
Courses
Introduction to Data Engineering
4 giờ
127.6K
Có nhiều cách để xử lý slowly changing dimensions. Hãy xem ba cách phổ biến nhất.
Với SCD loại 1, nếu một bản ghi trong bảng dimension thay đổi, bản ghi hiện có sẽ được cập nhật hoặc ghi đè. Nếu không, bản ghi mới sẽ được chèn vào bảng dimension. Điều này có nghĩa là các bản ghi trong bảng dimension luôn phản ánh trạng thái hiện tại và không lưu trữ dữ liệu lịch sử.
Một bảng lưu thông tin về các mặt hàng bán trong cửa hàng tạp hóa có thể xử lý bản ghi thay đổi bằng SCD loại 1. Nếu bản ghi cho mặt hàng cần thiết đã tồn tại trong bảng, nó sẽ được cập nhật bằng thông tin mới. Nếu không, bản ghi sẽ được chèn vào bảng dimension.
Trong thế giới kỹ thuật dữ liệu, thực hành cập nhật dữ liệu nếu đã tồn tại hoặc chèn nếu chưa được gọi là “upsert”. Bảng dưới đây chứa thông tin về các mặt hàng bán trong cửa hàng tạp hóa.
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Nếu Potato Chips được chuyển sang dãy 6, sử dụng SCD loại 1 để ghi nhận thay đổi này trong bảng dimension sẽ cho kết quả như sau:
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
SCD loại 1 đảm bảo không có bản ghi trùng lặp trong bảng và dữ liệu phản ánh dimension hiện tại nhất. Điều này đặc biệt hữu ích cho dashboard thời gian thực và mô hình dự báo, nơi chỉ trạng thái hiện tại được quan tâm.
Tuy nhiên, vì chỉ lưu thông tin mới nhất trong bảng, người làm dữ liệu không thể so sánh các thay đổi của dimension theo thời gian. Ví dụ, nhà phân tích dữ liệu sẽ khó xác định mức tăng doanh thu của Potato Chips sau khi chuyển sang dãy 6 nếu không có thông tin khác.
SCD loại 1 giúp báo cáo và phân tích trạng thái hiện tại trở nên dễ dàng nhưng có hạn chế khi phân tích lịch sử.
Mặc dù một bảng chỉ phản ánh trạng thái hiện tại có thể hữu ích, nhưng có lúc việc theo dõi các thay đổi lịch sử của một dimension lại tiện lợi, thậm chí thiết yếu. Với SCD loại 2, dữ liệu lịch sử được duy trì bằng cách thêm một dòng mới khi dimension thay đổi và đánh dấu đúng dòng mới là hiện tại, đồng thời đánh dấu dòng cũ là lịch sử.
Nói thì dễ, nhưng trong thực tế trông như thế nào có thể chưa rõ. Hãy xem một ví dụ.
Ở đây, chúng ta có một bảng khá giống ví dụ khi tìm hiểu SCD loại 1. Tuy nhiên, đã thêm một cột. Cột is_current lưu giá trị boolean; true nếu bản ghi phản ánh giá trị hiện tại nhất, và false nếu không.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
True |
|
07879 |
Soda |
7.99 |
13 |
True |
Nếu Potato Chips chuyển sang dãy 6, sử dụng SCD loại 2 để ghi nhận thay đổi này sẽ tạo ra một bảng như sau:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
False |
|
07879 |
Soda |
7.99 |
13 |
True |
|
93201 |
Potato Chips |
3.99 |
6 |
True |
Một dòng mới được thêm để phản ánh thay đổi vị trí của Potato Chips, với True trong cột is_current. Để duy trì dữ liệu lịch sử và mô tả chính xác trạng thái hiện tại, cột is_current của bản ghi trước đó được đặt thành False. Với SCD loại 1,
Nhưng nếu bạn muốn xem doanh số Potato Chips phản ứng thế nào với việc đổi vị trí thì sao? Điều này khá khó khi chỉ dùng một cột nếu có nhiều bản ghi lịch sử cho một mặt hàng. May mắn là có cách đơn giản để làm điều này.
