
Track
AI Fundamentals
10 hr
Weaviate is an open-source, cloud-native, modular, real-time vector search engine that enables you to store data objects and vector embeddings and query them based on similarity measures. In this tutorial, we will explore Weaviate and its core concepts, learn how to set it up, create a schema, add data to it, and query the data using Weaviate's GraphQL interface. We will also cover how to use Weaviate with Python and discuss best practices and tips for schema design, data import, and query optimization.
Weaviate is a vector database that stores both objects and vectors, allowing for combining vector search. It is modular, cloud-native, and real-time, making it easy to scale machine learning models. Weaviate comes with optional modules for text, image, and other media types, which can be chosen based on your task and data. You can also use more than one module, depending on the variety of data.
Unstructured data, such as text, images, and audio, lacks a predefined format, making it challenging for traditional databases and methods to handle.
To make this data usable in AI and machine learning applications, it's converted into numerical vectors using embeddings.
Embeddings serve as specialized dictionaries that transform high-dimensional data into compact numerical forms, facilitating efficient processing by AI models.
They are crucial in reducing data dimensionality and overcoming the limitations of traditional encoding methods, enabling AI to understand complex relationships and context within the data.
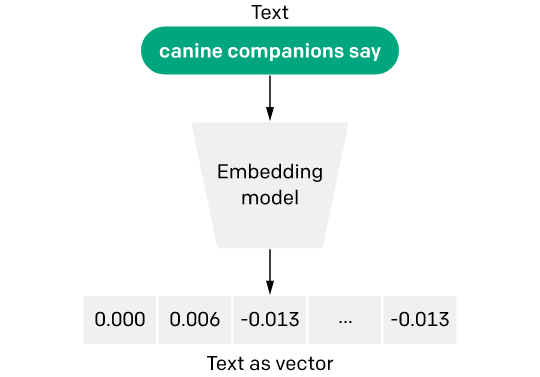
Text Embedding Model - Image Source
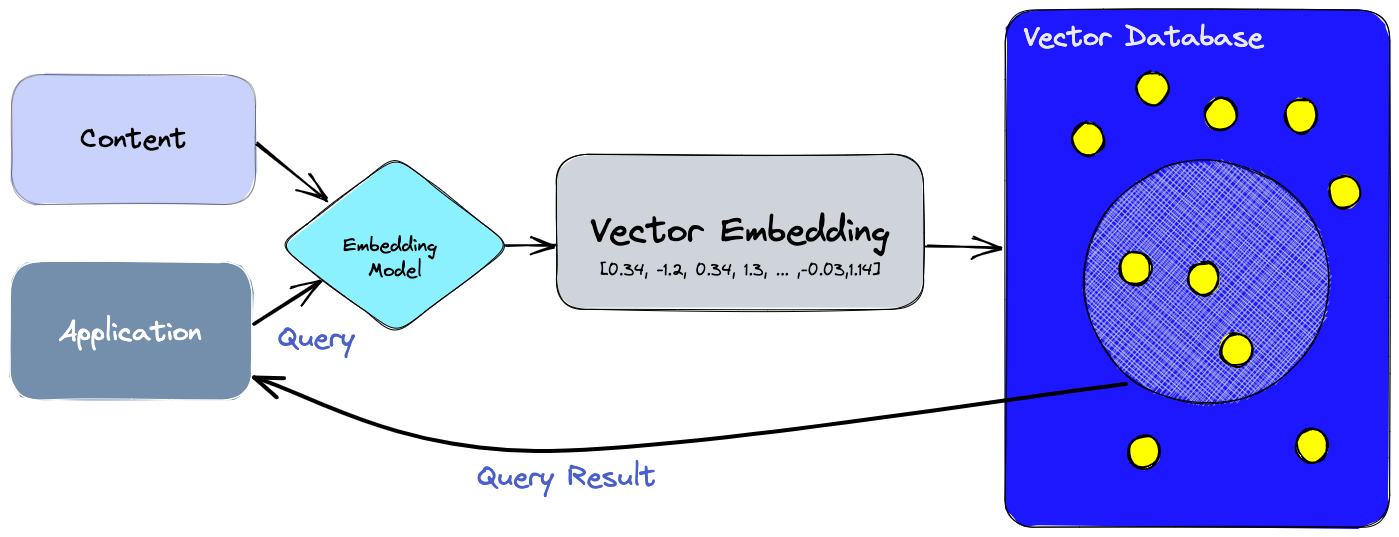
Traditional databases store data in tables, which can be queried using SQL. However, SQL is not well-suited for searching unstructured data, such as text or images. Vector databases, on the other hand, store data as vectors, which can be queried using similarity measures.
This makes them well-suited for tasks such as semantic search, question answering, and generative search. Vectors are obtained using the ML embeddings model. It is just the numeric representation of the original object, such as text, image, audio, video, etc.
Consider a scenario where a language model is used to analyze and categorize large sets of text documents. Each document could be transformed into a high-dimensional vector that encapsulates its semantic essence.
Storing these vectors in a traditional database might not be efficient for tasks like similarity search or clustering.
