
Cursus
Introductie tot Python
4 Hr
6.9M
In deze tutorial duiken we in de werking van t-SNE, een krachtige techniek voor dimensiereductie en datavisualisatie. We vergelijken het met een andere populaire techniek, PCA, en laten zien hoe je zowel t-SNE als PCA uitvoert met scikit-learn en plotly express op synthetische en real-world datasets.
t-SNE (t-distributed Stochastic Neighbor Embedding) is een onbewaakte, niet-lineaire dimensiereductietechniek voor data-exploratie en het visualiseren van hoog-dimensionale data. Niet-lineaire dimensiereductie betekent dat het algoritme ons in staat stelt data te scheiden die niet door een rechte lijn te scheiden is.

t-SNE geeft je gevoel en intuïtie voor hoe data in hogere dimensies is gerangschikt. Het wordt vaak gebruikt om complexe datasets te visualiseren in twee en drie dimensies, zodat we de onderliggende patronen en relaties in de data beter begrijpen.
Volg onze cursus Dimensiereductie in Python om te leren over het verkennen van hoog-dimensionale data, featureselectie en feature-extractie.
Zowel t-SNE als PCA zijn technieken voor dimensiereductie met verschillende mechanismen die het beste werken met verschillende soorten data.
PCA (Principal Component Analysis) is een lineaire techniek die het beste werkt met data met een lineaire structuur. Het probeert de onderliggende hoofdcomponenten in de data te identificeren door te projecteren naar lagere dimensies, de variantie te minimaliseren en grote paargewijze afstanden te behouden. Lees onze tutorial Principal Component Analysis (PCA) om de interne werking van de algoritmen te begrijpen met R-voorbeelden.
t-SNE daarentegen is een niet-lineaire techniek die zich richt op het behouden van de paargewijze gelijkenissen tussen datapunten in een lager-dimensionale ruimte. t-SNE richt zich op het behouden van kleine paargewijze afstanden, terwijl PCA zich richt op het behouden van grote paargewijze afstanden om de variantie te maximaliseren.
Samengevat: PCA behoudt de variantie in de data. t-SNE daarentegen behoudt de relaties tussen datapunten in een lager-dimensionale ruimte, waardoor het een goed algoritme is voor het visualiseren van complexe hoog-dimensionale data.
De volgende tabel helpt je t-SNE en PCA naast elkaar te vergelijken:
| Kenmerk | t-SNE | PCA |
|---|---|---|
| Type | Niet-lineaire dimensiereductie | Lineaire dimensiereductie |
| Doel | Lokale paargewijze gelijkenissen behouden | Globale variantie behouden |
| Beste toepassing voor | Visualiseren van complexe, hoog-dimensionale data | Data met lineaire structuur |
| Uitvoer | Lager-dimensionale representatie | Hoofdcomponenten |
| Use-cases | Clustering, anomaliedetectie, NLP | Ruisreductie, feature-extractie |
| Rekenintensiteit | Hoog | Laag |
| Interpretatie | Moeilijker te interpreteren | Makkelijker te interpreteren |
Het t-SNE-algoritme bepaalt de gelijkenis tussen paren instanties in hogere en lagere-dimensionale ruimte. Daarna probeert het twee gelijkenismaatstaven te optimaliseren. Dat doet het in drie stappen.
Het optimalisatieproces maakt het mogelijk om clusters en subclusters van vergelijkbare datapunten te creëren in de lager-dimensionale ruimte, die worden gevisualiseerd om de structuur en relaties in de hoog-dimensionale data te begrijpen.
In het Python-voorbeeld genereren we classificatiedata, voeren we PCA en t-SNE uit en visualiseren we de resultaten. We gebruiken scikit-learn voor dimensiereductie en we gebruiken Plotly Express voor visualisatie.
We gebruiken de functie make_classification() van scikit-learn om synthetische data te genereren met 6 features, 1500 samples en 3 klassen.
