
Program
Dasar-Dasar Agen Kecerdasan Buatan
6 Hr
GLM 5.1 adalah salah satu model open terkuat yang bisa Anda jalankan saat ini, dan Artificial Analysis saat ini menggambarkannya sebagai model open-weights terdepan di Intelligence Index mereka. Z.ai juga memposisikannya sebagai rilis andalan untuk pengkodean, penalaran, dan alur kerja agentic.
Sumber: AI Model & API Providers Analysis | Artificial Analysis
Menjalankannya secara lokal memberi Anda lebih banyak kontrol atas keseluruhan alur kerja. Data Anda tetap berada di lingkungan Anda sendiri, dan Anda dapat menguji prompt, membangun integrasi, serta menggunakannya dalam proyek pengkodean dengan privasi lebih baik dan kekhawatiran lebih kecil terhadap paparan data eksternal.
Dalam tutorial ini, Anda akan menyiapkan lingkungan RunPod H100, menjalankan GLM 5.1 secara lokal, mengujinya dengan panggilan API, menghubungkannya ke OpenAI Python SDK, mengaksesnya melalui WebUI, dan mengintegrasikannya dengan Claude Code.
Mulailah dengan membuka tab Pods di RunPod dan memilih mesin H100 SXM. Untuk templatenya, pilih opsi PyTorch terbaru agar Anda memiliki lingkungan siap pakai untuk menjalankan beban kerja model.
Sebelum melakukan deploy, perbarui pengaturan penyimpanan pod. Atur container disk ke 100GB dan volume disk ke 300GB agar tersedia ruang yang cukup untuk file model, dependensi, dan unduhan cache.
Kita akan mengerjakan semuanya di dalam direktori terpasang /workspace agar semuanya tetap di satu tempat. Anda juga harus mengekspos port 8910, yang akan kita gunakan untuk server model lokal dan llama.cpp WebUI.
Selanjutnya, tambahkan token Hugging Face Anda sebagai variabel lingkungan bernama HF_TOKEN.
Setelah itu, tinjau ringkasan pod dan klik Deploy On-Demand. Setelah pod berjalan, buka instance JupyterLab yang terlampir.
Di dalam JupyterLab, luncurkan terminal baru dan jalankan perintah berikut untuk memasang paket sistem yang diperlukan:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Sekarang pod sudah siap, langkah berikutnya adalah membangun llama.cpp dengan dukungan CUDA agar dapat menggunakan GPU H100 untuk inferensi lokal.
Pertama, klon repositori llama.cpp dari GitHub:
git clone https://github.com/ggml-org/llama.cppSelanjutnya, konfigurasikan build dan tempatkan file build yang dihasilkan di folder build terpisah:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Setelah itu, kompilasi biner utama yang kita butuhkan dalam mode Release yang dioptimalkan:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Terakhir, salin biner yang sudah dikompilasi ke folder utama llama.cpp agar lebih mudah dijalankan nanti:
cp llama.cpp/build/bin/llama-* llama.cppDi akhir langkah ini, Anda akan memiliki alat utama llama.cpp siap digunakan, termasuk llama-server, yang akan kita gunakan nanti untuk menjalankan GLM 5.1 secara lokal.
Sebelum mengunduh model, ada baiknya memahami mengapa kita menggunakan versi 2-bit untuk setup ini.
Model GLM 5.1 penuh memiliki 744B parameter, dengan 40B parameter aktif, context window 200K, dan membutuhkan sekitar 1,65TB ruang disk. Itu terlalu besar untuk setup lokal yang praktis.
Versi Unsloth Dynamic 2-bit GGUF mengurangi ukurannya menjadi sekitar 220–236GB, memangkas kebutuhan penyimpanan sekitar 80% sekaligus mempertahankan lapisan penting pada presisi lebih tinggi untuk kinerja yang lebih baik.
Itulah sebabnya model 2-bit adalah pilihan yang tepat untuk perangkat keras kita. Dengan VRAM 80GB dan RAM 125GB, versi terkuantisasi ini tetap membutuhkan banyak sumber daya tetapi jauh lebih realistis untuk dijalankan secara lokal sambil tetap memberikan kinerja kuat untuk pengkodean dan alur kerja agentic.
Sekarang, mari kita pasang alat yang diperlukan untuk mengunduh file model secara efisien.
