 95%-betrouwbaarheidsinterval dat tweezijdig is, is 1,975189. We kennen dit laatste getal via de functie qt(): qt(0.975, 157). In de onderstaande visualisatie zijn de blauwe lijnen de gebootstrappte lineaire regressielijnen en de rode stippellijnen het betrouwbaarheidsinterval dat is gegenereerd met de gebruikelijke analytische formule.
# Wald confidence interval(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")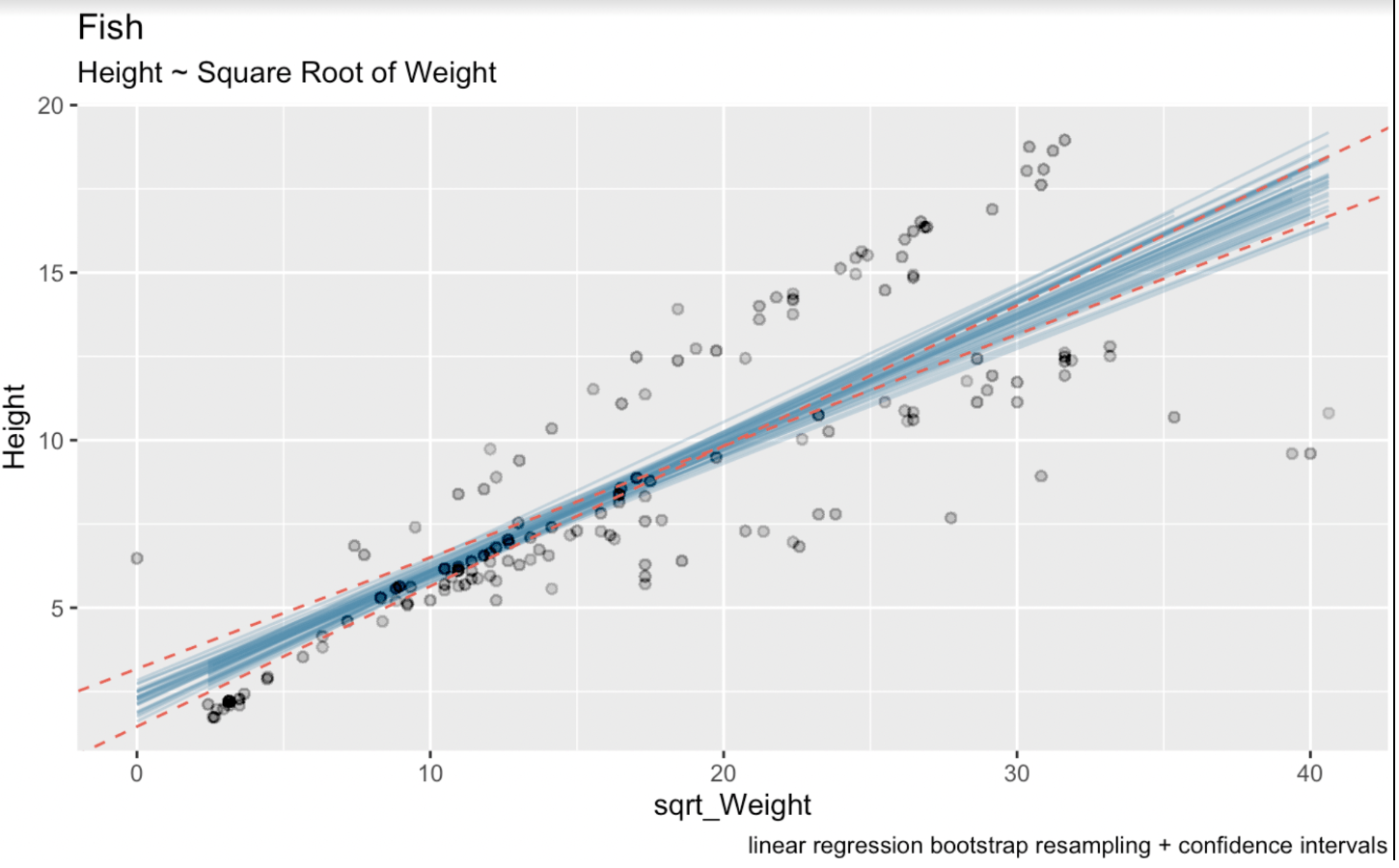
Gebootstrapte lineaire regressies met betrouwbaarheidsintervallen. Afbeelding door de auteur.