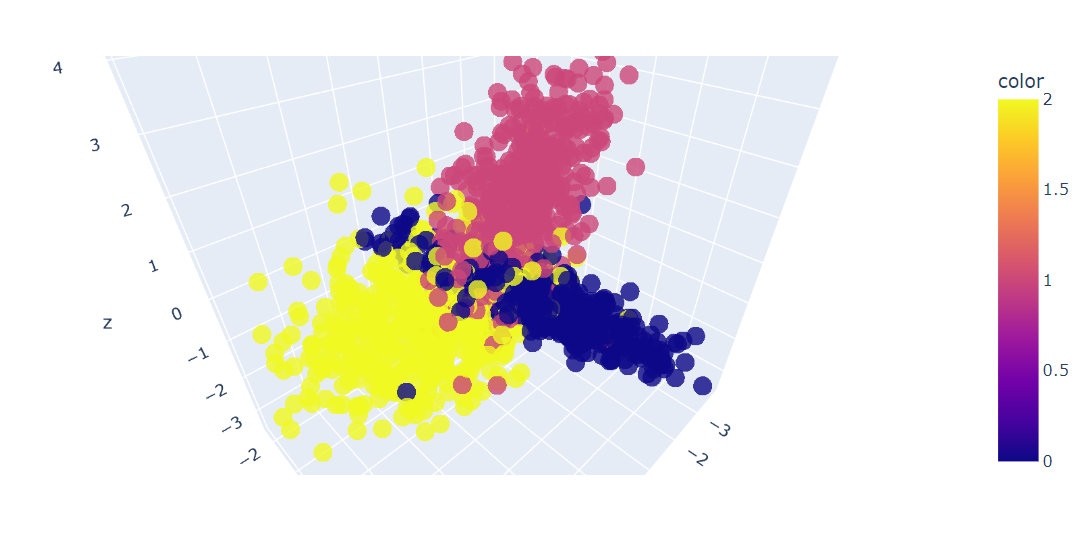
Daarna maken we een 3D-plot van de eerste drie features van de data met de Plotly Express-functie scatter_3d().
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()We hebben een 3D-plot van de data; je kunt de data ook in een 2D-grafiek visualiseren met de Plotly Express-functie scatter().
We passen nu het PCA-algoritme toe op de dataset om twee PCA-componenten terug te krijgen. De functie fit_transform() leert en transformeert de dataset tegelijk.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)We kunnen de resultaten nu visualiseren door twee PCA-componenten in een scatterplot weer te geven.
We hebben ook de functie update_layout() gebruikt om een titel toe te voegen en de x-as en y-as te hernoemen.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()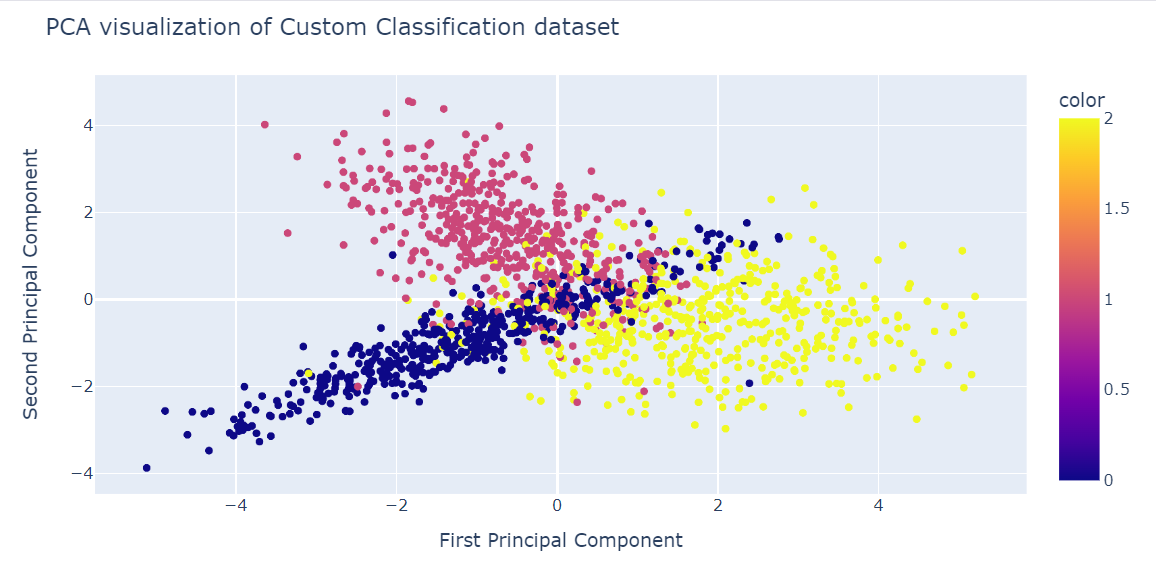
Nu passen we het t-SNE-algoritme toe op de dataset en vergelijken we de resultaten.