Pertama, pasang paket Hugging Face Hub dengan dukungan hf_xet, beserta pembantu hf-xet:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetSelanjutnya, pasang hf_transfer untuk mempercepat unduhan model berukuran besar:
pip -q install -U hf_transferSetelah itu, aktifkan transfer berperforma tinggi untuk unduhan lebih cepat:
export HF_XET_HIGH_PERFORMANCE=1Terakhir, unduh file model GLM 5.1 ke folder lokal:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Bahkan versi yang lebih kecil ini tetap merupakan unduhan besar. Di setup saya, model 2-bit memakan waktu sekitar 17 menit untuk selesai, jadi jangan khawatir jika butuh sedikit waktu.

Sekarang saatnya meluncurkan server lokal dan memuat model ke dalam memori.
Jalankan perintah berikut:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfArgumen utama yang perlu diperhatikan di sini adalah --fit on. Ini memberi tahu server untuk secara otomatis menempatkan sebanyak mungkin bagian model ke GPU, sementara sisanya dibebankan ke RAM sistem. Itu sangat berguna dalam setup kita, karena membantu menjalankan model yang sangat besar di VRAM 80GB dan RAM 125GB tanpa harus mengatur penempatan lapisan secara manual.
Argumen lainnya sebagian besar menangani nama server, port, pengaturan kinerja, batching, dan panjang konteks untuk inferensi.
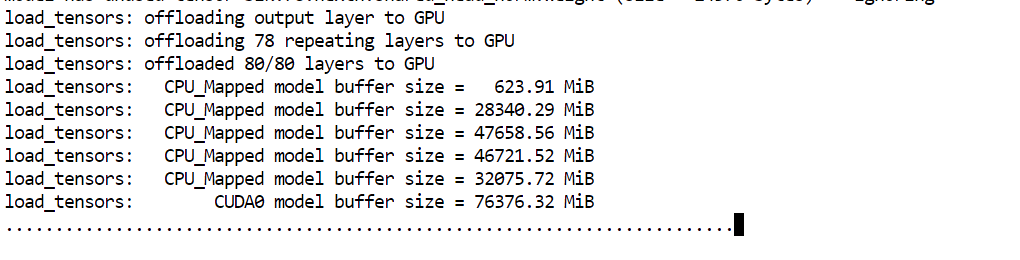
Setelah pemuatan model selesai, Anda akan melihat pesan yang menunjukkan server mendengarkan di: http://0.0.0.0:8910.

Pada titik itu, GLM 5.1 berjalan secara lokal dan siap diuji di langkah berikutnya.
Dengan server berjalan, langkah berikutnya adalah memastikan model merespons dengan benar melalui API lokalnya.
Buka terminal baru di dalam JupyterLab agar server tetap berjalan di terminal awal. Lalu kirim permintaan uji sederhana dengan curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Permintaan ini mengirim prompt ke server GLM 5.1 yang berjalan secara lokal dan memintanya menghasilkan respons singkat. Hal utama yang perlu diperhatikan di sini adalah URL server lokal, nama model, dan format messages yang digunakan di body permintaan.
Jika semuanya berfungsi dengan benar, terminal akan mengembalikan respons JSON yang berisi output model.

Sekarang API lokal sudah berfungsi, langkah berikutnya adalah menghubungkannya ke OpenAI Python SDK. Ini berguna karena banyak aplikasi dan skrip yang sudah ada menggunakan klien OpenAI, sehingga mengarahkannya ke server GLM 5.1 lokal Anda membuat integrasi jadi lebih mudah.
Pertama, tingkatkan pip dan pasang paket OpenAI:
python -m pip install --upgrade pip
pip install openaiSelanjutnya, jalankan skrip Python singkat yang menghubungkan SDK ke server lokal Anda:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYIntinya di sini adalah kita tidak memanggil API cloud OpenAI. Sebaliknya, kita menggunakan SDK yang sama tetapi mengubah base_url agar mengarah ke server GLM 5.1 lokal yang berjalan pada port 8910.
Jika semuanya disetel dengan benar, keluarannya akan berupa:
CanberraServer llama.cpp terbaru juga menyertakan WebUI bawaan, artinya Anda bisa berinteraksi dengan model GLM 5.1 lokal Anda melalui antarmuka chat sederhana, tidak hanya menggunakan terminal atau panggilan API.
Untuk membukanya, kembali ke dasbor RunPod dan buka tab Connect untuk pod Anda. Karena port 8910 sudah diekspos, klik tautan HTTP Service untuk port tersebut. Ini akan membuka WebUI llama.cpp di tab browser baru.
