Con l’ascesa dei large language model (LLM) e delle loro applicazioni, abbiamo visto aumentare la popolarità di strumenti di integrazione, framework LLMOps e database vettoriali. Questo perché lavorare con gli LLM richiede un approccio diverso rispetto ai modelli di machine learning tradizionali.
Una delle tecnologie abilitanti fondamentali per gli LLM sono gli embedding vettoriali. Poiché i computer non possono comprendere direttamente il testo, gli embedding rappresentano il testo in forma numerica. Tutto il testo fornito dall’utente viene convertito in embedding, che sono poi usati per generare le risposte.
Convertire il testo in embedding è un processo che richiede tempo. Per evitarlo, esistono database vettoriali progettati espressamente per l’archiviazione e il recupero efficienti degli embedding.
In questo tutorial, vedremo i vector store e Chroma DB, un database open source per archiviare e gestire gli embedding. Imparerai ad aggiungere e rimuovere documenti, eseguire ricerche per similarità e convertire il testo in embedding.

Immagine dell’autore
TL;DR
- ChromaDB è un database vettoriale open source per archiviare e recuperare embedding—installalo con
pip install chromadb - Usa
chromadb.PersistentClient(path="./chroma_db")per la persistenza locale oppurechromadb.EphemeralClient()per test in memoria - Crea una collection (analoga a una tabella), quindi
add()documenti con metadati e ID facoltativi - Esegui ricerche di similarità semantica con
collection.query(query_texts=["..."], n_results=5) - Collega qualsiasi modello di embedding—OpenAI, HuggingFace, Google Gemini o una funzione personalizzata
- ChromaDB è ampiamente usato come vector store nelle pipeline di RAG (Retrieval-Augmented Generation)
Cosa sono i vector store?
I vector store sono database progettati espressamente per archiviare e recuperare in modo efficiente gli embedding vettoriali. Sono necessari perché i database tradizionali come SQL non sono ottimizzati per memorizzare e interrogare grandi quantità di dati vettoriali.
Gli embedding rappresentano i dati (di solito non strutturati, come il testo) in formati vettoriali numerici in uno spazio ad alta dimensionalità. I database relazionali tradizionali non sono adatti a memorizzare e cercare queste rappresentazioni vettoriali.
I vector store possono indicizzare e cercare rapidamente vettori simili usando algoritmi di similarità, consentendo alle applicazioni di trovare vettori correlati a partire da una query vettoriale di riferimento.
Per esempio, nel caso di un chatbot personalizzato, l’utente inserisce un prompt per il modello generativo. Usando un algoritmo di ricerca per similarità, il modello cerca testo simile all’interno di una raccolta di documenti. Le informazioni risultanti vengono poi usate per generare una risposta altamente personalizzata e accurata. Questo recupero di informazioni è reso possibile tramite embedding e indicizzazione vettoriale all’interno dei vector store.
Che cos’è Chroma DB?
Chroma DB è un vector store open source usato per archiviare e recuperare embedding vettoriali. Il suo uso principale è salvare gli embedding insieme ai metadati per essere poi utilizzati dai large language model. Inoltre, può essere utilizzato anche per motori di ricerca semantica su dati testuali.
Funzionalità di Chroma DB
- Semplice e potente:
- Installazione con un solo comando:
pip install chromadb. - Avvio rapido con Python SDK, per un’integrazione fluida e una configurazione veloce.
- Installazione con un solo comando:
- Completo di funzionalità:
- Funzioni di retrieval complete: include ricerca vettoriale, full‑text search, archiviazione documenti, filtraggio per metadati e retrieval multimodale.
- Altamente scalabile: usa SQLite per l’archiviazione persistente locale e supporta una modalità client‑server per deploy multi‑client e in produzione.
- Supporto multi‑linguaggio:
- Offre SDK per i linguaggi più diffusi, tra cui Python, JavaScript/TypeScript, Ruby, PHP e Java.
- Integrato:
- Integrazione nativa con modelli di embedding di HuggingFace, OpenAI, Google e altri.
- Compatibile con Langchain e LlamaIndex, con ulteriori integrazioni in arrivo.
- Open source:
- Licenza Apache 2.0.
- Velocità e semplicità:
- Si concentra su semplicità e rapidità, progettato per rendere analisi e retrieval efficienti e allo stesso tempo intuitivi da usare.
