If you're a data scientist or data analyst familiar with relational and non-relational databases like SQL and MongoDB, get ready to dive into an exciting new world of data management. In this tutorial, you will learn about a new type of data store called vector databases, a specialized type of database designed to handle and process vector data efficiently. In this Pinecone tutorial, we’ll look specifically at the Pinecone vector database platform.
To learn more about Pinecone, be sure to check out our course, Vector Databases for Embeddings with Pinecone.
What is a Vector Database?
In traditional databases, data is typically stored in rows and columns, suitable for structured data. However, as datasets become more complex and high-dimensional, the need for a more specialized solution arises. This is where vector databases shine. Instead of dealing with traditional data structures, vector databases are optimized to handle vectors - mathematical representations of data points in multi-dimensional spaces.
Vector data finds extensive use in various fields, including machine learning, data science, computational biology, and NLP. They can represent numerical features, coordinates, embeddings, text, images, and much more. With the rise of AI-driven applications, the demand for efficient handling of vectorized datasets has surged, and Vector Databases have become a crucial tool in this context.
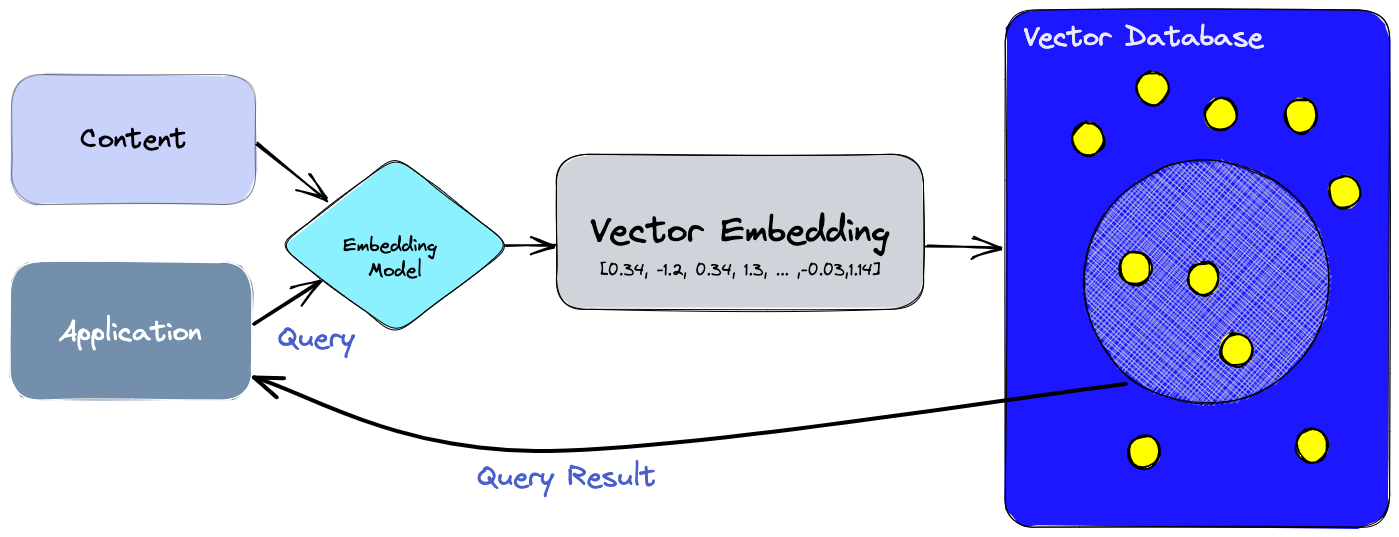
What is Pinecone?
Pinecone is a managed vector database platform that has been purpose-built to tackle the unique challenges associated with high-dimensional data. Equipped with cutting-edge indexing and search capabilities, Pinecone empowers data engineers and data scientists to construct and implement large-scale machine learning applications that effectively process and analyze high-dimensional data.
Key features of Pinecone
Let’s look at what makes pinecone such a useful tool:
Fully managed service
As a fully managed platform, Pinecone manages everything related to infrastructure and maintenance. This allows developers to concentrate their efforts on the development and deployment of their machine learning applications without worrying about infrastructure and operational complexities.
