
Programma
Scienziato specializzato in apprendimento automatico in Python
85 h
In questo articolo esploreremo una tecnica importante in statistica e machine learning chiamata bootstrapping. Il termine deriva dall'espressione inglese “pulling yourself up by your bootstraps”, perché questa tecnica consente di ottenere molto anche a partire da poco. Con il bootstrapping puoi partire da una distribuzione di qualsiasi forma o dimensione, creare una nuova distribuzione di ricampionamenti e usare questa nuova distribuzione per approssimare la vera distribuzione di probabilità. Per questo motivo, il bootstrapping è particolarmente efficace per attribuire a stime campionarie misure di accuratezza come bias, varianza, intervalli di confidenza ed errore di previsione.
Prima di iniziare, se ti interessa la data science, valuta di seguire questi corsi DataCamp su data science e statistica, come il nostro skill track Statistical Inference in R e il corso Foundations of Inference in Python.
Partiamo collocando correttamente il bootstrapping tra i metodi di ricampionamento. Sebbene esistano diverse tipologie di ricampionamento, hanno in comune un aspetto fondamentale: imitano il processo di campionamento. Usiamo un metodo di ricampionamento perché non è pratico continuare a prelevare nuovi campioni dalla popolazione di interesse: il ricampionamento è una sorta di scorciatoia.
Ad esempio, quando vogliamo capire qualcosa sulla nostra popolazione di interesse, potremmo pensare di somministrare un sondaggio e puntare a mille risposte. Tuttavia nessuno amministrerà lo stesso sondaggio mille volte alla stessa popolazione target. È per questa limitazione pratica che ricorriamo a un metodo di ricampionamento per generare statistiche sul nostro campione, come l'errore standard.
Esistono quattro tipologie principali di ricampionamento. Vale la pena menzionare anche gli altri metodi perché condividono una storia comune di innovazione e miglioramento statistico. In particolare, il bootstrapping è stato sviluppato come estensione, modifica o perfezionamento del metodo jackknife.
È utile soffermarsi sul jackknife perché è un precursore del bootstrapping, e il bootstrapping è stato introdotto come estensione e miglioramento del jackknife, sviluppato negli anni Cinquanta quando i computer avevano circa un kilobyte di memoria.
Il jackknife è un metodo leave-one-out che calcola una statistica di interesse rimuovendo successivamente, o iterativamente, ciascuna osservazione. Con il jackknife, il numero di ricampionamenti è limitato al numero di osservazioni e, in gran parte per questo motivo, il jackknife si comporta un po' peggio con campioni piccoli. È anche piuttosto limitato in termini di tipi di dati utilizzabili. D'altra parte, a differenza del bootstrap, il jackknife è riproducibile ogni volta.
Il bootstrapping ha un ampio ventaglio di applicazioni sia in statistica che in machine learning. Uno degli usi più comuni è stimare gli intervalli di confidenza quando la distribuzione sottostante è sconosciuta o quando le dimensioni campionarie sono ridotte. Questa capacità lo rende particolarmente prezioso nelle situazioni in cui i metodi parametrici tradizionali potrebbero non essere appropriati.
Il bootstrapping è spesso utilizzato anche nei test di ipotesi e nella validazione dei modelli, dove aiuta a valutare la robustezza delle previsioni. Nel machine learning, il bootstrapping è alla base del popolare metodo di ensemble noto come bagging, utilizzato in modelli come le random forest per migliorare l'accuratezza riducendo la varianza.
Per illustrare il bootstrapping, dobbiamo usare un linguaggio di programmazione come R, perché ci consente di generare più dataset ricampionati; senza un ambiente di programmazione, il processo sarebbe troppo lungo e complesso da eseguire manualmente. In questo articolo vedremo come fare il bootstrap degli intervalli di confidenza per una distribuzione e anche per una regressione lineare usando il dataset Fish Market su Kaggle.
Prima di vedere il bootstrapping in senso stretto, è utile familiarizzare con l'idea del campionamento con reinserimento. In R base, la funzione sample() accetta almeno due argomenti da specificare esplicitamente: x e size. x definisce l'elenco o l'intervallo di valori da cui scegliere il campione e size definisce la dimensione del campione. C'è un argomento aggiuntivo spesso specificato, cioè l'argomento replace. Se non diversamente stabilito, il valore predefinito è replace = FALSE.