This is where a vector database comes in handy. It is optimized for storing vectors and performing high-speed vector operations, such as finding the nearest neighbors or calculating the cosine similarity between vectors.
Pinecone is another popular vector database and is a great alternative to Weaviate. If you would like to learn more about Pinecone, check out Mastering Vector Databases with Pinecone Tutorial.
To set up Weaviate, you can use Docker Compose or install it manually. Docker Compose is the recommended method, as it simplifies the installation process. Once you have installed Weaviate, you can verify the installation by running a simple query.
For Docker compose, download this yaml file from Weaviate. Once you have this file, you can simply run:
docker compose up -dThe other options of using Weaviate are:
To use Weaviate in Python you can install the weaviate python client using pip.
!pip install -U weaviate-clientIn Weaviate, each data item belongs to a group called a "Class" and has certain features called "Properties". These data items (represented as JSON documents) are class-based collections.
Each data item is represented by a vector (machine learning embeddings model). Each class-based collection contains objects of the same class, which are defined by a common schema.
Weaviate is built in a flexible way, allowing you to add optional features like turning data into vectors or creating backups.
Without these add-ons, the basic version of Weaviate serves as a database specifically designed for vector data.
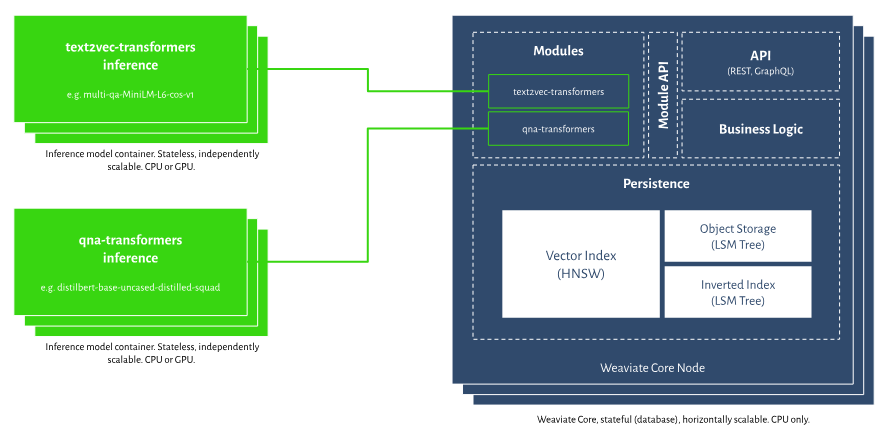
Weaviate is a reliable database that saves data instantly and can handle both software and hardware failures.
When you search for something using vectors, Weaviate gives you the full data item (sometimes called a "document" in other databases) rather than just an identifier like an ID.
If you use both regular and vector-based searches, the filters are applied before the vector search, ensuring you get the exact number of results you asked for. This is different from filtering after the search, where the number of results can vary.
You can freely update or delete data and their vectors, even while you're reading from the database.
You can interact with Weaviate using its APIs, which include both a RESTful API and a GraphQL API. All programming languages' client libraries are compatible with these API features.
GraphQL is a query language for APIs that allows you to request exactly the data you need. It provides a more efficient and flexible way to interact with databases compared to traditional methods like REST.
GraphQL interface was chosen for multiple reasons, that includes:
Each Weaviate object belongs to one class. You can create the class manually or use Auto-schema from Weaviate to create one. When you create a class manually, you have more control over the data model.
To create a class using python client library:
class_name = "Item description"
class_object = {"class": class_name}
client.schema.create_class(class_object) Typically, you will also specify additional configurations, a more realistic example as taken from Weaviate.io would be:
{
"class": "Article",
"vectorizer": "text2vec-cohere",
"vectorIndexConfig": {
"distance": "cosine",
},
"moduleConfig": {
"generative-openai": {}
},
"properties": [
{
"name": "title",
"dataType": ["text"]
},
{
"name": "chunk",
"dataType": ["text"]
},
{
"name": "chunk_no",
"dataType": ["int"]
},
{
"name": "url",
"dataType": ["text"],
"tokenization": "field"
},
],
}
Notice that a model for vectorization text2vec-cohere is defined as well as distance metric cosine. Notice how properties are defined as a list of dictionaries.
Object belongs to a class. Objects can omit class properties as well as add new properties. Below is an example of adding an object to class Article.
uuid = client.data_object.create({
'question': 'question here ...',
'answer': 'answer here ...'
}, 'Article')You can optionally assign a vector to represent each object. If you do not define a vector, Weaviate will use its default vectorizer.
uuid = client.data_object.create(
data_object={
'question': 'question here ...',
'answer': 'answer here ...',
},
class_name='Article',
vector=[0.12345] * 1536This is an example showing how to create a class and then add an object to the class using the python client of Weaviate. You must install the python client first with pip.
!pip install -U weaviate-clientTo work with Weaviate, you must have a working instance of Weaviate. There are two ways you can use it, first by using a fully managed hosted instance on Weaviate cloud service. Alternatively you can use Embedded Weaviate, which runs the instance in the background of your app.
