
Kursus
Pengantar Python
4 Hr
6.9M
Dalam tutorial ini, kita akan membahas cara kerja t-SNE, teknik ampuh untuk reduksi dimensi dan visualisasi data. Kita akan membandingkannya dengan teknik populer lainnya, PCA, dan mendemonstrasikan cara menjalankan t-SNE dan PCA menggunakan scikit-learn dan plotly express pada dataset sintetis dan dunia nyata.
t-SNE (t-distributed Stochastic Neighbor Embedding) adalah teknik reduksi dimensi nonlinier tanpa pengawasan untuk eksplorasi data dan visualisasi data berdimensi tinggi. Reduksi dimensi nonlinier berarti algoritma memungkinkan kita memisahkan data yang tidak dapat dipisahkan oleh garis lurus.

t-SNE memberi Anda gambaran dan intuisi tentang bagaimana data tersusun dalam dimensi yang lebih tinggi. Teknik ini sering digunakan untuk memvisualisasikan dataset kompleks ke dalam dua dan tiga dimensi, sehingga memungkinkan kita memahami lebih jauh pola dan hubungan yang mendasari dalam data.
Ikuti kursus Dimensionality Reduction in Python untuk mempelajari eksplorasi data berdimensi tinggi, seleksi fitur, dan ekstraksi fitur.
t-SNE dan PCA sama-sama merupakan teknik reduksi dimensi dengan mekanisme berbeda yang bekerja paling baik pada jenis data yang berbeda.
PCA (Principal Component Analysis) adalah teknik linier yang paling cocok untuk data dengan struktur linier. Tujuannya adalah mengidentifikasi komponen utama yang mendasari dalam data dengan memproyeksikannya ke dimensi lebih rendah, meminimalkan varians, dan mempertahankan jarak berpasangan yang besar. Baca tutorial Principal Component Analysis (PCA) kami untuk memahami cara kerja algoritme dengan contoh R.
Sementara itu, t-SNE adalah teknik nonlinier yang berfokus pada pelestarian kemiripan berpasangan antar titik data dalam ruang berdimensi lebih rendah. t-SNE menitikberatkan pada pelestarian jarak berpasangan yang kecil, sedangkan PCA berfokus pada pemeliharaan jarak berpasangan yang besar untuk memaksimalkan varians.
Singkatnya, PCA mempertahankan varians dalam data. Sebaliknya, t-SNE mempertahankan hubungan antar titik data dalam ruang berdimensi lebih rendah, menjadikannya algoritme yang cukup baik untuk memvisualisasikan data nonlinier berdimensi tinggi yang kompleks.
Tabel berikut dapat membantu Anda membandingkan t-SNE dan PCA secara berdampingan:
| Karakteristik | t-SNE | PCA |
|---|---|---|
| Jenis | Reduksi dimensi nonlinier | Reduksi dimensi linier |
| Tujuan | Melestarikan kemiripan berpasangan lokal | Melestarikan varians global |
| Paling cocok untuk | Memvisualisasikan data kompleks berdimensi tinggi | Data dengan struktur linier |
| Keluaran | Representasi berdimensi rendah | Komponen utama |
| Kasus penggunaan | Clustering, deteksi anomali, NLP | Reduksi derau, ekstraksi fitur |
| Intensitas komputasi | Tinggi | Rendah |
| Interpretasi | Lebih sulit diinterpretasikan | Lebih mudah diinterpretasikan |
Algoritme t-SNE mencari ukuran kemiripan antara pasangan instance di ruang berdimensi tinggi dan rendah. Setelah itu, algoritme mencoba mengoptimalkan dua ukuran kemiripan. Semua itu dilakukan dalam tiga langkah.
Proses optimasi memungkinkan terciptanya klaster dan subklaster dari titik data yang serupa dalam ruang berdimensi rendah, yang kemudian divisualisasikan untuk memahami struktur dan hubungan dalam data berdimensi tinggi.
