
Kurs
Data Engineering'e Giriş
4 sa
127.6K
Yavaş değişen boyutları ele almanın birden çok yolu vardır. En yaygın üç yönteme göz atalım.
SCD tip 1 kullanıldığında, bir boyut tablosundaki bir kayıt değişirse mevcut kayıt güncellenir veya üzerine yazılır. Aksi takdirde yeni kayıt boyut tablosuna eklenir. Bu, boyut tablosundaki kayıtların her zaman mevcut durumu yansıttığı ve geçmiş verilerin tutulmadığı anlamına gelir.
Bir markette satılan ürünlere ilişkin bilgileri depolayan bir tablo, değişen kayıtları SCD tip 1 kullanarak ele alabilir. İlgili ürün için tabloda zaten bir kayıt varsa yeni bilgilerle güncellenir. Aksi halde kayıt boyut tablosuna eklenir.
Veri mühendisliği dünyasında, verinin varsa güncellenmesi yoksa eklenmesi uygulamasına “upsert” denir. Aşağıdaki tablo, bir markette satılan ürünlere ilişkin bilgileri içerir.
|
item_id |
name |
price |
aisle |
|
93201 |
Patates Cipsi |
3.99 |
11 |
|
07879 |
Kola |
7.99 |
13 |
Patates Cipsi 6. koridora taşınırsa, bu değişikliği boyut tablosunda SCD tip 1 ile yakalamak aşağıdaki sonucu verir:
|
item_id |
name |
price |
aisle |
|
93201 |
Patates Cipsi |
3.99 |
6 |
|
07879 |
Kola |
7.99 |
13 |
SCD tip 1, tabloda yinelenen kayıtların olmamasını ve verilerin en güncel boyutu yansıtmasını sağlar. Bu, yalnızca mevcut durumun ilgi çektiği gerçek zamanlı panolar ve öngörüsel modelleme için özellikle kullanışlıdır.
Ancak tabloda yalnızca en son bilgiler tutulduğu için, veri uzmanları boyutlardaki değişiklikleri zaman içinde karşılaştıramaz. Örneğin, bir veri analisti, Patates Cipsi 6. koridora taşındıktan sonra gelirdeki artışı başka bilgiler olmadan tespit etmekte zorlanır.
SCD tip 1, mevcut duruma ilişkin raporlama ve analitiği kolaylaştırır ancak tarihsel analizlerde sınırlamalara sahiptir.
Yalnızca mevcut durumu yansıtan bir tablo yararlı olabilir; ancak bazen bir boyuttaki tarihsel değişiklikleri izlemek uygun, hatta zorunludur. SCD tip 2 ile, bir boyut değiştiğinde yeni bir satır eklenerek geçmiş veriler korunur; bu yeni satır doğru şekilde güncel olarak işaretlenirken, artık tarihsel olan kayıt da uygun biçimde gösterilir.
Söylemesi kolay; ancak bunun pratikte nasıl göründüğü hemen net olmayabilir. Bir örneğe bakalım.
Burada, SCD tip 1’i incelerken kullandığımız örneğe oldukça benzer bir tablo var. Ancak ek bir sütun eklendi. is_current boole bir değer tutar; kayıt en güncel değeri yansıtıyorsa true, aksi halde false.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Patates Cipsi |
3.99 |
11 |
True |
|
07879 |
Kola |
7.99 |
13 |
True |
Patates Cipsi 6. koridora taşınırsa, bu değişikliği belgelemek için SCD tip 2 kullanmak şöyle bir tablo oluşturur:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Patates Cipsi |
3.99 |
11 |
False |
|
07879 |
Kola |
7.99 |
13 |
True |
|
93201 |
Patates Cipsi |
3.99 |
6 |
True |
Patates Cipsi için konum değişikliğini yansıtmak üzere yeni bir satır eklenir ve is_current sütununa True yazılır. Geçmiş verileri korumak ve mevcut durumu doğru şekilde göstermek için önceki kaydın is_current değeri False olarak ayarlanır. SCD tip 1 ile,
Peki Patates Cipsi satışlarının konum değişikliğine nasıl tepki verdiğini incelemek isterseniz? Tek bir sütun kullanırken, bir ürün için birden fazla tarihsel kayıt varsa bu oldukça zordur. Neyse ki bunun kolay bir yolu var.
