
Kurs
Python’a Giriş
4 sa
6.9M
Bu eğitimde, boyut indirgeme ve veri görselleştirme için güçlü bir teknik olan t-SNE’nin nasıl çalıştığını ele alacağız. Bunu bir başka popüler teknik olan PCA ile karşılaştıracak ve hem t-SNE hem de PCA’yı scikit-learn ve plotly express kullanarak sentetik ve gerçek dünyadan veri kümeleri üzerinde nasıl uygulayacağımızı göstereceğiz.
t-SNE (t-distributed Stochastic Neighbor Embedding), yüksek boyutlu verileri keşfetmek ve görselleştirmek için kullanılan gözetimsiz, doğrusal olmayan bir boyut indirgeme tekniğidir. Doğrusal olmayan boyut indirgeme, algoritmanın düz bir çizgiyle ayrılamayan verileri ayırmamıza imkân tanıdığı anlamına gelir.

t-SNE, verilerin daha yüksek boyutlarda nasıl düzenlendiğine dair bir sezgi kazandırır. Çoğunlukla karmaşık veri kümelerini iki ya da üç boyutta görselleştirmek için kullanılır; bu sayede verideki temel örüntüler ve ilişkiler hakkında daha fazla anlayış elde ederiz.
Yüksek boyutlu verileri keşfetme, özellik seçimi ve özellik çıkarımı hakkında bilgi edinmek için Python ile Boyut Azaltma kursumuzu alın.
Hem t-SNE hem de PCA, farklı mekanizmalara sahip boyut indirgeme teknikleridir ve farklı veri türlerinde en iyi şekilde çalışırlar.
PCA (Temel Bileşenler Analizi), doğrusal yapıya sahip verilerde en iyi sonuç veren doğrusal bir tekniktir. Veriyi daha düşük boyutlara yansıtarak altta yatan temel bileşenleri belirlemeye çalışır; varyansı en aza indirir ve büyük ikili uzaklıkları korur. Algoritmaların iç işleyişini R örnekleriyle anlamak için Principal Component Analysis (PCA) eğitimimizi okuyun.
Buna karşılık, t-SNE doğrusal olmayan bir tekniktir ve düşük boyutlu bir uzayda veri noktaları arasındaki ikili benzerlikleri korumaya odaklanır. t-SNE küçük ikili uzaklıkları korumakla ilgilenirken, PCA varyansı maksimize etmek için büyük ikili uzaklıkları korumaya odaklanır.
Özetle, PCA verideki varyansı korur. Buna karşın t-SNE, veri noktaları arasındaki ilişkileri düşük boyutlu bir uzayda korur; bu da onu karmaşık, yüksek boyutlu verileri görselleştirmek için oldukça iyi bir algoritma yapar.
Aşağıdaki tablo, t-SNE ve PCA’yı yan yana karşılaştırmanıza yardımcı olabilir:
| Özellik | t-SNE | PCA |
|---|---|---|
| Tür | Doğrusal olmayan boyut indirgeme | Doğrusal boyut indirgeme |
| Amaç | Yerel ikili benzerlikleri korumak | Küresel varyansı korumak |
| En uygun olduğu durum | Karmaşık, yüksek boyutlu verileri görselleştirme | Doğrusal yapılı veriler |
| Çıktı | Düşük boyutlu gösterim | Temel bileşenler |
| Kullanım alanları | Kümeleme, anomali tespiti, NLP | Gürültü azaltma, özellik çıkarımı |
| Hesaplama yoğunluğu | Yüksek | Düşük |
| Yorumlanabilirlik | Yorumlaması daha zor | Daha kolay yorumlanır |
t-SNE algoritması, yüksek ve düşük boyutlu uzayda örnek çiftleri arasındaki benzerlik ölçüsünü bulur. Ardından iki benzerlik ölçüsünü optimize etmeye çalışır. Tüm bunları üç adımda yapar.
Optimizasyon süreci, düşük boyutlu uzayda benzer veri noktalarının küme ve alt kümeler oluşturmasına olanak tanır; bunlar, yüksek boyutlu verideki yapı ve ilişkileri anlamak için görselleştirilir.