Setelah halaman dimuat, Anda dapat mulai mengobrol langsung dengan model. Ketik prompt pertama Anda, dan respons akan muncul dalam beberapa detik. Di setup saya, model menghasilkan sekitar 8 token per detik, yang merupakan kecepatan solid untuk model sebesar ini.
Untuk uji cepat, coba minta untuk membuat aplikasi Hello World sederhana. Model ini menghasilkan contoh yang berfungsi dalam beberapa bahasa pemrograman populer.
Sekarang GLM 5.1 berjalan secara lokal, langkah berikutnya adalah menghubungkannya ke Claude Code. Ini adalah uji yang berguna karena GLM 5.1 diposisikan sebagai model pengkodean yang kuat, jadi menggunakannya di dalam alur kerja agen pengkodean memberikan gambaran yang lebih baik tentang performanya pada tugas pengembangan nyata.
Start dengan memasang Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Selanjutnya, tambahkan Claude Code ke PATH shell Anda agar perintah claude dapat dijalankan dari terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcSetelah itu, konfigurasikan Claude Code agar mengarah ke server GLM 5.1 lokal Anda alih-alih API Anthropic yang dihosting:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFLalu muat ulang konfigurasi shell Anda agar variabel lingkungan tersebut berlaku:
source ~/.bashrcSekarang, buat folder uji dan luncurkan Claude Code di dalamnya:
mkdir -p test-claude-local
cd test-claude-local
claudeSaat pertama kali Claude Code dimulai, mungkin Anda diminta menyelesaikan beberapa langkah setup, seperti memilih tema atau memercayai direktori kerja. Setelah selesai, Anda dapat mulai memberinya tugas.
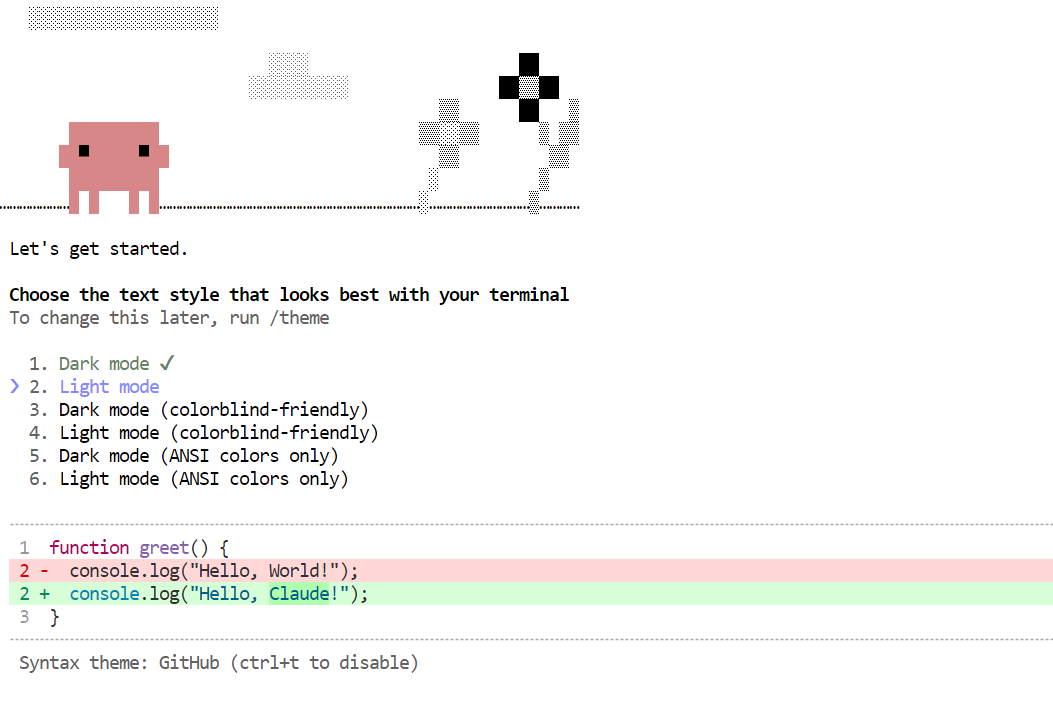
Untuk uji pertama yang sederhana, coba prompt ini:
Build the simple Hello World app in Python
Ini memungkinkan Anda memeriksa apakah Claude Code berhasil mengirim permintaan ke server GLM 5.1 lokal Anda dan menggunakannya untuk menghasilkan kode.