Aşağıdaki tabloya bakın. Bu boyut tablosu, öncekiyle aynı bilgileri içeriyor; ancak bir is_current sütunu yerine hem start_date hem de end_date sütunlarına sahip. Bu tarihler, bir boyutun en güncel olduğu dönemi temsil eder. Bu tablodaki veriler en güncel olduğundan, end_date gelecekte bir tarihe ayarlanmıştır.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Patates Cipsi |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Kola |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Patates Cipsi 4 Ocak 2024’te 6. koridora taşındıysa, güncellenmiş tablo şöyle görünür:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Patates Cipsi |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Kola |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Patates Cipsi |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
İlk satırdaki end_date’in, Patates Cipsi’nin 11. koridorda mevcut olduğu son güne güncellendiğine dikkat edin. Yeni bir kayıt eklendi ve Patates Cipsi artık 6. koridorda raflarda yer alıyor. start_date ve end_date, değişikliğin ne zaman yapıldığını gösterir ve hangi kaydın güncel olduğunu belirtir.
Bu tekniği kullanarak SCD tip 1 uygulamak, yalnızca geçmiş verileri korumakla kalmaz, aynı zamanda verilerin ne zaman değiştiğine dair bilgi de sunar. Bu, veri analistlerinin ve veri bilimcilerinin operasyonel değişiklikleri keşfetmesini, A/B testleri yapmasını ve bilgiye dayalı kararlar almasını sağlar.
Verilerin yalnızca bir kez değişmesinin beklendiği durumlarda veya yalnızca en güncel tarihsel kaydın ilgi çektiği hallerde SCD tip 3 oldukça kullanışlıdır. Değiştirilen bir boyutu “upsert” etmek veya değişikliği yeni bir satır olarak saklamak yerine, SCD tip 3 değişikliği temsil etmek için bir sütun kullanır. Bunu açıklamak biraz zor; o yüzden doğrudan bir örneğe geçelim.
Aşağıdaki tablo, Amerika Birleşik Devletleri genelindeki takımların sporlarına ilişkin bilgileri içerir. Burada tablo, güncel ve eski stadyum adını saklamak için iki sütun içeriyor. Bu takımların her biri orijinal stadyum adını kullandığı için previous_stadium_name sütunu NULL değerlerle doldurulmuştur.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Futbol |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Futbol |
Musket Stadium |
NULL |
Lafayette Hawks yirmi beş yıllık bir anlaşma için yeni bir sponsorla anlaşmaya karar verirse, güncellenmiş tablo şöyle görünür:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Futbol |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Futbol |
Musket Stadium |
NULL |
Yeni stadyum adını hesaba katmak için “Triple X Stadium" previous_stadium_name sütununa taşınır ve “Wabash Field" current_stadium_name sütununda yerini alır. Yirmi beş yıllık yeni sponsorluk anlaşması, oluşturulan modelin ömrünü büyük olasılıkla aşacağından, kaydın tekrar değişmesi beklenmez.
SCD tip 3 kullanmak, mevcut durum verilerini tarihsel verilerle karşılaştırmayı oldukça kolaylaştırır. Her takım için yalnızca tek bir satır vardır ve güncel ve tarihsel veriler yan yana iki farklı sütunda durur. Ancak bu, tek bir boyutsal öznitelik için yalnızca tek bir tarihsel kaydın tutulabileceği anlamına gelir; bu da özellikle veriler beklenenden daha sık değişiyorsa sınırlayıcı olabilir.
1, 2 ve 3. tiplere ek olarak yavaş değişen boyutları uygulamak için başka teknikler de vardır. Tip 0, boyutların asla değişmemesi gerektiğinde kullanılır. Tip 4, en güncel veriyi bir boyut tablosunda tutarken geçmiş verileri ayrı bir tabloda saklar. Tip 6 ise 1, 2 ve 3. tiplerin bir sentezidir ve genellikle bu tekniklerin en iyi özelliklerinin birleştirilmesiyle uygulanır.
