Cùng với sự trỗi dậy của các mô hình ngôn ngữ lớn (LLM) và ứng dụng của chúng, các công cụ tích hợp, khung LLMOps và cơ sở dữ liệu vector ngày càng phổ biến. Lý do là vì làm việc với LLM đòi hỏi cách tiếp cận khác so với các mô hình học máy truyền thống.
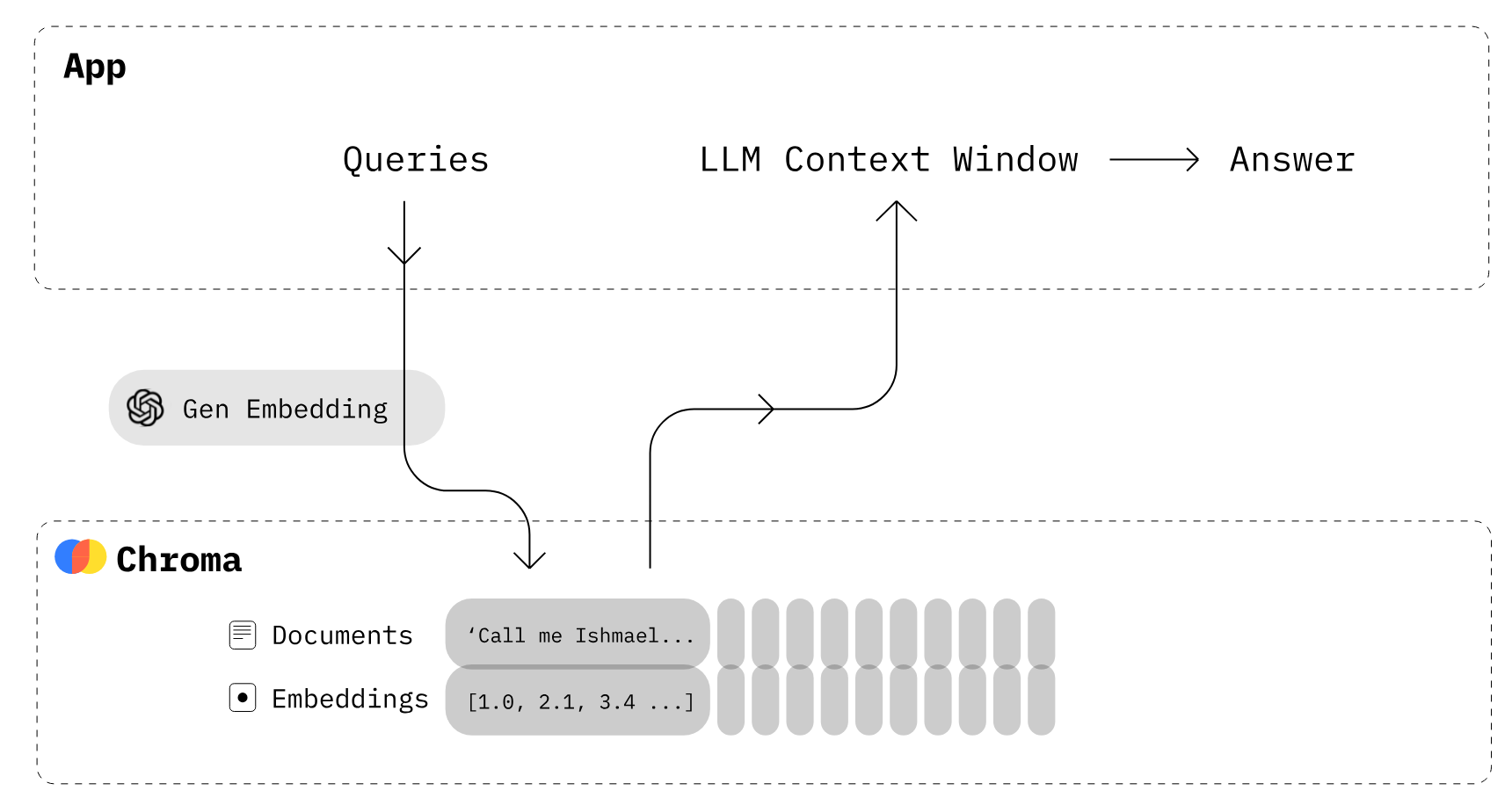
Một trong những công nghệ cốt lõi giúp LLM hoạt động là vector embedding. Máy tính không thể hiểu trực tiếp văn bản, nên embedding biểu diễn văn bản dưới dạng số. Mọi văn bản do người dùng cung cấp được chuyển thành embedding và được dùng để tạo phản hồi.
