
Kursus
Pengantar Data Engineering
4 Hr
127.6K
Ada sejumlah cara untuk menangani slowly changing dimensions. Mari kita lihat tiga cara yang paling umum.
Dengan SCD tipe 1, jika sebuah record dalam tabel dimensi berubah, record yang ada diperbarui atau ditimpa. Jika tidak, record baru dimasukkan ke tabel dimensi. Artinya, record dalam tabel dimensi selalu mencerminkan keadaan saat ini dan tidak ada data historis yang dipertahankan.
Sebuah tabel yang menyimpan informasi tentang item yang dijual di toko bahan makanan mungkin menangani perubahan record menggunakan SCD tipe 1. Jika record untuk item yang dimaksud sudah ada di tabel, record tersebut akan diperbarui dengan informasi baru. Jika tidak, record akan dimasukkan ke tabel dimensi.
Di dunia rekayasa data, praktik memperbarui data jika sudah ada atau memasukkannya jika belum ini dikenal sebagai “upsert”. Tabel di bawah berisi informasi tentang item yang dijual di sebuah toko bahan makanan.
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Jika Potato Chips dipindahkan ke lorong 6, menggunakan SCD tipe 1 untuk menangkap perubahan ini dalam tabel dimensi akan menghasilkan seperti di bawah:
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
SCD tipe 1 memastikan tidak ada record duplikat di tabel dan data mencerminkan dimensi terkini. Ini sangat berguna untuk dashboarding real-time dan pemodelan prediktif, ketika hanya keadaan saat ini yang menjadi fokus.
Namun, karena hanya informasi terbaru yang disimpan di tabel, praktisi data tidak dapat membandingkan perubahan dimensi dari waktu ke waktu. Misalnya, seorang analis data akan kesulitan mengidentifikasi kenaikan pendapatan untuk Potato Chips setelah dipindahkan ke lorong 6 tanpa informasi lain.
SCD tipe 1 memudahkan pelaporan dan analitik keadaan saat ini namun memiliki keterbatasan saat melakukan analisis historis.
Meski memiliki tabel yang hanya mencerminkan keadaan saat ini mungkin bermanfaat, ada kalanya melacak perubahan historis pada dimensi itu nyaman, bahkan esensial. Dengan SCD tipe 2, data historis dipertahankan dengan menambahkan baris baru ketika sebuah dimensi berubah dan menandai baris baru ini sebagai saat ini sekaligus menandai record yang kini historis dengan semestinya.
Mudah diucapkan, tapi mungkin belum jelas seperti apa praktiknya. Mari intip contohnya.
Di sini, kita punya tabel yang mirip dengan contoh saat mengeksplorasi SCD tipe 1. Namun, ditambahkan satu kolom. Kolom is_current menyimpan nilai boolean; true jika record mencerminkan nilai paling mutakhir, dan false jika tidak.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
True |
|
07879 |
Soda |
7.99 |
13 |
True |
Jika Potato Chips dipindahkan ke lorong 6, menggunakan SCD tipe 2 untuk mendokumentasikan perubahan ini akan menghasilkan tabel seperti ini:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
False |
|
07879 |
Soda |
7.99 |
13 |
True |
|
93201 |
Potato Chips |
3.99 |
6 |
True |
Baris baru ditambahkan untuk mencerminkan perubahan lokasi Potato Chips, dengan True di kolom is_current. Untuk mempertahankan data historis dan menggambarkan keadaan saat ini secara akurat, kolom is_current untuk record sebelumnya disetel ke False. Dengan SCD tipe 1,
Namun bagaimana jika Anda ingin melihat bagaimana penjualan Potato Chips merespons perubahan lokasi? Ini cukup sulit bila hanya menggunakan satu kolom jika ada banyak record historis untuk satu item. Untungnya, ada cara mudah untuk melakukannya.
Lihat tabel di bawah. Tabel dimensi ini berisi informasi yang sama seperti sebelumnya, tetapi alih-alih kolom is_current, tabel ini memiliki kolom start_date dan end_date. Tanggal-tanggal ini merepresentasikan periode ketika sebuah dimensi merupakan yang paling mutakhir. Karena data dalam tabel ini adalah yang terbaru, end_date ditetapkan jauh di masa depan.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Jika Potato Chips dipindahkan ke lorong 6 pada 4 Januari 2024, tabel yang diperbarui akan terlihat seperti ini:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Perhatikan bahwa end_date untuk baris pertama telah diperbarui menjadi hari terakhir Potato Chips tersedia di lorong 11. Record baru ditambahkan, dengan Potato Chips kini ditaruh di lorong 6. start_date dan end_date membantu menunjukkan kapan perubahan dibuat dan menandai record mana yang saat ini berlaku.