Chroma DB offre un’opzione server self‑hosted. Se ti serve un database vettoriale gestito o cloud‑native, consulta le nostre guide su Pinecone o Weaviate come soluzioni alternative.
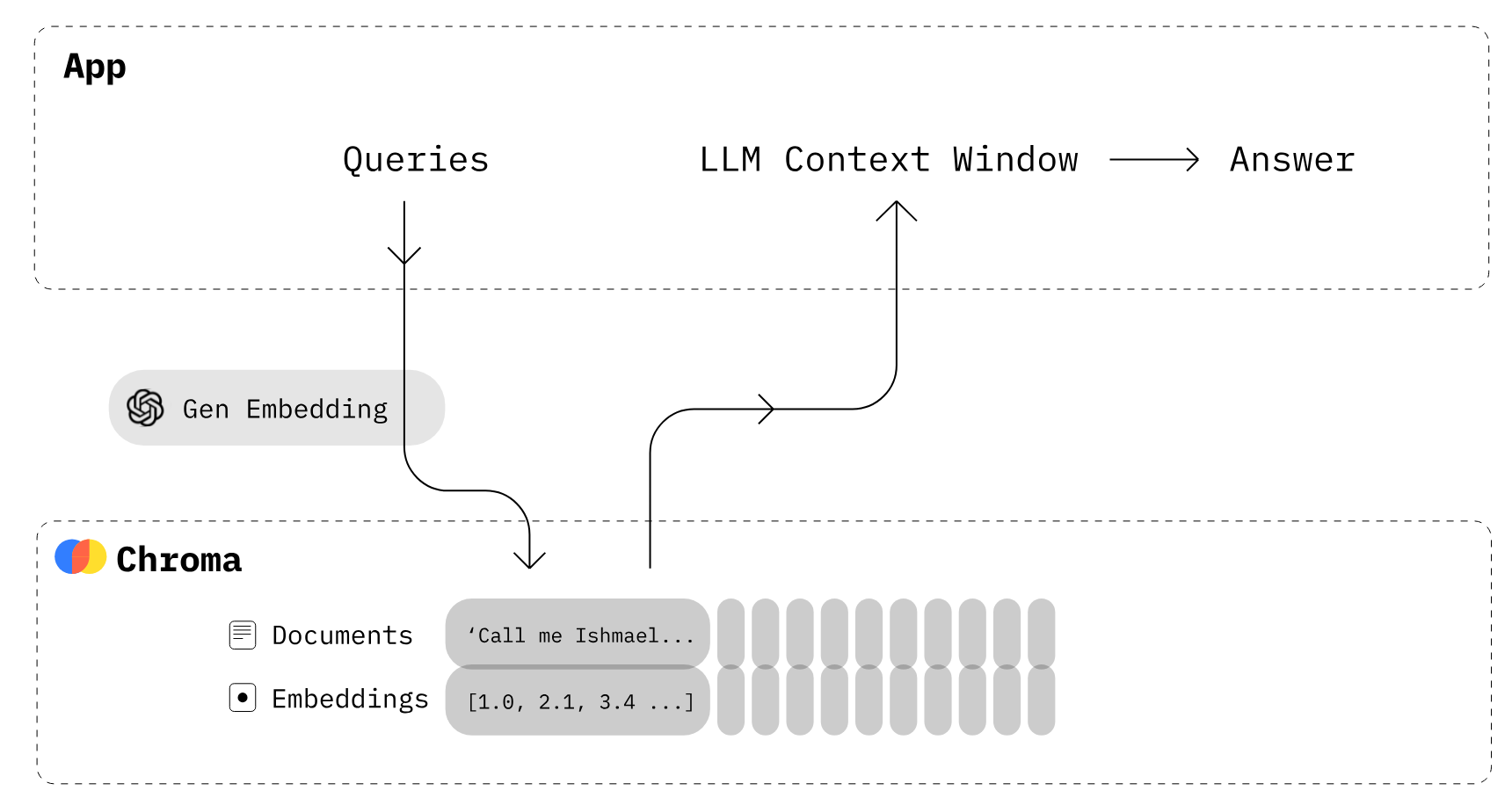
Immagine da Chroma
Come funziona Chroma DB?
