Büyük dil modelleri (LLM’ler) ve uygulamalarının yükselişiyle birlikte, entegrasyon araçları, LLMOps çatıları ve vektör veritabanlarının popülerliğinde artış gördük. Bunun nedeni, LLM’lerle çalışmanın geleneksel makine öğrenimi modelleriyle çalışmaktan farklı bir yaklaşım gerektirmesidir.
LLM’leri mümkün kılan temel teknolojilerden biri vektör gömlemeleridir. Bilgisayarlar metni doğrudan anlayamazken, gömlemeler metni sayısal olarak temsil eder. Kullanıcının sağladığı tüm metin gömlemelere dönüştürülür ve yanıt üretiminde kullanılır.
Metni gömlemeye dönüştürmek zaman alıcı bir işlemdir. Bunu aşmak için, vektör gömlemelerini verimli şekilde depolamak ve almak üzere özel olarak tasarlanmış vektör veritabanları vardır.
Bu eğitimde, gömleme depolarını ve gömlemeleri depolamak ve yönetmek için açık kaynaklı bir veritabanı olan Chroma DB’yi anlatacağım. Belgeleri nasıl ekleyip kaldıracağınızı, benzerlik aramaları yapmayı ve metni gömlemelere dönüştürmeyi öğreneceksiniz.

Görsel: yazar
Özet (TL;DR)
- ChromaDB, gömlemeleri depolamak ve almak için açık kaynaklı bir vektör veritabanıdır—
pip install chromadbile kurun - Yerel kalıcılık için
chromadb.PersistentClient(path="./chroma_db"), bellek içi test içinchromadb.EphemeralClient()kullanın - Bir koleksiyon (tablaya benzer) oluşturun, ardından isteğe bağlı üstveri ve kimliklerle
add()ile belgeler ekleyin collection.query(query_texts=["..."], n_results=5)ile anlamsal benzerlik araması yapın- Herhangi bir gömleme modelini bağlayın—OpenAI, HuggingFace, Google Gemini veya özel bir işlev
- ChromaDB, RAG (Retrieval-Augmented Generation) boru hatlarında yaygın olarak vektör deposu olarak kullanılır
Vektör Depoları Nedir?
Vektör depoları, vektör gömlemelerini verimli şekilde depolamak ve almak üzere özel olarak tasarlanmış veritabanlarıdır. Gerekli olmalarının nedeni, SQL gibi geleneksel veritabanlarının büyük vektör verilerini depolama ve sorgulama için optimize edilmemiş olmasıdır.
Gömlemeler, verileri (genellikle metin gibi yapılandırılmamış verileri) yüksek boyutlu bir uzayda sayısal vektör biçimlerinde temsil eder. Geleneksel ilişkisel veritabanları bu vektör temsillerini depolamak ve aramak için pek uygun değildir.
Vektör depoları, benzerlik algoritmalarını kullanarak benzer vektörleri indeksleyip hızlıca arayabilir; bu da uygulamaların hedef bir vektör sorgusu verildiğinde ilişkili vektörleri bulmasını sağlar.
Örneğin, kişiselleştirilmiş bir sohbet botunda kullanıcı üretken yapay zekâ modeline bir istem girer. Benzerlik arama algoritması kullanılarak model, bir belge koleksiyonu içinde benzer metinleri arar. Elde edilen bilgiler, son derece kişiselleştirilmiş ve doğru bir yanıt üretmek için kullanılır. Bu bilginin geri getirimi, vektör depoları içinde gömleme ve vektör indeksleme sayesinde mümkün olur.
Chroma DB Nedir?
Chroma DB, vektör gömlemelerini depolamak ve almak için kullanılan açık kaynaklı bir vektör deposudur. Ana kullanım amacı, gömlemeleri üstverilerle birlikte kaydedip daha sonra büyük dil modelleri tarafından kullanılmasını sağlamaktır. Ek olarak, metin verileri üzerinde anlamsal arama motorları için de kullanılabilir.
