Met de opkomst van large language models (LLM’s) en hun toepassingen zien we een groei in de populariteit van integratietools, LLMOps-frameworks en vectordatabases. Dat komt omdat werken met LLM’s een andere aanpak vraagt dan werken met traditionele machinelearningmodellen.
Een van de kerntechnologieën achter LLM’s zijn vector-embeddings. Computers kunnen tekst niet rechtstreeks begrijpen, maar embeddings representeren tekst numeriek. Alle door de gebruiker aangeleverde tekst wordt omgezet naar embeddings, die vervolgens gebruikt worden om antwoorden te genereren.
Tekst omzetten naar embeddings kost tijd. Om dat te vermijden, zijn er vectordatabases die expliciet zijn ontworpen voor efficiënte opslag en het snel ophalen van vector-embeddings.
In deze tutorial neem ik je mee door vector stores en Chroma DB, een open-source database voor het opslaan en beheren van embeddings. Je leert hoe je documenten toevoegt en verwijdert, similariteitszoekopdrachten uitvoert en tekst omzet in embeddings.

Afbeelding door de auteur
TL;DR
- ChromaDB is een open-source vectordatabase voor het opslaan en ophalen van embeddings—installeer met
pip install chromadb - Gebruik
chromadb.PersistentClient(path="./chroma_db")voor lokale persistentie ofchromadb.EphemeralClient()voor in-memory testen - Maak een collectie (vergelijkbaar met een tabel) en voeg vervolgens documenten toe met
add(), optioneel met metadata en ID’s - Draai semantische similariteitszoekopdrachten met
collection.query(query_texts=["..."], n_results=5) - Koppel elk embeddingmodel—OpenAI, HuggingFace, Google Gemini of een eigen functie
- ChromaDB wordt veel gebruikt als vector store in RAG (Retrieval-Augmented Generation)-pijplijnen
Wat zijn vector stores?
Vector stores zijn databases die expliciet zijn ontworpen voor het efficiënt opslaan en ophalen van vector-embeddings. Ze zijn nodig omdat traditionele databases zoals SQL niet geoptimaliseerd zijn voor het opslaan en query’en van grote hoeveelheden vectordata.
Embeddings representeren data (meestal ongestructureerde data zoals tekst) als numerieke vectoren in een hoog-dimensionale ruimte. Traditionele relationele databases zijn minder geschikt voor het opslaan en doorzoeken van deze vectorrepresentaties.
Vector stores kunnen indexeren en snel zoeken naar vergelijkbare vectoren met similariteitsalgoritmen, waardoor toepassingen gerelateerde vectoren kunnen vinden op basis van een doelvector-query.
Bijvoorbeeld, in het geval van een gepersonaliseerde chatbot geeft de gebruiker een prompt aan het generatieve AI-model. Met een similariteitszoekalgoritme zoekt het model naar vergelijkbare tekst binnen een verzameling documenten. De resulterende informatie wordt vervolgens gebruikt om een sterk gepersonaliseerd en accuraat antwoord te genereren. Deze retrieval van informatie is mogelijk door embedding en vectorindexering binnen vector stores.
Wat is Chroma DB?
Chroma DB is een open-source vector store die wordt gebruikt voor het opslaan en ophalen van vector-embeddings. De belangrijkste toepassing is het opslaan van embeddings met metadata, zodat grote taalmodellen ze later kunnen gebruiken. Daarnaast kan het ook worden ingezet voor semantische zoekmachines over tekstdata.
Chroma DB-functies
- Eenvoudig en krachtig:
- Installeren met één simpele opdracht:
pip install chromadb. - Snel starten met de Python SDK, voor naadloze integratie en snelle setup.
- Installeren met één simpele opdracht:
- Volledig uitgerust:
- Uitgebreide retrievalfuncties: Bevat vector search, full-text search, documentopslag, metadatafiltering en multimodale retrieval.
- Zeer schaalbaar: Gebruikt SQLite voor lokale persistente opslag en ondersteunt een client-servermodus voor meerdere clients en productieomgevingen.
- Meertalige ondersteuning:
- Biedt SDK’s voor populaire programmeertalen, waaronder Python, JavaScript/TypeScript, Ruby, PHP en Java.
- Geïntegreerd:
- Native integratie met embeddingmodellen van HuggingFace, OpenAI, Google en meer.
- Compatibel met Langchain en LlamaIndex; meer toolintegraties volgen snel.
- Open source:
- Gelicenseerd onder Apache 2.0.