Il bootstrapping è campionamento con reinserimento. Quando campioniamo con reinserimento, reinseriamo il valore dopo ogni estrazione. Ogni estrazione è quindi indipendente da quella precedente. Quando campioniamo senza reinserimento, non reinseriamo i valori: una volta selezionato un valore, non può essere selezionato di nuovo; possiamo quindi dire che due estrazioni non sono indipendenti e che il risultato di una influisce sulle possibilità della successiva. Una conseguenza è che non possiamo scegliere una dimensione del campione maggiore della dimensione del vettore di input, a meno di specificare replace = TRUE. Il bootstrapping non ha questo problema e possiamo generare un dataset ricampionato bootstrap molto più grande dell'originale.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Scarichiamo ora il dataset e leggiamolo dalla cartella Download in RStudio usando la funzione read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Per cominciare, creiamo un istogramma della radice quadrata del peso dei pesci, per osservare la distribuzione. Questa distribuzione, come si vede, è ben lontana da una distribuzione normale o gaussiana. Se vogliamo, è in qualche misura bimodale.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")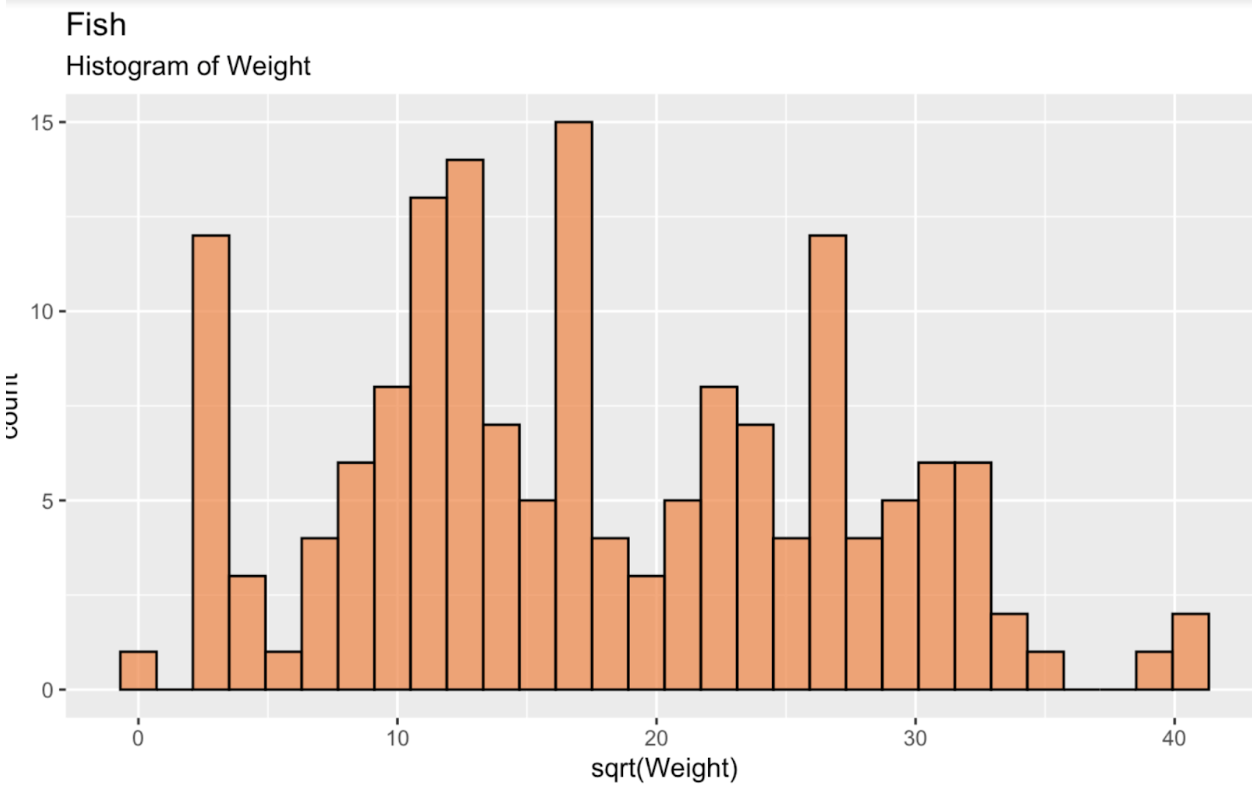
Istogramma del peso dei pesci. Immagine dell'autore.