Na het fitten en transformeren van de data tonen we de Kullback-Leibler (KL) divergentie tussen de hoog- en laag-dimensionale waarschijnlijkheidsverdelingen. Een lage KL-divergentie is normaal gesproken een teken van betere resultaten.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
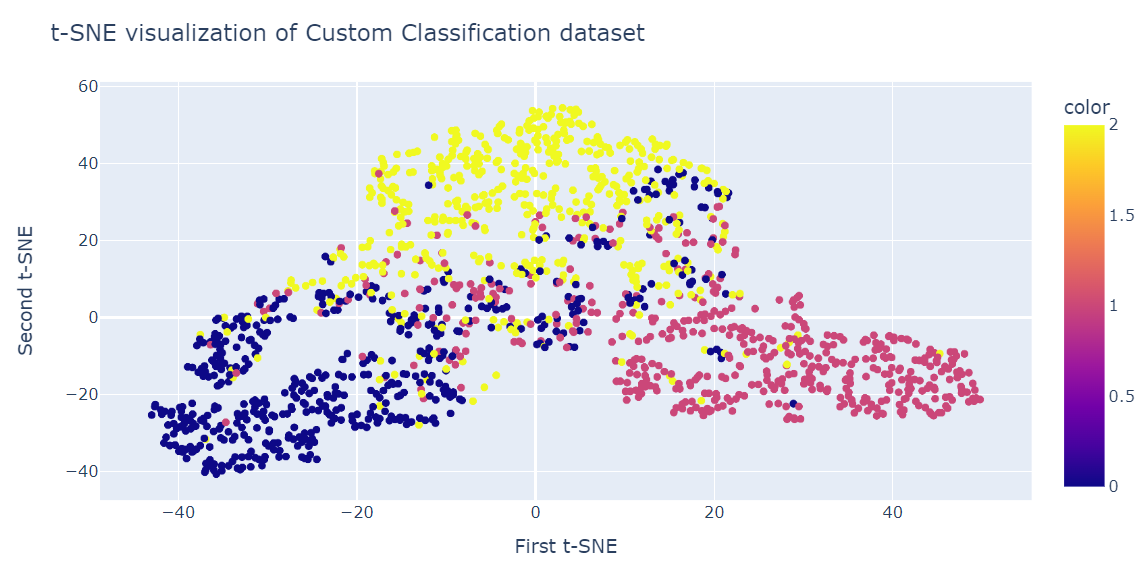
tsne.kl_divergence_1.1169137954711914Net als bij PCA visualiseren we twee t-SNE-componenten in een scatterplot.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Het resultaat is duidelijk beter dan PCA. We zien drie grote clusters.
In deze sectie gebruiken we de customer churn-dataset van een Iraans telecombedrijf. De dataset bevat informatie over de activiteit van klanten, zoals mislukte oproepen en abonnementsduur, en een churn-label.
Churn betekent het percentage klanten dat in een bepaalde periode stopt met het gebruik van een specifieke dienst.
Let op: De broncode en dataset van beide voorbeelden zijn beschikbaar in deze DataLab-werkmap; als je de code wilt aanpassen en uitvoeren, maak dan gewoon een kopie, en je kunt aan de slag!
We laden de dataset met pandas en tonen de eerste drie rijen.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Daarna zullen we:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
pca.score(X_test)-17.04482851288105We visualiseren nu het PCA-resultaat met de Plotly Express-scatterplot.
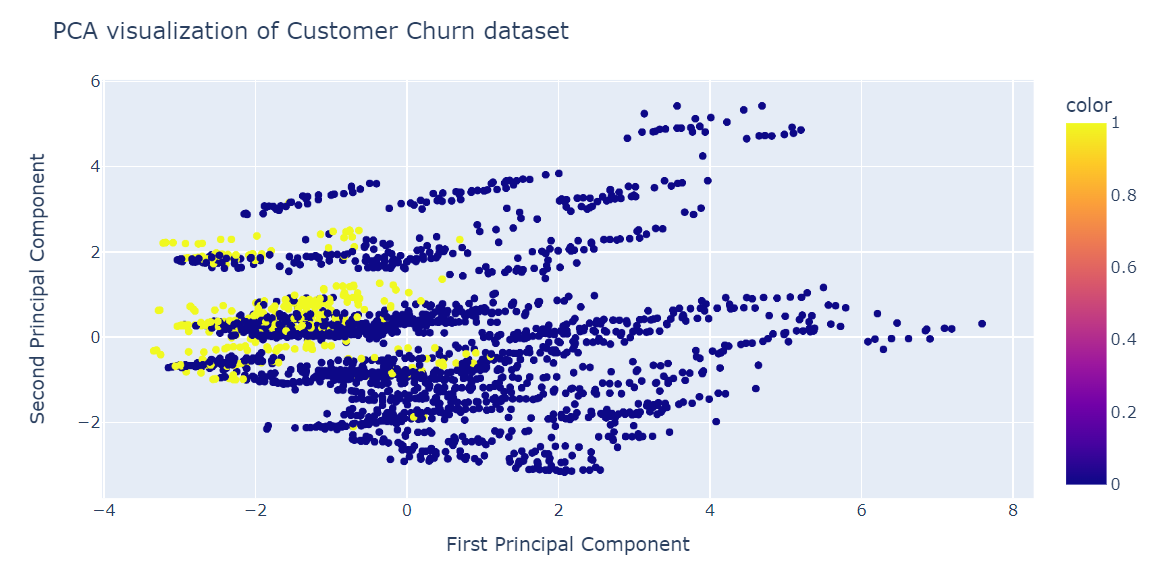
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()PCA was niet goed in het maken van clusters. De data ziet er in de lage dimensie willekeurig uit. Het kan ook betekenen dat de features in de dataset sterk scheef verdeeld zijn, of dat er geen sterke correlatiestructuur is.