Yavaş değişen boyutların temelini ele aldık. Her bir tekniğin nasıl uygulanacağını daha iyi anlamak için bir örneğe bakalım.
Bu örnekte, perakende işlemleri için SCD tip 1, 2 ve 3’ü uygulamak üzere Snowflake kullanacağız. Snowflake’e kısa bir hatırlatmaya ihtiyaç duyarsanız Introduction to Snowflake kursumuza göz atın.
Bir adet sales adlı olgu tablosu ve employees, items ve discounts adlarında üç boyut tablosu vardır. Aşağıda bu yıldız şeması için ERD yer almaktadır.
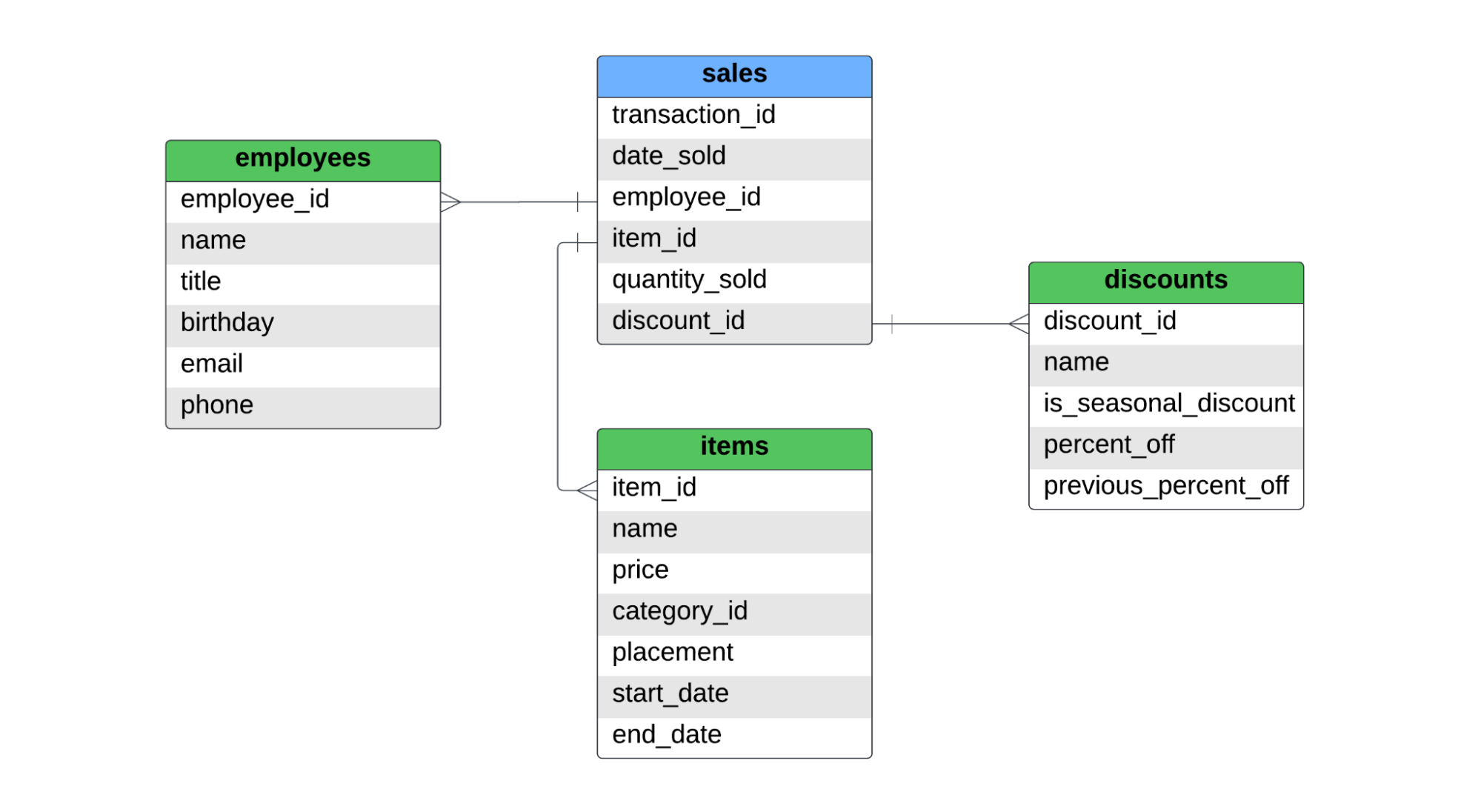
sales tablosu, ürün düzeyinde satışları yakalar. Bir müşteri iki gömlek ve bir kot pantolon aldıysa, iki farklı ürün satıldığından olgu tablosunda iki kayıt bulunur. SCD tip 1, tip 2 ve tip 3 için aşağıdakileri ele alacağız:
Bu tabloların başlangıçta nasıl doldurulduğunu incelemeyeceğiz; ancak genellikle veri ambarının yukarısında, ham verileri kaynaktan alan, istenen modele dönüştüren ve nihai hedefe yükleyen bir ETL veya ELT hattı bulunur.