Xem bảng dưới đây. Bảng dimension này chứa cùng thông tin như trước, nhưng thay vì cột is_current, nó có cả start_date và end_date. Các ngày này biểu thị khoảng thời gian một dimension là hiện tại nhất. Vì dữ liệu trong bảng này là mới nhất, end_date được đặt ở thời điểm rất xa trong tương lai.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Nếu Potato Chips chuyển sang dãy 6 vào ngày 04-01-2024, bảng cập nhật sẽ như sau:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Lưu ý rằng end_date của dòng đầu tiên đã được cập nhật thành ngày cuối cùng Potato Chips còn ở dãy 11. Một bản ghi mới được thêm, với Potato Chips hiện đặt ở dãy 6. Các cột start_date và end_date cho biết thời điểm thay đổi và bản ghi nào là hiện tại.
Sử dụng kỹ thuật này để triển khai SCD loại 1 không chỉ bảo toàn dữ liệu lịch sử mà còn cung cấp thông tin về thời điểm dữ liệu thay đổi. Điều này cho phép nhà phân tích và nhà khoa học dữ liệu khám phá thay đổi vận hành, thực hiện A/B testing và đưa ra quyết định có cơ sở.
Khi làm việc với dữ liệu chỉ kỳ vọng thay đổi một lần, hoặc chỉ quan tâm đến bản ghi lịch sử gần nhất, SCD loại 3 rất hữu ích. Thay vì “upsert” một dimension đã thay đổi hoặc lưu thay đổi như một dòng mới, SCD loại 3 dùng một cột để biểu diễn thay đổi. Điều này hơi khó giải thích, nên hãy vào thẳng ví dụ.
Bảng dưới chứa thông tin về các môn thể thao cho các đội trên khắp Hoa Kỳ. Ở đây, bảng có hai cột để lưu tên sân vận động hiện tại và lịch sử. Vì mỗi đội đều đang dùng tên sân ban đầu, cột previous_stadium_name được điền NULL.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Nếu Lafayette Hawks ký tài trợ mới trong 25 năm, bảng cập nhật sẽ trông như sau:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
Để phản ánh tên sân mới, “Triple X Stadium" được chuyển sang cột previous_stadium_name, và “Wabash Field" thay vào cột current_stadium_name. Thỏa thuận tài trợ mới kéo dài 25 năm có khả năng lâu hơn vòng đời của mô hình đang xây, nghĩa là bản ghi nhiều khả năng sẽ không thay đổi nữa.
Dùng SCD loại 3 giúp so sánh dữ liệu trạng thái hiện tại với dữ liệu lịch sử khá đơn giản. Mỗi đội chỉ có một dòng, và dữ liệu hiện tại cùng lịch sử nằm cạnh nhau ở hai cột khác nhau. Tuy nhiên, điều này đồng nghĩa chỉ có thể duy trì một bản ghi lịch sử cho một thuộc tính dimension, có thể hạn chế, đặc biệt nếu dữ liệu thay đổi thường xuyên hơn dự kiến.
Ngoài các loại 1, 2 và 3, còn có nhiều kỹ thuật khác để triển khai slowly changing dimensions. Loại 0 dùng khi dimension không bao giờ thay đổi. Loại 4 lưu dữ liệu lịch sử ở bảng riêng trong khi giữ dữ liệu hiện tại ở bảng dimension. Loại 6 là sự kết hợp của loại 1, 2 và 3, thường được triển khai bằng cách kết hợp các ưu điểm của từng kỹ thuật.
Chúng ta đã điểm qua các kiến thức cơ bản về slowly changing dimensions. Để hiểu rõ hơn cách triển khai từng kỹ thuật, hãy xem một ví dụ.
Trong ví dụ này, chúng ta sẽ dùng Snowflake để triển khai SCD loại 1, 2 và 3 cho giao dịch bán lẻ. Nếu bạn cần ôn lại Snowflake, hãy xem khóa Introduction to Snowflake của chúng tôi.
Có một bảng fact tên sales và ba bảng dimension tên employees, items và discounts. Dưới đây là ERD cho mô hình sao này.