- Snelheid en eenvoud:
- Richt zich op eenvoud en snelheid; ontworpen om analyse en retrieval efficiënt en intuïtief te maken.
Chroma DB biedt een zelfgehoste serveroptie. Heb je een beheerde of cloud-native vectordatabase nodig, bekijk dan onze gidsen over Mastering Vector Databases met Pinecone of Weaviate als alternatieve oplossingen.
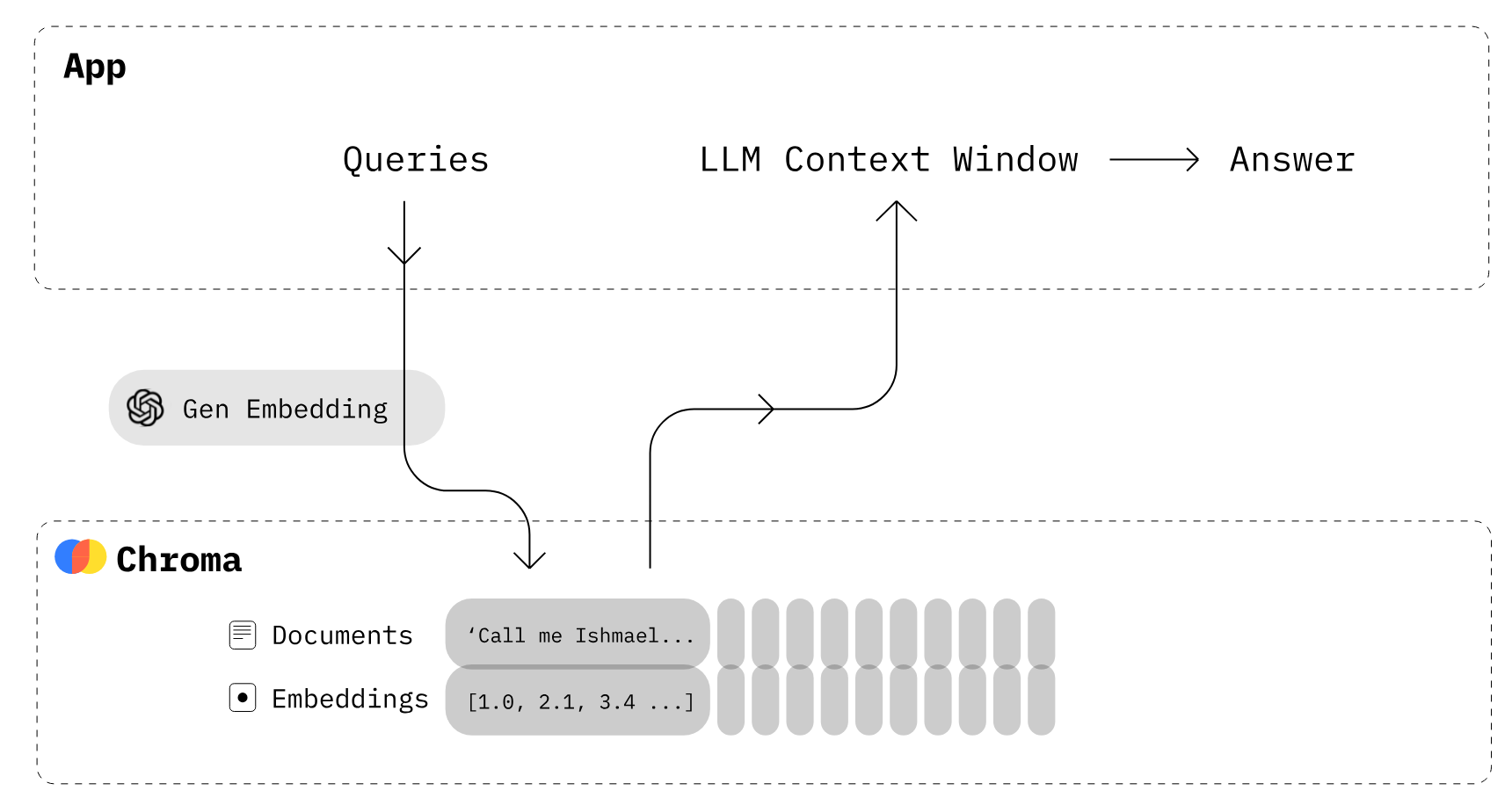
Afbeelding van Chroma
Hoe werkt Chroma DB?
