
Cursus
Introductie tot Data Engineering
4 Hr
127.6K
Er zijn meerdere manieren om met slowly changing dimensions om te gaan. Laten we drie van de meest gangbare benaderingen bekijken.
Bij SCD type 1 geldt: als een record in een dimensietabel verandert, wordt het bestaande record geüpdatet of overschreven. Anders wordt het nieuwe record in de dimensietabel ingevoegd. Dit betekent dat records in de dimensietabel altijd de huidige status weerspiegelen en er geen historische data wordt bewaard.
Een tabel met informatie over de artikelen die in een supermarkt worden verkocht, kan veranderende records met SCD type 1 afhandelen. Als er al een record voor het betreffende artikel bestaat, wordt het geüpdatet met de nieuwe informatie. Anders wordt het record in de dimensietabel ingevoegd.
In de data-engineeringwereld staat deze praktijk van updaten als het bestaat, of anders invoegen, bekend als “upserten”. De onderstaande tabel bevat informatie over artikelen die in een supermarkt worden verkocht.
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Als Potato Chips naar gangpad 6 worden verplaatst, levert SCD type 1 om deze wijziging in de dimensietabel vast te leggen het onderstaande resultaat op:
SCD type 1 zorgt ervoor dat er geen dubbele records in de tabel staan en dat de data de meest recente, huidige dimensie weerspiegelt. Dit is vooral handig voor realtimedashboards en voorspellende modellen, waar alleen de huidige status relevant is.
Omdat alleen de meest recente informatie in de tabel staat, kunnen dataprofessionals echter niet vergelijken hoe dimensies in de tijd veranderen. Een data-analist zou bijvoorbeeld lastig de omzetstijging voor Potato Chips kunnen vaststellen nadat ze naar gangpad 6 zijn verplaatst, zonder aanvullende informatie.
SCD type 1 maakt rapportage en analyse van de huidige toestand gemakkelijk, maar kent beperkingen bij historische analyses.
Hoewel een tabel die alleen de huidige toestand weergeeft nuttig kan zijn, zijn er momenten waarop het handig, of zelfs essentieel, is om historische wijzigingen in een dimensie te volgen. Met SCD type 2 wordt historische data bewaard door een nieuwe rij toe te voegen wanneer een dimensie verandert en deze nieuwe rij als actueel te markeren, terwijl het eerder actuele record als historisch wordt gemarkeerd.
Makkelijk gezegd, maar hoe ziet dat er in de praktijk uit? Laten we een voorbeeld bekijken.
Hier hebben we een tabel die lijkt op het voorbeeld bij SCD type 1. Er is echter een extra kolom toegevoegd. De kolom is_current slaat een booleaanse waarde op; true als het record de meest actuele waarde weergeeft, en false anders.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
True |
|
07879 |
Soda |
7.99 |
13 |
True |
Als Potato Chips naar gangpad 6 verhuizen, zou SCD type 2 om deze wijziging vast te leggen een tabel opleveren die er zo uitziet:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
False |
|
07879 |
Soda |
7.99 |
13 |
True |
|
93201 |
Potato Chips |
3.99 |
6 |
True |
Er wordt een nieuwe rij toegevoegd om de wijziging van de locatie voor Potato Chips vast te leggen, met True in de kolom is_current. Om historische data te bewaren en de huidige status juist weer te geven, wordt de kolom is_current voor het vorige record op False gezet. Met SCD type 1,
Maar wat als je wilt onderzoeken hoe de verkoop van Potato Chips reageerde op de locatiewijziging? Dat is lastig met slechts één kolom als er meerdere historische records voor één artikel zijn. Gelukkig is daar een eenvoudige oplossing voor.
Bekijk de onderstaande tabel. Deze dimensietabel bevat dezelfde informatie als voorheen, maar in plaats van een kolom is_current zijn er nu zowel een kolom start_date als end_date. Deze datums vertegenwoordigen de periode waarin een dimensie de meest actuele was. Omdat de data in deze tabel het meest recent is, staat de end_date ver in de toekomst.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Als de Potato Chips op 4 januari 2024 naar gangpad 6 zijn verplaatst, ziet de bijgewerkte tabel er zo uit:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Merk op dat de end_date voor de eerste rij is bijgewerkt naar de laatste dag dat Potato Chips in gangpad 11 lagen. Er is een nieuw record toegevoegd, met Potato Chips nu in gangpad 6. De start_date en end_date laten zien wanneer de wijziging is doorgevoerd en welke rij actueel is.
