
Corso
Introduzione a Python
4 h
6.9M
In questo tutorial vedremo come funziona t-SNE, una potente tecnica per la riduzione della dimensionalità e la visualizzazione dei dati. La confronteremo con un'altra tecnica molto diffusa, la PCA, e mostreremo come eseguire sia t-SNE sia PCA con scikit-learn e plotly express su dataset sintetici e reali.
t-SNE (t-distributed Stochastic Neighbor Embedding) è una tecnica non supervisionata e non lineare di riduzione della dimensionalità per l'esplorazione e la visualizzazione di dati ad alta dimensionalità. Riduzione della dimensionalità non lineare significa che l'algoritmo permette di separare dati che non possono essere separati con una linea retta.

t-SNE ti dà un'idea e un'intuizione su come i dati sono disposti in dimensioni superiori. È spesso usato per visualizzare dataset complessi in due o tre dimensioni, consentendoci di comprendere meglio pattern e relazioni sottostanti nei dati.
Segui il nostro corso Dimensionality Reduction in Python per imparare a esplorare dati ad alta dimensionalità, selezionare le feature ed estrarle.
Sia t-SNE che PCA sono tecniche di riduzione della dimensionalità con meccanismi diversi che funzionano al meglio con tipologie di dati differenti.
PCA (Principal Component Analysis) è una tecnica lineare che funziona meglio con dati che presentano una struttura lineare. Cerca di identificare le componenti principali sottostanti nei dati proiettandoli in dimensioni inferiori, minimizzando la varianza residua e preservando grandi distanze a coppie. Leggi il nostro tutorial Principal Component Analysis (PCA) per capire a fondo gli algoritmi con esempi in R.
t-SNE, invece, è una tecnica non lineare che si concentra nel preservare le somiglianze a coppie tra i punti dati in uno spazio a dimensionalità inferiore. t-SNE si preoccupa di preservare le piccole distanze a coppie, mentre PCA si concentra sul mantenimento delle grandi distanze a coppie per massimizzare la varianza.
In sintesi, PCA preserva la varianza nei dati. Al contrario, t-SNE preserva le relazioni tra i punti dati in uno spazio a dimensionalità inferiore, risultando un ottimo algoritmo per visualizzare dati complessi ad alta dimensionalità.
La seguente tabella può aiutarti a confrontare t-SNE e PCA fianco a fianco:
| Caratteristica | t-SNE | PCA |
|---|---|---|
| Tipologia | Riduzione della dimensionalità non lineare | Riduzione della dimensionalità lineare |
| Obiettivo | Preservare le somiglianze locali a coppie | Preservare la varianza globale |
| Ideale per | Visualizzare dati complessi e ad alta dimensionalità | Dati con struttura lineare |
| Output | Rappresentazione a bassa dimensionalità | Componenti principali |
| Casi d'uso | Clustering, rilevamento anomalie, NLP | Riduzione del rumore, estrazione di feature |
| Intensità computazionale | Alta | Bassa |
| Interpretazione | Più difficile da interpretare | Più facile da interpretare |
L'algoritmo t-SNE calcola una misura di similarità tra coppie di istanze nello spazio a dimensioni alte e basse. Poi cerca di ottimizzare due misure di similarità. Il tutto avviene in tre passaggi.
Il processo di ottimizzazione consente la creazione di cluster e sotto-cluster di punti simili nello spazio a bassa dimensionalità, che vengono visualizzati per comprendere la struttura e le relazioni nei dati ad alta dimensionalità.
Nell'esempio in Python genereremo dati di classificazione, eseguiremo PCA e t-SNE e visualizzeremo i risultati. Useremo scikit-learn per la riduzione della dimensionalità e useremo Plotly Express per la visualizzazione.
Useremo la funzione make_classification() di scikit-learn per generare dati sintetici con 6 feature, 1500 campioni e 3 classi.
Dopodiché realizzeremo un grafico 3D delle prime tre feature usando la funzione Plotly Express scatter_3d().
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()Abbiamo un grafico 3D dei dati; puoi anche visualizzare i dati in un grafico 2D usando la funzione scatter() di Plotly Express.