SCD tip 1 uygulamasını pratik etmek için employee tablosuna bakacağız. Bu tablo, bir çalışanın adı, unvanı ve iletişim bilgileri dahil olmak üzere temel bilgilerini içerir. Aşağıdakilere benzer kayıtlar içerebilir.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Müdür |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Kasiyer |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Bu yavaş değişen boyutu SCD tip 1 ile yakalamak için mevcut kayıt en güncel kayıtla üzerine yazılır. Bu boyutsal özniteliklerden biri değişirse, yeni kayıt mevcut tabloya “upsert” edilmelidir. Örneğin, Emily’nin telefon numarası 928-652-9704 olarak değişirse yeni tablo şöyle görünür:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Müdür |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Kasiyer |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Bunu Snowflake ile yapmak için MERGE INTO komutunu kullanacağız. MERGE INTO, bir eşleştirme anahtarı ve bir koşul belirtmeye olanak tanır. Eşleştirme anahtarı ve koşul sağlanırsa kayıt UPDATE anahtar sözcüğüyle güncellenebilir. Aksi takdirde bir kayıt INSERT edilebilir veya yürütme sonlandırılabilir.
MERGE INTO komutuna başlamadan önce, stage_employees adlı bir tablo oluşturup kayıtlara ekleme yapacağız. Bu, employees tablosu son kez yenilendiğinden beri güncellenen tüm kayıtları içerecek. Aşağıdaki ifadelerle bunu yapabiliriz.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Şimdi, mevcut kaydı “upsert” etmek için Snowflake’in MERGE işlevini kullanabiliriz.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Yukarıda, employees ile stage_employees tabloları arasındaki veriyi birleştirmek için anahtar employee_id alanıdır. Başka bir koşul belirlenmedi; yani employee_id eşleşirse, söz konusu çalışan kimliği için name, title, email ve phone boyutsal öznitelikleri stage_employees tablosundaki değerlerle güncellenir. stage_employees kayıtları employees tablosundakilerle eşleşmezse, kayıt employees tablosuna eklenir.
SCD tip 2’yi uygulamak, SCD tip 1’den biraz daha zordur. Mevcut bir kaydın üzerine yazmak veya aksi halde bir kayıt eklemek kadar basit olmasa da, bu sorunu ele almak için yine Snowflake’in MERGE INTO mantığını kullanabiliriz. Aşağıdaki boyuta bakın.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Çorap |
8.99 |
156 |
Koridor 11 |
2023-08-24 |
NULL |
|
747295 |
Spor Forması |
59.99 |
743 |
Koridor 8 |
2023-02-17 |
NULL |
Bu tablo, bir perakende mağazasında satılan belirli ürünlere ilişkin bilgileri içerir. Boyutsal öznitelikler; ürünün adı, fiyatı ve konumu ile ürünün ait olduğu kategorinin yabancı anahtarını kapsar. SCD tip 2’yi uygulamak için veriyi bu kez hem tarihsel hem güncel verileri korumak üzere start_date ve end_date kullanarak “upsert” etmemiz gerekir.