Met deze techniek om SCD type 1 te implementeren, behoud je niet alleen historische data, je krijgt ook informatie over wanneer data is gewijzigd. Hierdoor kunnen data-analisten en data scientists operationele wijzigingen onderzoeken, A/B-testen uitvoeren en beter onderbouwde beslissingen nemen.
Bij data waarvan je verwacht dat die slechts één keer verandert, of wanneer alleen het meest recente historische record interessant is, is SCD type 3 erg handig. In plaats van een gewijzigde dimensie te “upserten” of de wijziging als een nieuwe rij op te slaan, gebruikt SCD type 3 een kolom om de wijziging te representeren. Dat is lastig uit te leggen, dus laten we meteen een voorbeeld bekijken.
De onderstaande tabel bevat informatie over sportteams in de Verenigde Staten. Hier bevat de tabel twee kolommen om een huidige en een historische stadionnaam op te slaan. Omdat elk van deze teams de oorspronkelijke stadionnaam gebruikt, is de kolom previous_stadium_name gevuld met NULLs.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Als de Lafayette Hawks een nieuwe sponsor voor een contract van vijfentwintig jaar aannemen, ziet de bijgewerkte tabel er ongeveer zo uit:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Om rekening te houden met de nieuwe stadionnaam wordt “Triple X Stadium” verplaatst naar de kolom previous_stadium_name, en “Wabash Field” komt in de kolom current_stadium_name. De nieuwe sponsorovereenkomst van vijfentwintig jaar zal waarschijnlijk langer meegaan dan het te bouwen model, wat betekent dat het record waarschijnlijk niet nog eens zal veranderen.
Met SCD type 3 wordt het vergelijken van actuele data met historische data heel eenvoudig. Er is slechts één rij per team, en de huidige en historische data staan naast elkaar in twee kolommen. Dit betekent echter ook dat je slechts één historisch record voor één dimensioneel attribuut kunt bewaren, wat beperkend kan zijn, zeker als data vaker verandert dan verwacht.
Naast type 1, 2 en 3 zijn er nog andere technieken om slowly changing dimensions te implementeren. Type 0 wordt gebruikt wanneer dimensies nooit mogen veranderen. Type 4 bewaart historische data in een aparte tabel, terwijl de meest actuele data in een dimensietabel blijft. Type 6 is een combinatie van type 1, 2 en 3 en wordt doorgaans geïmplementeerd door de beste eigenschappen van deze technieken te combineren.
We hebben de basis van slowly changing dimensions behandeld. Om beter te begrijpen hoe je elke techniek implementeert, bekijken we een voorbeeld.
In dit voorbeeld gebruiken we Snowflake om SCD type 1, 2 en 3 te implementeren voor retailtransacties. Heb je een opfrisser nodig voor Snowflake? Bekijk dan onze Introduction to Snowflake-cursus.
Er is één facttabel, genaamd sales, en drie dimensietabellen, met de namen employees, items en discounts. Hieronder staat het ERD voor dit sterrenschema.