Scalability
Pinecone exhibits exceptional scalability, effortlessly managing billions of high-dimensional vectors and offering horizontal scaling capabilities. This makes it well-suited for handling even the most demanding machine learning workloads.
Real-time data ingestion
Pinecone seamlessly supports real-time data ingestion, allowing users to store and index new data as it becomes available without experiencing any downtime or interruptions.
Low-latency search
By leveraging sophisticated indexing algorithms, Pinecone achieves low-latency search results for nearest neighbor queries and similarity search operations. This ensures fast and precise outcomes for time-sensitive applications.
Seamless integration
Pinecone's API has been thoughtfully designed for simplicity and intuitiveness, streamlining the integration process with existing machine learning workflows and data pipelines.
Understanding Unstructured Data and Vector Embeddings
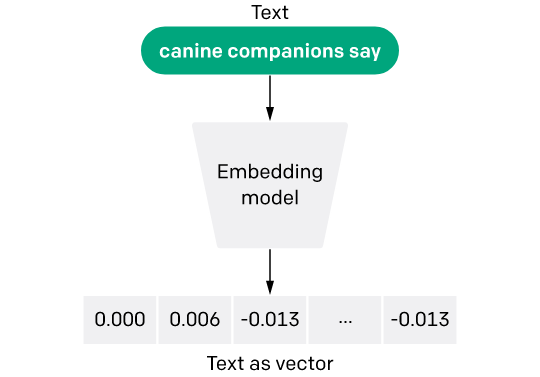
Text Embedding Model - Image Source
Unstructured data refers to data that does not have a predefined or organized format, making it challenging for traditional databases to store and process efficiently. Examples of unstructured data include text, images, audio, and video files.
Unstructured data lacks a rigid structure, making it difficult to analyze directly using traditional methods. Hence to be able to use unstructured data for machine learning and AI applications, unstructured data is transformed and stored into multi-dimensional numeric representation using vector embeddings.
Embeddings play a pivotal role in the field of artificial intelligence, offering a powerful technique to transform high-dimensional data, like words, images, or user preferences, into compact numerical representations. These numerical embeddings enable AI models to efficiently process and comprehend complex information.
Understanding embeddings becomes easier when thinking of them as a specialized dictionary for a particular task. For instance, in text mining projects, embeddings help us grasp the semantic meaning of words by analyzing their relationships with other words. This process generates a list of embeddings, which can be treated as a task-specific dictionary, providing numerical vector representations that reflect the semantic meaning of words. The similarity and relationship between different words are measured by the distance between their corresponding embeddings, enabling AI models to understand the context and significance of words.
The significance of embeddings lies in their ability to reduce data dimensionality, making it more manageable for machine learning models to handle large inputs like sparse vectors representing words or items. By using embeddings, we can avoid the limitations of one-hot-encoding, where each category is converted into a separate dummy variable, which could lead to excessively large input matrices for certain tasks.
If you want to learn more about how Word Embeddings work, check out our LDA2vec: Word Embeddings in Topic Models tutorial.
Recap:
- A vector database is a specialized type of database designed to handle and process vector data efficiently
- Pinecone is a fully managed vector database service
- Unstructured data refers to data that does not have a predefined or organized format, such as images, text, audio, or video
- Embeddings is a powerful technique to transform high-dimensional data into compact numerical representations
How Does a Vector Database Work?
You must be familiar with how traditional databases function, storing scalar data like strings and numbers in rows and columns. However, vector databases operate differently, working with vectors and employing distinct optimization and querying methods.
In traditional databases, queries typically look for exact matches in the database. On the other hand, vector databases use a similarity metric to find the vector that best matches our query.
Vector databases utilize a combination of algorithms, collectively known as Approximate Nearest Neighbor (ANN) search. These algorithms optimize the search process through techniques like hashing, quantization, or graph-based search.