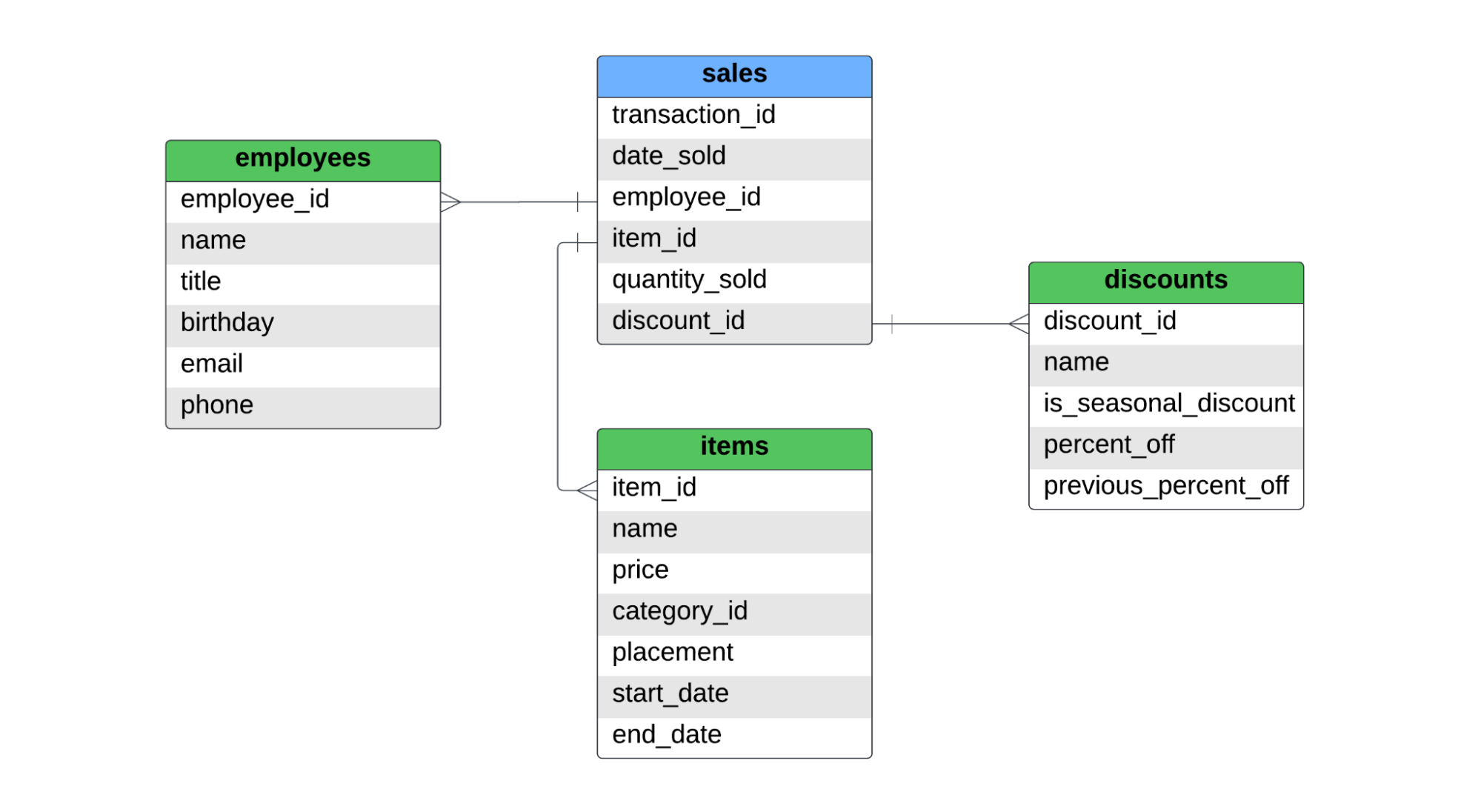
Bảng sales ghi nhận doanh số theo từng mặt hàng. Nếu một khách mua hai chiếc áo và một quần jean, sẽ có hai bản ghi trong bảng fact, vì đã bán hai mặt hàng khác nhau. Với SCD loại 1, 2 và 3, chúng ta sẽ đề cập đến:
Chúng ta sẽ không xem cách các bảng này được điền dữ liệu ban đầu, nhưng thường thì một pipeline ETL hoặc ELT ở thượng nguồn kho dữ liệu sẽ trích xuất dữ liệu thô từ nguồn, biến đổi về mô hình mong muốn và nạp vào đích cuối.
Để thực hành triển khai SCD loại 1, chúng ta sẽ xem bảng employee. Bảng này chứa thông tin cơ bản về nhân viên, gồm tên, chức danh và thông tin liên hệ. Nó có thể chứa các bản ghi như sau.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Dùng SCD loại 1 để ghi nhận dimension thay đổi chậm này, bản ghi hiện có sẽ bị ghi đè bởi bản ghi mới nhất. Nếu một trong các thuộc tính dimension này thay đổi, bản ghi mới nên được “upsert” vào bảng hiện có. Ví dụ, nếu số điện thoại của Emily đổi thành 928-652-9704, bảng mới sẽ như sau:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Để làm điều này với Snowflake, chúng ta sẽ dùng lệnh MERGE INTO. MERGE INTO cho phép người làm dữ liệu cung cấp khóa đối sánh và một điều kiện. Nếu khóa đối sánh và điều kiện thỏa, bản ghi có thể được cập nhật với từ khóa UPDATE. Nếu không, có thể INSERT bản ghi, hoặc dừng thực thi.