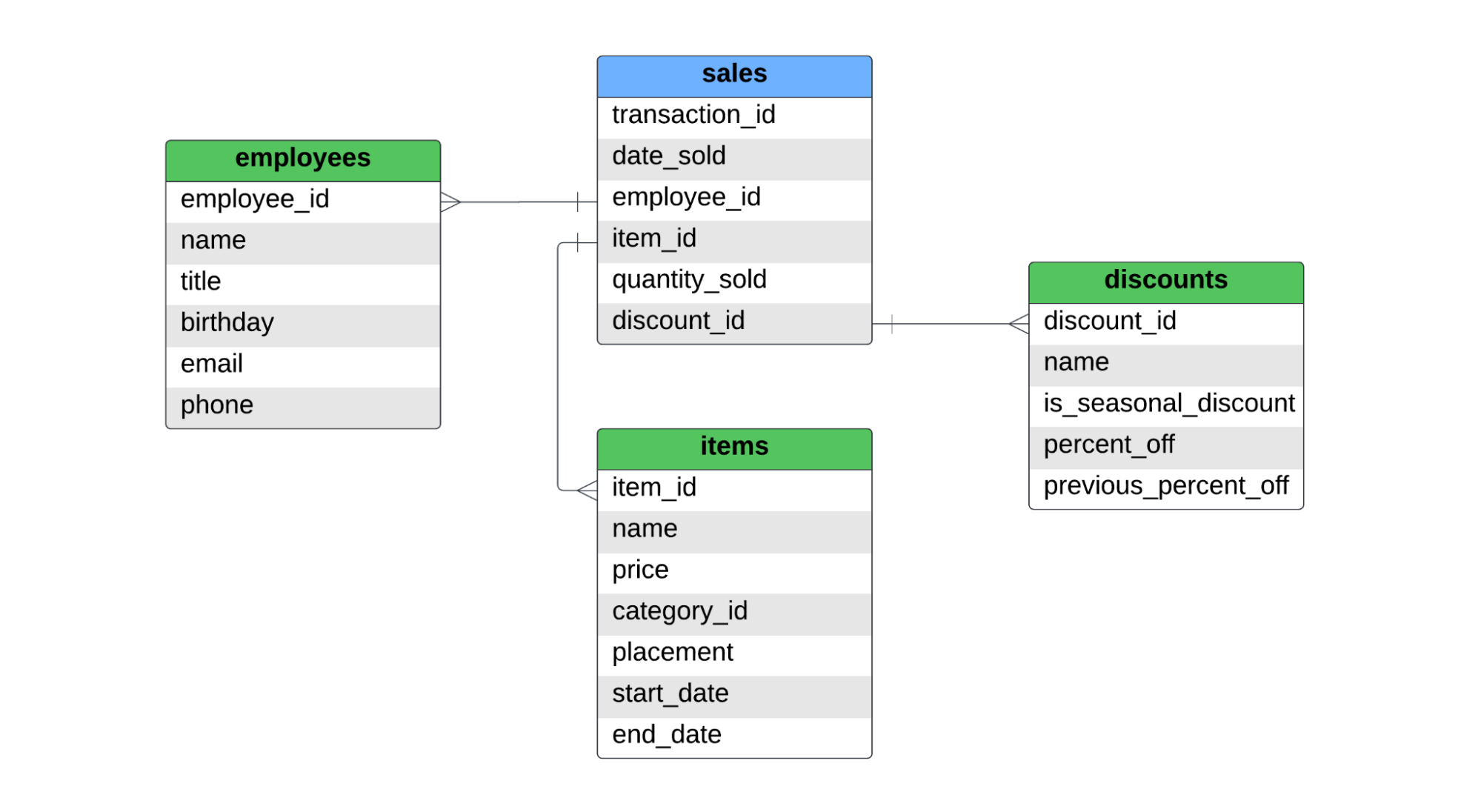
De tabel sales legt verkopen op artikelniveau vast. Als een klant twee shirts en een spijkerbroek koopt, staan er twee records in de facttabel, omdat er twee verschillende artikelen zijn verkocht. Voor SCD type 1, type 2 en type 3 behandelen we het volgende:
We gaan niet in op hoe deze tabellen oorspronkelijk zijn gevuld, maar meestal heeft een ETL- of ELT-pijplijn stroomopwaarts van het datawarehouse ruwe data uit de bron gehaald, getransformeerd naar het gewenste model en in de eindbestemming geladen.
Om SCD type 1 te oefenen, bekijken we de tabel employee. Deze tabel bevat basisinformatie over een medewerker, waaronder naam, functietitel en contactgegevens. Er kunnen records in staan zoals hieronder.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Bij SCD type 1 wordt de bestaande rij overschreven door het meest recente record. Als een van deze dimensionele attributen wijzigt, moet het nieuwe record in de bestaande tabel worden “geupsert”. Als Emily’s telefoonnummer bijvoorbeeld verandert in 928-652-9704, ziet de nieuwe tabel er zo uit:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Om dit in Snowflake te doen, gebruiken we het commando MERGE INTO. Met MERGE INTO kan een dataprofessional een matchkey en een voorwaarde opgeven. Als de matchkey en de voorwaarde kloppen, kan het record met het trefwoord UPDATE worden bijgewerkt. Anders kan een record worden INSERT’ed, of stopt de uitvoering.