Possiamo fare il bootstrap in R usando il pacchetto infer della libreria tidymodels. Stampando questa tabella in console otteniamo un data frame della statistica desiderata per ciascuna replica. Quando creiamo una nuova distribuzione di queste repliche, questa distribuzione sarà normale e potremo ricavarne intervalli di confidenza.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")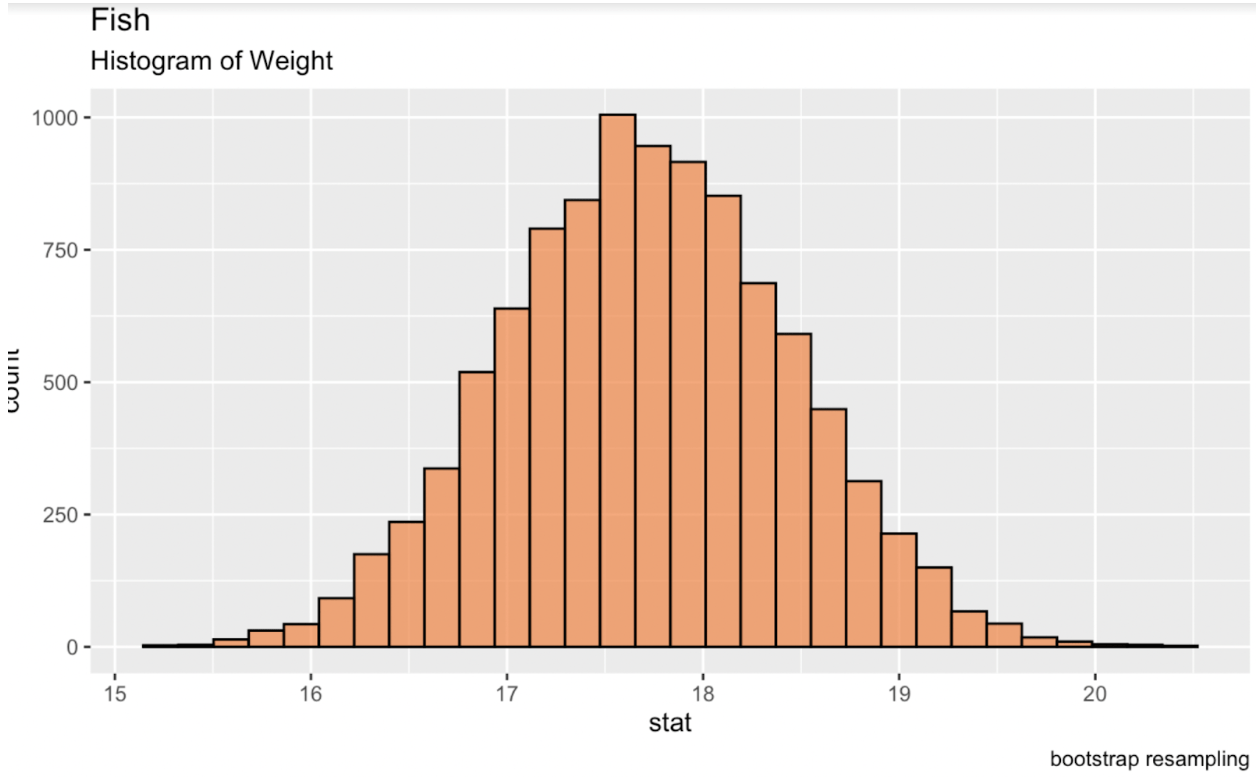 Istogramma della media bootstrappata del peso dei pesci. Immagine dell'autore.
Istogramma della media bootstrappata del peso dei pesci. Immagine dell'autore.
La regressione lineare, pietra angolare della modellazione statistica, serve a mostrare la relazione tra una o più variabili indipendenti e una variabile dipendente. Quando si lavora con modelli di regressione è comune valutare l'incertezza delle nostre stime. Un modo per farlo è calcolare gli intervalli di confidenza della regressione lineare, che forniscono un intervallo di valori entro cui è probabile che ricada il vero parametro, come la media. Qui creeremo intervalli di confidenza tramite bootstrapping e anche con il metodo di approssimazione normale, chiamato anche intervallo di confidenza di Wald.