Trước khi bắt đầu với lệnh MERGE INTO, chúng ta sẽ tạo và thêm bản ghi vào bảng tên stage_employees. Bảng này sẽ chứa mọi bản ghi đã được cập nhật kể từ lần cuối bảng employees được làm mới. Ta có thể làm điều này bằng các câu lệnh dưới đây.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Giờ đây, chúng ta có thể dùng tính năng MERGE của Snowflake để “upsert” bản ghi hiện có.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Ở trên, khóa để gộp dữ liệu giữa bảng employees và stage_employees là trường employee_id. Không đặt điều kiện khác, nghĩa là nếu employee_id khớp, các thuộc tính dimension name, title, email và phone sẽ được cập nhật bằng giá trị từ bảng stage_employees cho employee ID đó. Nếu bản ghi từ stage_employees không khớp với bản ghi nào từ bảng employees, bản ghi sẽ được chèn vào bảng employees.
Triển khai SCD loại 2 khó hơn một chút so với loại 1. Dù không đơn giản như ghi đè bản ghi hiện có hoặc chèn nếu không có, ta vẫn có thể dùng logic MERGE INTO của Snowflake để xử lý vấn đề này. Hãy xem dimension dưới đây.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
NULL |
Bảng này chứa thông tin về các mặt hàng cụ thể bán tại cửa hàng bán lẻ. Các thuộc tính dimension bao gồm tên, giá và vị trí trưng bày của mặt hàng, cũng như khóa ngoại tới danh mục của mặt hàng. Để triển khai SCD loại 2, ta cần “upsert” dữ liệu, lần này dùng start_date và end_date để duy trì cả dữ liệu lịch sử và hiện tại.
Giả sử vào đầu mùa giải NFL (National Football League), áo thể thao được chuyển ra phía trước cửa hàng để khách dễ thấy khi bước vào. Cùng với vị trí mới, giá mặt hàng này được giảm. Để mô tả hành vi vận hành này, đồng thời duy trì dữ liệu lịch sử, bản ghi hiện có được cập nhật với ngày kết thúc, và chèn thêm bản ghi mới. Xem nhé!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sports Jersey |
49.99 |
743 |
Entry Display |
2023-11-13 |
NULL |
Tương tự như trước, trước hết chúng ta sẽ tạo bảng tên stage_items. Bảng này sẽ lưu các bản ghi dùng để triển khai SCD loại 2 trong dimension items tương ứng, có dạng như trên. Sau khi tạo bảng stage_items, ta sẽ chèn một bản ghi chứa cả thay đổi vị trí và giá cho áo thể thao.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Giờ là lúc dùng tính năng MERGE INTO của Snowflake để triển khai SCD loại 2. Điều này khó hơn ví dụ trước một chút và cần suy nghĩ kỹ. Vì chỉ có thể chèn bản ghi nếu điều kiện khớp KHÔNG thỏa, chúng ta sẽ làm trong hai bước. Đầu tiên ta tạo điều kiện khớp với ba mệnh đề sau:
item_id ở bảng items và stage_items phải khớpstart_date ở bảng stage_items phải lớn hơn ở bảng itemsend_date ở bảng items phải là NULLNếu ba điều kiện này thỏa, thì bản ghi gốc trong bảng items phải được cập nhật. Lưu ý cột items.end_date sẽ không còn NULL; nó sẽ nhận giá trị start_date ở bảng stage_items. Không có logic cho trường hợp không khớp trong câu lệnh đầu tiên này.
Tiếp theo, ta dùng một lệnh MERGE INTO riêng để chèn bản ghi mới. Điều này khó hơn một chút. Để chèn bản ghi mới, điều kiện khớp phải không thỏa.