- Eerst maak je een collectie, vergelijkbaar met tabellen in relationele databases. Standaard zet Chroma de tekst om in embeddings met
all-MiniLM-L6-v2, maar je kunt de collectie aanpassen om een ander embeddingmodel te gebruiken. - Voeg tekstdocumenten met metadata en een unieke ID toe aan de nieuw aangemaakte collectie. Wanneer je collectie de tekst ontvangt, zet deze die automatisch om in embeddings.
- Query de collectie op tekst of embedding om vergelijkbare documenten te ontvangen. Je kunt resultaten ook filteren op basis van metadata.
Vereisten
Om deze tutorial te volgen, heb je nodig:
- Python 3.8+ (Python 3.11 aanbevolen voor de beste ChromaDB-compatibiliteit)
- pip package manager
- Een OpenAI API-sleutel (alleen nodig voor de Embeddings-sectie; de kernsecties van ChromaDB werken zonder)
- SQLite 3.35 of hoger (ingebouwd in Python 3.11; als je op een oudere versie zit en problemen tegenkomt, gebruik
pip install pysqlite3-binary) - Basiskennis van Python-lijsten en -dicts
Aan de slag met Chroma DB
In deze sectie maak ik een vectordatabase, voeg ik een collectie toe, laad ik er tekst in en voer ik een similariteitszoekopdracht uit.
Installeer eerst chromadb en openai. Je hebt alleen een OpenAI API-sleutel nodig voor de Embeddings-sectie—de kernvoorbeelden van ChromaDB hieronder werken zonder.
Let op: Chroma vereist SQLite versie 3.35 of hoger. Als je problemen ervaart, upgrade dan naar Python 3.11 of installeer een oudere versie van chromadb.
!pip install chromadb openai Een clientmodus kiezen
ChromaDB biedt drie clientmodi afhankelijk van je usecase:
| Client | Usecase | Code |
|---|---|---|
| EphemeralClient | In-memory testen; data gaat verloren bij afsluiten | chromadb.EphemeralClient() |
| PersistentClient | Lokale bestandsopslag; data blijft behouden na herstart | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Productie; maakt verbinding met een draaiende ChromaDB-server | chromadb.HttpClient(host="localhost", port=8000) |
Je kunt voor testen een in-memory (ephemere) database maken met chromadb.EphemeralClient(). Dit slaat data alleen in het geheugen op en wordt gereset zodra het programma eindigt—perfect voor snelle experimenten.
In dit voorbeeld maak ik een persistente database die wordt opgeslagen in de map ./chroma_db. ChromaDB gebruikt in persistente modus opslag op basis van SQLite—de DuckDB-backend is verwijderd in ChromaDB 0.4.0.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")Daarna maken we een collection-object met de client. Dit lijkt op het aanmaken van een tabel in een traditionele database.
collection = client.create_collection(name="Students")Om tekst aan onze collectie toe te voegen, genereren we willekeurige tekst over een student, club en universiteit. Je kunt willekeurige tekst genereren met ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Nu gebruiken we de functie add() om tekstdata toe te voegen met metadata en unieke ID’s. Daarna zal Chroma automatisch het model all-MiniLM-L6-v2 downloaden om de tekst om te zetten in embeddings en op te slaan in de "Students"-collectie.
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Om een similariteitszoekopdracht uit te voeren, kun je de functie query() gebruiken en vragen stellen in gewone taal. De query wordt omgezet naar embeddings en gebruikt similariteitsalgoritmen om vergelijkbare resultaten te vinden. In ons geval geeft het twee vergelijkbare resultaten terug.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embeddings
Je kunt elk performant embeddingmodel uit de embeddinglijst gebruiken. Je kunt zelfs je eigen embeddingfuncties maken. Voor een deep dive in OpenAI’s huidige generatie modellen, zie onze gids over text-embedding-3-large.
In deze sectie gebruik ik OpenAI’s text-embedding-3-small-model om tekst om te zetten in embeddings. Dit is OpenAI’s aanbevolen vervanger voor de verouderde text-embedding-ada-002—het levert betere benchmarkprestaties tegen 5× lagere kosten.
Na het aanmaken van de OpenAI-embeddingfunctie kun je de lijst met tekstdocumenten toevoegen om embeddings te genereren.
Ontdek hoe je de OpenAI API voor tekste mbeddings gebruikt en maak tekstclassificaties, informatieretrievalsystemen en detectors voor semantische similariteit.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]In plaats van het standaard embeddingmodel te gebruiken, laad ik de al gegenereerde embeddings direct in een nieuwe collectie.