Pada contoh Python, kita akan membuat data klasifikasi, menjalankan PCA dan t-SNE, serta memvisualisasikan hasilnya. Kita akan menggunakan scikit-learn untuk melakukan reduksi dimensi, dan kita akan menggunakan Plotly Express untuk visualisasi.
Kita akan menggunakan fungsi make_classification() dari scikit-learn untuk menghasilkan data sintetis dengan 6 fitur, 1500 sampel, dan 3 kelas.
Setelah itu, kita akan membuat plot 3D dari tiga fitur pertama data menggunakan fungsi Plotly Express scatter_3d().
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()Kita memiliki plot 3D dari data; Anda juga dapat memvisualisasikan data dalam bagan 2D menggunakan fungsi scatter() di Plotly Express.
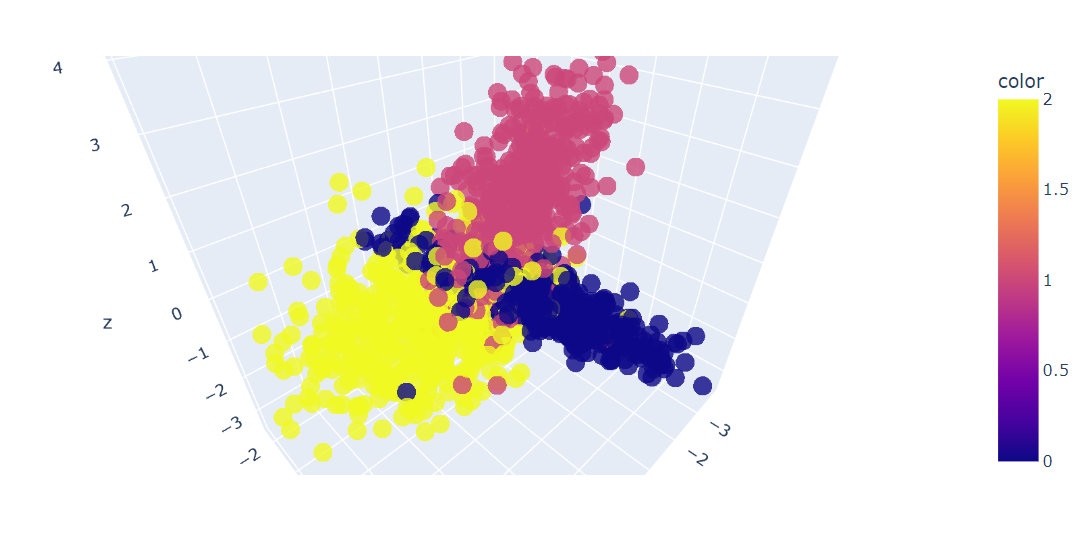
Sekarang kita akan menerapkan algoritme PCA pada dataset untuk menghasilkan dua komponen PCA. Metode fit_transform() mempelajari dan mentransformasi dataset secara bersamaan.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)Sekarang kita dapat memvisualisasikan hasil dengan menampilkan dua komponen PCA pada scatter plot.
