
Corso
Introduzione al Data Engineering
4 h
127.6K
Esistono vari modi per gestire le slowly changing dimensions. Diamo un'occhiata a tre dei metodi più comuni.
Con le SCD di tipo 1, se un record in una tabella di dimensione cambia, il record esistente viene aggiornato o sovrascritto. In caso contrario, il nuovo record viene inserito nella tabella di dimensione. Ciò significa che i record nella tabella di dimensione riflettono sempre lo stato attuale e non vengono mantenuti dati storici.
Una tabella che memorizza informazioni sugli articoli venduti in un supermercato potrebbe gestire i record che cambiano usando SCD di tipo 1. Se esiste già un record in tabella per l'articolo desiderato, verrà aggiornato con le nuove informazioni. Altrimenti, il record verrà inserito nella tabella di dimensione.
Nel mondo della data engineering, questa pratica di aggiornare i dati se esistono o inserirli altrimenti è nota come “upsert”. La tabella seguente contiene informazioni sugli articoli venduti in un supermercato.
|
item_id |
name |
price |
aisle |
|
93201 |
Patatine |
3.99 |
11 |
|
07879 |
Bibita |
7.99 |
13 |
Se le Patatine vengono spostate alla corsia 6, usare le SCD di tipo 1 per catturare questo cambiamento nella tabella di dimensione produrrà il risultato seguente:
|
item_id |
name |
price |
aisle |
|
93201 |
Patatine |
3.99 |
6 |
|
07879 |
Bibita |
7.99 |
13 |
Le SCD di tipo 1 garantiscono che non ci siano record duplicati in tabella e che i dati riflettano la dimensione più recente. Ciò è particolarmente utile per dashboard in tempo reale e modelli predittivi, dove interessa solo lo stato attuale.
Tuttavia, poiché nella tabella è archiviata solo l'informazione più recente, i professionisti dei dati non possono confrontare i cambiamenti nelle dimensioni nel tempo. Ad esempio, a un data analyst risulterebbe difficile identificare l'incremento di ricavi delle Patatine dopo lo spostamento alla corsia 6 senza altre informazioni.
Le SCD di tipo 1 rendono semplici i report e le analisi sullo stato attuale ma presentano limiti quando si eseguono analisi storiche.
Avere una tabella che riflette solo lo stato attuale può essere utile, ma ci sono momenti in cui è comodo, se non essenziale, tracciare i cambiamenti storici di una dimensione. Con le SCD di tipo 2, i dati storici vengono mantenuti aggiungendo una nuova riga quando una dimensione cambia e contrassegnando correttamente questa nuova riga come corrente, segnalando allo stesso tempo come storica la riga precedente.
Facile a dirsi, ma non è detto che sia subito chiaro come appaia in pratica. Diamo un'occhiata a un esempio.
Qui abbiamo una tabella molto simile all'esempio usato per esplorare le SCD di tipo 1. È stata però aggiunta una colonna. La colonna is_current memorizza un valore booleano: true se il record riflette il valore più attuale, false altrimenti.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Patatine |
3.99 |
11 |
True |
|
07879 |
Bibita |
7.99 |
13 |
True |
Se le Patatine si spostano alla corsia 6, usare le SCD di tipo 2 per documentare questo cambiamento creerebbe una tabella come questa:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Patatine |
3.99 |
11 |
False |
|
07879 |
Bibita |
7.99 |
13 |
True |
|
93201 |
Patatine |
3.99 |
6 |
True |
Viene aggiunta una nuova riga per riflettere il cambio di collocazione delle Patatine, con True nella colonna is_current. Per mantenere i dati storici e rappresentare correttamente lo stato attuale, la colonna is_current per il record precedente è impostata su False. Con le SCD di tipo 1,
Ma se volessi analizzare come le vendite di Patatine hanno reagito al cambio di posizione? Questo è piuttosto difficile usando una singola colonna se esistono più record storici per un singolo articolo. Per fortuna, c'è un modo semplice per farlo.