NFL (National Football League) sezonunun başında, spor formalarının, müşteri içeri girdiğinde daha iyi görünürlük için mağazanın girişine taşındığını varsayalım. Yeni bir konumla birlikte bu ürünün fiyatı da düşürüldü. Bu operasyonel davranışı göstermek ve tarihsel verileri korumak için mevcut kayıt bir bitiş tarihiyle güncellenir ve yeni bir kayıt eklenir. İşte şöyle!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Çorap |
8.99 |
156 |
Koridor 11 |
2023-08-24 |
NULL |
|
747295 |
Spor Forması |
59.99 |
743 |
Koridor 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Spor Forması |
49.99 |
743 |
Giriş Sergisi |
2023-11-13 |
NULL |
Önceki gibi, önce stage_items adlı bir tablo oluşturacağız. Bu tablo, yukarıda gösterildiği biçimi alan ilgili items boyutunda SCD tip 2 uygulanacak kayıtları tutacaktır. stage_items tablosu oluşturulduktan sonra, spor formaları için hem konum hem de fiyat değişikliğini içeren bir kayıt ekleyeceğiz.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Şimdi, SCD tip 2’yi uygulamak için Snowflake’in MERGE INTO işlevini kullanma zamanı. Bu, önceki örnekten biraz daha zor ve biraz düşünmeyi gerektiriyor. Bir kayıt yalnızca eşleşme koşulu SAĞLANMAZSA eklenebildiğinden, bunu iki adımda yapacağız. Önce aşağıdaki üç ifadeyle bir eşleşme koşulu oluşturacağız:
items ve stage_items tablolarındaki item_id değerleri eşleşmelidirstage_items tablosundaki start_date, items tablosundakinden büyük olmalıdıritems tablosundaki end_date NULL olmalıdırBu üç koşul sağlanırsa, items tablosundaki orijinal kayıt güncellenmelidir. items.end_date sütununun artık NULL olmayacağına; stage_items tablosundaki start_date değerini alacağına dikkat edin. Bu ilk ifadede eşleşmeyen kayıtlar için bir mantık yoktur.
Ardından, yeni kaydı eklemek için ayrı bir MERGE INTO çağrısı kullanacağız. Bu biraz daha zor. Yeni bir kaydın eklenebilmesi için eşleşme koşulunun sağlanmaması gerekir.
Bu örnekte, iki tablodaki items_id değerlerinin eşleşip eşleşmediğini ve items tablosundaki end_date değerinin NULL olup olmadığını kontrol ederek bunu yapabiliriz. Biraz daha açalım.
items_id değerleri eşleşiyorsa ve items.end_date NULL ise, items tablosunda zaten en güncel olan bir kayıt vardır. Bu durumda yeni bir kayıt eklenmemelidir.item_id değerleri arasında eşleşme yoksa, eşleşme koşulu sağlanmaz ve yeni bir satır eklenir. Bu, items tablosundaki o item_id için ilk kayıt olacaktır.stage_items tablosundaki item_id, items tablosundaki aynı item_id ile eşleşiyor ve end_date NULL değilse, yeni bir değer eklenir. Bu, geçmiş verileri korur ve items tablosunda güncel bir kaydın bulunmasını sağlar.Aşağıda, önce mevcut kaydı güncellemek, ardından en güncel veriyi eklemek için iki MERGE INTO ifadesi kullanılarak yapılan uygulama yer almaktadır.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Son olarak, yeni bir boyutla SCD tip 3’ün uygulanmasına bakacağız. Örneğimizde discounts tablosu, müşterilerin kasada kullanabilecekleri belirli indirimlere ilişkin bilgileri saklar. Tablo, indirimin kimliğini, adını, indirim yüzdesini ve mevsimsel indirim sınıflandırmasını içerir. İşte discounts tablosunda bulunabilecek iki kayda örnek.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Ödül Üyesi |
False |
10 |
NULL |
|
467782 |
Çalışan İndirimi |
False |
50 |
NULL |
Perakendeci indirimlerin sık değişmesini beklemediği için, bu boyut yavaş değişen boyutlara tip 3 yaklaşımını uygulamak için harika bir adaydır. İndirimle sunulan yüzdelik oran değişirse, önceki oran previous_percent_off sütununa taşınır; yeni değer ise percent_off sütununda yerini alır.
