Seiring meningkatnya popularitas large language model (LLM) dan penerapannya, kita juga melihat lonjakan pada alat integrasi, kerangka kerja LLMOps, dan basis data vektor. Ini karena bekerja dengan LLM memerlukan pendekatan yang berbeda dibandingkan dengan model pembelajaran mesin tradisional.
Salah satu teknologi inti yang mendukung LLM adalah embedding vektor. Meskipun komputer tidak dapat memahami teks secara langsung, embedding merepresentasikan teks secara numerik. Semua teks yang diberikan pengguna diubah menjadi embedding, yang kemudian digunakan untuk menghasilkan respons.
Mengonversi teks menjadi embedding adalah proses yang memakan waktu. Untuk menghindarinya, kita memiliki basis data vektor yang dirancang khusus untuk penyimpanan dan pengambilan embedding vektor secara efisien.
Dalam tutorial ini, saya akan membahas penyimpanan vektor dan Chroma DB, sebuah basis data open-source untuk menyimpan dan mengelola embedding. Anda akan mempelajari cara menambah dan menghapus dokumen, melakukan pencarian kemiripan, serta mengonversi teks menjadi embedding.

Gambar oleh penulis
Ringkasnya
- ChromaDB adalah basis data vektor open-source untuk menyimpan dan mengambil embedding—instal dengan
pip install chromadb - Gunakan
chromadb.PersistentClient(path="./chroma_db")untuk penyimpanan lokal persisten atauchromadb.EphemeralClient()untuk pengujian in-memory - Buat collection (analog dengan tabel), lalu
add()dokumen dengan metadata dan ID opsional - Jalankan pencarian kemiripan semantik dengan
collection.query(query_texts=["..."], n_results=5) - Sambungkan model embedding apa pun—OpenAI, HuggingFace, Google Gemini, atau fungsi kustom
- ChromaDB banyak digunakan sebagai penyimpanan vektor dalam pipeline RAG (Retrieval-Augmented Generation)
Apa itu Vector Store?
Vector store adalah basis data yang dirancang khusus untuk menyimpan dan mengambil embedding vektor secara efisien. Ini dibutuhkan karena basis data tradisional seperti SQL tidak dioptimalkan untuk menyimpan dan melakukan query data vektor berukuran besar.
Embedding merepresentasikan data (biasanya data tidak terstruktur seperti teks) dalam format vektor numerik di ruang berdimensi tinggi. Basis data relasional tradisional kurang cocok untuk menyimpan dan menelusuri representasi vektor ini.
Vector store dapat melakukan pengindeksan dan dengan cepat mencari vektor yang serupa menggunakan algoritme kemiripan, sehingga aplikasi dapat menemukan vektor terkait berdasarkan query vektor target.
Sebagai contoh, dalam kasus chatbot personalisasi, pengguna memasukkan prompt untuk model AI generatif. Menggunakan algoritme pencarian kemiripan, model menelusuri teks serupa dalam kumpulan dokumen. Informasi yang dihasilkan kemudian digunakan untuk menghasilkan respons yang sangat personal dan akurat. Pengambilan informasi ini dimungkinkan melalui embedding dan pengindeksan vektor dalam vector store.
Apa itu Chroma DB?
Chroma DB adalah vector store open-source yang digunakan untuk menyimpan dan mengambil embedding vektor. Penggunaan utamanya adalah menyimpan embedding beserta metadata untuk digunakan kemudian oleh large language model. Selain itu, Chroma DB juga dapat digunakan untuk mesin pencari semantik pada data teks.
Fitur Chroma DB
- Sederhana dan andal:
- Instal dengan perintah sederhana:
pip install chromadb. - Mulai cepat dengan Python SDK, memungkinkan integrasi mulus dan penyiapan yang cepat.
- Instal dengan perintah sederhana:
- Fitur lengkap:
- Fitur retrieval komprehensif: Termasuk pencarian vektor, pencarian full-text, penyimpanan dokumen, pemfilteran metadata, dan retrieval multimodal.
- Sangat skalabel: Menggunakan SQLite untuk penyimpanan lokal persisten dan mendukung mode client-server untuk multi-klien dan deployment produksi.
- Dukungan multi-bahasa:
- Menyediakan SDK untuk bahasa pemrograman populer, termasuk Python, JavaScript/TypeScript, Ruby, PHP, dan Java.
- Terintegrasi:
- Integrasi native dengan model embedding dari HuggingFace, OpenAI, Google, dan lainnya.
- Kompatibel dengan Langchain dan LlamaIndex, dengan lebih banyak integrasi alat segera hadir.
- Open source:
- Berlisensi Apache 2.0.
- Cepat dan sederhana:
- Berfokus pada kesederhanaan dan kecepatan, dirancang untuk membuat analisis dan retrieval efisien sekaligus intuitif digunakan.