Hier zien we duidelijk dat ons proces van bootstrap-hersteekproeven wat meer onzekerheid in onze schatting heeft geïntroduceerd. Dit komt doordat de intervallen voor regressiecoëfficiënten zijn berekend met theoretische formules op basis van aannames over de verdeling van fouten en de eigenschappen van de schatter. Deze formules steunen op aannames zoals normaliteit van fouten en constante variantie.
Bootstrap-hersteekproeven daarentegen zijn verdelingsvrij, wat betekent dat ze minimale aannames doen over de onderliggende dataverdeling. In plaats daarvan schat bootstrap-hersteekproeven direct de steekproefverdeling van onze statistiek van interesse door te hersteekproeven uit de geobserveerde data. Daardoor kunnen bootstrap-betrouwbaarheidsintervallen robuuster en betrouwbaarder zijn wanneer de aannames van traditionele methoden worden geschonden of bij kleine steekproeven, zoals bij onze Fish Market-dataset met 159 observaties.
Bij parametrisch bootstrapping worden aannames gedaan over de onderliggende verdeling van de data en worden hersteekproeven op basis van die aannames gegenereerd. Deze methode is handig wanneer je vooraf kennis of sterke aannames hebt over de verdeling van de data. Denk aan een steekproefdataset die misschien geen normale verdeling heeft, maar waarbij het idee achter de steekproeven beter bekend is, zodat je een verdeling kunt creëren met parameters uit de populatie.
Niet-parametrisch bootstrapping daarentegen doet geen aannames over de verdeling van de data. Het hersteekproeft direct met teruglegging uit de geobserveerde data en is daardoor vooral waardevol wanneer de werkelijke verdeling onbekend of lastig te definiëren is. In ons voorbeeld hierboven gebruikten we niet-parametrisch bootstrapping. Beide methoden stellen je in staat statistieken zoals standaardfouten en betrouwbaarheidsintervallen te schatten. Niet-parametrisch bootstrapping biedt echter meer flexibiliteit voor real-world datasets, vooral bij kleine of complexe steekproeven, en wordt in de praktijk vaker gebruikt.
Bij tijdreeksvoorspellingen kan bootstrapping worden toegepast om historische data te hersteekproeven en toekomstige voorspellingen te genereren, waardoor je een verdeling van mogelijke uitkomsten krijgt in plaats van één puntschatting. Dit helpt het bereik aan potentiële toekomstige scenario’s te modelleren en creëert betrouwbaarheidsintervallen voor voorspellingen. Bootstrapping ligt ook ten grondslag aan ensemblemethoden zoals bagging in tijdreeksmodellen, die overfitting kunnen verminderen en de algehele nauwkeurigheid van de voorspelling kunnen verbeteren door meerdere modellen te combineren. Onze cursus Forecasting in R leert je hoe je kunt hersteekproeven bij tijdreeksvoorspellen, of je nu ARIMA-voorspellingen of een andere methode gebruikt.
Ik hoop dat je bootstrapping bent gaan waarderen, als dat nog niet zo was. Bootstrapping is, zoals we hebben gezien, een krachtig hulpmiddel in zowel statistiek als machine learning en biedt een interessante manier om de variabiliteit en zekerheid van statistische maten te schatten zonder sterke aannames over de onderliggende data.
Overweeg om te beginnen met onze carrièretrack Machine Learning Scientist in Python en word zeker bedreven in het werken met verdelingstypen en complexe datasets. Onze skill track Statistical Inference in R is een andere geweldige optie met focus op hypothesetoetsing, randomisatie en het meten van onzekerheid.
Leer met DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