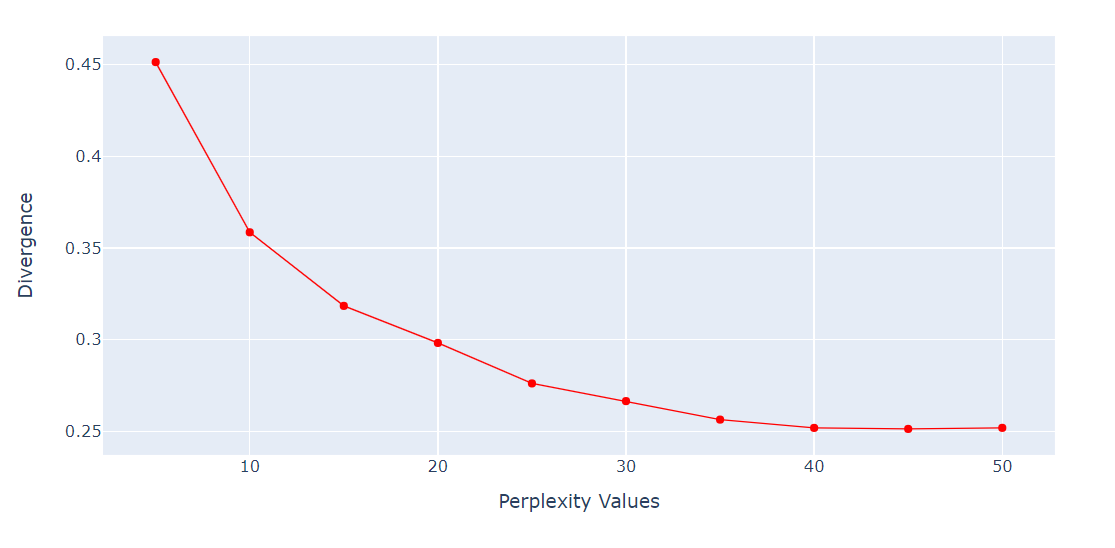
Perplexity is een belangrijke hyperparameter voor het t-SNE-algoritme. Het bepaalt het effectieve aantal buren dat elk punt in aanmerking neemt tijdens het dimensiereductieproces.
We draaien een lus om de KL-divergentie te verkrijgen bij verschillende perplexity-waarden van 5 tot 55 met stappen van 5. Vervolgens tonen we het resultaat met de Plotly Express-lijngrafiek.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()De KL-divergentie wordt constant na een perplexity van 40. Daarom gebruiken we een perplexity van 40 in het t-SNE-algoritme.