Chroma DB menawarkan opsi server yang di-host sendiri. Jika Anda memerlukan basis data vektor terkelola atau cloud-native, jelajahi panduan kami tentang Menguasai Basis Data Vektor dengan Pinecone atau Weaviate sebagai solusi alternatif.
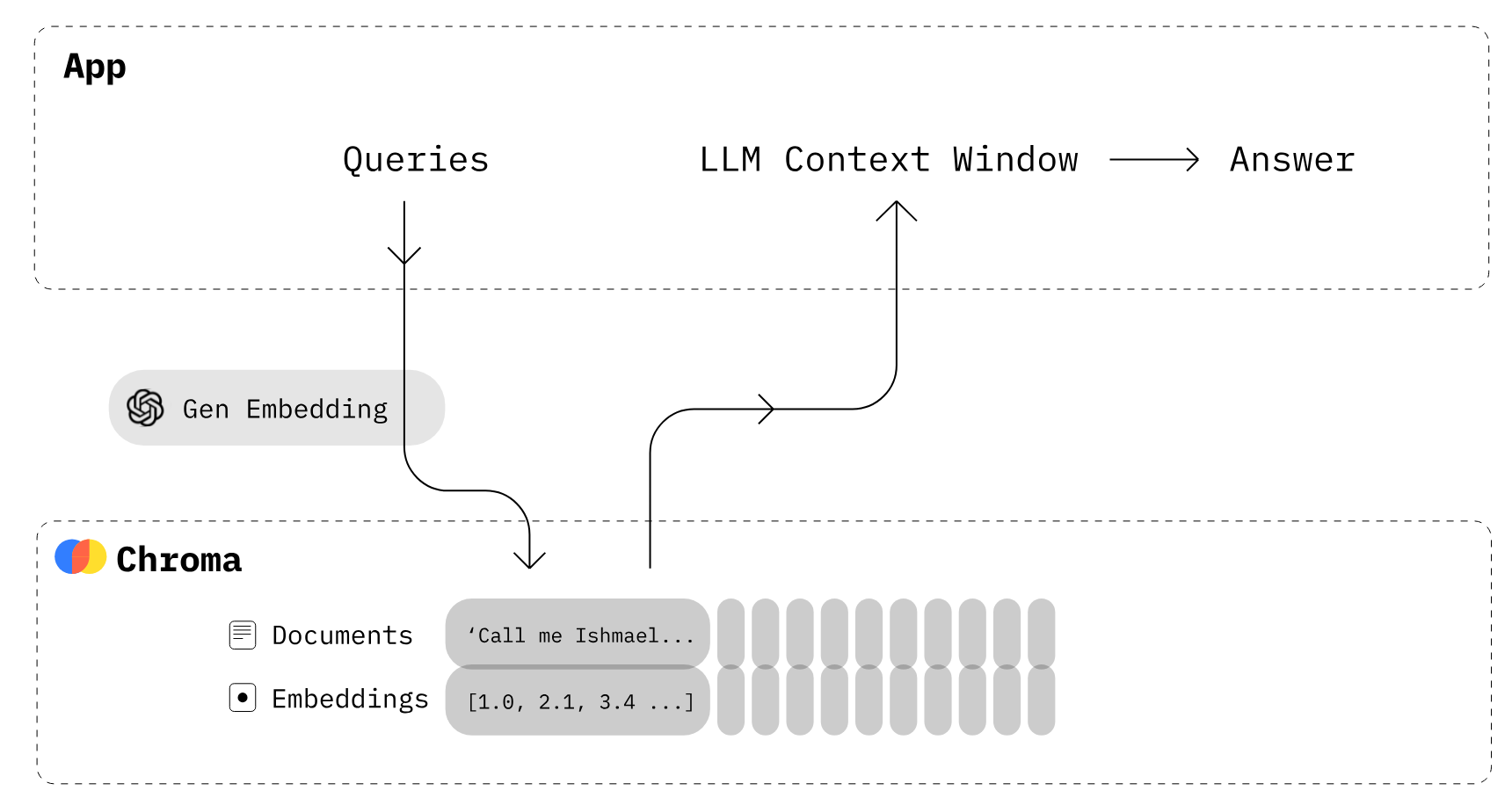
Gambar dari Chroma
Bagaimana cara kerja Chroma DB?
- Pertama, Anda harus membuat collection yang mirip dengan tabel pada basis data relasional. Secara bawaan, Chroma mengonversi teks menjadi embedding menggunakan
all-MiniLM-L6-v2, tetapi Anda dapat memodifikasi collection untuk menggunakan model embedding lain. - Tambahkan dokumen teks dengan metadata dan ID unik ke collection yang baru dibuat. Saat collection menerima teks, Chroma otomatis mengonversinya menjadi embedding.