Python örneğinde, sınıflandırma verisi oluşturacak, PCA ve t-SNE uygulayacak ve sonuçları görselleştireceğiz. Boyut indirgeme için scikit-learn kullanacağız ve görselleştirme için de Plotly Express kullanacağız.
scikit-learn’ün make_classification() fonksiyonunu kullanarak 6 özellik, 1500 örnek ve 3 sınıfa sahip sentetik veri oluşturacağız.
Ardından, verinin ilk üç özelliğini Plotly Express scatter_3d() fonksiyonunu kullanarak 3B olarak çizeceğiz.
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()Verinin 3B çizimini elde ettik; ayrıca Plotly Express’in scatter() fonksiyonunu kullanarak veriyi 2B grafikte de görselleştirebilirsiniz.
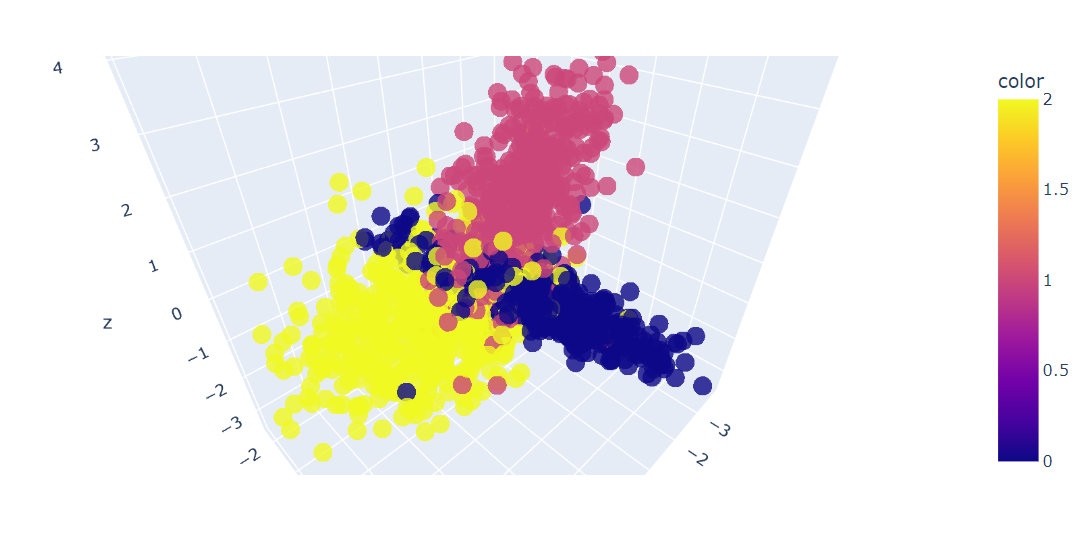
Şimdi, veri kümesi üzerinde PCA algoritmasını uygulayarak iki PCA bileşeni elde edeceğiz. fit_transform() veri setini aynı anda öğrenir ve dönüştürür.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)Artık iki PCA bileşenini bir saçılma grafiğinde göstererek sonuçları görselleştirebiliriz.
