
Courses
Nhập môn Python
4 giờ
6.9M
Trong hướng dẫn này, chúng ta sẽ tìm hiểu cách hoạt động của t-SNE, một kỹ thuật mạnh mẽ để giảm chiều và trực quan hóa dữ liệu. Chúng ta sẽ so sánh t-SNE với một kỹ thuật phổ biến khác là PCA, và minh họa cách thực hiện cả t-SNE và PCA bằng scikit-learn và plotly express trên các bộ dữ liệu tổng hợp và thực tế.
t-SNE (t-distributed Stochastic Neighbor Embedding) là một kỹ thuật giảm chiều phi tuyến không giám sát dùng cho khám phá dữ liệu và trực quan hóa dữ liệu có số chiều cao. Giảm chiều phi tuyến có nghĩa là thuật toán cho phép chúng ta tách dữ liệu không thể phân tách bằng một đường thẳng.

t-SNE giúp bạn hình dung và trực giác về cách dữ liệu được sắp xếp trong không gian có số chiều cao. Nó thường được dùng để trực quan hóa các bộ dữ liệu phức tạp sang hai hoặc ba chiều, cho phép chúng ta hiểu rõ hơn về các mẫu và mối quan hệ tiềm ẩn trong dữ liệu.
Hãy tham gia khóa học Dimensionality Reduction in Python để học về khám phá dữ liệu nhiều chiều, chọn lọc đặc trưng và trích xuất đặc trưng.
Cả t-SNE và PCA đều là các kỹ thuật giảm chiều nhưng có cơ chế khác nhau và phù hợp nhất với các loại dữ liệu khác nhau.
PCA (Phân tích Thành phần Chính) là một kỹ thuật tuyến tính, hoạt động tốt nhất với dữ liệu có cấu trúc tuyến tính. Nó tìm cách xác định các thành phần chính tiềm ẩn trong dữ liệu bằng cách chiếu xuống không gian có số chiều thấp hơn, tối thiểu hóa phương sai bị mất và bảo toàn các khoảng cách cặp lớn. Đọc hướng dẫn Principal Component Analysis (PCA) của chúng tôi để hiểu cách thức hoạt động bên trong của các thuật toán với ví dụ R.
Trong khi đó, t-SNE là một kỹ thuật phi tuyến tập trung vào việc bảo toàn độ tương đồng theo cặp giữa các điểm dữ liệu trong không gian có số chiều thấp hơn. t-SNE chú trọng bảo toàn các khoảng cách cặp nhỏ, trong khi PCA tập trung duy trì các khoảng cách cặp lớn để tối đa hóa phương sai.
Tóm lại, PCA bảo toàn phương sai trong dữ liệu. Ngược lại, t-SNE bảo toàn mối quan hệ giữa các điểm dữ liệu trong không gian có số chiều thấp, khiến nó trở thành thuật toán khá tốt để trực quan hóa dữ liệu phức tạp có số chiều cao.
Bảng sau có thể giúp bạn so sánh t-SNE và PCA song song:
| Đặc điểm | t-SNE | PCA |
|---|---|---|
| Loại | Giảm chiều phi tuyến | Giảm chiều tuyến tính |
| Mục tiêu | Bảo toàn độ tương đồng cục bộ theo cặp | Bảo toàn phương sai toàn cục |
| Phù hợp nhất cho | Trực quan hóa dữ liệu phức tạp, nhiều chiều | Dữ liệu có cấu trúc tuyến tính |
| Đầu ra | Biểu diễn có số chiều thấp | Các thành phần chính |
| Trường hợp sử dụng | Phân cụm, phát hiện bất thường, NLP | Giảm nhiễu, trích xuất đặc trưng |
| Cường độ tính toán | Cao | Thấp |
| Diễn giải | Khó diễn giải hơn | Dễ diễn giải hơn |
Thuật toán t-SNE tìm độ đo tương đồng giữa các cặp mẫu trong không gian có số chiều cao và thấp. Sau đó, nó cố gắng tối ưu hóa hai độ đo tương đồng này. Toàn bộ quá trình gồm ba bước.
Quá trình tối ưu hóa cho phép tạo ra các cụm và tiểu cụm của những điểm dữ liệu tương tự trong không gian chiều thấp, từ đó trực quan hóa để hiểu cấu trúc và mối quan hệ trong dữ liệu nhiều chiều.
Trong ví dụ Python, chúng ta sẽ tạo dữ liệu phân loại, thực hiện PCA và t-SNE, và trực quan hóa kết quả. Chúng ta sẽ dùng scikit-learn để giảm chiều, và sẽ dùng Plotly Express để trực quan hóa.