Việc chuyển văn bản thành embedding tốn thời gian. Để tránh điều đó, ta có các cơ sở dữ liệu vector được thiết kế chuyên biệt cho việc lưu trữ và truy xuất embedding một cách hiệu quả.
Trong hướng dẫn này, tôi sẽ giới thiệu về kho vector và Chroma DB, một cơ sở dữ liệu mã nguồn mở để lưu trữ và quản lý embedding. Bạn sẽ học cách thêm và xóa tài liệu, thực hiện tìm kiếm tương đồng, và chuyển văn bản thành embedding.

Hình ảnh do tác giả cung cấp
Tóm tắt nhanh (TL;DR)
- ChromaDB là cơ sở dữ liệu vector mã nguồn mở dùng để lưu trữ và truy xuất embedding—cài đặt bằng
pip install chromadb - Dùng
chromadb.PersistentClient(path="./chroma_db")để lưu cục bộ bền vững hoặcchromadb.EphemeralClient()để thử nghiệm trong bộ nhớ - Tạo một bộ sưu tập (tương tự bảng), rồi
add()tài liệu kèm metadata và ID tùy chọn - Chạy tìm kiếm tương đồng ngữ nghĩa với
collection.query(query_texts=["..."], n_results=5) - Có thể cắm bất kỳ mô hình embedding nào—OpenAI, HuggingFace, Google Gemini, hoặc hàm tùy chỉnh
- ChromaDB được dùng rộng rãi làm kho vector trong các pipeline RAG (Retrieval-Augmented Generation)
Vector Store là gì?
Vector store là các cơ sở dữ liệu được thiết kế chuyên biệt để lưu trữ và truy xuất embedding vector một cách hiệu quả. Chúng cần thiết vì các cơ sở dữ liệu truyền thống như SQL không được tối ưu cho việc lưu trữ và truy vấn dữ liệu vector lớn.
Embedding biểu diễn dữ liệu (thường là dữ liệu phi cấu trúc như văn bản) bằng các vector số trong không gian nhiều chiều. Cơ sở dữ liệu quan hệ truyền thống không phù hợp để lưu trữ và tìm kiếm các biểu diễn vector này.
Vector store có thể lập chỉ mục và nhanh chóng tìm các vector tương tự bằng các thuật toán đo tương đồng, cho phép ứng dụng tìm các vector liên quan khi đưa vào một vector truy vấn mục tiêu.
Ví dụ, với một chatbot cá nhân hóa, người dùng nhập một lời nhắc cho mô hình sinh. Dựa trên thuật toán tìm kiếm tương đồng, mô hình sẽ tìm văn bản tương tự trong một tập tài liệu. Thông tin tìm được sẽ được dùng để tạo phản hồi chính xác và cá nhân hóa cao. Việc truy xuất thông tin này khả thi nhờ embedding và lập chỉ mục vector trong các vector store.
Chroma DB là gì?
Chroma DB là một vector store mã nguồn mở dùng để lưu trữ và truy xuất embedding vector. Mục đích chính của nó là lưu embedding kèm metadata để các mô hình ngôn ngữ lớn sử dụng sau này. Ngoài ra, nó cũng có thể dùng cho các công cụ tìm kiếm ngữ nghĩa trên dữ liệu văn bản.
Tính năng của Chroma DB
- Đơn giản và mạnh mẽ:
- Cài đặt bằng một lệnh đơn giản:
pip install chromadb. - Bắt đầu nhanh với Python SDK, cho phép tích hợp mượt mà và thiết lập nhanh.
- Cài đặt bằng một lệnh đơn giản:
- Đầy đủ tính năng:
- Tính năng truy xuất toàn diện: Gồm tìm kiếm vector, tìm kiếm toàn văn bản, lưu trữ tài liệu, lọc theo metadata, và truy xuất đa phương thức.