- Query collection berdasarkan teks atau embedding untuk menerima dokumen serupa. Anda juga dapat memfilter hasil berdasarkan metadata.
Prasyarat
Untuk mengikuti tutorial ini, Anda memerlukan:
- Python 3.8+ (Python 3.11 direkomendasikan untuk kompatibilitas ChromaDB terbaik)
- Pengelola paket pip
- Kunci API OpenAI (hanya diperlukan untuk bagian Embeddings; bagian inti ChromaDB di bawah ini dapat berjalan tanpa kunci)
- SQLite 3.35 atau lebih tinggi (sudah ada di Python 3.11; jika Anda menggunakan versi lebih lama dan mengalami masalah, gunakan
pip install pysqlite3-binary) - Pemahaman dasar tentang list dan dictionary di Python
Mulai Menggunakan Chroma DB
Di bagian ini, saya akan membuat basis data vektor, menambahkan collection, memuat teks ke dalamnya, dan menjalankan query pencarian kemiripan.
Pertama, instal chromadb dan openai. Anda memerlukan kunci API OpenAI hanya untuk bagian Embeddings—contoh inti ChromaDB di bawah ini dapat berjalan tanpanya.
Catatan: Chroma memerlukan SQLite versi 3.35 atau lebih tinggi. Jika Anda mengalami masalah, tingkatkan ke Python 3.11 atau instal versi chromadb yang lebih lama.
!pip install chromadb openai Memilih mode klien
ChromaDB menyediakan tiga mode klien bergantung pada kasus penggunaan Anda:
| Client | Use case | Code |
|---|---|---|
| EphemeralClient | Pengujian in-memory; data hilang saat keluar | chromadb.EphemeralClient() |
| PersistentClient | Penyimpanan file lokal; data bertahan setelah restart | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Produksi; terhubung ke server ChromaDB yang berjalan | chromadb.HttpClient(host="localhost", port=8000) |
Anda dapat membuat basis data in-memory (sementara) untuk pengujian menggunakan chromadb.EphemeralClient(). Ini hanya menyimpan data di memori dan akan direset ketika program berakhir—sempurna untuk eksperimen cepat.
Dalam contoh ini, saya akan membuat basis data persisten yang disimpan di direktori ./chroma_db. ChromaDB menggunakan penyimpanan berbasis SQLite dalam mode persisten—backend DuckDB dihapus pada ChromaDB 0.4.0.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")Setelah itu, kita akan membuat objek collection menggunakan klien. Ini mirip dengan membuat tabel pada basis data tradisional.
collection = client.create_collection(name="Students")Untuk menambahkan teks ke collection kita, kita akan menghasilkan teks acak tentang seorang mahasiswa, klub, dan universitas. Anda dapat membuat teks acak menggunakan ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Sekarang, kita akan menggunakan fungsi add() untuk menambahkan data teks beserta metadata dan ID unik. Setelah itu, Chroma akan otomatis mengunduh model all-MiniLM-L6-v2 untuk mengonversi teks menjadi embedding dan menyimpannya di collection "Students".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Untuk menjalankan pencarian kemiripan, Anda dapat menggunakan fungsi query() dan mengajukan pertanyaan dalam bahasa alami. Fungsi ini akan mengonversi query menjadi embedding dan menggunakan algoritme kemiripan untuk menghasilkan hasil yang serupa. Dalam kasus kita, fungsi mengembalikan dua hasil yang serupa.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embedding
Anda dapat menggunakan model embedding berkinerja tinggi mana pun dari daftar embedding. Anda bahkan dapat membuat fungsi embedding kustom. Untuk penjelasan mendalam tentang model generasi terkini OpenAI, lihat panduan kami tentang text-embedding-3-large.
Di bagian ini, saya akan menggunakan model text-embedding-3-small dari OpenAI untuk mengonversi teks menjadi embedding. Ini adalah pengganti yang direkomendasikan OpenAI untuk model lama text-embedding-ada-002—memberikan kinerja benchmark yang lebih baik dengan biaya 5× lebih rendah.
Setelah membuat fungsi embedding OpenAI, Anda dapat menambahkan daftar dokumen teks untuk menghasilkan embedding.
Pelajari cara menggunakan OpenAI API untuk Text Embeddings dan buat pengklasifikasi teks, sistem information retrieval, serta detektor kemiripan semantik.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Alih-alih menggunakan model embedding bawaan, saya akan memuat embedding yang sudah dihasilkan langsung ke collection baru.