Chúng ta sẽ dùng hàm make_classification() của scikit-learn để tạo dữ liệu tổng hợp với 6 đặc trưng, 1500 mẫu và 3 lớp.
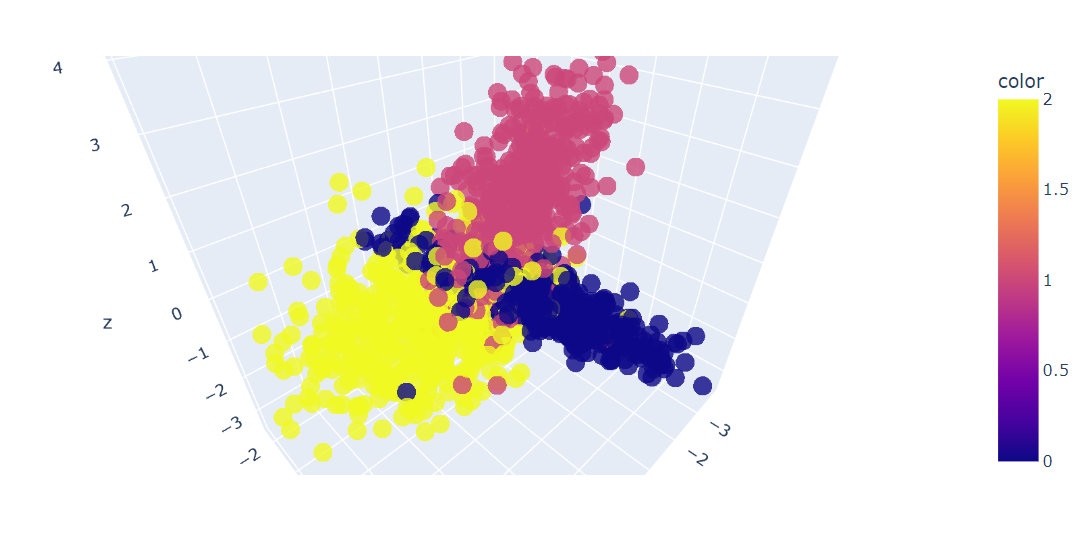
Sau đó, chúng ta sẽ vẽ 3D ba đặc trưng đầu tiên của dữ liệu bằng hàm Plotly Express scatter_3d().
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()Chúng ta đã có biểu đồ 3D của dữ liệu; bạn cũng có thể trực quan hóa dữ liệu trên biểu đồ 2D bằng cách dùng hàm scatter() của Plotly Express.
Bây giờ chúng ta sẽ áp dụng thuật toán PCA lên bộ dữ liệu để trả về hai thành phần PCA. Phương thức fit_transform() vừa học vừa biến đổi bộ dữ liệu cùng lúc.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)Giờ chúng ta có thể trực quan hóa kết quả bằng cách hiển thị hai thành phần PCA trên biểu đồ phân tán.
Chúng ta cũng dùng hàm update_layout() để thêm tiêu đề và đổi tên trục x và trục y.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()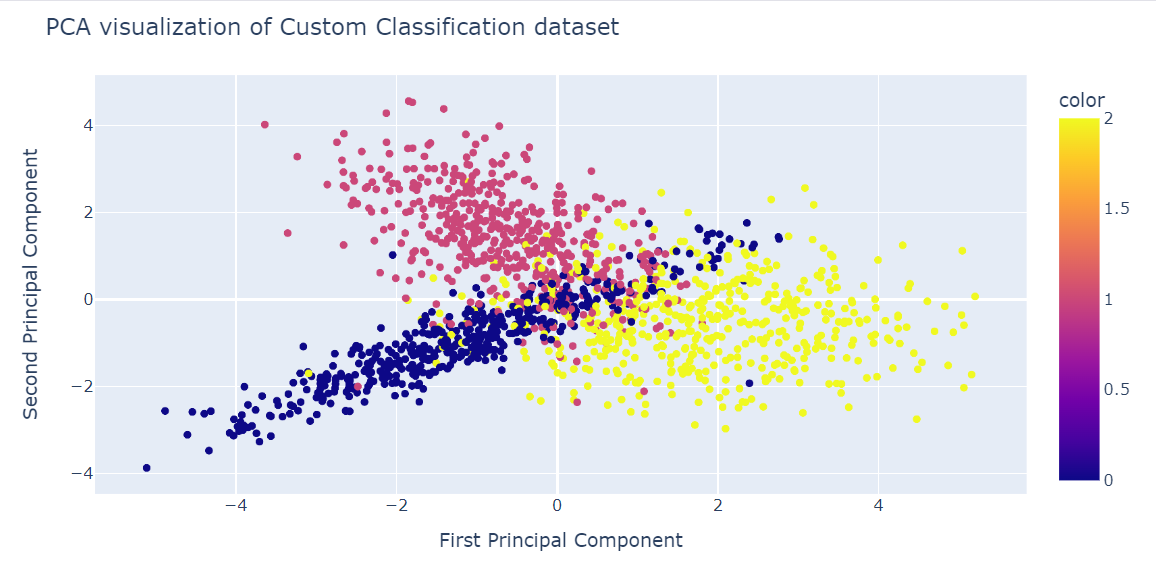
Bây giờ, chúng ta sẽ áp dụng thuật toán t-SNE lên bộ dữ liệu và so sánh kết quả.