Kita juga menggunakan fungsi update_layout() untuk menambahkan judul dan mengganti nama sumbu x dan sumbu y.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()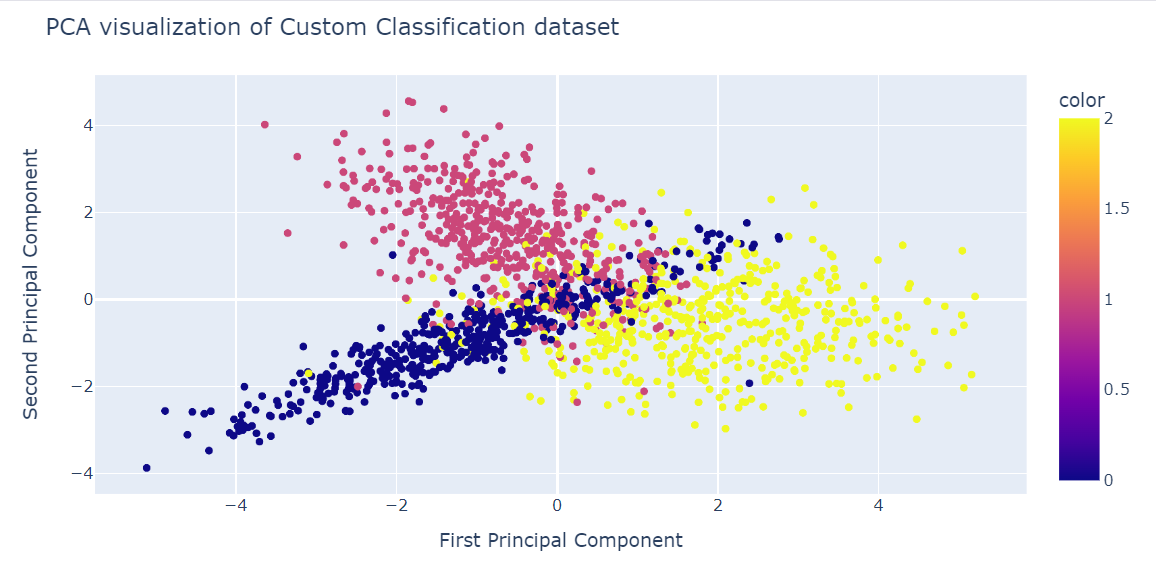
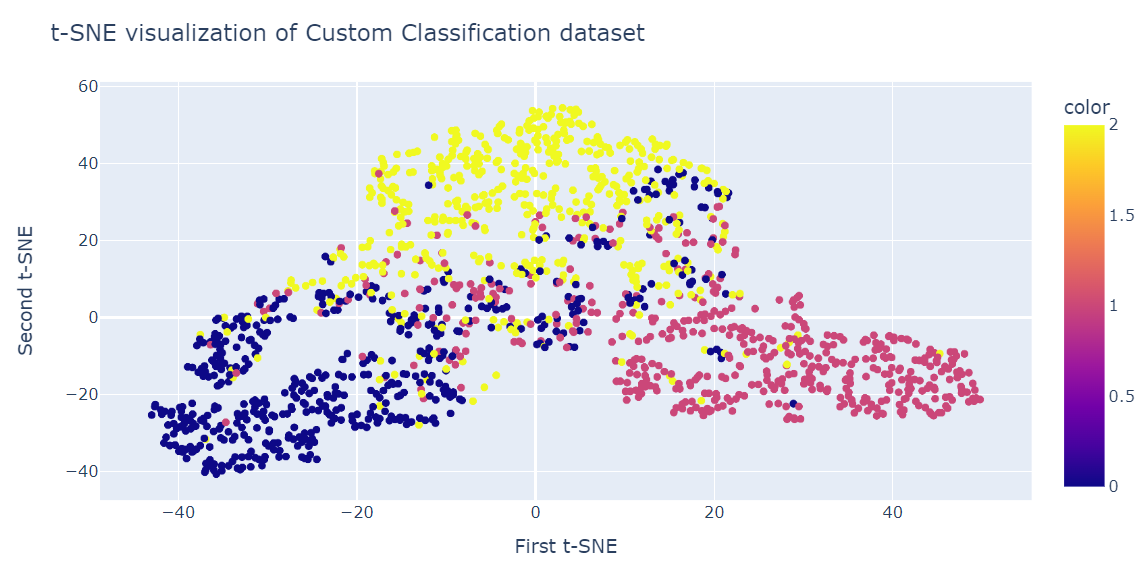
Sekarang, kita akan menerapkan algoritme t-SNE pada dataset dan membandingkan hasilnya.