Trong ví dụ này, ta có thể làm bằng cách kiểm tra xem items_id ở hai bảng có khớp không, và end_date ở bảng items có là NULL không. Cùng phân tích kỹ hơn.
items_id khớp và items.end_date là NULL, đã có một bản ghi hiện tại trong bảng items. Nghĩa là không nên chèn bản ghi mới.item_id ở hai bảng, điều kiện khớp không thỏa và sẽ chèn một dòng mới. Đây sẽ là bản ghi đầu tiên cho item_id đó trong bảng items.item_id ở bảng stage_items khớp với các bản ghi có cùng item_id ở bảng items, và end_date không phải NULL, sẽ chèn giá trị mới. Điều này duy trì dữ liệu lịch sử và đảm bảo có bản ghi hiện tại trong bảng items.Dưới đây là phần triển khai, dùng hai câu lệnh MERGE INTO để trước hết cập nhật bản ghi hiện có rồi chèn dữ liệu hiện tại nhất.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Cuối cùng, chúng ta sẽ xem cách triển khai SCD loại 3 với một dimension mới. Trong ví dụ, bảng discounts lưu thông tin về một số ưu đãi mà khách hàng có thể sử dụng khi thanh toán. Bảng bao gồm ID ưu đãi, tên, phần trăm giảm giá và phân loại là ưu đãi theo mùa hay không. Dưới đây là ví dụ hai bản ghi có thể có trong bảng discounts.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
50 |
NULL |
Vì nhà bán lẻ không kỳ vọng các ưu đãi thay đổi thường xuyên, dimension này là ứng viên tuyệt vời để áp dụng cách tiếp cận loại 3 cho slowly changing dimensions. Nếu phần trăm giảm của ưu đãi thay đổi, giá trị phần trăm trước đó sẽ chuyển sang cột previous_percent_off , trong khi giá trị mới sẽ thay vào cột percent_off.
Điều này cho phép duy trì dữ liệu lịch sử đồng thời hiển thị giá trị mới nhất ở cột percent_off.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
35 |
50 |
Để triển khai với Snowflake, chúng ta sẽ tạo bảng stage_discounts và chèn một bản ghi. Bản ghi này sẽ bao gồm percent_off mới.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Một lần nữa, chúng ta dùng MERGE INTO để triển khai SCD loại 3. Điều kiện khớp đơn giản; nếu discount_id ở bảng discounts và stage_discounts khớp, và giá trị percent_off khác nhau, bản ghi hiện có trong bảng discounts sẽ được cập nhật. Giá trị percent_off hiện tại sẽ chuyển sang trường previous_percent_off, và nếu discount_id ở hai bảng không khớp, sẽ chèn bản ghi mới với giá trị NULL. Lưu ý rằng các bản ghi này không bị ràng buộc theo thời gian, và chỉ có thể duy trì một giá trị lịch sử cho percent_off.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Hãy nhớ, SCD loại 3 phù hợp nhất với dữ liệu hiếm khi thay đổi, và chỉ duy trì bản ghi lịch sử gần nhất. Nếu kỳ vọng có nhiều thay đổi đối với dimension, có lẽ tốt hơn nên dùng SCD loại 2.
Khi triển khai bất kỳ kỹ thuật nào cho slowly changing dimensions, điều quan trọng là lưu ý khả năng dữ liệu trùng lặp. Có hai loại trùng lặp cần chú ý: trùng liên lô (intra-batch) và trùng trong cùng lô (inter-batch). Hãy cùng phân tích.
Trùng liên lô là các bản ghi trùng tồn tại giữa các lô dữ liệu khác nhau. Nếu có một bảng dimension hiện có, hai tệp dùng để cập nhật bảng này có thể chứa bản ghi trùng.
Để xử lý, cần thêm các ràng buộc vào logic “upsert” và/hoặc nạp dữ liệu vào bảng dimension. Trong các ví dụ trên, chúng ta đã thêm logic xuyên suốt để đảm bảo không có trùng lặp. Bao gồm:
employee_id khớppercent_off có khác nhau giữa bảng items và stage_items trước khi cập nhật bản ghi hiện cóTrùng trong cùng lô là trùng lặp xảy ra trong cùng một lô dữ liệu. Ví dụ, nếu một tệp chứa hai mục để cập nhật một bản ghi trong bảng dimension, cần có biện pháp phòng ngừa. Giống như trùng liên lô, cần thêm ràng buộc vào logic dùng để triển khai SCD loại 1, 2 hoặc 3.
Nếu có bản ghi xung đột trong cùng một tệp, các bản ghi này sẽ phải được phân biệt theo cách nào đó. Có thể là metadata về bản ghi hoặc timestamp do nguồn cung cấp. Dù chọn cách nào để xử lý các trùng lặp này, điều quan trọng là ghi lại giả định của bạn và xem xét với nhóm để đảm bảo các dimension kết quả phản ánh đúng giá trị vận hành.