- Kita akan menggunakan fungsi
get_or_create_collection()untuk membuat collection baru bernama "Students2". Fungsi ini berbeda dengancreate_collection(). Fungsi ini akan mengambil collection jika sudah ada atau membuatnya jika belum ada. - Sekarang kita akan menambahkan embedding, dokumen teks, metadata, dan ID ke collection baru kita.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Ada metode lain yang lebih sederhana juga. Anda dapat menambahkan fungsi embedding OpenAI saat membuat atau mengakses collection. Selain OpenAI, Anda dapat menggunakan model Cohere, Google Gemini, HuggingFace, dan Instructor.
Dalam kasus kita, menambahkan dokumen teks baru akan menjalankan fungsi embedding OpenAI alih-alih model bawaan untuk mengonversi teks menjadi embedding.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Mari kita lihat perbedaannya dengan menjalankan query serupa pada collection baru.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsHasil kita meningkat. Pencarian kemiripan sekarang mengembalikan informasi tentang universitas alih-alih klub. Selain itu, jarak antar vektor lebih rendah dibandingkan model embedding bawaan, yang merupakan hal baik.

Pemfilteran Hasil Query
ChromaDB mendukung pemfilteran metadata untuk mempersempit hasil pencarian kemiripan. Gunakan parameter where dengan operator filter di dalam query():
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Operator yang didukung: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Anda juga dapat memfilter konten dokumen dengan where_document={"$contains": "chess"}.
Memperbarui dan Menghapus Data
Sama seperti basis data relasional, Anda dapat memperbarui atau menghapus nilai dari collection. Untuk memperbarui teks dan metadata, kita akan memberikan ID spesifik untuk rekaman tersebut dan teks baru.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Jalankan query sederhana untuk memeriksa apakah perubahan telah berhasil dilakukan.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsSeperti yang terlihat, alih-alih Alexandra, kita mendapatkan Kristiane.

Untuk menghapus sebuah rekaman dari collection, kita akan menggunakan fungsi delete() dan menentukan ID unik.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsTeks informasi mahasiswa telah dihapus; sebagai gantinya, kita mendapatkan hasil terbaik berikutnya.

Manajemen Collection
Di bagian ini, saya akan membahas fungsi utilitas collection untuk menghitung, menampilkan daftar, mengganti nama, dan menghapus collection.
Kita akan membuat collection baru bernama "vectordb" dan menambahkan informasi tentang cheat sheet Chroma DB, dokumentasi, dan JS API beserta metadata.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Kita akan menggunakan fungsi count() untuk memeriksa berapa banyak rekaman yang dimiliki collection.
vector_collections.count()3Untuk melihat semua rekaman dari collection, gunakan fungsi get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Untuk mengubah nama collection, gunakan fungsi modify(). Untuk melihat semua nama collection, gunakan list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Tampaknya kita telah berhasil mengganti nama "vectordb" menjadi "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Untuk mengakses collection mana pun, Anda dapat menggunakan get_collection() dengan nama collection.
vector_collections_new = client.get_collection(name="chroma_info")Kita dapat menghapus sebuah collection menggunakan fungsi klien delete_collection() dan menentukan nama collection.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Kita dapat menghapus seluruh collection basis data menggunakan client.reset(). Namun, ini tidak direkomendasikan karena tidak ada cara untuk memulihkan data setelah dihapus.
client.reset()
client.list_collections()[]ChromaDB dengan LangChain: Contoh RAG
Salah satu integrasi ChromaDB yang paling umum adalah dengan LangChain untuk membangun aplikasi RAG. Berikut contoh minimal menggunakan ChromaDB sebagai penyimpanan vektor:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)Untuk pipeline RAG siap produksi dengan FastAPI, lihat tutorial kami Membangun Sistem RAG dengan LangChain dan FastAPI. Untuk contoh menggunakan DeepSeek, lihat tutorial Chatbot DeepSeek R1 RAG dengan Chroma.
Kesimpulan
Vector store seperti Chroma DB menjadi komponen esensial dari sistem large language model. Dengan menyediakan penyimpanan khusus dan pengambilan embedding vektor yang efisien, vector store memungkinkan akses cepat ke informasi semantik yang relevan untuk mendukung LLM.
Dalam tutorial Chroma DB ini, kita membahas dasar-dasar membuat collection, menambahkan dokumen, mengonversi teks menjadi embedding, melakukan query untuk kemiripan semantik, dan mengelola collection.
Langkah alami berikutnya adalah membangun aplikasi Retrieval-Augmented Generation (RAG) dengan ChromaDB sebagai penyimpanan vektor. Mulailah dengan tutorial Membangun Sistem RAG dengan LangChain dan FastAPI untuk pipeline siap produksi, atau jelajahi Agentic RAG untuk alur kerja retrieval tingkat lanjut yang digerakkan agen. Anda juga dapat menggunakan LlamaIndex untuk memasukkan data privat ke LLM, atau ikuti tutorial LangChain LLM untuk pengembangan aplikasi secara menyeluruh.