Setelah melakukan fitting dan mentransformasi data, kita akan menampilkan divergensi Kullback-Leibler (KL) antara distribusi probabilitas berdimensi tinggi dan rendah. Nilai divergensi KL yang rendah biasanya menandakan hasil yang lebih baik.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
tsne.kl_divergence_1.1169137954711914Serupa dengan PCA, kita akan memvisualisasikan dua komponen t-SNE pada scatter plot.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Hasilnya cukup lebih baik daripada PCA. Kita dapat melihat tiga klaster besar dengan jelas.
Pada bagian ini, kita akan menggunakan dataset customer churn dari perusahaan telekomunikasi Iran. Dataset ini memuat informasi aktivitas pelanggan, seperti kegagalan panggilan dan lama berlangganan, serta label churn.
Churn berarti persentase pelanggan yang berhenti menggunakan layanan tertentu dalam rentang waktu tertentu.
Catatan: Kode sumber dan dataset dari kedua contoh tersedia di buku kerja DataLab ini; jika Anda ingin menyesuaikan dan menjalankan kodenya, cukup buat salinan, dan Anda siap melanjutkan!
Kita akan memuat dataset menggunakan pandas dan menampilkan tiga baris pertama.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Setelah itu, kita akan:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
pca.score(X_test)-17.04482851288105Sekarang kita akan memvisualisasikan hasil PCA menggunakan scatter plot dari Plotly Express.
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
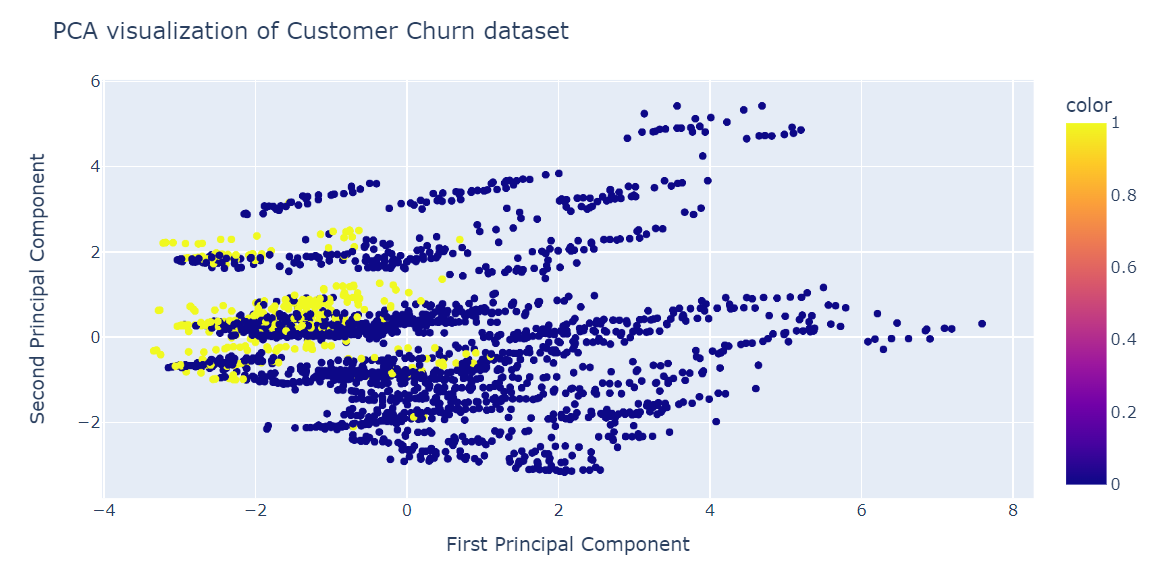
fig.show()PCA kurang baik dalam membentuk klaster. Data pada dimensi rendah terlihat acak. Ini juga bisa berarti fitur dalam dataset sangat bias (skewed), atau tidak memiliki struktur korelasi yang kuat.