Menggunakan teknik ini untuk mengimplementasikan SCD tipe 1 tidak hanya mempertahankan data historis, tetapi juga memberikan informasi tentang kapan data berubah. Ini memungkinkan analis data dan data scientist mengeksplorasi perubahan operasional, melakukan A/B testing, dan mendukung pengambilan keputusan yang terinformasi.
Saat bekerja dengan data yang diperkirakan hanya akan berubah sekali, atau hanya record historis terbaru yang menarik, SCD tipe 3 sangat berguna. Alih-alih melakukan “upsert” pada dimensi yang diubah atau menyimpan perubahan sebagai baris baru, SCD tipe 3 menggunakan kolom untuk merepresentasikan perubahan. Ini sedikit rumit dijelaskan, jadi mari langsung ke contohnya.
Tabel di bawah memuat informasi tentang olahraga untuk tim di seluruh Amerika Serikat. Di sini, tabel berisi dua kolom untuk menyimpan nama stadion saat ini dan historis. Karena masing-masing tim ini masih menggunakan nama stadion asli, kolom previous_stadium_name diisi dengan NULL.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Jika Lafayette Hawks memutuskan mengambil sponsor baru untuk kesepakatan dua puluh lima tahun, tabel yang diperbarui akan terlihat seperti ini:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Untuk mencatat nama stadion baru, “Triple X Stadium" dipindahkan ke kolom previous_stadium_name, dan “Wabash Field" menggantikannya di kolom current_stadium_name. Kesepakatan sponsor baru yang berdurasi dua puluh lima tahun ini kemungkinan akan melampaui umur model yang dibangun, sehingga record kecil kemungkinan berubah lagi.
Menggunakan SCD tipe 3 membuat perbandingan data keadaan saat ini dengan data historis menjadi cukup sederhana. Hanya ada satu baris untuk setiap tim, dan data saat ini serta historis berdampingan dalam dua kolom berbeda. Namun, ini berarti hanya satu record historis untuk satu atribut dimensi yang dapat dipertahankan, yang mungkin membatasi, terutama jika data berubah lebih sering dari perkiraan.
Selain tipe 1, 2, dan 3, ada sejumlah teknik lain untuk mengimplementasikan slowly changing dimensions. Tipe 0 digunakan ketika dimensi tidak boleh berubah. Tipe 4 menyimpan data historis di tabel terpisah sambil mempertahankan data paling mutakhir di tabel dimensi. Tipe 6 merupakan gabungan dari tipe 1, 2, dan 3 dan biasanya diimplementasikan dengan mengombinasikan fitur terbaik dari masing-masing teknik.
Kita telah membahas dasar-dasar slowly changing dimensions. Untuk memahami lebih baik cara mengimplementasikan tiap teknik, mari lihat sebuah contoh.
Dalam contoh ini, kita akan menggunakan Snowflake untuk mengimplementasikan SCD tipe 1, 2, dan 3 untuk transaksi ritel. Jika Anda perlu penyegaran tentang Snowflake, lihat kursus Introduction to Snowflake kami.
Ada satu tabel fakta bernama sales, dan tiga tabel dimensi, bernama employees, items, dan discounts. Di bawah ini adalah ERD untuk star schema ini.
