
Programma
Nozioni di base sugli agenti AI
6 h
GLM 5.1 è uno dei migliori modelli open che puoi eseguire oggi, e Artificial Analysis attualmente lo descrive come il modello open-weights leader nel suo Intelligence Index. Z.ai lo presenta anche come una release di punta per coding, reasoning e workflow agentici.
Fonte: AI Model & API Providers Analysis | Artificial Analysis
Eseguirlo in locale ti dà più controllo sull’intero workflow. I tuoi dati restano nel tuo ambiente, e puoi testare prompt, costruire integrazioni e usarlo in progetti di coding con maggiore privacy e minori preoccupazioni sull’esposizione esterna dei dati.
In questo tutorial imposterai un ambiente H100 su RunPod, eseguirai GLM 5.1 in locale, lo testerai con chiamate API, lo collegherai all’SDK Python di OpenAI, vi accederai tramite WebUI e lo integrerai con Claude Code.
Inizia andando alla scheda Pods in RunPod e selezionando una macchina H100 SXM. Per il template, scegli l’opzione PyTorch più recente, così avrai un ambiente pronto all’uso per eseguire i carichi di lavoro dei modelli.
Prima del deploy, aggiorna le impostazioni di storage del pod. Imposta il container disk a 100GB e il volume disk a 300GB così da avere spazio sufficiente per file del modello, dipendenze e download in cache.
Faremo tutto il lavoro all’interno della directory montata /workspace così tutto resta in un unico posto. Dovresti anche esporre la porta 8910, che useremo sia per il server del modello locale sia per la llama.cpp WebUI.
Poi, aggiungi il tuo token Hugging Face come variabile d’ambiente chiamata HF_TOKEN.
Una volta fatto, rivedi il riepilogo del pod e clicca su Deploy On-Demand. Dopo l’avvio del pod, apri l’istanza di JupyterLab collegata.
Dentro JupyterLab, avvia un nuovo terminale ed esegui i seguenti comandi per installare i pacchetti di sistema richiesti:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Ora che il pod è pronto, il passo successivo è compilare llama.cpp con supporto CUDA in modo che possa usare la GPU H100 per l’inferenza locale.
Per prima cosa, clona il repository di llama.cpp da GitHub:
git clone https://github.com/ggml-org/llama.cppQuindi configura la build e posiziona i file generati in una cartella build separata:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Dopodiché, compila i binari principali necessari in modalità Release ottimizzata:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Infine, copia i binari compilati nella cartella principale di llama.cpp così sarà più semplice eseguirli in seguito:
cp llama.cpp/build/bin/llama-* llama.cppAl termine di questo passaggio, avrai pronti gli strumenti principali di llama.cpp, incluso llama-server, che useremo più avanti per eseguire GLM 5.1 in locale.
Prima di scaricare il modello, è utile capire perché per questa configurazione usiamo la versione a 2 bit.
Il modello GLM 5.1 completo ha 744B parametri, con 40B parametri attivi, una finestra di contesto da 200K e richiede circa 1,65TB di spazio su disco. È troppo grande per un setup locale pratico.
La versione Unsloth Dynamic 2-bit GGUF riduce la dimensione a circa 220–236GB, tagliando il fabbisogno di storage di circa l’80% pur mantenendo layer importanti ad alta precisione per prestazioni migliori.
Questo rende il modello a 2 bit la scelta giusta per il nostro hardware. Con 80GB di VRAM e 125GB di RAM, questa versione quantizzata resta comunque impegnativa a livello di risorse ma molto più realistica da eseguire in locale, offrendo ancora buone prestazioni per coding e workflow agentici.
Ora installiamo gli strumenti necessari per scaricare in modo efficiente i file del modello.
Per prima cosa, installa il pacchetto Hugging Face Hub con supporto hf_xet, insieme all’helper hf-xet:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetPoi, installa hf_transfer per velocizzare i download di modelli di grandi dimensioni:
pip -q install -U hf_transferSuccessivamente, abilita i trasferimenti ad alte prestazioni per download più rapidi:
export HF_XET_HIGH_PERFORMANCE=1Infine, scarica i file del modello GLM 5.1 in una cartella locale:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Anche questa versione più piccola resta comunque un download pesante. Nel mio setup, il modello a 2 bit ha impiegato circa 17 minuti, quindi non preoccuparti se ci mette un po’.

Ora è il momento di lanciare il server locale e caricare il modello in memoria.