- Per prima cosa, devi creare una collection simile alle tabelle nei database relazionali. Per impostazione predefinita, Chroma converte il testo in embedding usando
all-MiniLM-L6-v2, ma puoi modificare la collection per usare un altro modello di embedding. - Aggiungi documenti testuali con metadati e un ID univoco alla collection appena creata. Quando la collection riceve il testo, lo converte automaticamente in embedding.
- Interroga la collection per testo o embedding per ottenere documenti simili. Puoi anche filtrare i risultati in base ai metadati.
Prerequisiti
Per seguire questo tutorial, ti serviranno:
- Python 3.8+ (consigliato Python 3.11 per la massima compatibilità con ChromaDB)
- Gestore pacchetti pip
- Una chiave API OpenAI (necessaria solo per la sezione Embeddings; le sezioni principali su ChromaDB funzionano senza)
- SQLite 3.35 o superiore (integrato in Python 3.11; se usi una versione più vecchia e riscontri problemi, usa
pip install pysqlite3-binary) - Conoscenze di base di liste e dizionari in Python
Primi passi con Chroma DB
In questa sezione, creerò un database vettoriale, aggiungerò una collection, caricherò del testo e lancerò una query di similarità.
Per prima cosa, installa chromadb e openai. Ti servirà una chiave API OpenAI solo per la sezione Embeddings—gli esempi principali qui sotto su ChromaDB funzionano anche senza.
Nota: Chroma richiede SQLite versione 3.35 o superiore. Se riscontri problemi, aggiorna a Python 3.11 o installa una versione precedente di chromadb.
!pip install chromadb openai Scegliere una modalità client
ChromaDB fornisce tre modalità client in base al caso d’uso:
| Client | Uso | Codice |
|---|---|---|
| EphemeralClient | Test in memoria; i dati si perdono all’uscita | chromadb.EphemeralClient() |
| PersistentClient | Archiviazione su file locale; i dati persistono tra i riavvii | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Produzione; si connette a un server ChromaDB in esecuzione | chromadb.HttpClient(host="localhost", port=8000) |
Puoi creare un database in memoria (effimero) per i test usando chromadb.EphemeralClient(). Questo archivia i dati solo in RAM e si azzera alla fine del programma—perfetto per esperimenti rapidi.
In questo esempio, creerò un database persistente archiviato nella directory ./chroma_db. In modalità persistente, ChromaDB usa lo storage basato su SQLite—il backend DuckDB è stato rimosso in ChromaDB 0.4.0.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")Dopodiché, creeremo un oggetto collection usando il client. È simile alla creazione di una tabella in un database tradizionale.
collection = client.create_collection(name="Students")Per aggiungere testo alla nostra collection, genereremo del testo casuale su una studentessa, un club e un’università. Puoi generare testo casuale usando ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Ora useremo la funzione add() per aggiungere dati testuali con metadati e ID univoci. Dopodiché, Chroma scaricherà automaticamente il modello all-MiniLM-L6-v2 per convertire il testo in embedding e lo memorizzerà nella collection "Students".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Per eseguire una ricerca per similarità, puoi usare la funzione query() e porre domande in linguaggio naturale. La query verrà convertita in embedding e userà algoritmi di similarità per generare risultati affini. Nel nostro caso, restituisce due risultati simili.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embedding
Puoi usare qualsiasi modello di embedding ad alte prestazioni dalla lista embedding. Puoi persino creare funzioni di embedding personalizzate. Per un approfondimento sui modelli di generazione attuali di OpenAI, vedi la nostra guida su text-embedding-3-large.
In questa sezione, userò il modello text-embedding-3-small di OpenAI per convertire il testo in embedding. È il sostituto consigliato da OpenAI per il vecchio text-embedding-ada-002: offre prestazioni migliori nei benchmark a un costo 5× inferiore.
Dopo aver creato la funzione di embedding di OpenAI, puoi aggiungere l’elenco di documenti testuali per generare gli embedding.
Scopri come usare l’API OpenAI per i Text Embeddings e creare classificatori di testo, sistemi di information retrieval e rilevatori di similarità semantica.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Invece di usare il modello di embedding predefinito, caricherò direttamente gli embedding già generati in una nuova collection.