update_layout() fonksiyonunu da başlık eklemek ve x ile y eksenlerini yeniden adlandırmak için kullandık.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()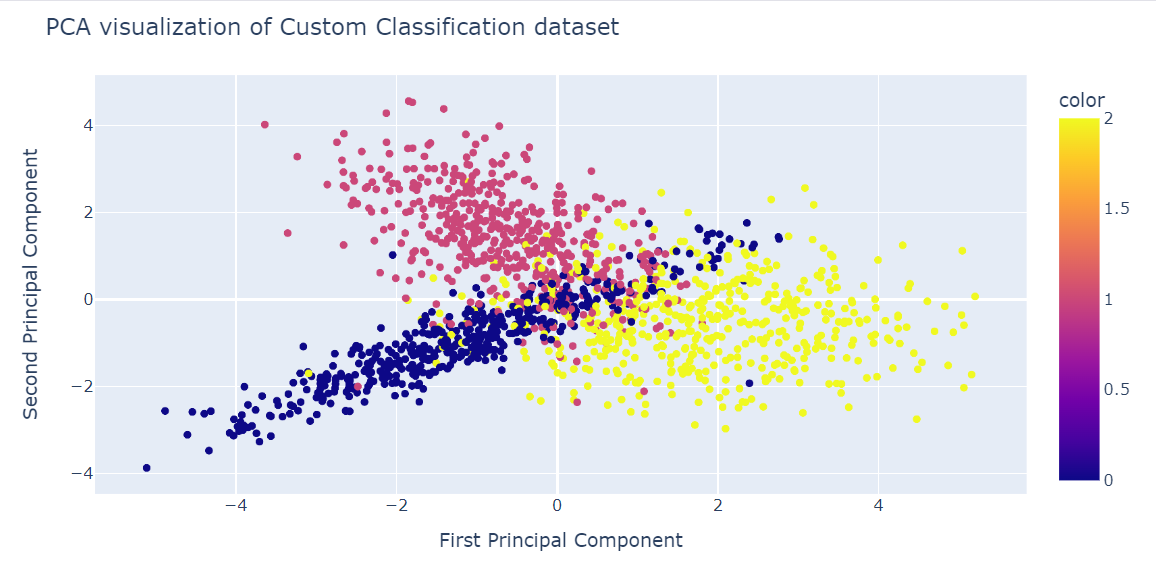
Şimdi t-SNE algoritmasını veri kümesine uygulayıp sonuçları karşılaştıracağız.
Veriyi uyarlayıp dönüştürdükten sonra, yüksek ve düşük boyutlu olasılık dağılımları arasındaki Kullback-Leibler (KL) sapmasını göstereceğiz. Düşük KL sapması genellikle daha iyi sonuçların işaretidir.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
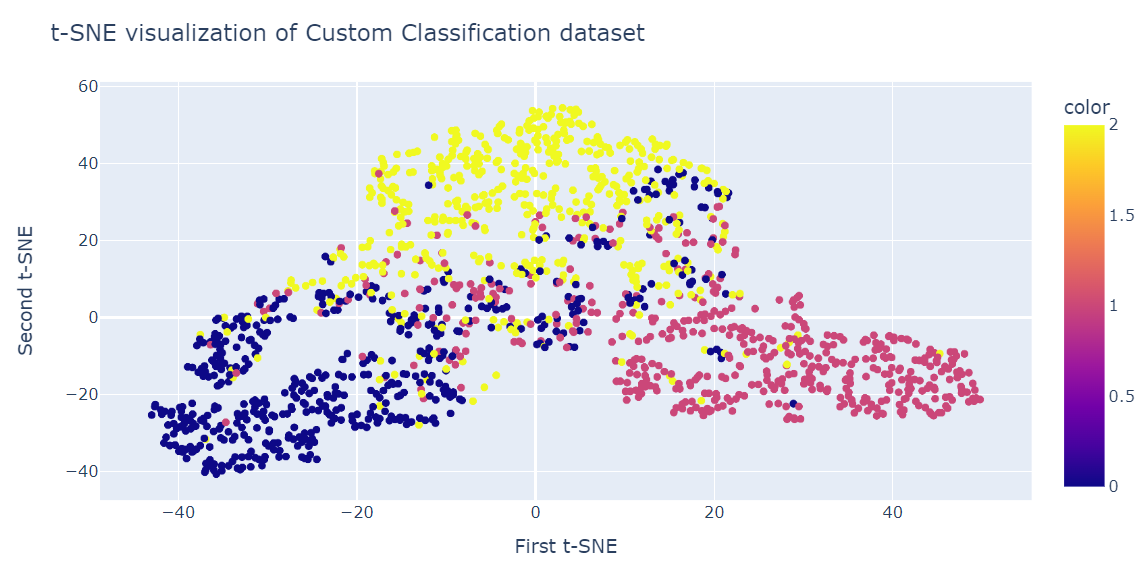
tsne.kl_divergence_1.1169137954711914PCA’ya benzer şekilde, iki t-SNE bileşenini bir saçılma grafiğinde görselleştireceğiz.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Sonuç PCA’dan oldukça daha iyi. Üç büyük kümeyi açıkça görebiliyoruz.