Esegui il seguente comando:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfL’argomento principale a cui prestare attenzione qui è --fit on. Indica al server di posizionare automaticamente la maggior parte possibile del modello sulla GPU, scaricando il resto sulla RAM di sistema. È particolarmente utile nel nostro setup perché ci aiuta a eseguire un modello molto grande sfruttando i 80GB di VRAM e i 125GB di RAM disponibili senza dover gestire manualmente il posizionamento dei layer.
Gli altri argomenti gestiscono per lo più nome del server, porta, impostazioni di performance, batching e lunghezza del contesto per l’inferenza.
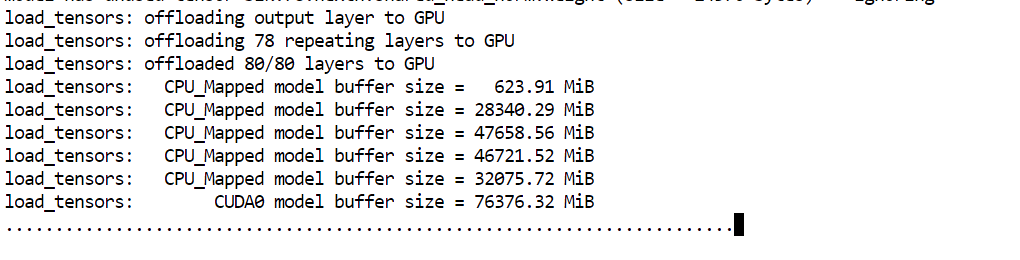
Una volta completato il caricamento del modello, vedrai un messaggio che indica che il server è in ascolto su: http://0.0.0.0:8910.

A questo punto, GLM 5.1 è in esecuzione in locale ed è pronto per essere testato nel prossimo passaggio.
Con il server in esecuzione, il passo successivo è assicurarti che il modello risponda correttamente tramite la sua API locale.
Apri un nuovo terminale dentro JupyterLab in modo che il server continui a girare nell’originale. Quindi invia una semplice richiesta di test con curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Questa richiesta invia un prompt al tuo server GLM 5.1 in locale e gli chiede di generare una breve risposta. Gli elementi principali da notare sono l’URL del server locale, il nome del modello e il formato messages usato nel body della richiesta.
Se tutto funziona correttamente, il terminale restituirà una risposta JSON contenente l’output del modello.

Ora che l’API locale funziona, il passo successivo è collegarla all’SDK Python di OpenAI. È utile perché molte app e script esistenti usano già il client OpenAI, quindi puntarlo al tuo server GLM 5.1 locale semplifica molto l’integrazione.
Per prima cosa, aggiorna pip e installa il pacchetto OpenAI:
python -m pip install --upgrade pip
pip install openaiQuindi, esegui un breve script Python che connette l’SDK al tuo server locale:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYLa cosa principale che succede qui è che non stiamo chiamando l’API cloud di OpenAI. Invece, usiamo lo stesso SDK ma cambiamo la base_url in modo che punti al server GLM 5.1 locale in esecuzione sulla porta 8910.
Se tutto è configurato correttamente, l’output dovrebbe essere:
CanberraL’ultima versione del server llama.cpp include anche una WebUI integrata, il che significa che puoi interagire con il tuo modello GLM 5.1 locale tramite una semplice interfaccia chat invece di usare solo il terminale o le chiamate API.
Per aprirla, torna alla tua dashboard RunPod e apri la scheda Connect del tuo pod. Poiché la porta 8910 è già esposta, clicca sul link HTTP Service per quella porta. Questo aprirà la WebUI di llama.cpp in una nuova scheda del browser.
Una volta caricata la pagina, puoi iniziare a chattare direttamente con il modello. Digita il tuo primo prompt e la risposta dovrebbe apparire entro pochi secondi. Nel mio setup, il modello generava circa 8 token al secondo, che è una velocità solida per un modello di queste dimensioni.
Per una prova rapida, prova a chiedergli di creare una semplice app Hello World. Ha generato esempi funzionanti in diversi linguaggi di programmazione popolari.
Ora che GLM 5.1 è in esecuzione in locale, il passo successivo è collegarlo a Claude Code. È un test utile perché GLM 5.1 è presentato come un valido modello per il coding, quindi usarlo dentro un workflow di coding agentico dà una visione migliore di come si comporta su compiti di sviluppo reali.