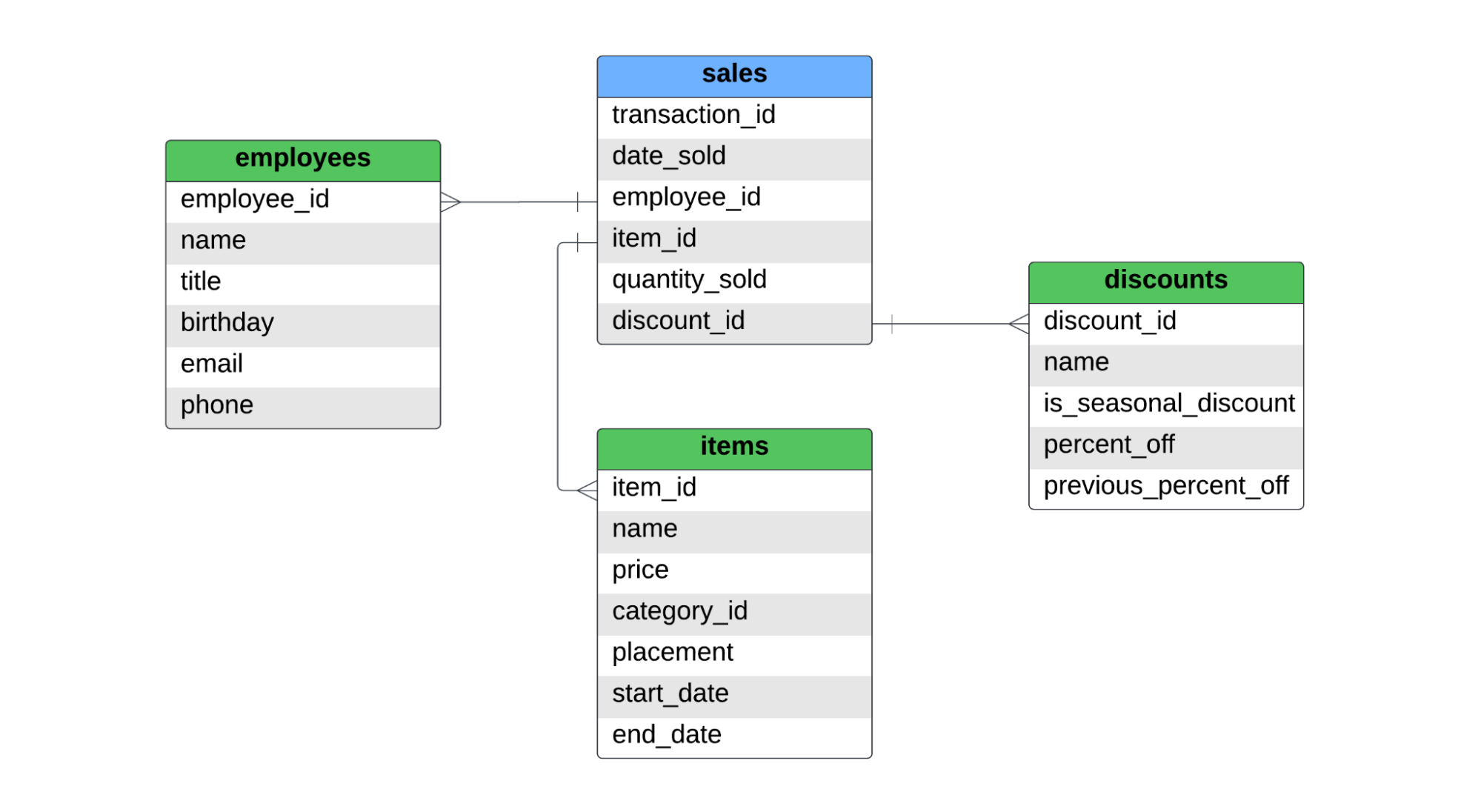
Tabel sales menangkap penjualan per item. Jika seorang pelanggan membeli dua kemeja dan sepasang jeans, akan ada dua record di tabel fakta, karena dua item berbeda terjual. Untuk SCD tipe 1, tipe 2, dan tipe 3, kita akan membahas hal-hal berikut:
Kita tidak akan membahas bagaimana tabel-tabel ini awalnya diisi, tetapi umumnya, sebuah pipeline ETL atau ELT di hulu data warehouse mengambil data mentah dari sumber, mentransformasikannya ke model yang diinginkan, dan memuatnya ke tujuan akhir.
Untuk berlatih mengimplementasikan SCD tipe 1, kita akan melihat tabel employee. Tabel ini memuat informasi dasar tentang karyawan, termasuk nama, jabatan, dan informasi kontak. Tabel ini mungkin berisi record seperti di bawah.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Menggunakan SCD tipe 1 untuk menangkap dimensi yang berubah secara perlahan, record yang ada akan ditimpa oleh record paling baru. Jika salah satu atribut dimensi ini berubah, record baru harus di-“upsert” ke tabel yang ada. Misalnya, jika nomor telepon Emily berubah menjadi 928-652-9704, tabel baru akan seperti ini:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Untuk melakukan ini dengan Snowflake, kita akan menggunakan perintah MERGE INTO. MERGE INTO memungkinkan praktisi data memberikan kunci pencocokan dan sebuah kondisi. Jika kunci dan kondisi terpenuhi, record dapat diperbarui dengan kata kunci UPDATE. Jika tidak, record dapat di-INSERT atau eksekusi dihentikan.