Nel contesto della regressione lineare, il ricampionamento bootstrap prevede l'estrazione casuale dal dataset per creare più campioni bootstrap. Quindi adattiamo un modello di regressione a ciascun campione. Infine, usiamo la distribuzione dei coefficienti del modello su questi campioni per stimare gli intervalli di confidenza. Nel codice seguente, usiamo la funzione bootstraps() del pacchetto tidymodels per effettuare il ricampionamento bootstrap sul nostro dataset. Creiamo quindi istogrammi per mostrare l'intervallo di valori presente nei ricampionamenti bootstrap per i coefficienti di intercetta e di peso.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')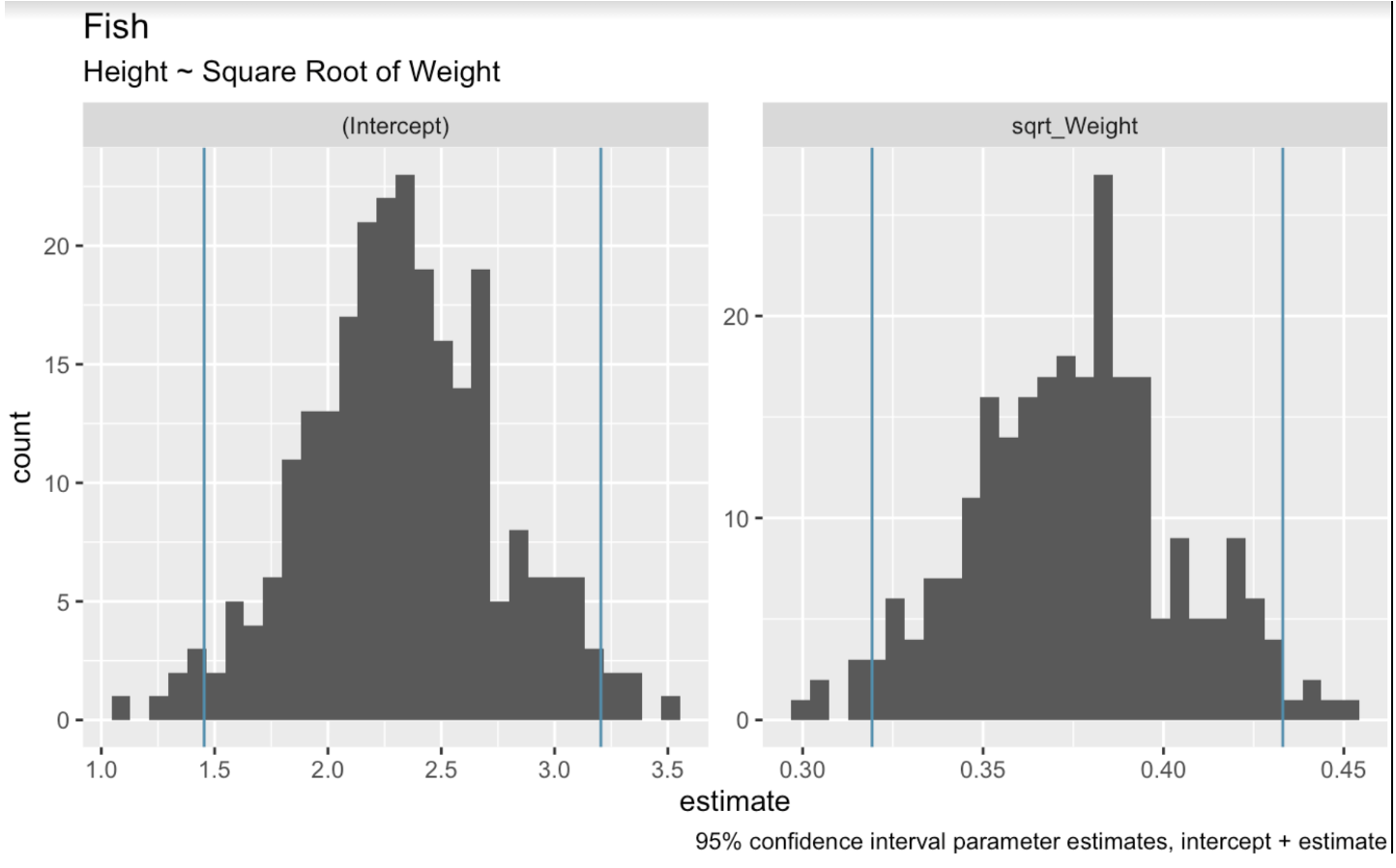
Coefficienti bootstrappati del modello lineare. Immagine dell'autore.