Chroma DB özellikleri
- Basit ve güçlü:
- Basit bir komutla kurun:
pip install chromadb. - Python SDK ile hızlı başlangıç; zahmetsiz entegrasyon ve hızlı kurulum.
- Basit bir komutla kurun:
- Tam özellikli:
- Kapsamlı getirimi: Vektör arama, tam metin arama, belge depolama, üstveri filtreleme ve çok modlu getirim içerir.
- Yüksek ölçeklenebilirlik: Yerel kalıcı depolama için SQLite kullanır ve çoklu istemci ile üretim dağıtımları için istemci-sunucu modunu destekler.
- Çoklu dil desteği:
- Python, JavaScript/TypeScript, Ruby, PHP ve Java dahil popüler programlama dilleri için SDK’lar sunar.
- Entegre:
- HuggingFace, OpenAI, Google ve daha birçok sağlayıcının gömleme modelleriyle doğal entegrasyon.
- Langchain ve LlamaIndex ile uyumlu; yakında daha fazla araç entegrasyonu gelecek.
- Açık kaynak:
- Apache 2.0 lisansı altında.
- Hız ve sadelik:
- Kullanımı sezgisel olacak şekilde tasarlanmış; analizi ve getirimi verimli kılmaya odaklanır.
Chroma DB, kendi kendine barındırılan bir sunucu seçeneği sunar. Yönetilen veya bulut-yerel bir vektör veritabanına ihtiyacınız varsa, alternatif çözümler olarak Pinecone ile Vektör Veritabanlarında Ustalaşma veya Weaviate rehberlerimizi inceleyin.
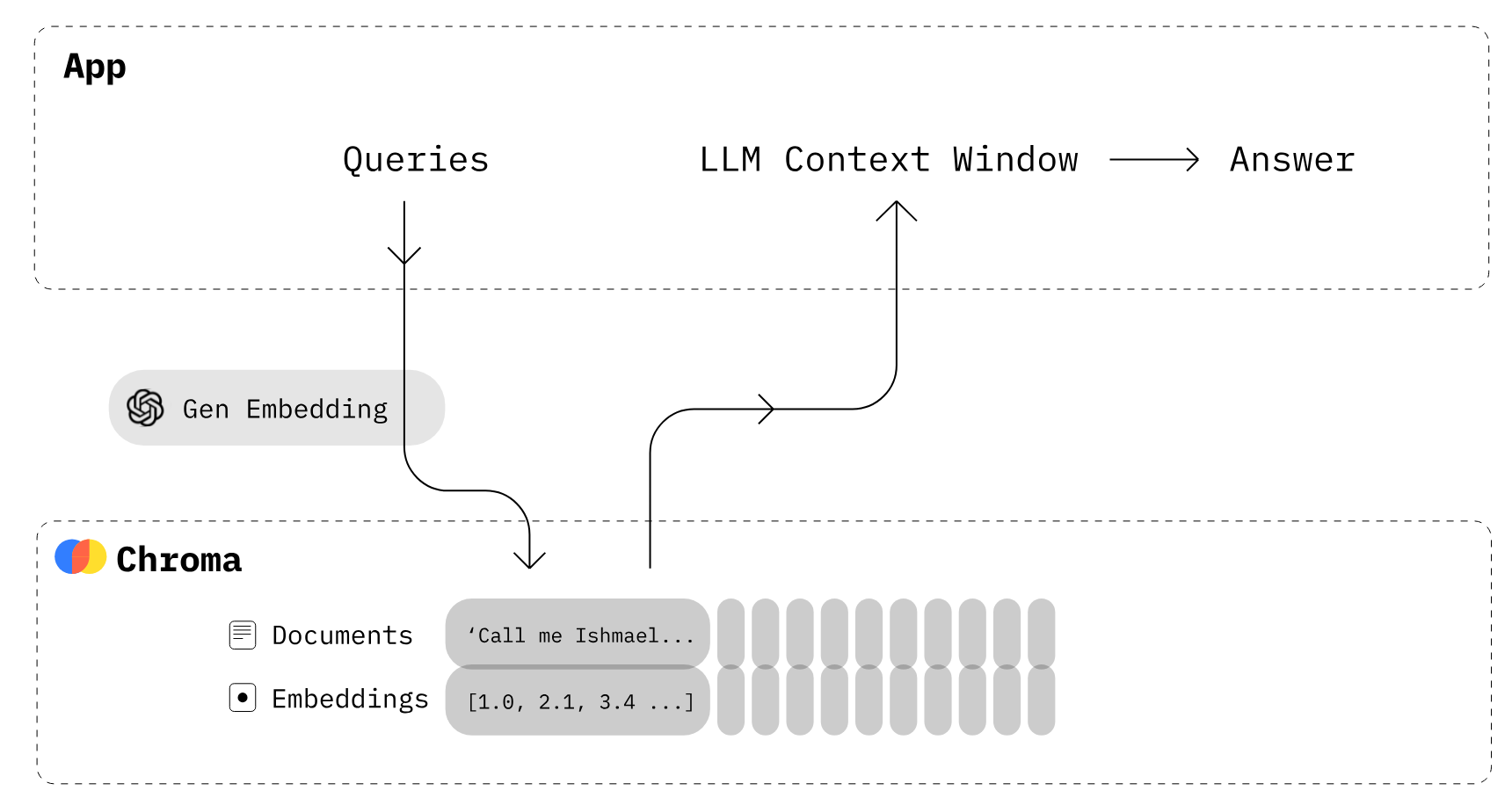
Görsel: Chroma
Chroma DB nasıl çalışır?
- Önce, ilişkisel veritabanındaki tablolara benzer bir koleksiyon oluşturmanız gerekir. Varsayılan olarak Chroma, metni
all-MiniLM-L6-v2kullanarak gömlemelere dönüştürür; ancak koleksiyonu başka bir gömleme modelini kullanacak şekilde değiştirebilirsiniz. - Yeni oluşturulan koleksiyona üstveri ve benzersiz bir kimlikle metin belgeleri ekleyin. Koleksiyon metni aldığında otomatik olarak gömlemeye dönüştürür.