Sebelum memulai dengan perintah MERGE INTO, kita terlebih dahulu membuat dan menambahkan record ke tabel bernama stage_employees. Ini akan memuat semua record yang diperbarui sejak tabel employees terakhir disegarkan. Kita dapat melakukannya dengan pernyataan di bawah.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Sekarang, kita dapat menggunakan fungsionalitas MERGE Snowflake untuk melakukan “upsert” pada record yang ada.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Di atas, kunci untuk menggabungkan data antara tabel employees dan stage_employees adalah field employee_id. Kondisi lain tidak ditetapkan, yang berarti jika employee_id cocok, atribut dimensi name, title, email, dan phone diperbarui dengan nilai dari tabel stage_employees untuk ID karyawan tersebut. Jika record dari stage_employees tidak cocok dengan apa pun di tabel employees, record akan dimasukkan ke tabel employees.
Mengimplementasikan SCD tipe 2 sedikit lebih rumit daripada SCD tipe 1. Meski tidak sesederhana menimpa record yang ada atau memasukkan record baru, kita tetap bisa menggunakan logika MERGE INTO Snowflake untuk mengatasi masalah ini. Lihat dimensi di bawah.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
NULL |
Tabel ini memuat informasi tentang item tertentu yang dijual di toko ritel. Atribut dimensinya mencakup nama, harga, dan penempatan item, serta foreign key ke kategori item tersebut. Untuk mengimplementasikan SCD tipe 2, kita perlu melakukan “upsert” data, kali ini menggunakan start_date dan end_date untuk mempertahankan data historis dan data saat ini.
Misalkan di awal musim NFL (National Football League), jersey olahraga dipindahkan ke bagian depan toko agar lebih terlihat saat pelanggan masuk. Bersamaan dengan lokasi baru, harga item ini diturunkan. Untuk menggambarkan perilaku operasional ini sekaligus mempertahankan data historis, record yang ada diperbarui dengan tanggal akhir, dan record baru dimasukkan. Lihat!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sports Jersey |
49.99 |
743 |
Entry Display |
2023-11-13 |
NULL |
Seperti sebelumnya, kita terlebih dahulu akan membuat tabel bernama stage_items. Tabel ini akan menyimpan record yang akan digunakan untuk mengimplementasikan SCD tipe 2 pada dimensi items terkait, yang bentuknya seperti di atas. Setelah tabel stage_items dibuat, kita akan menyisipkan record yang memuat perubahan penempatan dan harga untuk jersey olahraga.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Sekarang, saatnya menggunakan fungsionalitas MERGE INTO Snowflake untuk mengimplementasikan SCD tipe 2. Ini sedikit lebih rumit dibanding contoh sebelumnya, dan butuh sedikit pemikiran. Karena record hanya dapat dimasukkan jika kondisi kecocokan TIDAK terpenuhi, kita harus melakukannya dalam dua langkah. Pertama kita buat kondisi kecocokan dengan tiga pernyataan berikut:
item_id di tabel items dan stage_items harus cocokstart_date di tabel stage_items harus lebih besar daripada di tabel itemsend_date di tabel items harus NULLJika ketiga kondisi ini terpenuhi, maka record asli di tabel items harus diperbarui. Perhatikan bahwa kolom items.end_date tidak lagi NULL; nilainya akan mengambil start_date dari tabel stage_items. Tidak ada logika jika record tidak cocok pada pernyataan pertama ini.
Berikutnya, kita akan menggunakan pemanggilan MERGE INTO terpisah untuk memasukkan record baru. Ini sedikit lebih sulit. Agar record baru dimasukkan, kondisi kecocokan tidak boleh terpenuhi.