Common pipeline for vector database (Image Source)
Want to Learn how to use the OpenAI API for creating text embeddings and then store it in a vector database like Pinecone? Discover their applications in text classification, information retrieval, and semantic similarity detection in Introduction to Text Embeddings with the OpenAI API blog at DataCamp.
Getting Started with Pinecone
To get started, simply head over to pinecone.io and sign up for a free account.
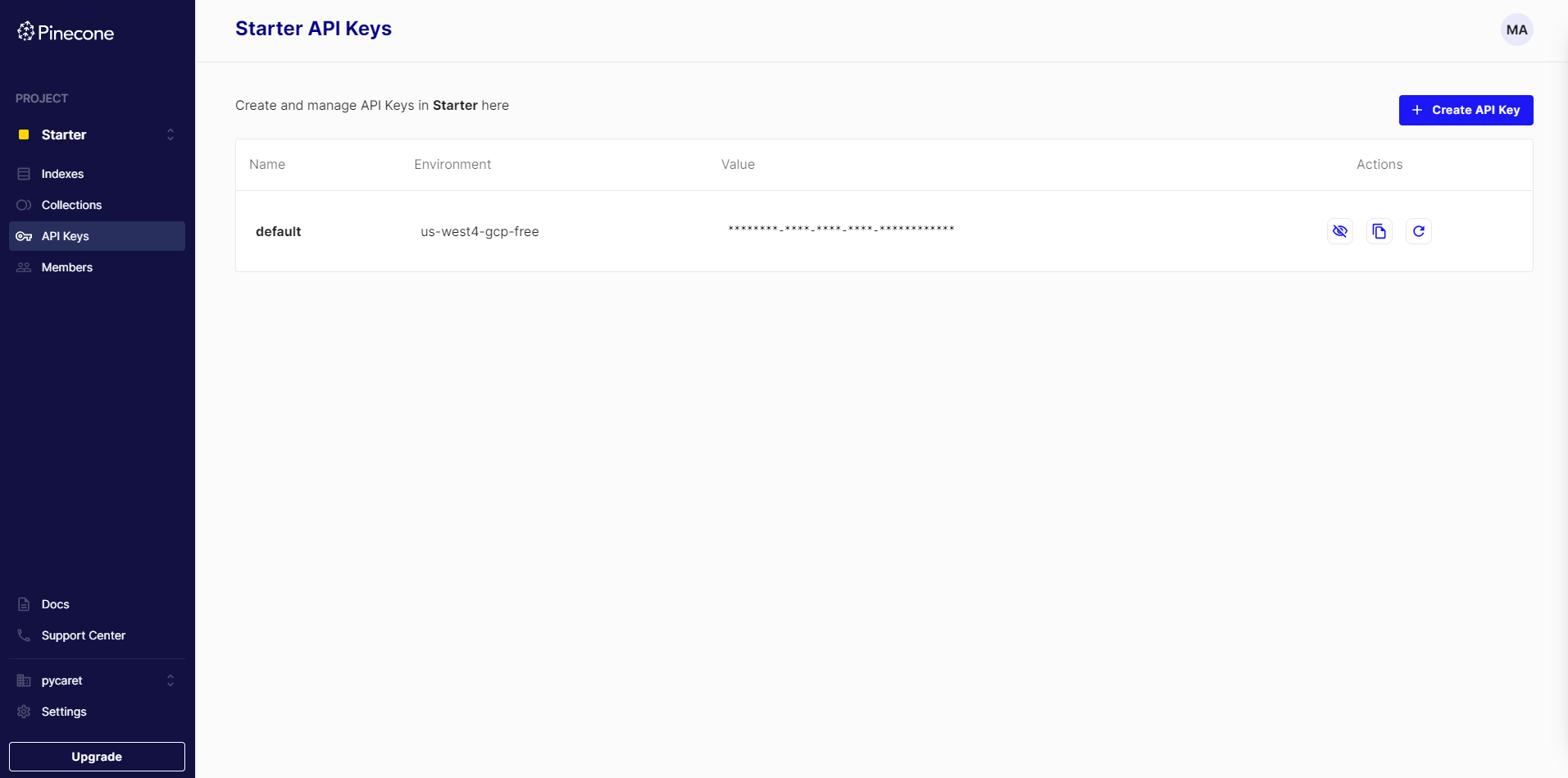
Once you sign up successfully, click on API Keys in the menu and copy your environment and API key. This will be used when working with the Python client of Pinecone.