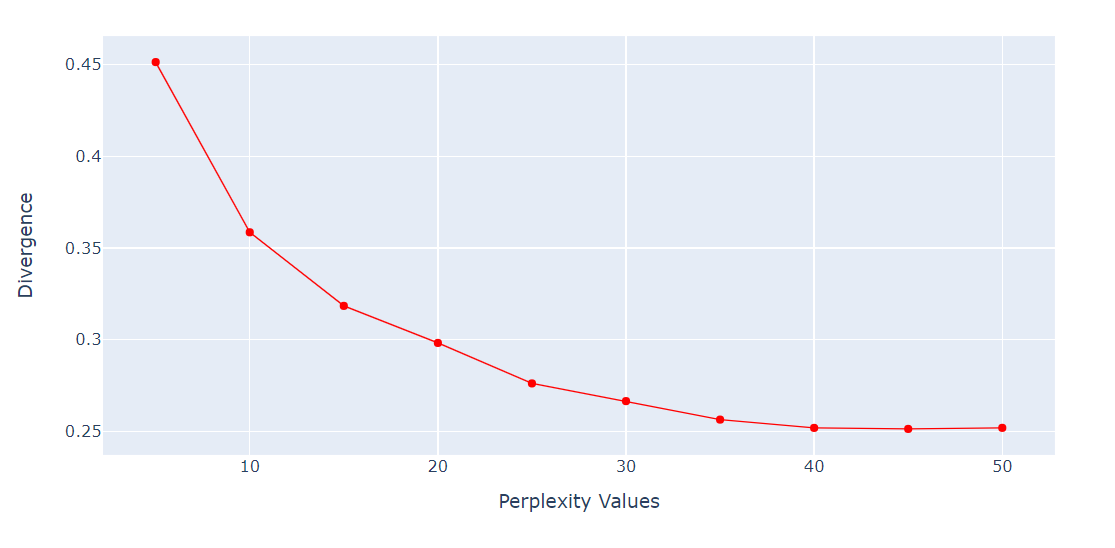
Perplexity adalah hiperparameter penting untuk algoritme t-SNE. Nilai ini mengontrol jumlah tetangga efektif yang dipertimbangkan setiap titik selama proses reduksi dimensi.
Kita akan menjalankan loop untuk memperoleh metrik Divergensi KL pada berbagai nilai perplexity dari 5 hingga 55 dengan selang 5. Lalu, kita akan menampilkan hasilnya menggunakan line plot dari Plotly Express.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()Divergensi KL menjadi konstan setelah perplexity 40. Jadi, kita akan menggunakan perplexity 40 dalam algoritme t-SNE.
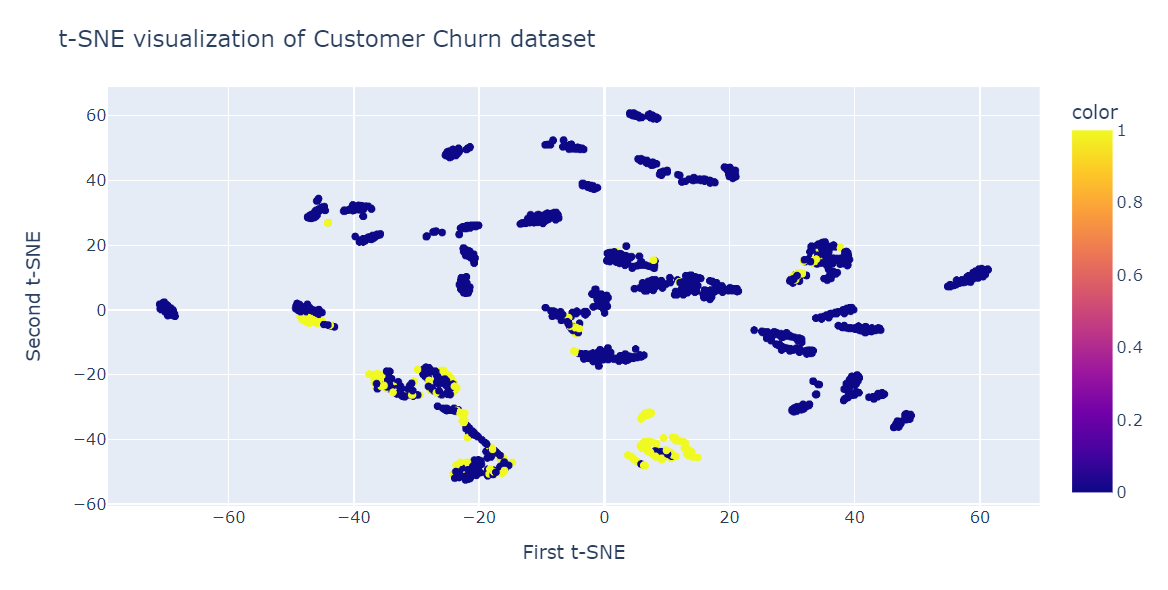
Sekarang kita akan melakukan fitting t-SNE dan mentransformasikan data ke dimensi lebih rendah menggunakan perplexity 40 untuk mendapatkan Divergensi KL serendah mungkin.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583Sekarang kita akan menggunakan Plotly Scatter plot untuk menampilkan komponen dan kelas target.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Seperti yang terlihat, kita memiliki banyak klaster dan subklaster. Informasi ini dapat digunakan untuk memahami pola dan mengembangkan strategi mempertahankan pelanggan yang ada.