Bu, percent_off sütununda en güncel değeri sunarken tarihsel verilerin korunmasını sağlar.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Ödül Üyesi |
False |
10 |
NULL |
|
467782 |
Çalışan İndirimi |
False |
35 |
50 |
Bunu Snowflake ile uygulamak için bir stage_discounts tablosu oluşturacak ve tek bir kayıt ekleyeceğiz. Bu kayıt yeni percent_off değerini içerecek.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Yine SCD tip 3’ü uygulamak için MERGE INTO kullanacağız. Eşleşme koşulu basittir; discounts ve stage_discounts tablosundaki discount_id değerleri eşleşir ve percent_off değerleri farklıysa, discounts tablosundaki mevcut kayıt güncellenir. Mevcut percent_off değeri previous_percent_off alanına taşınır; ardından iki tablodaki discount_id değerleri eşleşmezse, NULL değeriyle yeni bir kayıt eklenir. Bu kayıtların zamana bağlı olmadığını ve yalnızca percent_off için tek bir tarihsel değerin korunabileceğini unutmayın.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Unutmayın, SCD tip 3 en iyi, verilerin nadiren değiştiği ve yalnızca en güncel tarihsel girdinin korunacağı durumlarda uygulanır. Boyutun birden fazla kez değişmesi bekleniyorsa muhtemelen SCD tip 2’yi kullanmak en iyisidir.
Yavaş değişen boyutlar için herhangi bir teknik uygulanırken, yinelenen veri olasılığını akılda tutmak önemlidir. Dikkat edilmesi gereken iki tür yinelenen kayıt vardır: toplamalar arası ve toplama içi kopyalar. Bunu açalım.
Toplamalar arası kopyalar, farklı veri partileri arasında var olan yinelenen kayıtlardır. Mevcut bir boyut tablosu varsa, bu tabloyu güncellemek için kullanılan iki dosya yinelenen kayıtlar içerebilir.
Bunu ele almak için, veriyi bir boyut tablosuna “upsert” eden ve/veya yükleyen mantığınıza kısıtlar eklemek önemlidir. Yukarıdaki örneklerde, yinelenen kayıtların olmamasını sağlamak için çeşitli yerlerde mantık ekledik. Bunlar şunları içeriyordu:
employee_id olan kayıt yoksa SCD tip 1 kullanırken veriyi yalnızca eklemeitems ve stage_items tablolarındaki percent_off değerlerinin farklı olup olmadığını kontrol etmeToplama içi kopyalar, aynı veri partisinde meydana gelen yinelenen kayıtlardır. Örneğin, bir dosya bir boyut tablosundaki tek bir kaydı güncellemek için iki giriş içeriyorsa önlem alınmalıdır. Toplamalar arası kopyalarda olduğu gibi, SCD tip 1, 2 veya 3’ü uygulamak için kullanılan mantığa kısıtlar eklemek önemlidir.
Aynı dosyada çelişen kayıtlar varsa, bu kayıtların bir şekilde ayırt edilmesi gerekir. Bu, kayıtla ilgili üstveri veya kaynak tarafından sağlanan bir zaman damgası olabilir. Hangi yolu seçerseniz seçin, bu kopyaları nasıl ele aldığınızı belgelemeniz ve sonuçtaki boyutların operasyonel değerleri doğru şekilde yakaladığından emin olmak için ekibinizle gözden geçirmeniz önemlidir.
Bazen veriler değişmemesi gerektiğinde değişir. Şimdiye kadar tartıştığımız üç SCD tekniğinde bu, verinin üzerine yazılmasına, yeni bir satır eklenmesine veya verinin yeni bir sütunda doldurulmasına yol açabilir.