- Khả năng mở rộng cao: Dùng SQLite cho lưu trữ bền vững cục bộ và hỗ trợ chế độ client-server cho nhiều client và triển khai sản xuất.
- Hỗ trợ đa ngôn ngữ lập trình:
- Cung cấp SDK cho các ngôn ngữ phổ biến như Python, JavaScript/TypeScript, Ruby, PHP và Java.
- Tích hợp sẵn:
- Tích hợp gốc với các mô hình embedding từ HuggingFace, OpenAI, Google, và nhiều bên khác.
- Tương thích với Langchain và LlamaIndex, cùng nhiều tích hợp công cụ khác sắp ra mắt.
- Mã nguồn mở:
- Giấy phép Apache 2.0.
- Tốc độ và sự đơn giản:
- Tập trung vào đơn giản và nhanh chóng, được thiết kế để phân tích và truy xuất hiệu quả đồng thời dễ sử dụng.
Chroma DB cung cấp tùy chọn máy chủ tự lưu trữ. Nếu bạn cần một cơ sở dữ liệu vector quản lý hoặc cloud-native, hãy xem các hướng dẫn về Làm chủ cơ sở dữ liệu vector với Pinecone hoặc Weaviate như những giải pháp thay thế.
Hình ảnh từ Chroma
Chroma DB hoạt động như thế nào?
- Trước tiên, bạn cần tạo một bộ sưu tập tương tự như bảng trong cơ sở dữ liệu quan hệ. Theo mặc định, Chroma chuyển văn bản thành embedding bằng
all-MiniLM-L6-v2, nhưng bạn có thể chỉnh bộ sưu tập để dùng mô hình embedding khác. - Thêm các tài liệu văn bản kèm metadata và ID duy nhất vào bộ sưu tập mới. Khi nhận văn bản, bộ sưu tập sẽ tự động chuyển thành embedding.
- Truy vấn bộ sưu tập bằng văn bản hoặc embedding để nhận các tài liệu tương tự. Bạn cũng có thể lọc kết quả dựa trên metadata.
Yêu cầu tiên quyết
Để theo dõi hướng dẫn này, bạn cần:
- Python 3.8+ (khuyến nghị Python 3.11 để tương thích tốt nhất với ChromaDB)
- Trình quản lý gói pip
- Một khóa API OpenAI (chỉ cần cho phần Embedding; các phần lõi của ChromaDB hoạt động không cần khóa)
- SQLite 3.35 trở lên (tích hợp trong Python 3.11; nếu dùng phiên bản cũ hơn và gặp lỗi, dùng
pip install pysqlite3-binary) - Hiểu biết cơ bản về danh sách và từ điển trong Python
Bắt đầu với Chroma DB
Trong phần này, tôi sẽ tạo một cơ sở dữ liệu vector, thêm bộ sưu tập, nạp văn bản vào đó và chạy truy vấn tìm kiếm tương đồng.
Trước tiên, cài đặt chromadb và openai. Bạn sẽ cần một khóa API OpenAI chỉ cho phần Embedding—các ví dụ lõi của ChromaDB bên dưới hoạt động không cần khóa.
Lưu ý: Chroma yêu cầu SQLite phiên bản 3.35 trở lên. Nếu gặp vấn đề, hãy nâng cấp lên Python 3.11 hoặc cài phiên bản cũ hơn của chromadb.
!pip install chromadb openai Chọn chế độ client
ChromaDB cung cấp ba chế độ client tùy theo trường hợp sử dụng:
| Client | Tình huống sử dụng | Mã |
|---|---|---|
| EphemeralClient | Thử nghiệm trong bộ nhớ; dữ liệu mất khi thoát | chromadb.EphemeralClient() |
| PersistentClient | Lưu vào tệp cục bộ; dữ liệu tồn tại qua các lần khởi động lại | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Môi trường sản xuất; kết nối tới máy chủ ChromaDB đang chạy | chromadb.HttpClient(host="localhost", port=8000) |
Bạn có thể tạo cơ sở dữ liệu trong bộ nhớ (tạm thời) để thử nghiệm bằng chromadb.EphemeralClient(). Dữ liệu chỉ được lưu trong RAM và sẽ đặt lại khi chương trình kết thúc—rất phù hợp cho các thử nghiệm nhanh.