# For using embedded
import weaviate
from weaviate.embedded import EmbeddedOptions
import json
import os
client = weaviate.Client(
embedded_options=EmbeddedOptions(),
additional_headers = {
"X-OpenAI-Api-Key": "YOUR_OPENAI_KEY"
}
)
Creating a class is very straightforward:
class_obj = {
"class": "Question",
"vectorizer": "text2vec-openai",
"moduleConfig": {
"text2vec-openai": {},
"generative-openai": {}
}
}
client.schema.create_class(class_obj)
If vectorizer is set to None then you will have to provide vectors yourself as a list.
We can now add objects to the created class Question through the batch import process. We will use jeopardy Q&A in json format. This is what it looks like:
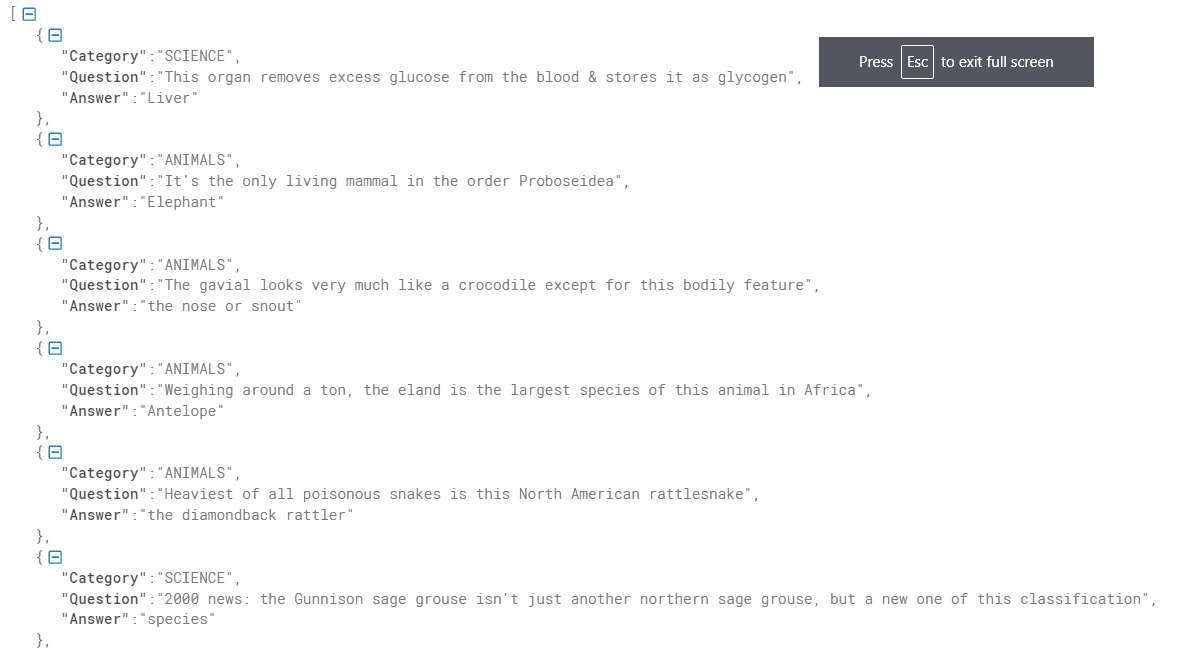
Data Source (Credit: Weaviate Official)
# Load data
import requests
url = 'https://raw.githubusercontent.com/weaviate-tutorials/quickstart/main/data/jeopardy_tiny.json'
resp = requests.get(url)
data = json.loads(resp.text)
# Configure a batch process
with client.batch(
batch_size=100
) as batch:
# Batch import all Questions
for i, d in enumerate(data):
print(f"importing question: {i+1}")
properties = {
"answer": d["Answer"],
"question": d["Question"],
"category": d["Category"],
}
client.batch.add_data_object(
properties,
"Question",
)
This example has been reproduced using the Weaviate documentation.
Let’s delve into some helpful hints for effectively using Weaviate. Whether you're designing your schema, importing data, or optimizing queries, these best practices will help you get the most out of Weaviate's capabilities.
ChromaDB is another popular open-source vector database in the data science community. With Chroma DB, you can easily manage text documents, convert text to embeddings, and do similarity searches. If you want to learn more about ChromaDB, check out Chroma DB Tutorial.
The Weaviate Tutorial provides a comprehensive guide to understanding and utilizing Weaviate, an open-source, cloud-native, real-time vector search engine. The blog covers a wide range of topics, from the basics of what Weaviate is and how it differs from traditional databases, to the nitty-gritty of setting it up and using it effectively.
Weaviate shines in its ability to handle unstructured data through vector embeddings, making it a powerful tool for machine learning and AI applications. Its modular architecture allows for flexibility, letting you choose optional modules based on your specific needs. The blog also delves into the importance of embeddings, explaining how they transform high-dimensional data into a format that can be easily processed by AI models.
If you want to continue learning about Weaviate, check out our webinar on Vector Databases for Data Science with Weaviate in Python.
Start Working With AI Today!
Track
Course
Course
blog
Moez Ali
14 min
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
code-along
JP Hwang
code-along
JP Hwang
code-along
James Briggs