Voor we met MERGE INTO beginnen, maken we eerst een tabel stage_employees aan en vullen we die. Deze bevat alle records die sinds de laatste verversing van de employees-tabel zijn bijgewerkt. Dat kan met de onderstaande statements.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Nu kunnen we de MERGE-functionaliteit van Snowflake gebruiken om het bestaande record te “upserten”.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Hierboven was de sleutel om data tussen de tabellen employees en stage_employees te mergen het veld employee_id. Er is geen extra voorwaarde ingesteld, wat betekent dat als de employee_id’s overeenkomen, de dimensionele attributen name, title, email en phone voor die employee ID worden bijgewerkt met de waarden uit stage_employees. Als records in stage_employees met geen enkel record in employees overeenkomen, wordt het record in de employees-tabel ingevoegd.
SCD type 2 implementeren is wat lastiger dan type 1. Hoewel het niet zo eenvoudig is als een bestaand record overschrijven of anders invoegen, kunnen we nog steeds de MERGE INTO-logica van Snowflake gebruiken om dit probleem aan te pakken. Bekijk de onderstaande dimensie.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
NULL |
Deze tabel bevat informatie over specifieke artikelen die in een winkel worden verkocht. De dimensionele attributen omvatten de naam, prijs en plaatsing van het artikel en een vreemde sleutel naar de categorie waartoe het artikel behoort. Voor SCD type 2 moeten we data “upserten”, dit keer met start_date en end_date om zowel historische als actuele data te behouden.
Stel dat aan het begin van het NFL-seizoen (National Football League) sportshirts naar de voorkant van de winkel worden verplaatst voor betere zichtbaarheid wanneer een klant binnenkomt. Naast een nieuwe locatie gaat de prijs omlaag. Om dit operationele gedrag te illustreren en historische data te bewaren, wordt het bestaande record bijgewerkt met een einddatum en wordt er een nieuw record ingevoegd. Kijk maar!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sports Jersey |
49.99 |
743 |
Entry Display |
2023-11-13 |
NULL |
Net als hiervoor maken we eerst een tabel stage_items. Deze tabel slaat records op die worden gebruikt om SCD type 2 te implementeren in de bijbehorende dimensie items, met de vorm zoals hierboven. Nadat de tabel stage_items is gemaakt, voegen we een record in dat zowel de wijziging in plaatsing als in prijs voor sportshirts bevat.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Tijd om de MERGE INTO-functionaliteit van Snowflake te gebruiken om SCD type 2 te implementeren. Dit is wat lastiger dan het vorige voorbeeld en vereist wat denkwerk. Omdat een record alleen kan worden ingevoegd als de matchvoorwaarde NIET wordt gehaald, doen we dit in twee stappen. Eerst maken we een matchvoorwaarde met de volgende drie statements:
item_id’s in de tabellen items en stage_items moeten overeenkomenstart_date in de tabel stage_items moet groter zijn dan in de tabel itemsend_date in de tabel items moet NULL zijnAls aan deze drie voorwaarden wordt voldaan, moet het oorspronkelijke record in de tabel items worden bijgewerkt. Merk op dat de kolom items.end_date niet langer NULL is; deze krijgt de waarde van de start_date in de tabel stage_items. Er is geen logica voor onbematchte records in deze eerste statement.
Vervolgens gebruiken we een aparte aanroep van MERGE INTO om het nieuwe record in te voegen. Dit is wat lastiger. Om een nieuw record in te voegen, mag de matchvoorwaarde niet gelden.