Dalam contoh ini, kita dapat melakukannya dengan memeriksa apakah items_id di kedua tabel cocok, dan end_date di tabel items adalah NULL. Mari kita uraikan lebih jauh.
items_id cocok, dan items.end_date adalah NULL, sudah ada record di tabel items yang paling mutakhir. Ini berarti record baru tidak boleh dimasukkan.item_id di kedua tabel, kondisi kecocokan tidak akan terpenuhi, dan baris baru akan dimasukkan. Ini akan menjadi record pertama untuk item_id tersebut di tabel items.item_id di tabel stage_items cocok dengan record dengan item_id yang sama di tabel items, dan end_date tidak NULL, nilai baru akan dimasukkan. Ini mempertahankan data historis dan memastikan bahwa record saat ini ada di tabel items.Di bawah ini adalah implementasinya, menggunakan dua pernyataan MERGE INTO untuk terlebih dahulu memperbarui record yang ada lalu memasukkan data paling mutakhir.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Terakhir, kita akan melihat implementasi SCD tipe 3 dengan dimensi baru. Dalam contoh kita, tabel discounts menyimpan informasi tentang diskon tertentu yang dapat ditukarkan pelanggan saat checkout. Tabel ini mencakup ID diskon, serta nama, persentase potongan, dan klasifikasinya sebagai diskon musiman. Berikut contoh dua record yang mungkin ada di tabel discounts.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
50 |
NULL |
Karena peritel tidak mengharapkan diskon sering berubah, dimensi ini merupakan kandidat yang bagus untuk menerapkan pendekatan tipe 3 untuk slowly changing dimensions. Jika persentase potongan yang ditawarkan melalui diskon berubah, persentase potongan sebelumnya akan dipindahkan ke kolom previous_percent_off, sementara nilai baru akan menempati kolom percent_off.
Ini memungkinkan data historis dipertahankan sambil menampilkan nilai terbaru di kolom percent_off.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
35 |
50 |
Untuk mengimplementasikan ini dengan Snowflake, kita akan membuat tabel stage_discounts, dan menyisipkan satu record. Record ini akan memuat percent_off yang baru.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Sekali lagi, kita akan menggunakan MERGE INTO untuk mengimplementasikan SCD tipe 3. Kondisi kecocokannya sederhana; jika discount_id di tabel discounts dan stage_discounts cocok, dan nilai percent_off berbeda, record yang ada di tabel discounts akan diperbarui. Nilai percent_off yang ada akan dipindahkan ke field previous_percent_off, lalu jika discount_id di kedua tabel tidak cocok, record baru akan dimasukkan dengan nilai NULL. Perhatikan bahwa record ini tidak terikat waktu, dan hanya satu nilai historis untuk percent_off yang dapat dipertahankan.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Ingat, SCD tipe 3 paling tepat digunakan untuk data yang jarang berubah, dan hanya entri historis terbaru yang akan dipertahankan. Jika diperkirakan ada banyak perubahan pada dimensi, kemungkinan besar lebih baik menggunakan SCD tipe 2.
Saat mengimplementasikan teknik apa pun untuk slowly changing dimensions, penting untuk mengingat kemungkinan adanya data duplikat. Ada dua jenis duplikat yang perlu diwaspadai: duplikat intra-batch dan inter-batch. Mari kita uraikan.
Duplikat intra-batch adalah duplikat yang ada di antara batch data yang berbeda. Jika ada tabel dimensi yang sudah ada, dua file yang ditujukan untuk memperbarui tabel ini mungkin mengandung record duplikat.
Untuk menanganinya, penting untuk menambahkan kendala pada logika yang melakukan “upsert” dan/atau memuat data ke tabel dimensi. Dalam contoh di atas, kita menambahkan logika untuk memastikan tidak ada duplikasi. Ini termasuk:
employee_id yang cocokpercent_off berbeda di tabel items dan stage_items sebelum memperbarui record yang adaDuplikat inter-batch adalah duplikat yang terjadi dalam batch data yang sama. Misalnya, jika sebuah file berisi dua entri untuk memperbarui satu record di tabel dimensi, harus ada tindakan pencegahan. Seperti pada duplikat intra-batch, penting untuk menambahkan kendala pada logika yang digunakan untuk mengimplementasikan SCD tipe 1, 2, atau 3.
Jika ada record yang saling bertentangan dalam file yang sama, record tersebut harus dibedakan dengan suatu cara. Ini bisa berupa metadata tentang record atau timestamp dari sumber. Apa pun cara Anda menangani duplikat ini, penting untuk mendokumentasikan asumsi Anda dan meninjaunya bersama tim untuk memastikan dimensi yang dihasilkan menangkap nilai operasional secara akurat.