Guarda la tabella qui sotto. Questa tabella di dimensione contiene le stesse informazioni di prima, ma invece della colonna is_current, ha sia una colonna start_date che una end_date. Queste date rappresentano il periodo in cui una dimensione era la più attuale. Poiché i dati in questa tabella sono i più recenti, la end_date è impostata molto in avanti nel futuro.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Patatine |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Bibita |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Se le Patatine sono state spostate alla corsia 6 il 4 gennaio 2024, la tabella aggiornata sarebbe così:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Patatine |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Bibita |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Patatine |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Nota che la end_date della prima riga è stata aggiornata all'ultimo giorno in cui le Patatine erano disponibili alla corsia 11. È stato aggiunto un nuovo record, con le Patatine ora esposte alla corsia 6. Le colonne start_date e end_date aiutano a mostrare quando è stato effettuato il cambio e a indicare quale record è quello corrente.
Usare questa tecnica per implementare le SCD di tipo 1 non solo preserva i dati storici, ma offre anche informazioni su quando i dati sono cambiati. Questo consente a data analyst e data scientist di esplorare cambiamenti operativi, eseguire A/B test e prendere decisioni informate.
Quando si lavora con dati che si prevede cambino solo una volta, o interessa solo il record storico più recente, le SCD di tipo 3 sono molto utili. Invece di fare “upsert” di una dimensione modificata o archiviare il cambiamento come una nuova riga, le SCD di tipo 3 usano una colonna per rappresentare il cambiamento. È un po' difficile da spiegare, quindi passiamo subito a un esempio.
La tabella seguente contiene informazioni su sport e squadre negli Stati Uniti. Qui, la tabella contiene due colonne per memorizzare il nome dello stadio attuale e storico. Poiché ognuna di queste squadre sta usando il nome originale dello stadio, la colonna previous_stadium_name è popolata con NULL.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Se i Lafayette Hawks decidono di accettare un nuovo sponsor per un accordo di venticinque anni, la tabella aggiornata apparirà così:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Per tenere conto del nuovo nome dello stadio, “Triple X Stadium” viene spostato nella previous_stadium_name column e “Wabash Field” ne prende il posto nella colonna current_stadium_name. Il nuovo accordo di sponsorizzazione, della durata di venticinque anni, con ogni probabilità supererà il ciclo di vita del modello in costruzione, il che significa che è improbabile che il record cambi di nuovo.
Usare le SCD di tipo 3 rende molto semplice confrontare i dati dello stato attuale con quelli storici. C'è una sola riga per ogni squadra e i dati correnti e storici sono affiancati in due colonne diverse. Tuttavia, ciò significa che può essere mantenuto solo un singolo record storico per un singolo attributo dimensionale, il che può risultare limitante, soprattutto se i dati cambiano più spesso del previsto.
Oltre ai tipi 1, 2 e 3, esistono numerose altre tecniche per implementare le slowly changing dimensions. Il tipo 0 si usa quando le dimensioni non dovrebbero mai cambiare. Il tipo 4 memorizza i dati storici in una tabella separata mantenendo i dati più recenti in una tabella di dimensione. Il tipo 6 è una combinazione dei tipi 1, 2 e 3 ed è tipicamente implementato combinando le migliori caratteristiche di ciascuna tecnica.
Abbiamo coperto le basi delle slowly changing dimensions. Per capire meglio come implementare ciascuna di queste tecniche, vediamo un esempio.
In questo esempio useremo Snowflake per implementare SCD di tipo 1, 2 e 3 per transazioni retail. Se ti serve un ripasso su Snowflake, dai un'occhiata al nostro corso Introduction to Snowflake.
C'è una tabella di fatto, chiamata sales, e tre tabelle di dimensione, chiamate employees, items e discounts. Qui sotto trovi l'ERD per questo star schema.