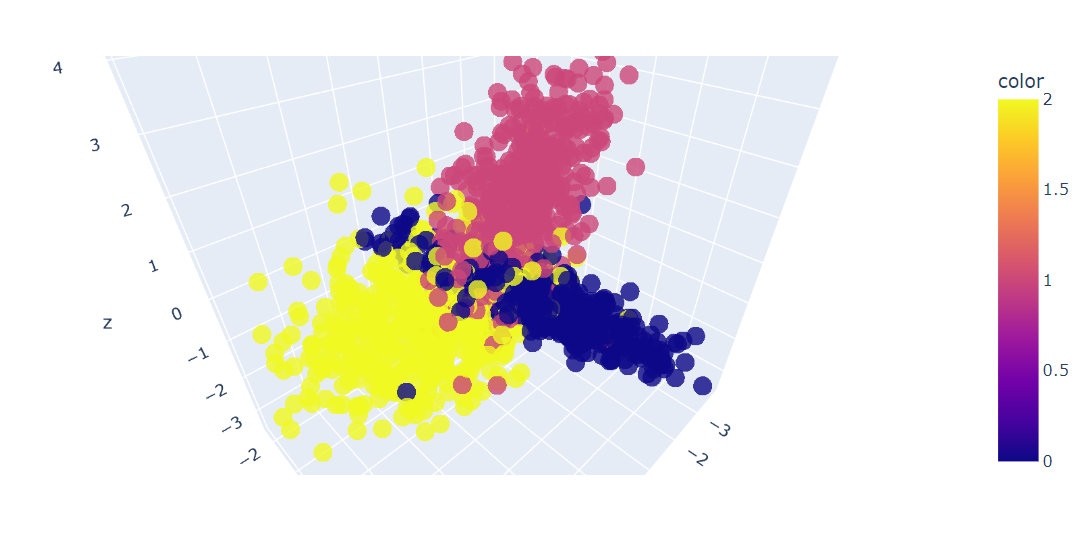
Ora applicheremo l'algoritmo PCA al dataset per ottenere due componenti PCA. fit_transform() apprende e trasforma il dataset allo stesso tempo.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)Possiamo ora visualizzare i risultati mostrando due componenti PCA in uno scatter plot.
Abbiamo anche usato la funzione update_layout() per aggiungere un titolo e rinominare gli assi x e y.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()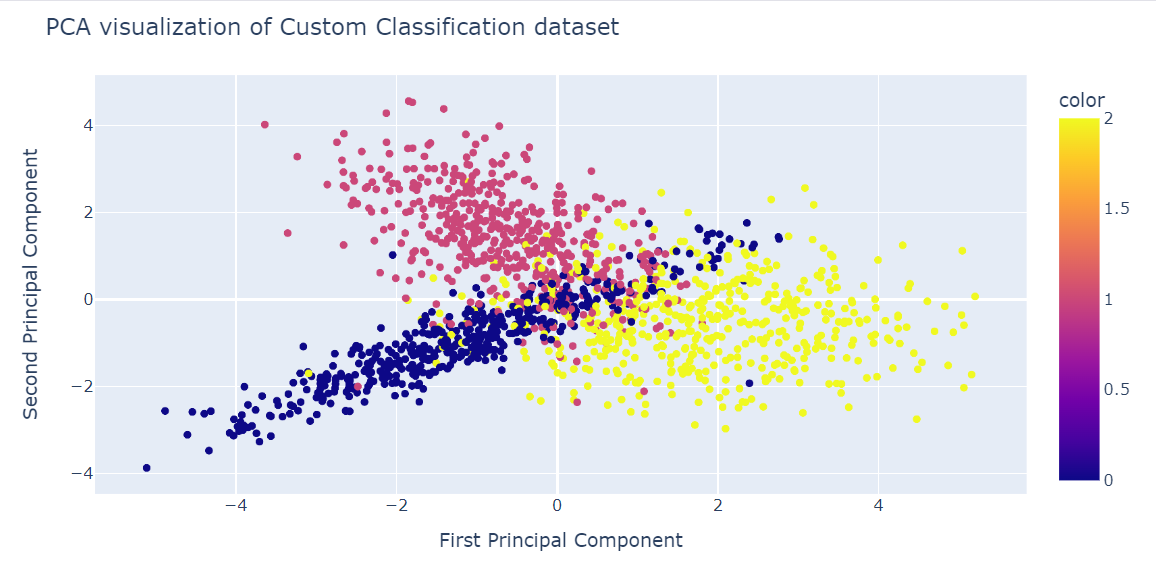
Ora applicheremo l'algoritmo t-SNE al dataset e confronteremo i risultati.