- Useremo la funzione
get_or_create_collection()per creare una nuova collection chiamata "Students2". Questa funzione è diversa dacreate_collection(): recupera una collection o la crea se non esiste già. - Ora aggiungeremo embedding, documenti testuali, metadati e ID alla nostra nuova collection.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Esiste anche un altro metodo, più diretto. Puoi aggiungere una funzione di embedding OpenAI mentre crei o accedi alla collection. Oltre a OpenAI, puoi usare i modelli Cohere, Google Gemini, HuggingFace e Instructor.
Nel nostro caso, aggiungere nuovi documenti testuali farà eseguire una funzione di embedding OpenAI invece del modello predefinito, per convertire il testo in embedding.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Vediamo la differenza eseguendo una query simile sulla nuova collection.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsI nostri risultati sono migliorati. La ricerca per similarità ora restituisce informazioni sull’università invece che sul club. Inoltre, la distanza tra i vettori è inferiore rispetto al modello di embedding predefinito, il che è positivo.

Filtrare i risultati delle query
ChromaDB supporta il filtraggio per metadati per restringere i risultati della ricerca per similarità. Usa il parametro where con gli operatori di filtro all’interno di query():
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Operatori supportati: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Puoi anche filtrare sul contenuto del documento con where_document={"$contains": "chess"}.
Aggiornare e rimuovere dati
Proprio come nei database relazionali, puoi aggiornare o rimuovere i valori dalle collection. Per aggiornare testo e metadati, forniremo l’ID specifico del record e il nuovo testo.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Esegui una semplice query per verificare che le modifiche siano state applicate correttamente.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsCome possiamo vedere, al posto di Alexandra abbiamo ottenuto Kristiane.

Per rimuovere un record dalla collection, useremo la funzione delete() e specificheremo un ID univoco.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsIl testo con le informazioni sulla studentessa è stato rimosso; al suo posto otteniamo i successivi migliori risultati.

Gestione delle collection
In questa sezione, vedremo le funzioni di utilità per contare, elencare, rinominare ed eliminare le collection.
Creeremo una nuova collection chiamata "vectordb" e aggiungeremo le informazioni sulla cheat sheet di Chroma DB, la documentazione e le API JS con metadati.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Useremo la funzione count() per verificare quanti record contiene la collection.
vector_collections.count()3Per visualizzare tutti i record della collection, usa la funzione get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Per cambiare il nome della collection, usa la funzione modify(). Per vedere tutti i nomi delle collection, usa list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Sembra che abbiamo rinominato correttamente "vectordb" in "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Per accedere a una nuova collection, puoi usare get_collection() con il nome della collection.
vector_collections_new = client.get_collection(name="chroma_info")Possiamo eliminare una collection usando la funzione del client delete_collection() e specificando il nome della collection.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Possiamo eliminare l’intero database delle collection usando client.reset(). Tuttavia, non è consigliato perché non c’è modo di ripristinare i dati dopo l’eliminazione.
client.reset()
client.list_collections()[]ChromaDB con LangChain: un esempio di RAG
Una delle integrazioni più comuni di ChromaDB è con LangChain per costruire applicazioni RAG. Ecco un esempio minimale che usa ChromaDB come vector store:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)Per una pipeline RAG pronta per la produzione con FastAPI, consulta il nostro tutorial Costruire un sistema RAG con LangChain e FastAPI. Per un esempio con DeepSeek, vedi il tutorial DeepSeek R1 RAG Chatbot con Chroma.
Conclusioni
I vector store come Chroma DB stanno diventando componenti essenziali dei sistemi basati su large language model. Fornendo un’archiviazione specializzata e un recupero efficiente degli embedding vettoriali, permettono un accesso rapido a informazioni semantiche pertinenti per alimentare gli LLM.
In questo tutorial su Chroma DB, abbiamo visto le basi per creare una collection, aggiungere documenti, convertire il testo in embedding, interrogare per similarità semantica e gestire le collection.
Il passo naturale successivo è costruire un’applicazione di Retrieval‑Augmented Generation (RAG) con ChromaDB come vector store. Inizia con il nostro tutorial Costruire un sistema RAG con LangChain e FastAPI per una pipeline pronta per la produzione, oppure esplora Agentic RAG per workflow avanzati di retrieval guidati da agent. Puoi anche usare LlamaIndex per ingerire dati privati negli LLM o seguire il tutorial su LangChain LLM per lo sviluppo completo di applicazioni.