- Benzer belgeleri almak için koleksiyonu metinle veya gömlemeyle sorgulayın. Sonuçları üstveriye göre de filtreleyebilirsiniz.
Önkoşullar
Bu eğitimi takip etmek için şunlara ihtiyacınız olacak:
- Python 3.8+ (en iyi ChromaDB uyumluluğu için Python 3.11 önerilir)
- pip paket yöneticisi
- OpenAI API anahtarı (yalnızca Gömlemeler bölümü için gereklidir; temel ChromaDB bölümleri onsuz da çalışır)
- SQLite 3.35 veya daha yenisi (Python 3.11’e gömülüdür; eski bir sürümde sorun yaşarsanız
pip install pysqlite3-binarykullanın) - Python listeleri ve sözlüklerine temel düzeyde aşinalık
Chroma DB ile Başlangıç
Bu bölümde bir vektör veritabanı oluşturacak, bir koleksiyon ekleyip içine metin yükleyecek ve bir benzerlik araması sorgusu çalıştıracağım.
Önce chromadb ve openai kurun. OpenAI API anahtarı yalnızca Gömlemeler bölümü için gereklidir—aşağıdaki temel ChromaDB örnekleri onsuz da çalışır.
Not: Chroma, SQLite 3.35 veya daha yenisini gerektirir. Sorun yaşarsanız Python 3.11’e yükseltin veya chromadb’nin daha eski bir sürümünü yükleyin.
!pip install chromadb openai İstemci modu seçimi
ChromaDB, kullanım durumunuza göre üç istemci modu sağlar:
| Client | Use case | Code |
|---|---|---|
| EphemeralClient | Bellek içi test; çıkışta veriler kaybolur | chromadb.EphemeralClient() |
| PersistentClient | Yerel dosya depolama; veriler yeniden başlatmalarda kalıcıdır | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Üretim; çalışan bir ChromaDB sunucusuna bağlanır | chromadb.HttpClient(host="localhost", port=8000) |
chromadb.EphemeralClient() kullanarak test için bellek içi (geçici) bir veritabanı oluşturabilirsiniz. Bu, verileri yalnızca bellekte tutar ve program bittiğinde sıfırlanır—hızlı denemeler için idealdir.