Trong ví dụ này, tôi sẽ tạo cơ sở dữ liệu bền vững được lưu tại thư mục ./chroma_db. ChromaDB dùng lưu trữ dựa trên SQLite ở chế độ bền vững—backend DuckDB đã bị loại bỏ từ ChromaDB 0.4.0.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")Sau đó, chúng ta sẽ tạo đối tượng collection bằng client. Điều này tương tự tạo một bảng trong cơ sở dữ liệu truyền thống.
collection = client.create_collection(name="Students")Để thêm văn bản vào bộ sưu tập, chúng ta sẽ tạo ngẫu nhiên văn bản về một sinh viên, câu lạc bộ và trường đại học. Bạn có thể tạo văn bản ngẫu nhiên bằng ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Bây giờ, chúng ta sẽ dùng hàm add() để thêm dữ liệu văn bản kèm metadata và ID duy nhất. Sau đó, Chroma sẽ tự động tải mô hình all-MiniLM-L6-v2 để chuyển văn bản thành embedding và lưu vào bộ sưu tập "Students".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Để chạy tìm kiếm tương đồng, bạn có thể dùng hàm query() và đặt câu hỏi bằng ngôn ngữ tự nhiên. Nó sẽ chuyển truy vấn thành embedding và dùng thuật toán tương đồng để tạo kết quả tương tự. Trong trường hợp của chúng ta, nó trả về hai kết quả tương tự.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embedding
Bạn có thể dùng bất kỳ mô hình embedding hiệu năng cao nào từ danh sách embedding. Bạn thậm chí có thể tạo hàm embedding tùy chỉnh. Để tìm hiểu sâu về các mô hình hiện tại của OpenAI, xem hướng dẫn về text-embedding-3-large.
Trong phần này, tôi sẽ dùng mô hình text-embedding-3-small của OpenAI để chuyển văn bản thành embedding. Đây là lựa chọn thay thế được OpenAI khuyến nghị cho phiên bản cũ text-embedding-ada-002—cho hiệu năng benchmark tốt hơn với chi phí thấp hơn 5 lần.
Sau khi tạo hàm embedding OpenAI, bạn có thể thêm danh sách tài liệu văn bản để tạo embedding.
Khám phá cách dùng OpenAI API cho Text Embedding và tạo bộ phân loại văn bản, hệ thống truy xuất thông tin, cùng bộ phát hiện tương đồng ngữ nghĩa.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Thay vì dùng mô hình embedding mặc định, tôi sẽ nạp trực tiếp các embedding đã sinh vào một bộ sưu tập mới.
- Chúng ta sẽ dùng hàm
get_or_create_collection()để tạo một bộ sưu tập mới tên "Students2". Hàm này khác vớicreate_collection(): nó sẽ lấy bộ sưu tập nếu đã tồn tại hoặc tạo mới nếu chưa có. - Bây giờ, chúng ta sẽ thêm embedding, tài liệu văn bản, metadata và ID vào bộ sưu tập mới tạo.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Cũng có một cách khác đơn giản hơn. Bạn có thể thêm hàm embedding OpenAI khi tạo hoặc truy cập bộ sưu tập. Ngoài OpenAI, bạn có thể dùng Cohere, Google Gemini, HuggingFace và Instructor.
Trong trường hợp của chúng ta, việc thêm tài liệu văn bản mới sẽ chạy hàm embedding OpenAI thay cho mô hình mặc định để chuyển văn bản thành embedding.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Hãy xem sự khác biệt bằng cách chạy một truy vấn tương tự trên bộ sưu tập mới.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsKết quả đã được cải thiện. Tìm kiếm tương đồng nay trả về thông tin về trường đại học thay vì câu lạc bộ. Ngoài ra, khoảng cách giữa các vector thấp hơn so với mô hình embedding mặc định, đây là tín hiệu tích cực.

Lọc kết quả truy vấn
ChromaDB hỗ trợ lọc theo metadata để thu hẹp kết quả tìm kiếm tương đồng. Sử dụng tham số where với các toán tử lọc trong query():
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Các toán tử hỗ trợ: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. Bạn cũng có thể lọc theo nội dung tài liệu với where_document={"$contains": "chess"}.