You can also install the Python client for Pinecone using pip.
pip install pinecone-clientKey Concepts in Pinecone
Before we dive into more detail, let’s explore some of the key terms and concepts you need to know:
Pinecone index
In Pinecone, an index represents the top-level organizational structure for vector data. It is responsible for receiving and storing vectors, handling queries on the stored vectors, and performing various vector operations within its data. Each index operates on one or more pods to ensure efficient functionality.
Pods
Pods are pre-configured hardware units that host Pinecone services. Each index in Pinecone operates on one or multiple pods, and having additional pods generally results in increased storage capacity, reduced latency, and improved throughput. Furthermore, users have the flexibility to create pods of varying sizes to meet specific requirements.
Distance Metrics
Distance Metrics are mathematical techniques used to assess the similarity between two vectors within a vector space. In vector databases, these measures play a crucial role in comparing the stored vectors with a given query vector to identify the most similar ones.
You can choose from different metrics when creating a vector index:
- Cosine similarity. This measure evaluates the cosine of the angle between two vectors in the vector space. Its scale ranges from -1 to 1, where 1 signifies identical vectors, 0 represents orthogonal vectors, and -1 indicates diametrically opposed vectors.
- Euclidean distance. This measure calculates the straight-line distance between two vectors in the vector space. It ranges from 0 to infinity, where 0 denotes identical vectors, and larger values indicate increasingly dissimilar vectors.