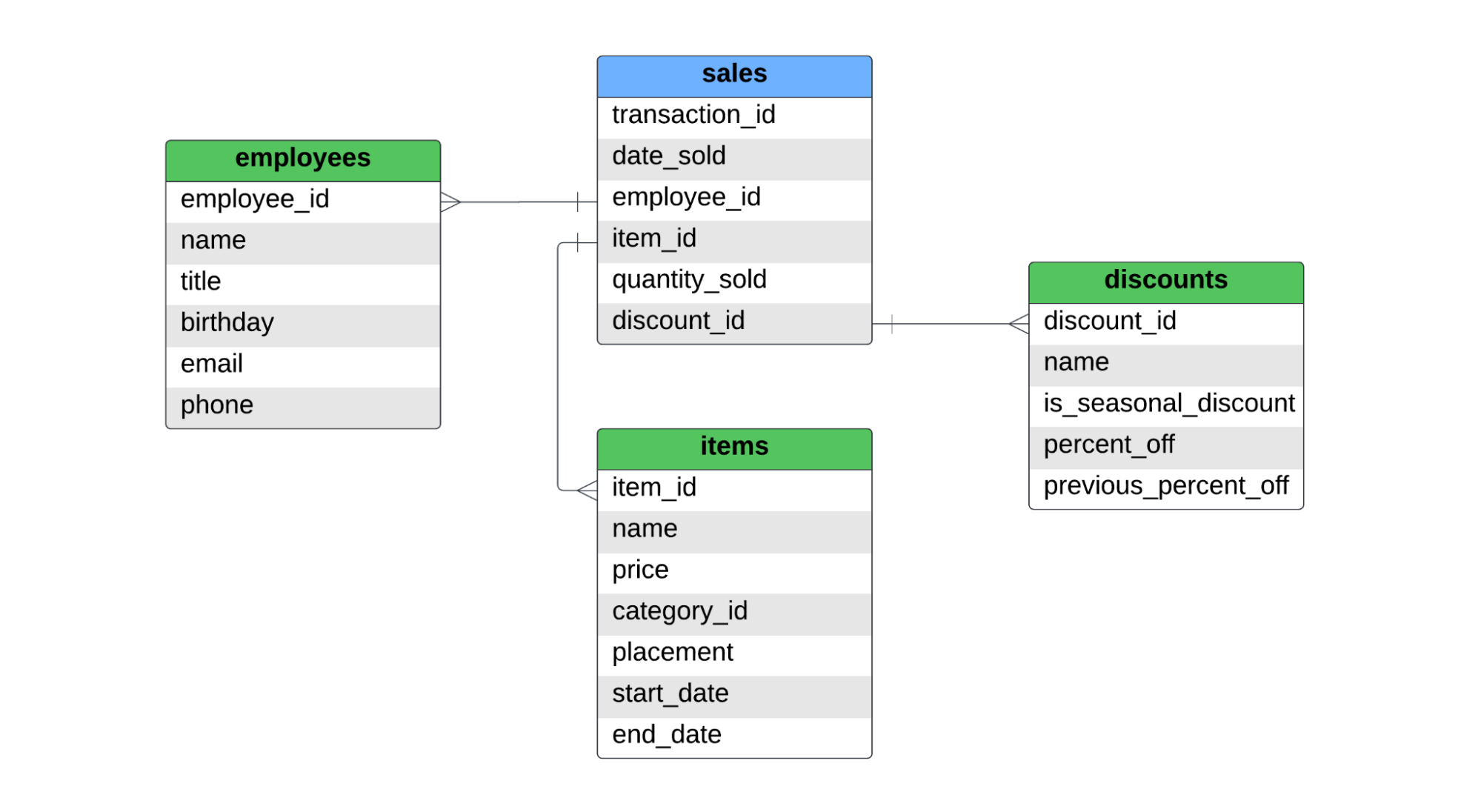
La tabella sales cattura le vendite a livello di articolo. Se un cliente acquista due magliette e un paio di jeans, ci saranno due record nella tabella di fatto, poiché sono stati venduti due articoli diversi. Per le SCD di tipo 1, tipo 2 e tipo 3, tratteremo i seguenti aspetti:
Non esploreremo come queste tabelle siano state popolate inizialmente, ma tipicamente una pipeline ETL o ELT a monte del data warehouse ha estratto i dati grezzi dalle fonti, li ha trasformati nel modello desiderato e li ha caricati nella destinazione finale.