Terkadang, data berubah saat seharusnya tidak. Dengan tiga teknik SCD yang telah kita bahas sejauh ini, ini dapat menyebabkan data ditimpa, baris baru ditambahkan, atau data diisi di kolom baru.
Kita telah membahas cara memastikan data duplikat tidak masuk ke dalam tabel dimensi. Selain data duplikat, praktisi data yang mengimplementasikan teknik untuk menangani slowly changing dimensions juga perlu mewaspadai hal-hal berikut:
Meski tidak semua kasus di atas dapat ditangkap langsung dalam kode yang digunakan untuk memelihara tabel dimensi, memiliki aturan kualitas data yang kuat dan proses untuk memantau dimensi dapat membantu menjaga integritas data.
Dalam contoh ritel di atas, dataset yang kita gunakan hanya terdiri dari beberapa baris data. Dalam lingkungan produksi, tabel dimensi ini bisa berisi ratusan bahkan ribuan record. Ini sangat umum saat mengimplementasikan SCD tipe 2, terutama jika dimensi sering berubah.
Seiring bertambahnya jumlah baris dalam tabel dimensi, penting bagi praktisi data untuk menempatkan kinerja di garis depan rencana desain dan implementasi. Berikut beberapa cara untuk mengoptimalkan implementasi SCD untuk dataset besar menggunakan Snowflake:
MERGEUPDATE dan INSERT bila sesuai, alih-alih MERGEJika dataset dimensi menjadi begitu besar sehingga kinerja sistem terganggu, mungkin perlu dibuat keputusan tentang trade-off antara akurasi historis dan kinerja sistem. Seperti disebutkan di atas, ini biasanya terjadi saat mengimplementasikan SCD tipe 2.
Jika record sering berubah, jumlah baris dalam tabel dapat membengkak dengan cepat. Dalam kondisi ini, mungkin tidak lagi bijak menggunakan SCD tipe 2 untuk mempertahankan data dimensi.
Beralih memanfaatkan SCD tipe 1 atau tipe 3 mungkin menawarkan fungsionalitas serupa, dengan peningkatan kinerja sistem yang signifikan. Konsekuensinya adalah representasi data historis yang tidak lengkap. Diskusikan dengan tim Anda untuk menimbang trade-off ini sebelum mengubah pendekatan implementasi SCD.
Menjalankan kueri sekali untuk mengimplementasikan SCD pada tabel dimensi itu cukup mudah. Namun, menjalankan proses ini secara terprogram untuk memelihara dimensi dalam lingkungan produksi memerlukan sedikit pemikiran. Alat seperti Apache Airflow sangat baik untuk mengorkestrasi proses ini dan menyediakan lapisan pemantauan serta peringatan untuk memastikan kinerja nominal. Dengan melakukan parameterisasi logika yang digunakan untuk memperbarui tabel dimensi, Airflow dapat digunakan untuk memicu proses di platform data Anda pada jadwal tertentu, menggantikan upaya manual praktisi data
Selain Airflow, alat seperti Mage, Prefect, atau Dagster dapat digunakan untuk mengorkestrasi implementasi slowly changing dimensions. Jika alat seperti ini tidak tersedia, alat orkestrasi buatan sendiri juga dapat digunakan.
Menguasai slowly changing dimensions (SCD) adalah keterampilan hebat untuk dimiliki, terutama saat Anda membuat model data sendiri.
Dalam artikel ini, kita membahas dasar-dasar star schema, serta definisi dan dasar SCD. Kita mengeksplorasi SCD tipe 1, 2, dan 3 untuk mempertahankan data historis sambil menangkap potret keadaan saat ini.
Dengan bantuan Snowflake, kita mengimplementasikan masing-masing teknik SCD yang didefinisikan di atas melalui contoh ritel. Setelah itu, kita menguraikan beberapa tantangan teknis yang mungkin muncul saat mengimplementasikan SCD, dan bagaimana mengatasinya.
Untuk terus mengembangkan keterampilan pemodelan data Anda, ikuti kursus Database Design, Introduction to Data Engineering, dan Introduction to Data Warehousing yang tersedia melalui DataCamp. Semoga sukses, dan selamat ngoding!
Mulai Perjalanan Data Anda Hari Ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