Berdasarkan pengalaman saya, setup ini berfungsi, tetapi terasa lebih lambat dibandingkan pengujian sebelumnya.
Dengan konteks lebih panjang dan prompt bergaya pengodean, kecepatan generasi turun menjadi sekitar 2 token per detik, dan model sering menghabiskan terlalu banyak waktu untuk bernalar sebelum menghasilkan jawaban sederhana.
Itulah salah satu trade-off utama yang saya perhatikan dengan GLM 5.1 dalam alur kerja ini: modelnya kapabel, tetapi bisa lebih lambat dan lebih verbose daripada yang Anda inginkan untuk tugas pengkodean yang ringan.
Bagian ini membahas beberapa masalah umum yang mungkin Anda temui saat menjalankan GLM 5.1 secara lokal dan cara cepat mengatasinya.
Biasanya ini berarti model terlalu besar untuk GPU dan memori sistem yang tersedia, jadi coba quant yang lebih kecil atau turunkan ukuran konteks. llama.cpp juga mendukung --fit on, yang membantu menyesuaikan model secara otomatis dengan memori yang tersedia.
Pastikan Anda membuka port yang diekspos dengan benar dari RunPod, bukan URL JupyterLab. Server llama.cpp menyertakan WebUI bawaannya sendiri, jadi port server itulah yang penting, dan URL harus mengarah ke 0.0.0.0:8910 pada layanan HTTP yang diekspos.
Ini biasanya merupakan ketidaksesuaian base URL atau endpoint. llama.cpp mendukung rute yang kompatibel dengan OpenAI dan rute yang kompatibel dengan Anthropic Messages, jadi periksa apakah alat Anda mengarah ke path yang benar, seperti /v1 atau /v1/messages.
Ini bisa terjadi karena performa bergantung pada perilaku klien dan model backend. Claude Code mendukung konfigurasi melalui pengaturan dan variabel lingkungan, tetapi respons yang lebih lambat sering disebabkan oleh model yang membutuhkan waktu lebih lama untuk bernalar atau menghasilkan keluaran.
Context window yang lebih panjang dan generasi yang lebih besar meningkatkan tekanan memori dan waktu respons. Mengurangi ukuran konteks, panjang prompt, atau pengaturan generasi dapat membantu meningkatkan kecepatan pada setup lokal.
Secara keseluruhan, menyiapkan GLM 5.1 secara lokal tergolong cukup mudah. Mengunduh model, menjalankan server, dan mengujinya untuk penggunaan dasar tidak membutuhkan banyak upaya. Untuk eksperimen lokal sederhana, prosesnya terasa sangat terkelola.
Tantangan utama mulai muncul saat Anda ingin menggunakannya untuk alur kerja agentic coding. Itu memerlukan lebih banyak RAM dan VRAM, dan kecepatan generasi token dapat melambat secara signifikan saat context window terisi. Meskipun model awalnya terasa cepat, mode thinking menambah banyak jeda, jadi untuk penggunaan lokal, sering kali lebih masuk akal untuk menonaktifkan mode thinking jika kecepatan penting.
Di luar performa, ada juga sisi praktis yang perlu dipertimbangkan. Menjalankan model lokal berarti Anda sendiri yang mengelola server model, menangani setup GPU, dan berurusan dengan isu infrastruktur. Ini juga menjadi lebih sulit ketika platform penyewaan GPU seperti RunPod atau Vast.ai memiliki ketersediaan terbatas, yang semakin umum karena meningkatnya permintaan.
Itu sebabnya, dalam banyak kasus, opsi API terkelola bisa menjadi pilihan yang lebih baik. Anda mungkin mengorbankan sebagian privasi dan kontrol, tetapi Anda mendapatkan kecepatan yang lebih baik, lebih sedikit perawatan, dan pengalaman yang jauh lebih mulus untuk tugas pengkodean yang lebih besar atau lebih kompleks. Jika biayanya hanya beberapa dolar per bulan, ini bisa menjadi pertukaran yang sepadan dibanding mengelola semuanya sendiri.
Jadi, jika tujuan Anda adalah bereksperimen, belajar, atau menjalankan GLM 5.1 untuk tugas lokal yang ringan, menjalankannya secara lokal adalah opsi yang baik. Namun jika tujuan Anda adalah agentic coding yang andal dalam skala besar, layanan terkelola sering kali lebih praktis. Untuk perbandingan terperinci, saya merekomendasikan membaca panduan GLM-5 vs GPT-5.3-Codex kami.
Kursus AI Agentic
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