Bu bölümde, İranlı bir telekom şirketinin müşteri terk veri kümesini kullanacağız. Veri kümesi, çağrı başarısızlıkları ve abonelik süresi gibi müşteri etkinlikleri ile bir terk etiketi hakkında bilgiler içerir.
Terk oranı, belirli bir zaman diliminde belirli bir hizmeti kullanmayı bırakan müşterilerin yüzdesi anlamına gelir.
Not: Her iki örneğin de kod kaynağı ve veri kümesi bu DataLab çalışma kitabında mevcuttur; kodla oynamak ve çalıştırmak isterseniz bir kopya oluşturmanız yeterlidir!
Veri kümesini pandas ile yükleyip ilk üç satırı görüntüleyeceğiz.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Ardından şunları yapacağız:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
pca.score(X_test)-17.04482851288105Şimdi PCA sonucunu Plotly Express saçılma grafiğiyle görselleştireceğiz.
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()PCA kümeler oluşturmada başarılı olmadı. Düşük boyuttaki veriler rastgele görünüyor. Bu aynı zamanda veri kümesindeki özelliklerin yüksek derecede çarpık olabileceği veya güçlü bir korelasyon yapısına sahip olmadığı anlamına da gelebilir.
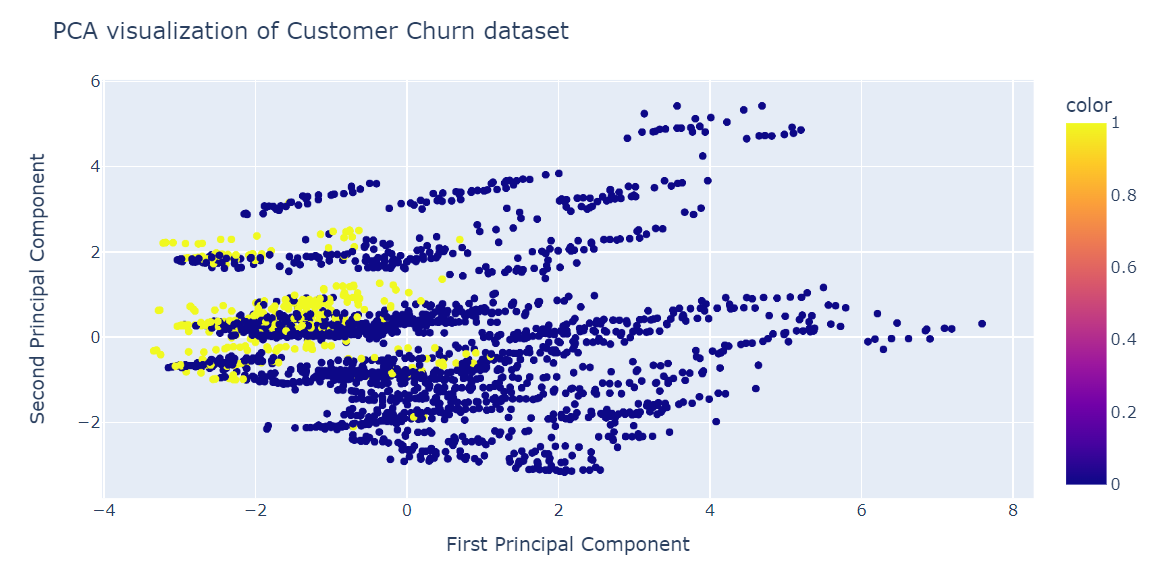
Çarpıklık, t-SNE algoritması için önemli bir hiperparametredir. Boyut indirgeme sürecinde her bir noktanın dikkate aldığı etkin komşu sayısını kontrol eder.
5’ten 55’e, 5’er artışla çeşitli çarpıklık değerleri üzerinde KL sapması metriğini almak için bir döngü çalıştıracağız. Ardından sonucu Plotly Express çizgi grafiğiyle göstereceğiz.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()40 çarpıklık değerinden sonra KL sapması sabit hale geldi. Bu nedenle t-SNE algoritmasında 40 çarpıklık kullanacağız.