Bu örnekte, ./chroma_db dizininde depolanan kalıcı bir veritabanı oluşturacağım. ChromaDB, kalıcı modda SQLite destekli depolama kullanır—DuckDB arka ucu ChromaDB 0.4.0’da kaldırılmıştır.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")Ardından, istemciyi kullanarak bir collection nesnesi oluşturacağız. Bu, geleneksel bir veritabanında tablo oluşturmaya benzer.
collection = client.create_collection(name="Students")Koleksiyonumuza metin eklemek için bir öğrenci, kulüp ve üniversite hakkında rastgele metin oluşturacağız. Rastgele metin üretmek için ChatGPT kullanabilirsiniz.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Şimdi, add() işlevini kullanarak üstveri ve benzersiz kimliklerle metin verilerini ekleyeceğiz. Bundan sonra Chroma, metni gömlemelere dönüştürmek için all-MiniLM-L6-v2 modelini otomatik olarak indirir ve "Students" koleksiyonunda saklar.
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Benzerlik araması çalıştırmak için query() işlevini kullanabilir ve doğal dilde sorular sorabilirsiniz. Sorguyu gömlemeye dönüştürür ve benzer sonuçlar üretmek için benzerlik algoritmalarını kullanır. Bizim örneğimizde iki benzer sonuç döndürüyor.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Gömlemeler
gömleme listesindeki yüksek performanslı herhangi bir gömleme modelini kullanabilirsiniz. Hatta kendi özel gömleme işlevlerinizi de oluşturabilirsiniz. OpenAI’nin güncel nesil modellerine derin bir bakış için text-embedding-3-large rehberimize bakın.
Bu bölümde, metni gömlemelere dönüştürmek için OpenAI’nin text-embedding-3-small modelini kullanacağım. Bu model, eski text-embedding-ada-002 için OpenAI’nin önerdiği ikamedir—karşılaştırma ölçütlerinde daha iyi performansı 5 kat daha düşük maliyetle sağlar.
OpenAI gömleme işlevini oluşturduktan sonra, gömlemeler üretmek için metin belgeleri listesini ekleyebilirsiniz.
OpenAI API ile Metin Gömlemelerini nasıl kullanacağınızı keşfedin; metin sınıflandırıcıları, bilgi getirim sistemleri ve anlamsal benzerlik algılayıcıları oluşturun.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Varsayılan gömleme modelini kullanmak yerine, önceden üretilmiş gömlemeleri doğrudan yeni bir koleksiyona yükleyeceğim.
- "Students2" adlı yeni bir koleksiyon oluşturmak için
get_or_create_collection()işlevini kullanacağız. Bu işlev,create_collection()’dan farklıdır. Mevcutsa koleksiyonu getirir, değilse oluşturur. - Şimdi yeni oluşturulan koleksiyonumuza gömleme, metin belgeleri, üstveri ve kimlikler ekleyeceğiz.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Daha da yalın bir yöntem daha var. Koleksiyonu oluştururken veya erişirken bir OpenAI gömleme işlevi ekleyebilirsiniz. OpenAI’nin yanı sıra Cohere, Google Gemini, HuggingFace ve Instructor modellerini de kullanabilirsiniz.
Bizim örneğimizde, yeni metin belgeleri eklemek metni gömlemelere dönüştürmek için varsayılan model yerine bir OpenAI gömleme işlevini çalıştıracaktır.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Benzer bir sorguyu yeni koleksiyon üzerinde çalıştırarak farkı görelim.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsSonuçlarımız iyileşti. Benzerlik araması artık bir kulüp yerine üniversiteye ilişkin bilgiler döndürüyor. Ayrıca, vektörler arasındaki mesafe varsayılan gömleme modeline kıyasla daha düşük; bu da olumlu bir durum.