Yinelenen verilerin boyut tablolarına sızmamasını sağlamanın yollarını ele aldık. Yinelenen verilere ek olarak, yavaş değişen boyutları ele almak için teknikleri uygulayan veri uzmanları aşağıdakilere dikkat etmek isteyecektir:
Yukarıdaki durumların tümü, doğrudan boyut tablolarını korumak için kullanılan kodda yakalanamayabilir; ancak güçlü veri kalitesi kuralları ve boyutları izleme süreçlerine sahip olmak, veri bütünlüğünün korunmasına yardımcı olabilir.
Yukarıdaki perakende örneğinde, üzerinde çalıştığımız veri kümeleri yalnızca birkaç satırdan oluşuyordu. Üretim ortamında bu boyut tabloları yüzlerce hatta binlerce kayıt içerebilir. Bu, özellikle boyutlar sık değişiyorsa, SCD tip 2 uygulanırken oldukça yaygındır.
Bir boyut tablosundaki satır sayısı arttıkça, performansı tasarım ve uygulama planlarının ön saflarında tutmak veri uzmanları için önem kazanır. Snowflake kullanarak büyük veri kümeleri için SCD uygulamasını optimize etmenin birkaç yolu şunlardır:
MERGE ifadesi(leri)nin işleyeceği veriyi azaltmak için mikro-bölümlendirme ve veri kümeleme avantajlarından yararlanınMERGE yerine uygun olduğunda UPDATE ve INSERT ifadelerini kullanmayı düşününBir boyut veri kümesi o kadar büyüyebilir ki sistem performansı tehlikeye girer; bu durumda tarihsel doğruluk ile sistem performansı arasında bir ödünleşim kararı gerekebilir. Yukarıda belirtildiği gibi bu genellikle SCD tip 2 uygulanırken söz konusudur.
Kayıtlar sık değişiyorsa tablodaki satır sayısı hızla şişebilir. Böyle bir durumda, boyutsal verileri korumak için SCD tip 2’yi kullanmak artık akıllıca olmayabilir.
SCD tip 1 veya tip 3’e geçmek, benzer işlevselliği sistem performansında önemli kazanımlarla sunabilir. Ödünleşim, tarihsel verilerin eksik temsili olacaktır. SCD uygulama yaklaşımını değiştirmeden önce bu ödünleşimi ekibinizle değerlendirin.
Bir boyut tablosu için SCD’yi uygulamak üzere tek seferlik bir sorgu çalıştırmak yeterince kolaydır. Ancak bu süreci üretim ortamında bu boyutu sürdürmek üzere programatik olarak çalıştırmak biraz düşünmeyi gerektirir. Apache Airflow gibi araçlar bu süreçleri orkestre etmek için harikadır ve nominal performansı sağlamak üzere bir izleme ve uyarı katmanı sunar. Boyut tablolarını güncellemek için kullanılan mantığı parametreleştirerek Airflow, veri platformunuzda planlanmış aralıklarla süreçleri tetiklemek için kullanılabilir ve veri uzmanının manuel çabasının yerini alır
Airflow’a ek olarak Mage, Prefect veya Dagster gibi araçlar da yavaş değişen boyutların uygulanmasını orkestre etmek için kullanılabilir. Bu tür araçlar hazırda yoksa, kurum içi orkestrasyon araçları da iş görebilir.
Yavaş değişen boyutlarda (SCD) ustalaşmak, özellikle kendi veri modelinizi oluştururken, araç kutunuzda bulunması harika bir beceridir.
Bu yazıda yıldız şemalarının temellerini ve SCD’nin tanımını ve temel noktalarını ele aldık. Mevcut durumun anlık görüntüsünü yakalarken tarihsel verileri korumak için SCD tip 1, 2 ve 3’ü inceledik.
Snowflake’in yardımıyla, perakende örneğinden yararlanarak yukarıda tanımlanan her bir SCD tekniğini uyguladık. Ardından, SCD uygulamanın getirebileceği daha teknik zorluklardan bazılarını ve bunların nasıl ele alınacağını özetledik.
Veri modelleme becerilerinizi geliştirmeye devam etmek için DataCamp üzerinden sunulan Database Design, Introduction to Data Engineering ve Introduction to Data Warehousing kurslarını alın. Bol şans ve keyifli kodlamalar!
Veri Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