- Dot product. This measure computes the product of the magnitudes of two vectors and the cosine of the angle between them. Its scale spans from -∞ to ∞, where positive values indicate vectors pointing in the same direction, 0 represents orthogonal vectors, and negative values signify vectors pointing in opposite directions.
How to Verify Pinecone API key
To utilize Pinecone from Python, an API key is required. You can locate your API key by accessing the Pinecone console and selecting "API Keys." Within the same view, you can also find information about the environment associated with your project.
import pinecone
pinecone.init(api_key="API_KEY", environment = 'ENVIRONMENT')
How to Create a Pinecone Index
To create an index in Pinecone, simply run:
pinecone.create_index("myfirstindex", dimension=8, metric="euclidean")As soon as you run this command, you will notice a Pinecone index being initialized in your console:
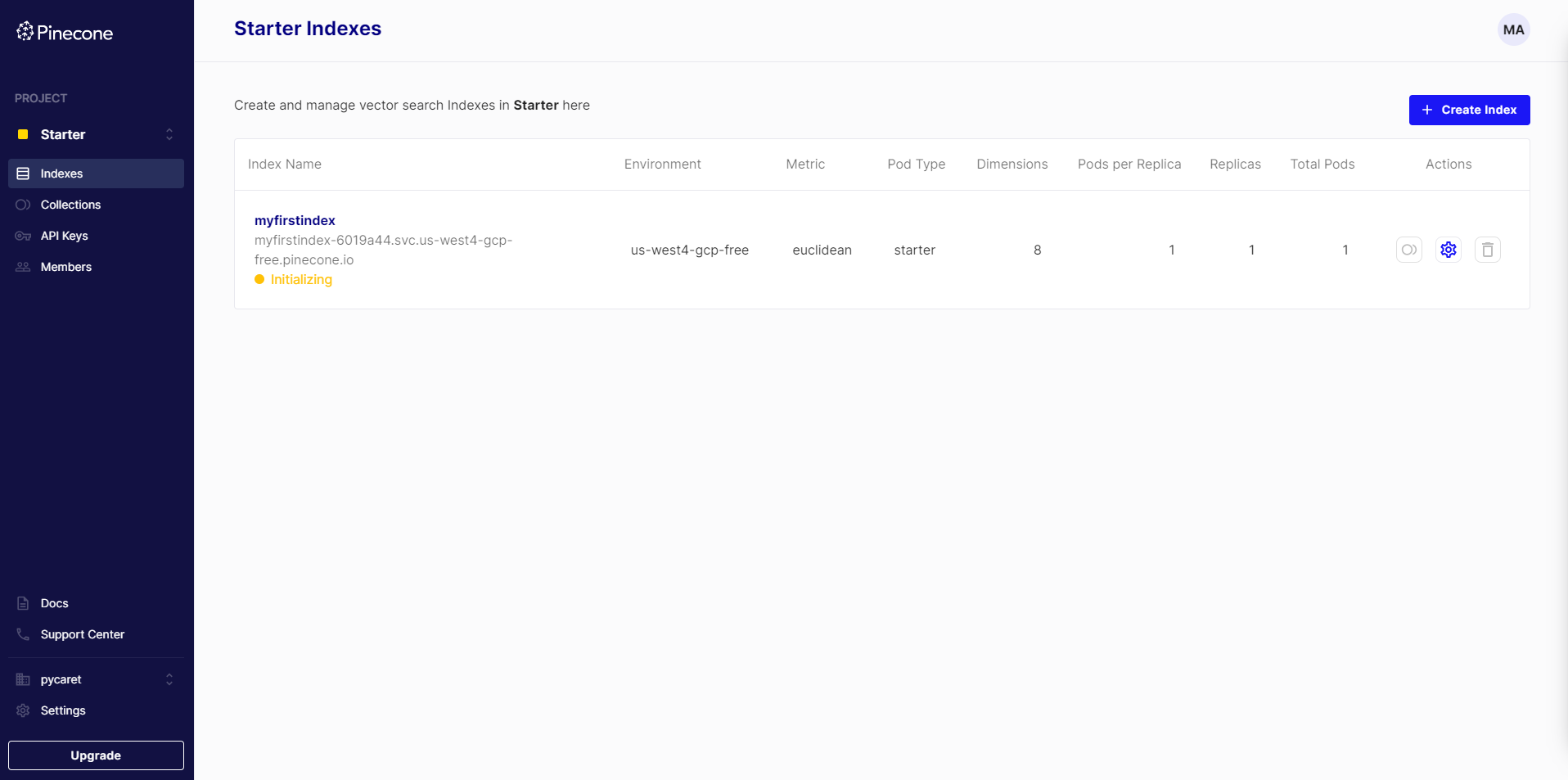
Pinecone Data Insertion and Querying
To add vectors to the index, upsert operation can be used. The upsert operation either adds a new vector to the index or updates an existing vector if a vector with the same ID already exists. Using the following commands, you can upsert five 8-dimensional vectors into your index.
index = pinecone.Index("myfirstindex")
index.upsert([
("A", [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5])
])
If you head over to the console, you will see the five vectors that we just added.
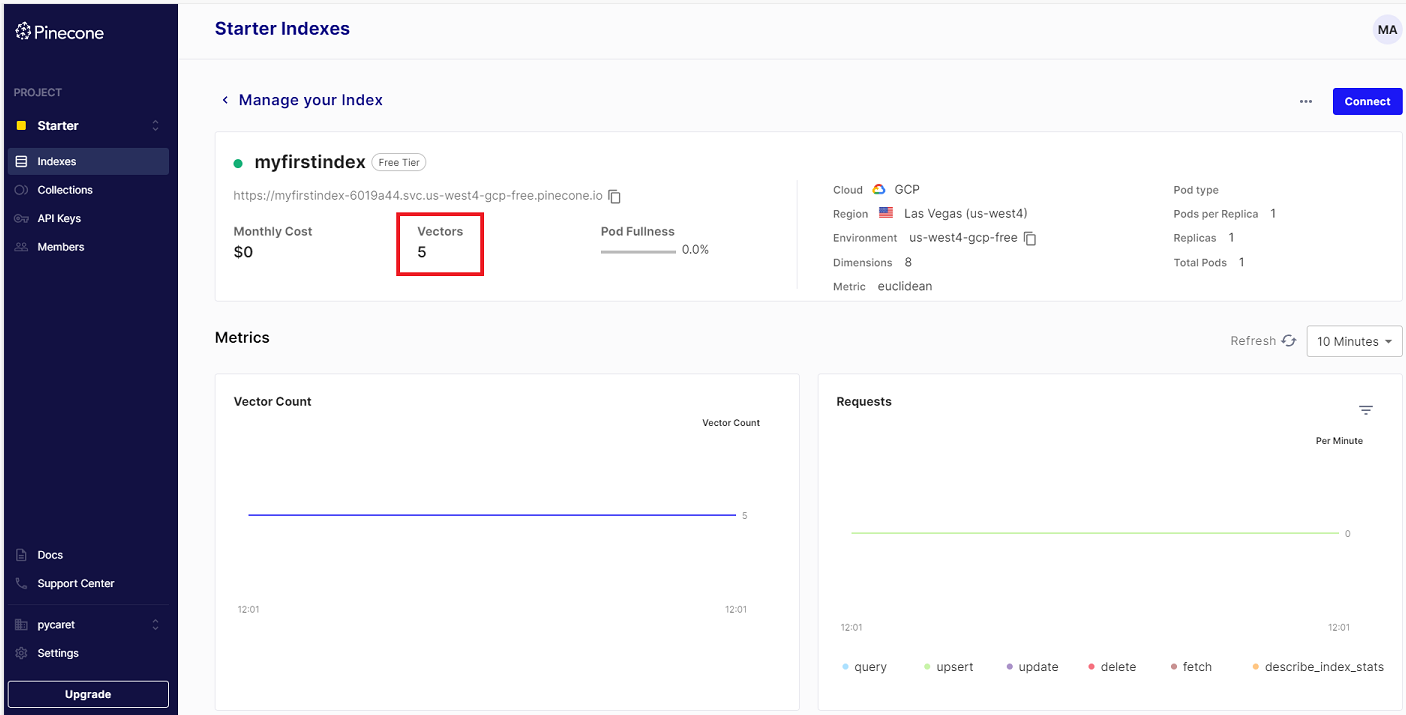
To check the dimension of the vector, you can run:
index.describe_index_stats()
>>> {'dimension': 8,
>>> 'index_fullness': 0.0,
>>> 'namespaces': {'': {'vector_count': 5}},
>>> 'total_vector_count': 5}How to Query the Index and Get Similar Vectors in Pinecone
In the given example below, the index is queried to retrieve the top three (3) vectors that exhibit the highest similarity with a sample 8-dimensional vector. The query utilizes the Euclidean distance metric as specified at the time of index creation.