Dopo aver fatto il fit e trasformato i dati, mostreremo la divergenza di Kullback–Leibler (KL) tra le distribuzioni di probabilità ad alta e bassa dimensionalità. Una bassa divergenza KL è in genere indice di risultati migliori.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
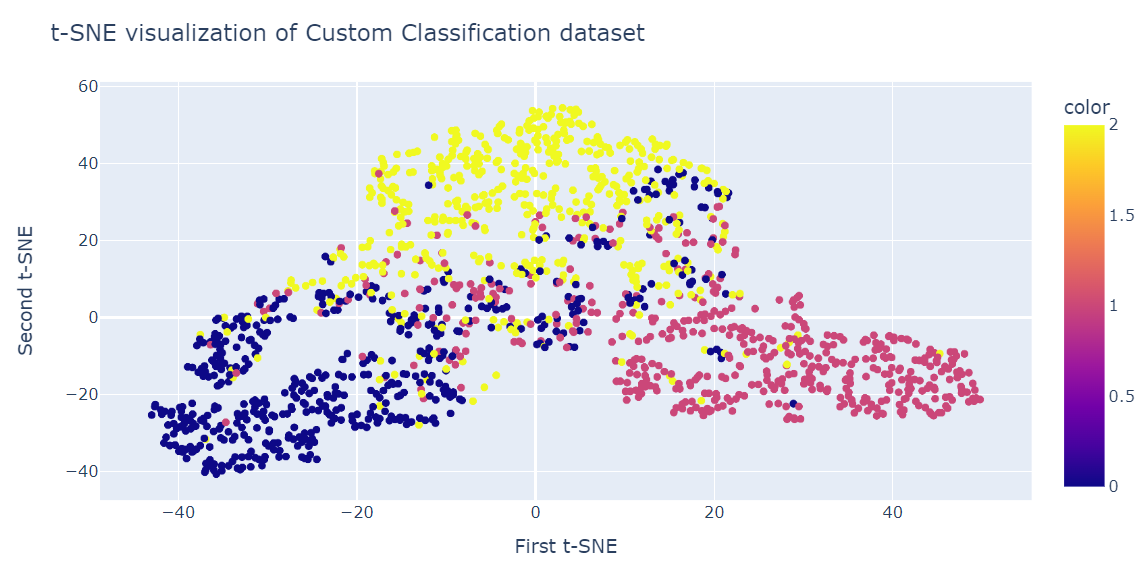
tsne.kl_divergence_1.1169137954711914In modo analogo alla PCA, visualizzeremo due componenti t-SNE in uno scatter plot.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Il risultato è nettamente migliore della PCA. Si vedono chiaramente tre grandi cluster.
In questa sezione useremo il dataset di customer churn di una compagnia telefonica iraniana. Il dataset contiene informazioni sull'attività dei clienti, come fallimenti delle chiamate e durata dell'abbonamento, e un'etichetta di churn.
Per churn si intende la percentuale di clienti che smettono di usare un determinato servizio in un dato periodo di tempo.
Nota: Il codice sorgente e il dataset di entrambi gli esempi sono disponibili in questo workbook di DataLab; se vuoi modificare ed eseguire il codice, ti basta farne una copia e sei a posto!
Caricheremo il dataset con pandas e mostreremo le prime tre righe.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Dopodiché, procederemo così:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
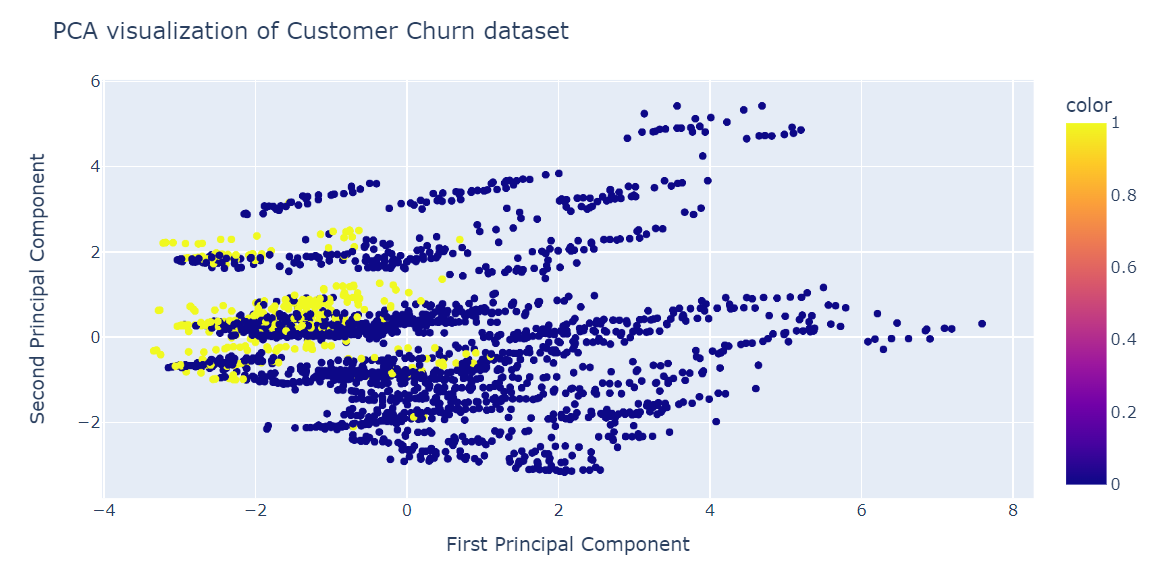
pca.score(X_test)-17.04482851288105Ora visualizzeremo il risultato della PCA usando lo scatter plot di Plotly Express.