Sau khi fit và biến đổi dữ liệu, chúng ta sẽ hiển thị độ lệch Kullback-Leibler (KL) giữa các phân phối xác suất ở chiều cao và chiều thấp. KL divergence thấp thường là dấu hiệu của kết quả tốt hơn.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
tsne.kl_divergence_1.1169137954711914Tương tự PCA, chúng ta sẽ trực quan hóa hai thành phần t-SNE trên biểu đồ phân tán.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Kết quả tốt hơn khá rõ so với PCA. Chúng ta có thể thấy rõ ba cụm lớn.
Trong phần này, chúng ta sẽ dùng bộ dữ liệu customer churn của một công ty viễn thông Iran. Bộ dữ liệu chứa thông tin về hoạt động của khách hàng, như lỗi cuộc gọi và thời gian đăng ký, cùng với nhãn churn.
Churn nghĩa là tỷ lệ phần trăm khách hàng ngừng sử dụng một dịch vụ nhất định trong một khoảng thời gian cụ thể.
Lưu ý: Mã nguồn và bộ dữ liệu của cả hai ví dụ đều có trong DataLab workbook này; nếu bạn muốn điều chỉnh và chạy mã, chỉ cần tạo một bản sao, là bạn có thể bắt đầu!
Chúng ta sẽ tải bộ dữ liệu bằng pandas và hiển thị ba hàng đầu tiên.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Sau đó, chúng ta sẽ:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
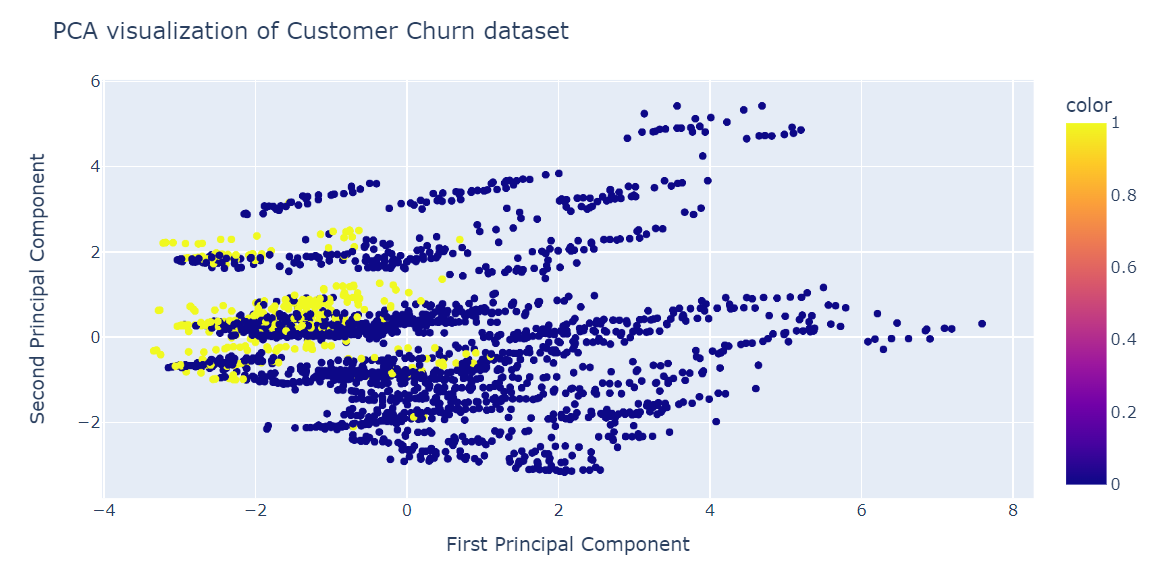
pca.score(X_test)-17.04482851288105Bây giờ chúng ta sẽ trực quan hóa kết quả PCA bằng biểu đồ phân tán của Plotly Express.