Quando tracciamo le possibili rette di regressione, taglieremo le più estreme a entrambe le estremità per ottenere un intervallo al 95%. La funzione int_pctl() semplifica questa operazione.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Come passo finale, creiamo ora gli intervalli di confidenza generati dalle più teoriche equazioni in forma chiusa. Possiamo trovare i parametri chiamando summary() sul nostro oggetto modello lineare.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Qui, il coefficiente stimato per la variabile sqrt_Weight è 0,37569. L'errore standard per sqrt_Weight è 0,02186. I gradi di libertà sono 157 (ossia 159 osservazioni nel dataset meno due parametri stimati). E il valore t per un intervallo di confidenza al 95% a due code è 1,975189. Conosciamo quest'ultimo numero tramite la funzione qt(): qt(0.975, 157). Nella visualizzazione qui sotto, le linee blu sono le regressioni lineari bootstrappate, mentre le linee tratteggiate rosse sono l'intervallo di confidenza generato dalla comune formula analitica.
# Wald confidence interval(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")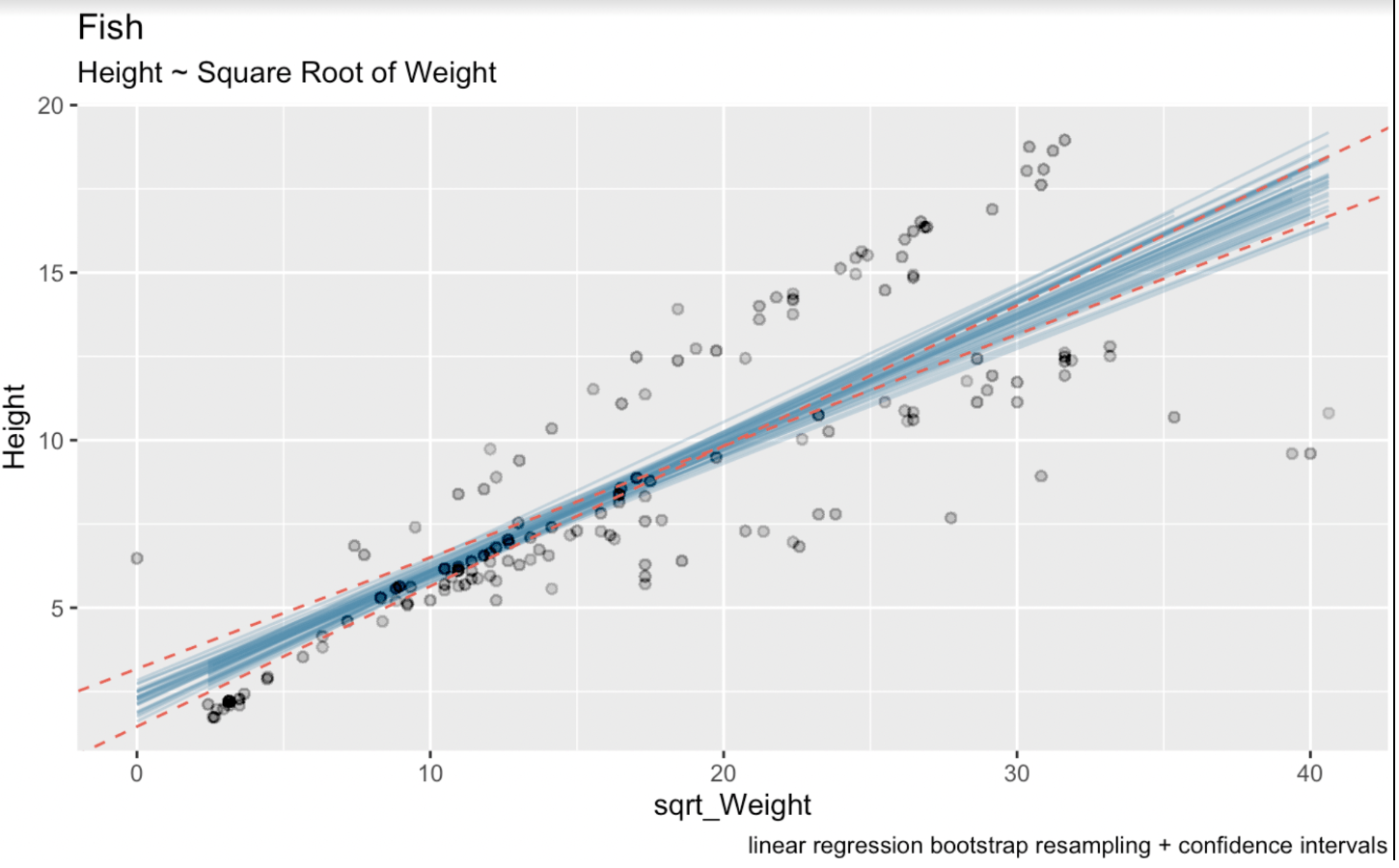
Regressioni lineari bootstrappate con intervalli di confidenza. Immagine dell'autore.