index.query(
vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],
top_k=3,
include_values=True
)>>> {'matches': [{'id': 'C',
>>> 'score': 0.0,
>>> 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
>>> {'id': 'D',
>>> 'score': 0.0799999237,
>>> 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]},
>>> {'id': 'B',
>>> 'score': 0.0800000429,
>>> 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]}],
>>> 'namespace': ''}
Deleting Indexes in Pinecone
When the index is no longer required, you can use the delete_index operation to remove the index.
pinecone.delete_index("myfirstindex")Conclusion
This tutorial has provided insights into the world of vector databases and Pinecone. Vector databases offer a specialized solution to efficiently handle high-dimensional data, which is becoming increasingly essential in the realm of machine learning, data science, and AI-driven applications.
Pinecone, as a managed vector database platform, stands out as a powerful tool for data engineers and scientists, offering scalability, low-latency search capabilities, and real-time data ingestion. With its seamless integration and user-friendly API, Pinecone streamlines the process of constructing and deploying large-scale machine learning applications.
The tutorial has also delved into the concept of unstructured data and how Vector Embeddings play a vital role in transforming such data into compact numerical representations for analysis.
If you are fascinated by the idea of vector databases and think you have a use case for this, check out our hands-on course, Vector Databases for Embeddings with Pinecone. You can also try Weaviate - an open-source vector database in Python. If you would like to learn more about this, check out Vector Databases for Data Science with Weaviate in Python Webinar on Datacamp.