In dit voorbeeld kunnen we dit doen door te controleren of de items_id’s in de twee tabellen overeenkomen en of de end_date in de tabel items NULL is. Laten we dat verder uitsplitsen.
items_id’s overeenkomen en items.end_date NULL is, is er al een record in de tabel items dat het meest actueel is. Dan moet er geen nieuw record worden ingevoegd.item_id’s in de twee tabellen, wordt de matchvoorwaarde niet gehaald en wordt er een nieuwe rij ingevoegd. Dit is het eerste record voor die item_id in de tabel items.item_id in de tabel stage_items overeenkomt met records met diezelfde item_id in de tabel items, en de end_date is niet NULL, dan wordt een nieuwe waarde ingevoerd. Dit bewaart historische data en zorgt ervoor dat er een actueel record in de tabel items staat.Hieronder staat de implementatie, met twee MERGE INTO-statements om eerst het bestaande record bij te werken en vervolgens de meest actuele data in te voegen.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Tot slot bekijken we de implementatie van SCD type 3 met een nieuwe dimensie. In ons voorbeeld slaat de tabel discounts informatie op over bepaalde kortingen die klanten bij het afrekenen kunnen inwisselen. De tabel bevat het ID van de korting, de naam, het kortingspercentage en de classificatie als seizoenskorting. Hier zijn twee voorbeeldrecords die in de tabel discounts kunnen staan.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
50 |
NULL |
Omdat de retailer niet verwacht dat de kortingen vaak veranderen, is deze dimensie een uitstekende kandidaat om een type 3-aanpak voor slowly changing dimensions te gebruiken. Als het kortingspercentage verandert, verhuist het vorige percentage naar de kolom previous_percent_off, terwijl de nieuwe waarde in de kolom percent_off komt te staan.
Zo blijft historische data bewaard, terwijl de meest recente waarde zichtbaar is in de kolom percent_off.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
35 |
50 |
Om dit in Snowflake te implementeren, maken we een tabel stage_discounts en voegen we één record in. Dit record bevat het nieuwe percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Wederom gebruiken we MERGE INTO om SCD type 3 te implementeren. De matchvoorwaarde is simpel; als de discount_id in de tabellen discounts en stage_discounts overeenkomen en de waarden in percent_off verschillen, wordt het bestaande record in discounts bijgewerkt. De bestaande waarde van percent_off wordt verplaatst naar previous_percent_off en als de discount_id’s in de twee tabellen niet overeenkomen, wordt een nieuw record ingevoerd met de waarde NULL. Merk op dat deze records niet tijdsgebonden zijn en dat er slechts één historische waarde voor percent_off kan worden bewaard.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Onthoud: SCD type 3 gebruik je het best bij data die zelden verandert en waarbij alleen de meest recente historische invoer wordt bewaard. Verwacht je meerdere wijzigingen in de dimensie, dan is SCD type 2 waarschijnlijk beter.
Bij het implementeren van een techniek voor slowly changing dimensions is het belangrijk rekening te houden met de mogelijkheid van duplicaten. Er zijn twee soorten duplicaten om op te letten: intrabatch- en interbatchduplicaten. Laten we dat uitsplitsen.
Intrabatchduplicaten zijn duplicaten die bestaan tussen verschillende batches data. Als er al een dimensietabel is, kunnen twee bestanden die deze tabel moeten bijwerken, dubbele records bevatten.
Om dit aan te pakken, is het belangrijk om beperkingen toe te voegen aan je logica die data “upsert” en/of laadt naar een dimensietabel. In onze voorbeelden hierboven hebben we logisch gecontroleerd om duplicaten te voorkomen. Dit omvatte:
employee_id bestondpercent_off verschilden in de tabellen items en stage_items voordat een bestaand record werd bijgewerktInterbatchduplicaten zijn duplicaten die in dezelfde databatch voorkomen. Als een bestand bijvoorbeeld twee invoeren bevat om één record in een dimensietabel bij te werken, moeten er voorzorgsmaatregelen worden genomen. Net als bij intrabatchduplicaten is het belangrijk om beperkingen toe te voegen aan de logica die wordt gebruikt om SCD type 1, 2 of 3 te implementeren.