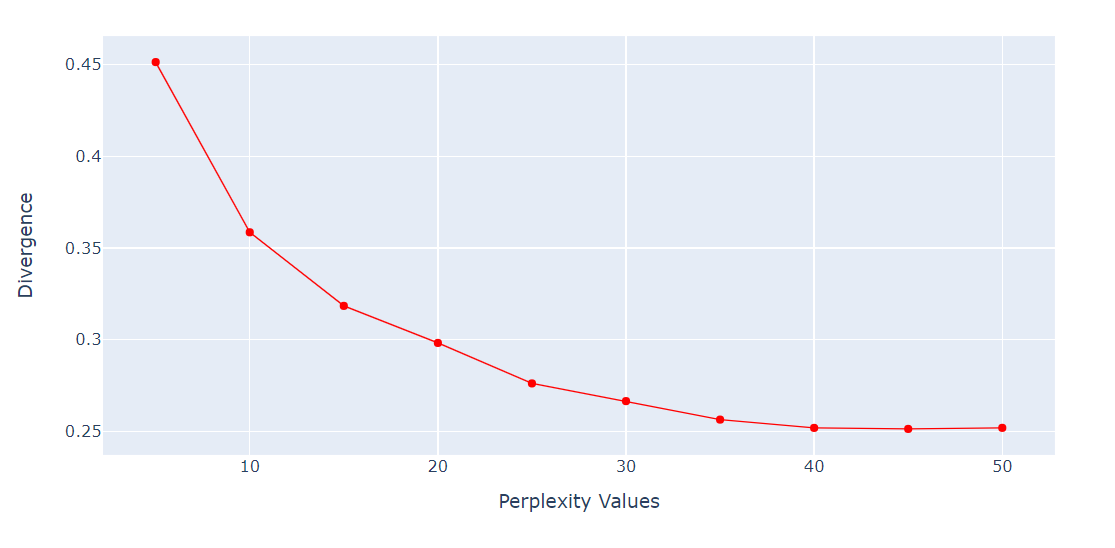
Şimdi t-SNE’yi uyarlayıp veriyi en düşük KL sapmasını elde etmek için 40 çarpıklıkla düşük boyutlara dönüştüreceğiz.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583Şimdi bileşenleri ve hedef sınıfları göstermek için Plotly saçılma grafiğini kullanacağız.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Gördüğümüz gibi, birden çok küme ve alt küme var. Bu bilgiyi örüntüyü anlamak ve mevcut müşterileri elde tutma stratejisi geliştirmek için kullanabiliriz.
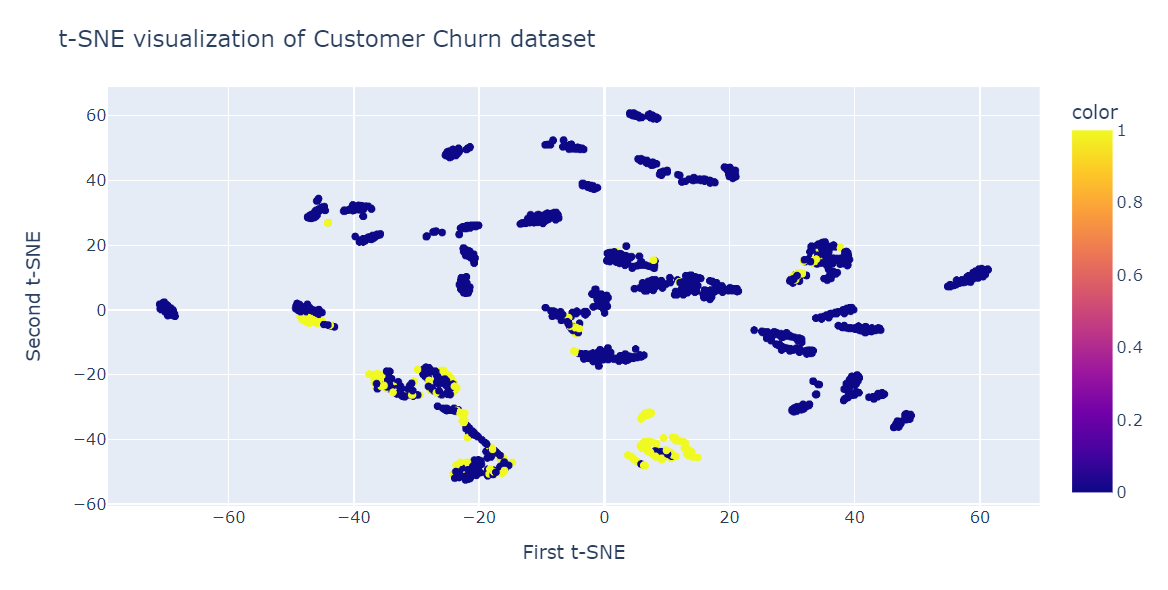
t-SNE, yüksek boyutlu veriler için güçlü bir görselleştirme aracı olsa da bazı sınırlamalarla birlikte gelir:
Son yıllarda, UMAP (Uniform Manifold Approximation and Projection), t-SNE’ye popüler bir alternatif olarak öne çıktı. Her ikisi de görselleştirme için tasarlanmış doğrusal olmayan boyut indirgeme teknikleri olsa da UMAP, t-SNE’nin bazı sınırlamalarını giderir:
Aşağıdaki tablo, t-SNE’nin UMAP ve PCA ile karşılaştırıldığında hesaplama karmaşıklığını özetler:
| Teknik | Hesaplama karmaşıklığı | Özellikler | Büyük veri kümeleri için uygunluk |
|---|---|---|---|
| t-SNE | O(N2) | Yerel yapıyı korur, yüksek özelleştirilebilirlik | Orta (büyük veri kümelerinde yavaş) |
| UMAP | O(N log N) | Yerel ve küresel yapıyı dengeler, daha hızlı | Yüksek (büyük veri kümelerini verimli işler) |
| PCA | O(Nd2) | Doğrusal indirgeme, yorumlanabilir bileşenler | Yüksek (çok verimli) |