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()La PCA non è stata efficace nel creare cluster. I dati nello spazio a bassa dimensionalità sembrano casuali. Potrebbe anche significare che le feature del dataset sono fortemente asimmetriche o che non presentano una forte struttura di correlazione.
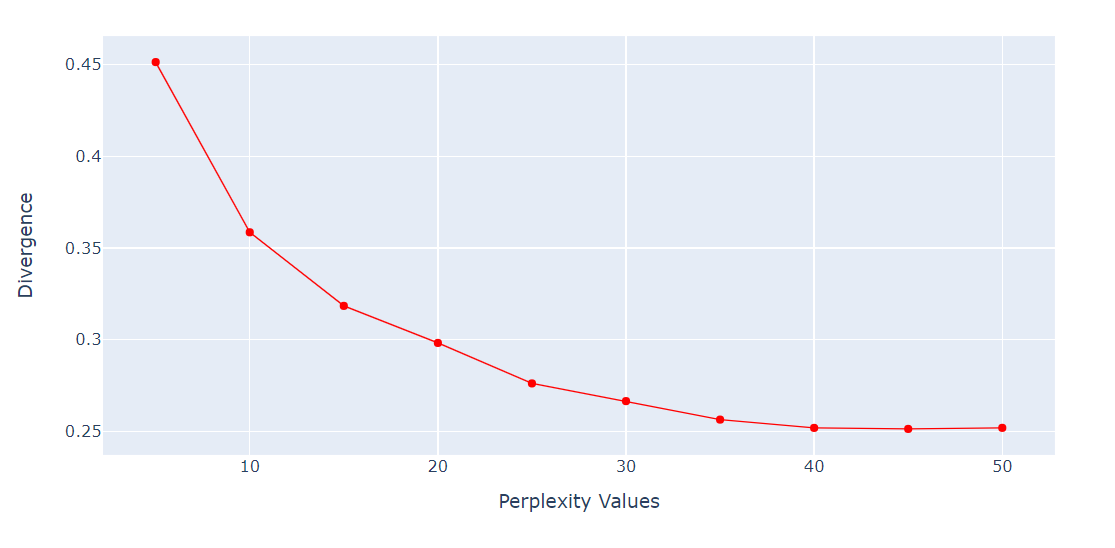
La perplexity è un iperparametro importante per l'algoritmo t-SNE. Controlla il numero effettivo di vicini che ogni punto considera durante il processo di riduzione della dimensionalità.
Eseguiremo un ciclo per ottenere la metrica di divergenza KL su varie perplexity da 5 a 55 con passo 5. Poi mostreremo il risultato con un line plot di Plotly Express.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()La divergenza KL diventa costante dopo una perplexity di 40. Quindi useremo perplexity 40 nell'algoritmo t-SNE.