Per esercitarci con l'implementazione delle SCD di tipo 1, analizzeremo la tabella employee. Questa tabella contiene informazioni di base su un dipendente, incluso nome, titolo e contatti. Può contenere record come quelli seguenti.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cassiere |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Usando le SCD di tipo 1 per catturare questa dimensione a cambiamento lento, il record esistente verrebbe sovrascritto dal record più recente. Se uno di questi attributi dimensionali cambia, il nuovo record dovrebbe essere “upsertato” nella tabella esistente. Ad esempio, se il numero di telefono di Emily cambia in 928-652-9704, la nuova tabella apparirebbe così:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cassiere |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Per farlo con Snowflake, useremo il comando MERGE INTO. MERGE INTO consente a un professionista dei dati di fornire una chiave di corrispondenza e una condizione. Se la chiave di corrispondenza e la condizione sono soddisfatte, il record può essere aggiornato con la parola chiave UPDATE. Altrimenti, è possibile INSERTare un record o interrompere l'esecuzione.
Prima di iniziare con il comando MERGE INTO, creeremo e aggiungeremo record a una tabella chiamata stage_employees. Questa conterrà tutti i record aggiornati da quando la tabella employees è stata aggiornata l'ultima volta. Possiamo farlo con le istruzioni seguenti.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Ora possiamo usare la funzionalità MERGE di Snowflake per fare l'“upsert” del record esistente.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Sopra, la chiave per unire i dati tra le tabelle employees e stage_employees era il campo employee_id. Non è stata impostata un'altra condizione, il che significa che se gli employee_id corrispondevano, gli attributi dimensionali name, title, email e phone venivano aggiornati con i valori della tabella stage_employees per quell'ID dipendente. Se i record di stage_employees non corrispondevano a nessuno della tabella employees, il record veniva inserito nella tabella employees.
Implementare le SCD di tipo 2 è un po' più complesso rispetto al tipo 1. Anche se non è semplice come sovrascrivere un record esistente o inserirne uno altrimenti, possiamo comunque usare la logica MERGE INTO di Snowflake per affrontare il problema. Guarda la dimensione qui sotto.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Calzini |
8.99 |
156 |
Corsia 11 |
2023-08-24 |
NULL |
|
747295 |
Maglia sportiva |
59.99 |
743 |
Corsia 8 |
2023-02-17 |
NULL |
Questa tabella contiene informazioni su articoli specifici venduti in un negozio al dettaglio. Gli attributi dimensionali includono nome, prezzo e collocazione dell'articolo, oltre a una chiave esterna verso la categoria di appartenenza. Per implementare le SCD di tipo 2, dovremo fare “upsert” dei dati, questa volta usando start_date ed end_date per mantenere sia i dati storici sia quelli attuali.
Supponiamo che all'inizio della stagione NFL (National Football League) le maglie sportive vengano spostate all'ingresso del negozio per una migliore visibilità quando un cliente entra. Oltre a una nuova collocazione, il prezzo di questo articolo viene ridotto. Per illustrare questo comportamento operativo e mantenere i dati storici, il record esistente viene aggiornato con una data di fine e ne viene inserito uno nuovo. Dai un'occhiata!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Calzini |
8.99 |
156 |
Corsia 11 |
2023-08-24 |
NULL |
|
747295 |
Maglia sportiva |
59.99 |
743 |
Corsia 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Maglia sportiva |
49.99 |
743 |
Espositore d'ingresso |
2023-11-13 |
NULL |
Come prima, creeremo innanzitutto una tabella chiamata stage_items. Questa tabella memorizzerà i record che verranno usati per implementare le SCD di tipo 2 nella corrispondente dimensione items, che assume la forma mostrata sopra. Una volta creata la tabella stage_items, inseriremo un record che contiene sia il cambio di collocazione sia il cambio di prezzo per le maglie sportive.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Ora è il momento di usare la funzionalità MERGE INTO di Snowflake per implementare le SCD di tipo 2. È un po' più complicato del precedente esempio e richiede un po' di ragionamento. Poiché un record può essere inserito solo se la condizione di match NON è soddisfatta, dovremo farlo in due passaggi. Per prima cosa creeremo una condizione di match con le seguenti tre istruzioni:
item_id nelle tabelle items e stage_items devono corrisponderestart_date nella tabella stage_items deve essere maggiore rispetto a quella nella tabella itemsend_date nella tabella items deve essere NULLSe queste tre condizioni sono soddisfatte, allora il record originale nella tabella items deve essere aggiornato. Nota che la colonna items.end_date non sarà più NULL; prenderà il valore della start_date nella tabella stage_items. Non c'è logica per i record non corrispondenti in questa prima istruzione.