- We gebruiken de functie
get_or_create_collection()om een nieuwe collectie "Students2" te maken. Deze functie verschilt vancreate_collection(). Hij haalt een collectie op, of maakt hem aan als die nog niet bestaat. - We voegen nu embeddings, tekstdocumenten, metadata en ID’s toe aan onze nieuw aangemaakte collectie.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Er is ook een andere, nog eenvoudigere methode. Je kunt een OpenAI-embeddingfunctie toevoegen tijdens het maken of benaderen van de collectie. Naast OpenAI kun je ook Cohere, Google Gemini, HuggingFace en Instructor-modellen gebruiken.
In ons geval zal het toevoegen van nieuwe tekstdocumenten een OpenAI-embeddingfunctie draaien in plaats van het standaardmodel om tekst om te zetten in embeddings.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Laten we het verschil bekijken door een vergelijkbare query op de nieuwe collectie uit te voeren.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsOnze resultaten zijn verbeterd. De similariteitszoekopdracht geeft nu informatie over de universiteit in plaats van een club. Daarnaast is de afstand tussen de vectoren lager dan bij het standaard embeddingmodel, wat gunstig is.

Queryresultaten filteren
ChromaDB ondersteunt metadatafiltering om similariteitsresultaten te verfijnen. Gebruik de parameter where met filteroperators binnen query():
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Ondersteunde operators: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Je kunt ook filteren op documentinhoud met where_document={"$contains": "chess"}.
Data bijwerken en verwijderen
Net als bij relationele databases kun je waarden in collecties bijwerken of verwijderen. Om tekst en metadata bij te werken, geven we de specifieke ID van het record en de nieuwe tekst op.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Voer een eenvoudige query uit om te controleren of de wijzigingen succesvol zijn doorgevoerd.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsZoals we zien, kregen we in plaats van Alexandra nu Kristiane.

Om een record uit de collectie te verwijderen, gebruiken we de functie delete() en geven we een unieke ID op.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsDe tekst met studentinformatie is verwijderd; in plaats daarvan krijgen we de volgende beste resultaten.

Collectiebeheer
In deze sectie behandel ik de hulpfuncties voor collecties om collecties te tellen, op te sommen, hernoemen en verwijderen.
We maken een nieuwe collectie genaamd "vectordb" en voegen informatie toe over de Chroma DB-cheatsheet, documentatie en JS API met metadata.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)We gebruiken de functie count() om te controleren hoeveel records de collectie heeft.
vector_collections.count()3Gebruik de functie get() om alle records uit de collectie te bekijken.
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Gebruik modify() om de naam van de collectie te wijzigen. Gebruik list_collections() om alle collectienamen te bekijken.
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Het lijkt erop dat we "vectordb" succesvol hebben hernoemd naar "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Om een nieuwe collectie te benaderen, kun je get_collection() gebruiken met de naam van de collectie.
vector_collections_new = client.get_collection(name="chroma_info")We kunnen een collectie verwijderen met de clientfunctie delete_collection() en de naam van de collectie opgeven.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]We kunnen de hele databasecollectie verwijderen met client.reset(). Dit wordt echter niet aanbevolen, omdat er geen manier is om de data na verwijdering te herstellen.
client.reset()
client.list_collections()[]ChromaDB met LangChain: een RAG-voorbeeld
Een van de meest voorkomende ChromaDB-integraties is met LangChain om RAG-applicaties te bouwen. Hier is een minimaal voorbeeld met ChromaDB als vector store:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)Voor een volledige, production-ready RAG-pijplijn met FastAPI, zie onze tutorial Building a RAG System with LangChain and FastAPI. Voor een voorbeeld met DeepSeek, bekijk onze tutorial DeepSeek R1 RAG Chatbot with Chroma.
Conclusie
Vector stores zoals Chroma DB worden essentiële bouwstenen van systemen met grote taalmodellen. Door gespecialiseerde opslag en efficiënte retrieval van vector-embeddings te bieden, maken ze snelle toegang tot relevante semantische informatie mogelijk om LLM’s aan te sturen.
In deze Chroma DB-tutorial bespraken we de basis van het maken van een collectie, het toevoegen van documenten, het omzetten van tekst naar embeddings, het uitvoeren van semantische query’s en het beheren van collecties.
De logische volgende stap is het bouwen van een Retrieval-Augmented Generation (RAG)-applicatie met ChromaDB als vector store. Begin met onze tutorial Building a RAG System with LangChain and FastAPI voor een production-ready pijplijn, of verken Agentic RAG voor geavanceerde, agentgestuurde retrieval-workflows. Je kunt ook LlamaIndex gebruiken om privédata in LLM’s te laden, of volg de LangChain LLM-tutorial voor volledige applicatieontwikkeling.