Walaupun t-SNE adalah alat visualisasi yang kuat untuk data berdimensi tinggi, ada beberapa keterbatasan:
Dalam beberapa tahun terakhir, UMAP (Uniform Manifold Approximation and Projection) muncul sebagai alternatif populer untuk t-SNE. Meski keduanya merupakan teknik reduksi dimensi nonlinier yang dirancang untuk visualisasi, UMAP mengatasi beberapa keterbatasan t-SNE:
Tabel berikut merangkum kompleksitas komputasi t-SNE dibandingkan dengan UMAP dan PCA:
| Teknik | Kompleksitas komputasi | Fitur | Kecocokan untuk dataset besar |
|---|---|---|---|
| t-SNE | O(N2) | Melestarikan struktur lokal, sangat dapat dikustomisasi | Moderat (lambat untuk dataset besar) |
| UMAP | O(N log N) | Menyeimbangkan struktur lokal dan global, lebih cepat | Tinggi (menangani dataset besar secara efisien) |
| PCA | O(Nd2) | Reduksi linier, komponen yang dapat diinterpretasikan | Tinggi (sangat efisien) |
Singkatnya, sementara t-SNE memberikan wawasan mendetail tentang hubungan lokal, UMAP sering kali menjadi pilihan yang lebih efisien dan skalabel untuk dataset modern. PCA tetap menjadi opsi yang cepat dan dapat diinterpretasikan untuk data linier. Bergantung pada dataset dan tujuan, memilih teknik yang tepat melibatkan penyeimbangan antara interpretabilitas, biaya komputasi, dan sifat data.
Selain untuk memvisualisasikan data multi-dimensi yang kompleks, t-SNE juga memiliki kegunaan lain:
t-SNE adalah alat visualisasi yang kuat untuk mengungkap pola dan struktur tersembunyi dalam dataset yang kompleks. Anda dapat menggunakannya pada gambar, audio, data biologis, dan data tabular untuk mengidentifikasi anomali dan pola.
Pada artikel ini, kita telah mempelajari t-SNE, teknik reduksi dimensi populer yang dapat memvisualisasikan data nonlinier berdimensi tinggi dalam ruang berdimensi rendah. Kita telah menjelaskan gagasan utama di balik t-SNE, cara kerjanya, dan aplikasinya. Selain itu, kami menunjukkan beberapa contoh penerapan t-SNE pada dataset sintetis dan nyata serta cara menafsirkan hasilnya.
t-SNE merupakan bagian dari Unsupervised Learning, dan langkah alami berikutnya adalah memahami hierarchical clustering, PCA, decorrelating, dan menemukan fitur yang dapat diinterpretasikan. Pelajari semua topik tersebut dengan mengikuti kursus Unsupervised Learning in Python kami.
Pelajari lebih lanjut tentang Python
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