Successivamente useremo una chiamata separata a MERGE INTO per inserire il nuovo record. Questo è un po' più complesso. Per inserire un nuovo record, la condizione di match non deve essere soddisfatta.
In questo esempio, possiamo farlo verificando se gli items_id nelle due tabelle corrispondono e se la end_date nella tabella items è NULL. Scomponiamolo ulteriormente.
items_id corrispondono e items.end_date è NULL, esiste già un record nella tabella items che è il più attuale. Questo significa che non dovrebbe essere inserito un nuovo record.item_id nelle due tabelle, la condizione di match non sarà soddisfatta e verrà inserita una nuova riga. Questo sarà il primo record per quell'item_id nella tabella items.item_id nella tabella stage_items corrisponde a record con lo stesso item_id nella tabella items e la end_date non è NULL, verrà inserito un nuovo valore. Questo mantiene i dati storici e garantisce che nella tabella items sia presente un record corrente.Di seguito l'implementazione, usando due istruzioni MERGE INTO per aggiornare prima il record esistente e poi inserire i dati più recenti.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Infine, vedremo come implementare le SCD di tipo 3 con una nuova dimensione. Nel nostro esempio, la tabella discounts memorizza informazioni su alcuni sconti che i clienti possono riscattare alla cassa. La tabella include l'ID dello sconto, nonché il nome, la percentuale di sconto e la classificazione come sconto stagionale. Ecco un esempio di due record che potrebbero essere presenti nella tabella discounts.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
50 |
NULL |
Poiché il retailer non si aspetta che gli sconti cambino spesso, questa dimensione è un'ottima candidata per implementare un approccio di tipo 3 alle slowly changing dimensions. Se la percentuale di sconto offerta cambia, la precedente percentuale verrà spostata nella colonna previous_percent_off , mentre il nuovo valore prenderà il suo posto nella colonna percent_off.
Questo consente di mantenere i dati storici pur esponendo il valore più recente nella colonna percent_off.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
35 |
50 |
Per implementarlo con Snowflake, creeremo una tabella stage_discounts e inseriremo un singolo record. Questo record includerà la nuova percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Anche qui useremo MERGE INTO per implementare le SCD di tipo 3. La condizione di match è semplice: se il discount_id nelle tabelle discounts e stage_discounts coincide e i valori di percent_off differiscono, il record esistente nella tabella discounts verrà aggiornato. Il valore percent_off esistente verrà spostato nel campo previous_percent_off; poi, se i discount_id nelle due tabelle non coincidono, verrà inserito un nuovo record con valore NULL. Nota che questi record non sono legati al tempo e può essere mantenuto solo un singolo valore storico per percent_off.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Ricorda: le SCD di tipo 3 si prestano meglio a dati che cambiano raramente e per cui si vuole mantenere solo la voce storica più recente. Se ci si aspettano più cambiamenti nella dimensione, probabilmente è meglio usare le SCD di tipo 2.
Quando si implementa qualsiasi tecnica per le slowly changing dimensions, è importante considerare la possibilità di dati duplicati. Esistono due tipi di duplicati a cui prestare attenzione: duplicati intra-batch e inter-batch. Vediamoli nel dettaglio.
I duplicati intra-batch sono duplicati che esistono tra diversi batch di dati. Se esiste una tabella di dimensione e due file destinati ad aggiornare questa tabella possono contenere record duplicati.
Per gestirlo, è importante aggiungere vincoli alla logica che esegue l'“upsert” e/o il caricamento dei dati in una tabella di dimensione. Negli esempi sopra, abbiamo aggiunto logica per garantire l'assenza di duplicati. Questo includeva:
employee_id corrispondentepercent_off fossero diversi nelle tabelle items e stage_items prima di aggiornare un record esistenteI duplicati inter-batch sono duplicati che si verificano nello stesso batch di dati. Ad esempio, se un file contiene due voci per aggiornare un singolo record in una tabella di dimensione, è necessario adottare precauzioni. Come per i duplicati intra-batch, è importante aggiungere vincoli alla logica usata per implementare SCD di tipo 1, 2 o 3.