Cập nhật và xóa dữ liệu
Tương tự cơ sở dữ liệu quan hệ, bạn có thể cập nhật hoặc xóa giá trị khỏi bộ sưu tập. Để cập nhật văn bản và metadata, chúng ta sẽ cung cấp ID cụ thể cho bản ghi cùng văn bản mới.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Chạy một truy vấn đơn giản để kiểm tra xem thay đổi đã được áp dụng thành công chưa.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsNhư ta thấy, thay vì Alexandra, chúng ta nhận được Kristiane.

Để xóa một bản ghi khỏi bộ sưu tập, chúng ta sẽ dùng hàm delete() và chỉ định ID duy nhất.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsVăn bản thông tin sinh viên đã bị xóa; thay vào đó, chúng ta nhận các kết quả tốt nhất tiếp theo.

Quản lý bộ sưu tập
Trong phần này, tôi sẽ đề cập đến các hàm tiện ích của bộ sưu tập để đếm, liệt kê, đổi tên và xóa bộ sưu tập.
Chúng ta sẽ tạo một bộ sưu tập mới tên "vectordb" và thêm thông tin về cheat sheet Chroma DB, tài liệu hướng dẫn và JS API kèm metadata.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Chúng ta sẽ dùng hàm count() để kiểm tra bộ sưu tập có bao nhiêu bản ghi.
vector_collections.count()3Để xem toàn bộ bản ghi trong bộ sưu tập, sử dụng hàm get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Để đổi tên bộ sưu tập, dùng hàm modify(). Để xem tất cả tên bộ sưu tập, dùng list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Có vẻ chúng ta đã đổi tên "vectordb" thành "chroma_info" một cách hiệu quả.
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Để truy cập bất kỳ bộ sưu tập mới nào, bạn có thể dùng get_collection() với tên bộ sưu tập.
vector_collections_new = client.get_collection(name="chroma_info")Chúng ta có thể xóa một bộ sưu tập bằng hàm client delete_collection() và chỉ định tên bộ sưu tập.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Chúng ta có thể xóa toàn bộ cơ sở dữ liệu bộ sưu tập bằng client.reset(). Tuy nhiên, không khuyến nghị vì không có cách khôi phục dữ liệu sau khi xóa.
client.reset()
client.list_collections()[]ChromaDB với LangChain: Ví dụ RAG
Một trong những tích hợp phổ biến nhất của ChromaDB là với LangChain để xây dựng ứng dụng RAG. Dưới đây là ví dụ tối giản dùng ChromaDB làm kho vector:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)Để xây dựng một pipeline RAG sẵn sàng sản xuất với FastAPI, xem hướng dẫn Xây dựng hệ thống RAG với LangChain và FastAPI. Với ví dụ dùng DeepSeek, xem Chatbot DeepSeek R1 RAG với Chroma.
Kết luận
Các vector store như Chroma DB đang trở thành thành phần thiết yếu của hệ thống mô hình ngôn ngữ lớn. Bằng cách cung cấp lưu trữ chuyên biệt và truy xuất hiệu quả cho embedding vector, chúng cho phép truy cập nhanh tới thông tin ngữ nghĩa liên quan để tăng sức mạnh cho LLM.
Trong hướng dẫn Chroma DB này, chúng ta đã tìm hiểu những điều cơ bản về tạo bộ sưu tập, thêm tài liệu, chuyển văn bản thành embedding, truy vấn tương đồng ngữ nghĩa, và quản lý các bộ sưu tập.
Bước tiếp theo tự nhiên là xây dựng ứng dụng Retrieval-Augmented Generation (RAG) với ChromaDB làm kho vector. Bắt đầu với hướng dẫn Xây dựng hệ thống RAG với LangChain và FastAPI cho một pipeline sẵn sàng sản xuất, hoặc khám phá Agentic RAG cho các quy trình truy xuất do agent điều phối nâng cao. Bạn cũng có thể dùng LlamaIndex để nạp dữ liệu riêng tư vào LLM, hoặc theo dõi hướng dẫn LangChain LLM để phát triển ứng dụng hoàn chỉnh.