Starta installando Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Poi, aggiungi Claude Code al tuo PATH della shell così il comando claude funzioni dal terminale:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcDopodiché, configura Claude Code in modo che punti al tuo server GLM 5.1 locale invece dell’API ospitata di Anthropic:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFPoi ricarica la configurazione della shell così che quelle variabili d’ambiente abbiano effetto:
source ~/.bashrcOra crea una cartella di test e avvia Claude Code al suo interno:
mkdir -p test-claude-local
cd test-claude-local
claudeLa prima volta che Claude Code si avvia, potrebbe chiederti di completare alcuni passaggi di configurazione, come scegliere un tema o fidarti della directory di lavoro. Una volta fatto, puoi iniziare ad assegnargli dei task.
Per un primo test semplice, prova questo prompt:
Build the simple Hello World app in Python
Questo ti permette di verificare se Claude Code invia correttamente le richieste al tuo server GLM 5.1 locale e lo usa per generare codice.
Per la mia esperienza, questa configurazione ha funzionato, ma era sensibilmente più lenta rispetto ai test precedenti.
Con contesti più lunghi e prompt in stile coding, la velocità di generazione è scesa a circa 2 token al secondo, e il modello spesso ha impiegato troppo tempo a ragionare prima di produrre anche risposte semplici.
Questo è uno dei principali compromessi che ho notato con GLM 5.1 in questo workflow: è capace, ma può essere più lento e più verboso di quanto si desideri per task di coding leggeri.
Questa sezione copre alcuni problemi comuni che potresti incontrare eseguendo GLM 5.1 in locale e come risolverli rapidamente.
Di solito significa che il modello è troppo grande per la GPU e la memoria di sistema disponibili, quindi prova una quantizzazione più piccola o riduci la dimensione del contesto. llama.cpp supporta anche --fit on, che aiuta a adattare automaticamente il modello alla memoria disponibile.
Assicurati di aprire la porta esposta corretta da RunPod e non l’URL di JupyterLab. Il server di llama.cpp include una WebUI integrata, quindi conta la porta del server, e l’URL deve puntare a 0.0.0.0:8910 sul servizio HTTP esposto.
Di solito è un disallineamento di base URL o endpoint. llama.cpp supporta route compatibili con OpenAI e con Anthropic Messages, quindi controlla che il tuo strumento punti al path corretto, come /v1 o /v1/messages.
Può succedere perché le prestazioni dipendono sia dal client sia dal comportamento del modello backend. Claude Code supporta la configurazione tramite impostazioni e variabili d’ambiente, ma le risposte lente sono spesso causate dal fatto che il modello impiega più tempo a ragionare o generare.
Finestre di contesto più ampie e generazioni più grandi aumentano la pressione sulla memoria e i tempi di risposta. Ridurre la dimensione del contesto, la lunghezza del prompt o le impostazioni di generazione può aiutare a migliorare la velocità nei setup locali.
In generale, configurare GLM 5.1 in locale è stato abbastanza lineare. Scaricare il modello, avviare il server e testarlo per l’uso di base non ha richiesto molto sforzo. Per semplici esperimenti locali, il processo è decisamente gestibile.
La sfida principale inizia quando vuoi usarlo per workflow di agentic coding. Questo richiede più RAM e VRAM, e la generazione dei token può rallentare sensibilmente man mano che si riempie la finestra di contesto. Anche se il modello può sembrare veloce all’inizio, la modalità “thinking” aggiunge molta latenza, quindi per l’uso locale spesso ha più senso disabilitarla se la velocità è importante.
Oltre alle prestazioni, c’è anche il lato pratico da considerare. Eseguire un modello in locale significa gestire il server del modello, la configurazione della GPU e i problemi di infrastruttura in autonomia. Diventa anche più difficile quando le piattaforme di noleggio GPU come RunPod o Vast.ai hanno disponibilità limitata, fenomeno diventato più comune per via dell’aumento della domanda.
Per questo, in molti casi, un’opzione API gestita può essere la scelta migliore. Rinunci a un po’ di privacy e controllo, ma ottieni maggiore velocità, meno manutenzione e un’esperienza molto più fluida per task di coding più grandi o complessi. Se il costo è di pochi dollari al mese, può essere un compromesso conveniente rispetto a gestire tutto da solo.
Quindi, se il tuo obiettivo è sperimentare, imparare o eseguire GLM 5.1 per task locali leggeri, eseguirlo in locale è una buona opzione. Ma se il tuo obiettivo è un agentic coding affidabile su larga scala, un servizio gestito è spesso la strada più pratica. Per un confronto dettagliato, ti consiglio di consultare la nostra guida GLM-5 vs GPT-5.3-Codex.
Corsi su AI agentica
Programma
Corso
Corso