Se nello stesso file ci sono record in conflitto, questi record dovranno essere differenziati in qualche modo. Potrebbero essere metadati sul record o un timestamp fornito dalla sorgente. Qualunque sia il metodo scelto per gestire questi duplicati, è importante documentare le tue assunzioni e rivederle con il tuo team per garantire che le dimensioni risultanti catturino accuratamente i valori operativi.
A volte i dati cambiano quando non dovrebbero. Con le tre tecniche SCD discusse finora, questo può portare alla sovrascrittura dei dati, all'aggiunta di una nuova riga o alla compilazione di dati in una nuova colonna.
Abbiamo discusso modi per evitare che dati duplicati finiscano nelle tabelle di dimensione. Oltre ai dati duplicati, i professionisti che implementano tecniche per gestire le slowly changing dimensions dovranno prestare attenzione a quanto segue:
Sebbene non tutti i casi sopra possano essere intercettati direttamente dal codice usato per mantenere le tabelle di dimensione, disporre di solide regole di qualità dei dati e di processi per monitorare le dimensioni può aiutare a garantire l'integrità dei dati.
Nell'esempio retail sopra, i dataset con cui abbiamo lavorato erano composti da poche righe di dati. In produzione, queste tabelle di dimensione potrebbero contenere centinaia o addirittura migliaia di record. Questo è molto comune quando si implementano SCD di tipo 2, specialmente se le dimensioni cambiano spesso.
Man mano che il numero di righe in una tabella di dimensione cresce, è importante per un professionista dei dati mantenere le prestazioni al centro della progettazione e dell'implementazione. Ecco alcuni modi per ottimizzare l'implementazione SCD per grandi dataset usando Snowflake:
MERGEUPDATE e INSERT dove opportuno, invece di MERGESe un dataset di dimensione diventa così grande da compromettere le prestazioni del sistema, potrebbe essere necessario decidere un compromesso tra accuratezza storica e prestazioni. Come accennato sopra, ciò accade tipicamente quando si implementano SCD di tipo 2.
Se i record cambiano spesso, il numero di righe in tabella può crescere rapidamente. In questi casi, potrebbe non essere più prudente usare SCD di tipo 2 per mantenere i dati dimensionali.
Passare a SCD di tipo 1 o tipo 3 può offrire funzionalità simili, con notevoli guadagni in termini di prestazioni di sistema. Il compromesso è una rappresentazione incompleta dei dati storici. Collabora con il tuo team per valutare questo compromesso prima di cambiare approccio nell'implementazione delle SCD.
Eseguire una query una tantum per implementare le SCD per una tabella di dimensione è piuttosto semplice. Tuttavia, eseguire programmaticamente questo processo per mantenere la dimensione in un ambiente di produzione richiede qualche considerazione. Strumenti come Apache Airflow sono ottimi per orchestrare questi processi e forniscono un livello di monitoraggio e allerta per garantire prestazioni nominali. Parametrizzando la logica usata per aggiornare le tabelle di dimensione, Airflow può avviare processi nella tua piattaforma dati in orari programmati, sostituendo gli sforzi manuali di un professionista dei dati
Oltre ad Airflow, strumenti come Mage, Prefect o Dagster possono essere usati per orchestrare l'implementazione delle slowly changing dimensions. Se strumenti di questo tipo non sono facilmente disponibili, anche soluzioni di orchestrazione interne possono andare bene.
Padroneggiare le slowly changing dimensions (SCD) è una competenza fantastica da avere nel tuo toolkit, soprattutto quando crei il tuo modello dati.
In questo articolo, abbiamo trattato le basi degli star schema, nonché le definizioni e i fondamenti delle SCD. Abbiamo esplorato le SCD di tipo 1, 2 e 3 per mantenere i dati storici catturando allo stesso tempo un'istantanea dello stato attuale.
Con l'aiuto di Snowflake, abbiamo implementato ciascuna delle tecniche SCD definite sopra con un esempio retail. Successivamente, abbiamo delineato alcune delle sfide tecniche che l'implementazione delle SCD può comportare e come affrontarle.
Per continuare a far crescere le tue competenze di data modeling, segui i corsi Database Design, Introduction to Data Engineering e Introduction to Data Warehousing disponibili su DataCamp. In bocca al lupo e buon coding!
Inizia oggi il tuo percorso nei dati!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