Özetle, t-SNE yerel ilişkiler hakkında ayrıntılı içgörüler sağlarken, UMAP modern veri kümeleri için çoğu zaman daha verimli ve ölçeklenebilir bir seçenektir. PCA ise doğrusal veriler için hızlı ve yorumlanabilir bir seçenek olarak kalır. Veri kümesine ve hedeflere bağlı olarak doğru tekniği seçmek, yorumlanabilirlik, hesaplama maliyeti ve verinin doğası arasında bir denge kurmayı gerektirir.
Karmaşık çok boyutlu verileri görselleştirmenin yanı sıra, t-SNE’nin diğer kullanım alanları şunlardır:
t-SNE, karmaşık veri kümelerinde gizli örüntüleri ve yapıları ortaya çıkarmak için güçlü bir görselleştirme aracıdır. Anomalileri ve örüntüleri belirlemek için görsellerde, seste, biyolojik verilerde ve tekil verilerde kullanılabilir.
Bu blog yazısında, yüksek boyutlu doğrusal olmayan verileri düşük boyutlu bir uzayda görselleştirebilen popüler bir boyut indirgeme tekniği olan t-SNE’yi öğrendik. t-SNE’nin ana fikrini, nasıl çalıştığını ve uygulamalarını açıkladık. Ayrıca, t-SNE’nin sentetik ve gerçek veri kümelerine uygulanmasına ve sonuçların nasıl yorumlanacağına dair bazı örnekler gösterdik.
t-SNE, Gözetimsiz Öğrenmenin bir parçasıdır; bir sonraki doğal adım ise hiyerarşik kümelemeyi, PCA’yı, ilişkisizleştirmeyi ve yorumlanabilir özellikler keşfetmeyi anlamaktır. Tüm bu konuları Unsupervised Learning in Python kursumuzu alarak öğrenin.
Python hakkında daha fazlasını öğrenin
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