Als er conflicterende records in hetzelfde bestand staan, moeten deze op de een of andere manier worden onderscheiden. Dit kan met metadata over het record of een timestamp uit de bron. Hoe je deze duplicaten ook aanpakt, het is belangrijk om je aannames te documenteren en met je team te bespreken, zodat de resulterende dimensies operationele waarden nauwkeurig vastleggen.
Soms verandert data terwijl dat niet zou moeten. Met de drie SCD-technieken die we tot nu toe hebben besproken, kan dat ertoe leiden dat data wordt overschreven, dat er een nieuwe rij wordt toegevoegd of dat data in een nieuwe kolom terechtkomt.
We hebben besproken hoe je voorkomt dat duplicaatdata in dimensietabellen terechtkomt. Naast duplicaten moeten dataprofessionals die technieken voor slowly changing dimensions implementeren letten op het volgende:
Hoewel niet alle bovenstaande gevallen direct in de code voor het beheer van dimensietabellen kunnen worden opgevangen, kunnen goede datakwaliteitsregels en processen om dimensies te monitoren helpen om de dataintegriteit te waarborgen.
In het retailvoorbeeld hierboven bestonden de datasets uit slechts een paar rijen. In een productieomgeving kunnen deze dimensietabellen honderden of zelfs duizenden records bevatten. Dit komt vaak voor bij SCD type 2, vooral als dimensies vaak veranderen.
Naarmate het aantal rijen in een dimensietabel groeit, is het belangrijk om performance centraal te houden in het ontwerp en de implementatie. Hier zijn enkele manieren om SCD-implementatie voor grote datasets in Snowflake te optimaliseren:
MERGE-statement(s) moet worden verwerktUPDATE- en INSERT-statements te gebruiken waar passend, in plaats van MERGEAls een dimensiedataset zo groot wordt dat systeemprestaties in het gedrang komen, moet mogelijk een afweging worden gemaakt tussen historische nauwkeurigheid en prestaties. Zoals hierboven genoemd, is dit meestal het geval bij SCD type 2.
Als records vaak veranderen, kan het aantal rijen in de tabel snel exploderen. In dat geval is het misschien niet langer verstandig om SCD type 2 te gebruiken om dimensionele data te beheren.
Overschakelen naar SCD type 1 of type 3 kan vergelijkbare functionaliteit bieden, met aanzienlijke prestatieverbeteringen. De keerzijde is een onvolledige weergave van historische data. Weeg deze trade-off met je team af voordat je de aanpak aanpast.
Eén keer een query uitvoeren om SCD voor een dimensietabel te implementeren is eenvoudig genoeg. Maar dit proces programmatisch uitvoeren om een dimensie in een productieomgeving te onderhouden, vergt wat denkwerk. Tools zoals Apache Airflow zijn uitstekend voor het orkestreren van deze processen en bieden monitoring en alerting om nominale prestaties te waarborgen. Door de logica te parameteriseren die wordt gebruikt om dimensietabellen bij te werken, kan Airflow processen in je dataplatform volgens een schema starten en zo handmatig werk vervangen.
Naast Airflow kunnen tools zoals Mage, Prefect of Dagster worden gebruikt om de implementatie van slowly changing dimensions te orkestreren. Als zulke tools niet voorhanden zijn, kunnen zelfgebouwde orkestratietools ook volstaan.
Slowly changing dimensions (SCD) beheersen is een fantastische vaardigheid voor in je gereedschapskist, zeker wanneer je je eigen datamodel bouwt.
In dit artikel hebben we de basis van sterrenschema’s en de definities en basisprincipes van SCD behandeld. We hebben SCD types 1, 2 en 3 verkend om historische data te behouden terwijl we een momentopname van de huidige status vastleggen.
Met behulp van Snowflake hebben we elk van de hierboven gedefinieerde SCD-technieken geïmplementeerd aan de hand van een retailvoorbeeld. Daarna hebben we enkele technische uitdagingen geschetst die SCD met zich mee kan brengen en hoe je die aanpakt.
Om je datamodelleringsvaardigheden te blijven ontwikkelen, volg de cursussen Database Design, Introduction to Data Engineering en Introduction to Data Warehousing op DataCamp. Succes en veel codeerplezier!
Begin vandaag nog met je datareis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