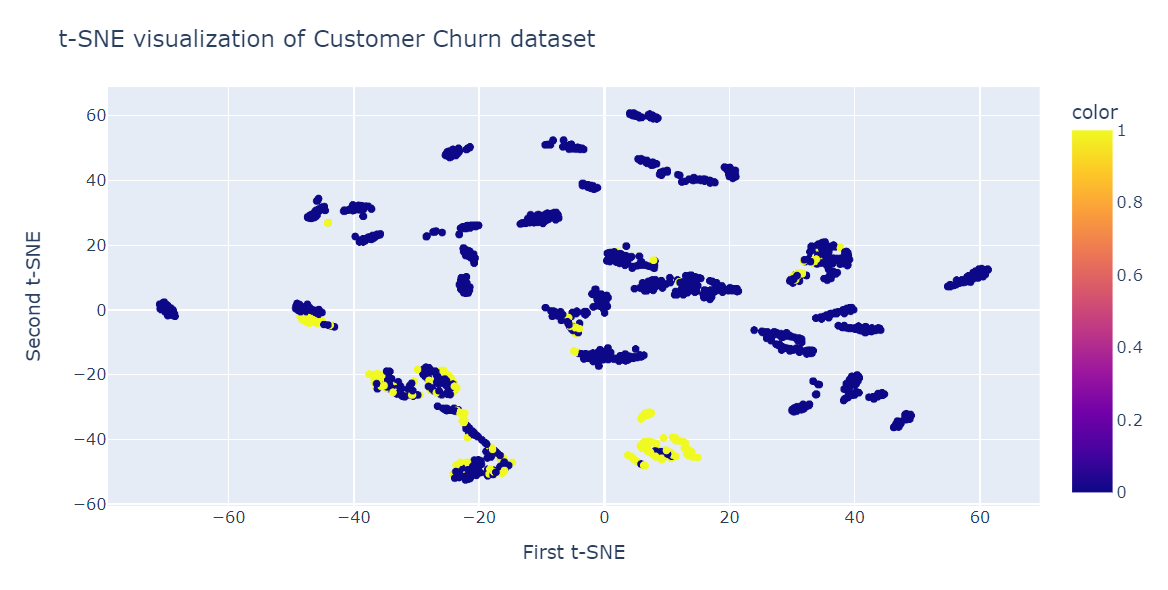
Ora eseguiremo il fit di t-SNE e trasformeremo i dati in dimensioni inferiori usando perplexity 40 per ottenere la divergenza KL più bassa.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583Ora useremo lo scatter plot di Plotly per mostrare componenti e classi target.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Come possiamo vedere, ci sono più cluster e sotto-cluster. Possiamo usare queste informazioni per comprendere il pattern e sviluppare una strategia per trattenere i clienti esistenti.
Sebbene t-SNE sia un potente strumento di visualizzazione per dati ad alta dimensionalità, presenta alcune limitazioni:
Negli ultimi anni, UMAP (Uniform Manifold Approximation and Projection) è emersa come un'alternativa popolare a t-SNE. Sebbene entrambe siano tecniche non lineari di riduzione della dimensionalità pensate per la visualizzazione, UMAP affronta alcune delle limitazioni di t-SNE:
La tabella seguente riassume la complessità computazionale di t-SNE rispetto a UMAP e PCA:
| Tecnica | Complessità computazionale | Caratteristiche | Adatta a dataset grandi |
|---|---|---|---|
| t-SNE | O(N2) | Preserva la struttura locale, altamente personalizzabile | Moderata (lenta per dataset grandi) |
| UMAP | O(N log N) | Bilancia struttura locale e globale, più veloce | Alta (gestisce in modo efficiente dataset grandi) |
| PCA | O(Nd2) | Riduzione lineare, componenti interpretabili | Alta (molto efficiente) |
In sintesi, mentre t-SNE fornisce informazioni dettagliate sulle relazioni locali, UMAP è spesso una scelta più efficiente e scalabile per i dataset moderni. PCA resta un'opzione veloce e interpretabile per dati lineari. A seconda del dataset e degli obiettivi, la scelta della tecnica giusta implica bilanciare interpretabilità, costo computazionale e natura dei dati.
Oltre a visualizzare dati complessi multidimensionali, t-SNE ha altri utilizzi:
t-SNE è un potente strumento di visualizzazione per rivelare pattern e strutture nascoste in dataset complessi. Puoi usarlo con immagini, audio, dati biologici e dati tabellari per identificare anomalie e pattern.
In questo post abbiamo visto t-SNE, una tecnica popolare di riduzione della dimensionalità che può visualizzare dati non lineari ad alta dimensionalità in uno spazio a bassa dimensionalità. Abbiamo spiegato l'idea di base di t-SNE, come funziona e le sue applicazioni. Inoltre, abbiamo mostrato alcuni esempi di applicazione di t-SNE a dataset sintetici e reali e come interpretarne i risultati.
t-SNE fa parte dell'apprendimento non supervisionato e il passo successivo naturale è comprendere il clustering gerarchico, la PCA, la decorrelazione e la scoperta di feature interpretabili. Impara tutti questi argomenti con il nostro corso Unsupervised Learning in Python.
Scopri di più su Python
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