Qui vediamo chiaramente che il nostro processo di ricampionamento bootstrap ha introdotto un po' più di incertezza nella stima. Questo perché gli intervalli per i coefficienti della regressione lineare erano calcolati usando formule teoriche basate su assunzioni sulla distribuzione degli errori e sulle proprietà dello stimatore. Queste formule si basano su ipotesi come la normalità degli errori e la varianza costante.
Il ricampionamento bootstrap, invece, è distribution-free, cioè fa ipotesi minime sulla distribuzione dei dati. Invece di affidarsi a ipotesi, stima direttamente la distribuzione campionaria della nostra statistica di interesse ricampionando dai dati osservati. Di conseguenza, gli intervalli di confidenza bootstrap possono essere più robusti e affidabili quando le assunzioni dei metodi tradizionali sono violate o quando si lavora con campioni piccoli, come nel caso del nostro dataset Fish Market con 159 osservazioni.
Nel bootstrapping parametrico si formulano ipotesi sulla distribuzione sottostante dei dati e si generano ricampionamenti sulla base di tali ipotesi. Questo metodo è utile quando hai conoscenze pregresse o ipotesi forti sulla distribuzione dei dati. Pensa a un dataset di campionamento che potrebbe non avere una distribuzione normale, ma il meccanismo alla base del campionamento è ben noto, quindi puoi creare una distribuzione usando parametri della popolazione.
Il bootstrapping non parametrico, invece, non fa assunzioni sulla distribuzione dei dati. Ricampiona direttamente dai dati osservati con reinserimento, risultando particolarmente utile quando la vera distribuzione è sconosciuta o difficile da definire. Nell'esempio sopra abbiamo usato il bootstrapping non parametrico. Entrambi i metodi permettono di stimare statistiche come errori standard e intervalli di confidenza. Tuttavia, il bootstrapping non parametrico offre maggiore flessibilità per i dataset reali, soprattutto con campioni piccoli o complessi, ed è più comunemente usato nella pratica.
Nel forecasting di serie storiche, il bootstrapping può essere applicato per ricampionare i dati storici e generare previsioni future, fornendo una distribuzione di possibili risultati invece di una singola stima puntuale. Questo aiuta a modellare la gamma di scenari futuri possibili e a creare intervalli di confidenza per le previsioni. Il bootstrapping è anche alla base di metodi di ensemble come il bagging nei modelli di serie storiche, che può ridurre l'overfitting e migliorare l'accuratezza complessiva della previsione combinando più modelli. Il nostro corso Forecasting in R ti insegnerà come ricampionare nel time forecasting, che tu usi il forecasting ARIMA o un altro metodo.
Spero che tu abbia imparato ad apprezzare il bootstrapping, se già non lo facevi. Come abbiamo visto, il bootstrapping è uno strumento potente sia in statistica che in machine learning e offre un modo interessante per stimare la variabilità e la confidenza delle misure statistiche senza richiedere forti assunzioni sui dati sottostanti.
Valuta di iniziare il nostro career track Machine Learning Scientist in Python e diventerai un esperto nel lavorare con tipi di distribuzione e dataset complessi. Il nostro skill track Statistical Inference in R è un'altra ottima opzione, con focus su test di ipotesi, randomizzazione e misurazione dell'incertezza.
Impara con DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