Đôi khi dữ liệu thay đổi khi không nên. Với ba kỹ thuật SCD đã bàn, điều này có thể dẫn đến dữ liệu bị ghi đè, thêm dòng mới, hoặc dữ liệu được điền vào cột mới.
Chúng ta đã bàn cách đảm bảo dữ liệu trùng không len vào các bảng dimension. Ngoài dữ liệu trùng, người triển khai kỹ thuật xử lý slowly changing dimensions cũng cần chú ý những điều sau:
Dù không phải mọi trường hợp trên đều có thể bắt trực tiếp trong mã dùng để duy trì bảng dimension, việc có các quy tắc chất lượng dữ liệu mạnh và quy trình giám sát dimension có thể giúp đảm bảo tính toàn vẹn dữ liệu.
Trong ví dụ bán lẻ ở trên, các tập dữ liệu ta làm việc chỉ gồm vài dòng. Trong môi trường sản xuất, các bảng dimension này có thể chứa hàng trăm hoặc thậm chí hàng nghìn bản ghi. Điều này khá thường gặp khi triển khai SCD loại 2, đặc biệt nếu dimension thay đổi thường xuyên.
Khi số dòng trong bảng dimension tăng, người làm dữ liệu cần đặt hiệu năng lên hàng đầu trong kế hoạch thiết kế và triển khai. Dưới đây là vài cách tối ưu triển khai SCD cho tập dữ liệu lớn bằng Snowflake:
MERGEUPDATE và INSERT khi phù hợp thay vì MERGENếu một tập dimension trở nên quá lớn đến mức hiệu năng hệ thống bị ảnh hưởng, có thể cần quyết định đánh đổi giữa độ chính xác lịch sử và hiệu năng. Như đã đề cập, điều này thường xảy ra khi triển khai SCD loại 2.
Nếu bản ghi thay đổi thường xuyên, số dòng trong bảng có thể phình to nhanh chóng. Khi đó, có thể không còn hợp lý để dùng SCD loại 2 để duy trì dữ liệu dimension.
Chuyển sang dùng SCD loại 1 hoặc loại 3 có thể mang lại chức năng tương tự, với cải thiện đáng kể về hiệu năng hệ thống. Sự đánh đổi là biểu diễn dữ liệu lịch sử không đầy đủ. Hãy làm việc với nhóm của bạn để cân nhắc đánh đổi này trước khi thay đổi cách tiếp cận triển khai SCD.
Chạy một truy vấn một lần để triển khai SCD cho bảng dimension là khá đơn giản. Tuy nhiên, chạy chương trình hóa quy trình này để duy trì dimension trong môi trường sản xuất cần suy nghĩ thêm. Các công cụ như Apache Airflow rất phù hợp để điều phối các quy trình này và cung cấp lớp giám sát, cảnh báo để đảm bảo hiệu năng danh định. Bằng cách tham số hóa logic cập nhật bảng dimension, Airflow có thể được dùng để kích hoạt các quy trình trong nền tảng dữ liệu của bạn theo lịch định kỳ, thay thế cho nỗ lực thủ công của người làm dữ liệu
Ngoài Airflow, các công cụ như Mage, Prefect hoặc Dagster cũng có thể dùng để điều phối việc triển khai slowly changing dimensions. Nếu các công cụ như vậy không sẵn có, các công cụ điều phối tự xây dựng cũng có thể đáp ứng.
Làm chủ slowly changing dimensions (SCD) là một kỹ năng tuyệt vời để có trong bộ công cụ của bạn, đặc biệt khi bạn tự tạo mô hình dữ liệu.
Trong bài viết này, chúng ta đã đề cập những điều cơ bản về mô hình sao, cũng như định nghĩa và kiến thức nền tảng của SCD. Chúng ta đã khám phá SCD loại 1, 2 và 3 để duy trì dữ liệu lịch sử đồng thời ghi nhận ảnh chụp trạng thái hiện tại.
Với sự hỗ trợ của Snowflake, chúng ta đã triển khai từng kỹ thuật SCD nói trên bằng ví dụ bán lẻ. Sau đó, chúng ta phác thảo một số thách thức kỹ thuật khi triển khai SCD và cách giải quyết.
Để tiếp tục phát triển kỹ năng mô hình dữ liệu, hãy học các khóa Database Design, Introduction to Data Engineering và Introduction to Data Warehousing trên DataCamp. Chúc bạn may mắn và code vui vẻ!
Bắt đầu hành trình dữ liệu của bạn ngay hôm nay!
Courses
Courses
Courses