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()PCA không tốt trong việc tạo cụm. Dữ liệu ở chiều thấp trông khá ngẫu nhiên. Điều này cũng có thể nghĩa là các đặc trưng trong bộ dữ liệu bị lệch mạnh hoặc không có cấu trúc tương quan rõ rệt.
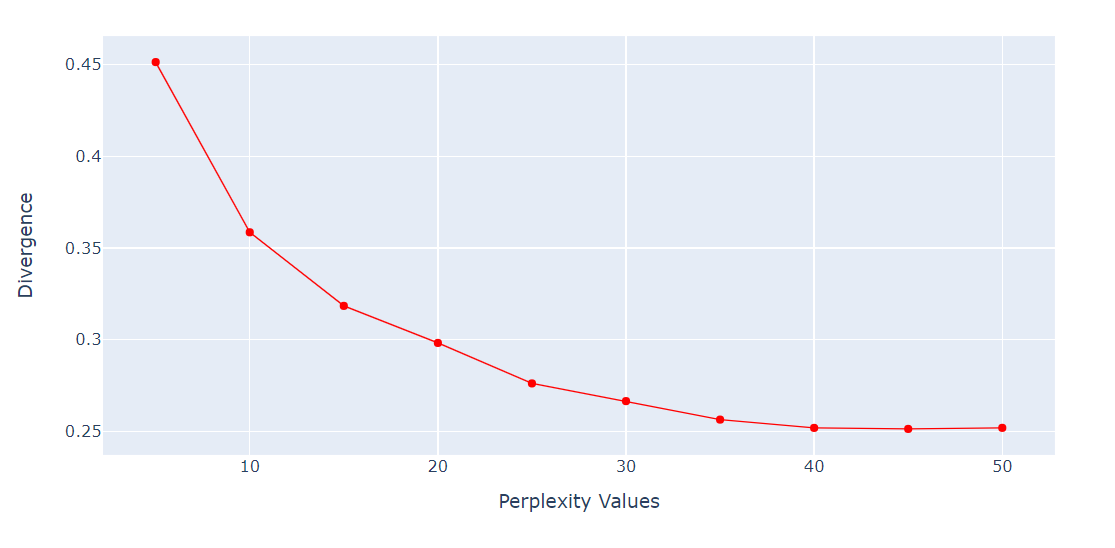
Perplexity là một siêu tham số quan trọng của thuật toán t-SNE. Nó kiểm soát số lượng láng giềng hiệu dụng mà mỗi điểm xem xét trong quá trình giảm chiều.
Chúng ta sẽ chạy vòng lặp để lấy chỉ số KL Divergence tại các giá trị perplexity khác nhau từ 5 đến 55 với bước 5. Sau đó, hiển thị kết quả bằng biểu đồ đường của Plotly Express.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()KL Divergence trở nên gần như hằng số sau perplexity 40. Vì vậy, chúng ta sẽ dùng perplexity 40 trong thuật toán t-SNE.
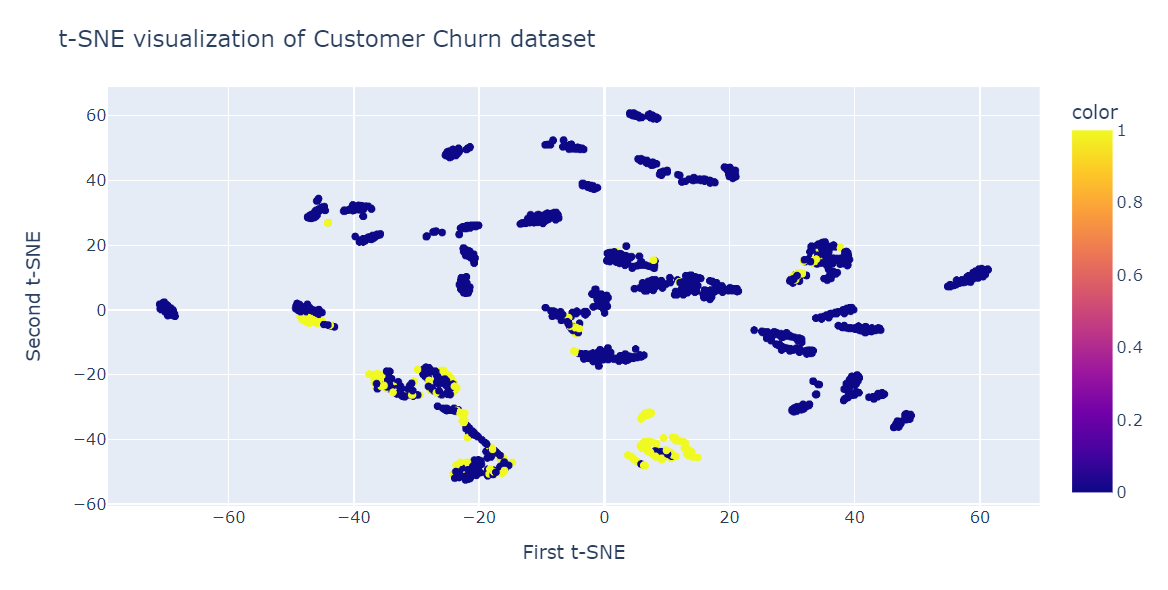
Bây giờ chúng ta sẽ fit t-SNE và biến đổi dữ liệu sang chiều thấp hơn với perplexity 40 để đạt KL Divergence thấp nhất.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583Chúng ta sẽ dùng biểu đồ phân tán Plotly để hiển thị các thành phần và lớp mục tiêu.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Như chúng ta thấy, có nhiều cụm và tiểu cụm. Ta có thể dùng thông tin này để hiểu mô hình và xây dựng chiến lược giữ chân khách hàng hiện tại.
Mặc dù t-SNE là công cụ trực quan hóa mạnh mẽ cho dữ liệu nhiều chiều, nó vẫn có một số hạn chế:
Những năm gần đây, UMAP (Uniform Manifold Approximation and Projection) nổi lên như một lựa chọn thay thế phổ biến cho t-SNE. Dù cả hai đều là kỹ thuật giảm chiều phi tuyến phục vụ trực quan hóa, UMAP giải quyết một số hạn chế của t-SNE:
Bảng sau tóm tắt độ phức tạp tính toán của t-SNE so với UMAP và PCA:
| Kỹ thuật | Độ phức tạp tính toán | Đặc trưng | Phù hợp với bộ dữ liệu lớn |
|---|---|---|---|
| t-SNE | O(N2) | Bảo toàn cấu trúc cục bộ, tùy biến cao | Trung bình (chậm với bộ dữ liệu lớn) |
| UMAP | O(N log N) | Cân bằng cấu trúc cục bộ và toàn cục, nhanh hơn | Cao (xử lý hiệu quả bộ dữ liệu lớn) |
| PCA | O(Nd2) | Giảm tuyến tính, thành phần dễ diễn giải | Cao (rất hiệu quả) |
Tóm lại, trong khi t-SNE cung cấp hiểu biết chi tiết về các mối quan hệ cục bộ, UMAP thường là lựa chọn hiệu quả và có khả năng mở rộng hơn cho các bộ dữ liệu hiện đại. PCA vẫn là lựa chọn nhanh và dễ diễn giải cho dữ liệu tuyến tính. Tùy thuộc vào bộ dữ liệu và mục tiêu, việc chọn kỹ thuật phù hợp cần cân bằng giữa khả năng diễn giải, chi phí tính toán và bản chất dữ liệu.
Ngoài việc trực quan hóa dữ liệu đa chiều phức tạp, t-SNE còn có các ứng dụng khác:
t-SNE là một công cụ trực quan hóa mạnh mẽ để hé lộ các mẫu và cấu trúc ẩn trong những bộ dữ liệu phức tạp. Bạn có thể dùng nó cho hình ảnh, âm thanh, dữ liệu sinh học và dữ liệu đơn lẻ để nhận diện bất thường và mẫu.
Trong bài viết này, chúng ta đã tìm hiểu về t-SNE, một kỹ thuật giảm chiều phổ biến có thể trực quan hóa dữ liệu phi tuyến nhiều chiều trong không gian chiều thấp. Chúng ta đã giải thích ý tưởng chính đằng sau t-SNE, cách nó hoạt động và các ứng dụng của nó. Ngoài ra, chúng ta đã trình bày một số ví dụ áp dụng t-SNE cho dữ liệu tổng hợp và dữ liệu thực tế và cách diễn giải kết quả.
t-SNE là một phần của Học không giám sát, và bước tiếp theo tự nhiên là hiểu phân cụm phân cấp, PCA, khử tương quan và khám phá các đặc trưng có thể diễn giải. Học tất cả các chủ đề này trong khóa học Unsupervised Learning in Python của chúng tôi.
Tìm hiểu thêm về Python
Courses
Courses
Courses