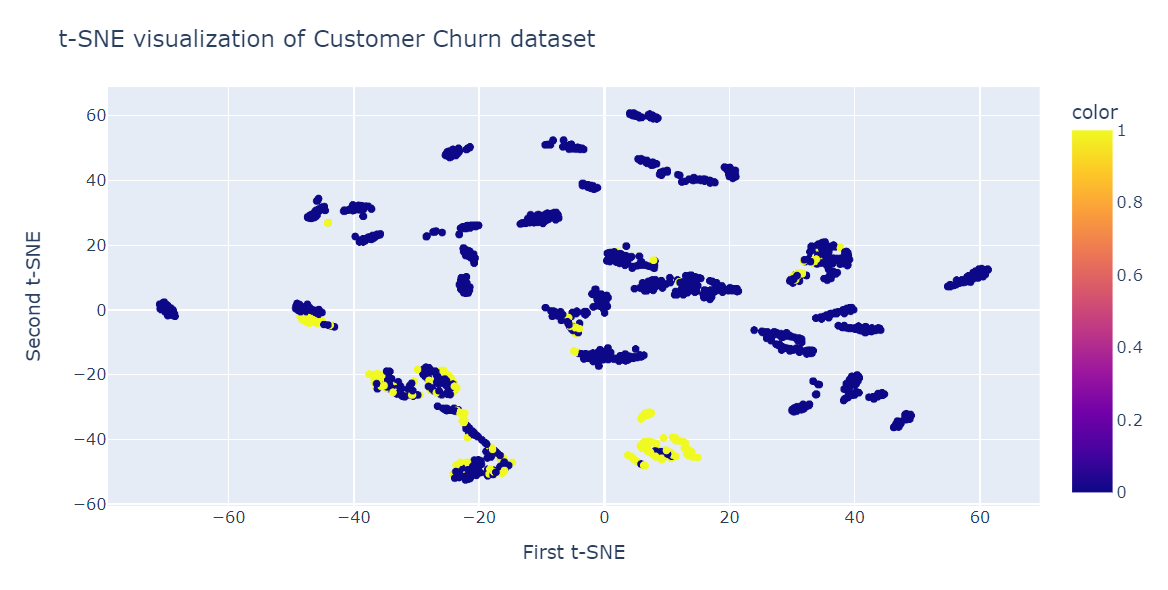
We fitten nu t-SNE en transformeren de data naar lagere dimensies met een perplexity van 40 om de laagste KL-divergentie te krijgen.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583We gebruiken nu de Plotly-scatterplot om componenten en targetklassen weer te geven.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Zoals we zien, zijn er meerdere clusters en subclusters. We kunnen deze informatie gebruiken om het patroon te begrijpen en een strategie te ontwikkelen om bestaande klanten te behouden.
Hoewel t-SNE een krachtig visualisatie-instrument is voor hoog-dimensionale data, zijn er enkele beperkingen:
De afgelopen jaren is UMAP (Uniform Manifold Approximation and Projection) opgekomen als een populair alternatief voor t-SNE. Hoewel beide niet-lineaire dimensiereductietechnieken zijn die ontworpen zijn voor visualisatie, pakt UMAP enkele beperkingen van t-SNE aan:
De volgende tabel vat de rekencomplexiteit van t-SNE samen in vergelijking met UMAP en PCA:
| Techniek | Rekencomplexiteit | Kenmerken | Geschiktheid voor grote datasets |
|---|---|---|---|
| t-SNE | O(N2) | Behoudt lokale structuur, sterk aanpasbaar | Gemiddeld (traag voor grote datasets) |
| UMAP | O(N log N) | Balanceert lokale en globale structuur, sneller | Hoog (verwerkt grote datasets efficiënt) |
| PCA | O(Nd2) | Lineaire reductie, interpreteerbare componenten | Hoog (zeer efficiënt) |
Samengevat: hoewel t-SNE gedetailleerde inzichten geeft in lokale relaties, is UMAP vaak een efficiëntere en schaalbaardere keuze voor moderne datasets. PCA blijft een snelle en interpreteerbare optie voor lineaire data. Afhankelijk van de dataset en doelen vraagt de juiste keuze om een balans tussen interpreteerbaarheid, rekenkosten en de aard van de data.
Naast het visualiseren van complexe multidimensionale data heeft t-SNE andere toepassingen:
t-SNE is een krachtig visualisatie-instrument om verborgen patronen en structuren in complexe datasets te onthullen. Je kunt het gebruiken voor afbeeldingen, audio, biologisch materiaal en individuele data om anomalieën en patronen te identificeren.
In deze blogpost hebben we t-SNE behandeld, een populaire dimensiereductietechniek die hoog-dimensionale niet-lineaire data kan visualiseren in een laag-dimensionale ruimte. We hebben het hoofdidee achter t-SNE, de werking en de toepassingen uitgelegd. Bovendien hebben we enkele voorbeelden laten zien van het toepassen van t-SNE op synthetische en echte datasets en hoe je de resultaten interpreteert.
t-SNE maakt deel uit van Unsupervised Learning, en de volgende logische stap is het begrijpen van hiërarchische clustering, PCA, decorrelatie en het ontdekken van interpreteerbare features. Leer al deze onderwerpen in onze cursus Unsupervised Learning in Python.
Leer meer over Python
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