Sonuçları Filtreleme
ChromaDB, benzerlik araması sonuçlarını daraltmak için üstveri filtrelemeyi destekler. query() içinde filtre operatörleriyle birlikte where parametresini kullanın:
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Desteklenen operatörler: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Belge içeriğinde de where_document={"$contains": "chess"} ile filtreleme yapabilirsiniz.
Verileri Güncelleme ve Kaldırma
İlişkisel veritabanlarında olduğu gibi, koleksiyonlardaki değerleri güncelleyebilir veya kaldırabilirsiniz. Metni ve üstveriyi güncellemek için kayıt için belirli kimliği ve yeni metni sağlayacağız.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Değişikliklerin başarıyla yapılıp yapılmadığını kontrol etmek için basit bir sorgu çalıştırın.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsGörüldüğü gibi, Alexandra yerine Kristiane sonucunu aldık.

Koleksiyondan bir kaydı kaldırmak için delete() işlevini ve benzersiz kimliği kullanacağız.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsÖğrenci bilgisi metni kaldırıldı; bunun yerine bir sonraki en iyi sonuçları alıyoruz.

Koleksiyon Yönetimi
Bu bölümde, koleksiyonları sayma, listeleme, yeniden adlandırma ve silme için yardımcı işlevleri ele alacağım.
"vectordb" adlı yeni bir koleksiyon oluşturacak ve Chroma DB kopya kâğıdı, dokümantasyon ve JS API hakkında bilgileri üstverileriyle birlikte ekleyeceğiz.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)count() işlevini kullanarak koleksiyonun kaç kaydı olduğunu kontrol edeceğiz.
vector_collections.count()3Koleksiyondaki tüm kayıtları görüntülemek için get() işlevini kullanın.
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Koleksiyon adını değiştirmek için modify() işlevini kullanın. Tüm koleksiyon adlarını görüntülemek için list_collections() kullanın.
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Görünüşe göre "vectordb" adını başarıyla "chroma_info" olarak yeniden adlandırdık.
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Yeni bir koleksiyona erişmek için, koleksiyonun adıyla get_collection() kullanabilirsiniz.
vector_collections_new = client.get_collection(name="chroma_info")delete_collection() istemci işlevini kullanarak bir koleksiyonu silebilir ve koleksiyon adını belirtebilirsiniz.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]client.reset() kullanarak tüm veritabanı koleksiyonlarını silebiliriz. Ancak geri dönüşü olmadığından önerilmez.
client.reset()
client.list_collections()[]LangChain ile ChromaDB: Bir RAG Örneği
ChromaDB’nin en yaygın entegrasyonlarından biri, RAG uygulamaları oluşturmak için LangChain ile birliktedir. İşte ChromaDB’yi vektör deposu olarak kullanan en basit örneklerden biri:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)FastAPI ile üretim düzeyinde bir RAG boru hattı için LangChain ve FastAPI ile RAG Sistemi Kurma eğitimimize bakın. DeepSeek kullanan bir örnek için Chroma ile DeepSeek R1 RAG Sohbet Botu eğitimimize göz atın.
Sonuç
Chroma DB gibi vektör depoları, büyük dil modeli sistemlerinin temel bileşenleri hâline geliyor. Vektör gömlemeleri için özel depolama ve verimli getirim sağlayarak, LLM’leri desteklemek için ilgili anlamsal bilgilere hızlı erişim sunarlar.
Bu Chroma DB eğitiminde, bir koleksiyon oluşturmanın, belgeler eklemenin, metni gömlemelere dönüştürmenin, anlamsal benzerlik için sorgulamanın ve koleksiyonları yönetmenin temellerini ele aldık.
Doğal bir sonraki adım, vektör deposu olarak ChromaDB’yi kullanan bir Erişimle Zenginleştirilmiş Üretim (RAG) uygulaması kurmaktır. Üretime hazır bir boru hattı için LangChain ve FastAPI ile RAG Sistemi Kurma eğitimimizle başlayın veya gelişmiş ajan odaklı getirim iş akışları için Agentic RAG’i keşfedin. Ayrıca, LlamaIndex ile özel verileri LLM’lere alabilir veya tam uygulama geliştirme için LangChain LLM eğitimini takip edebilirsiniz.

