
Lernpfad
KI-Agent-Grundlagen
6 Std.
GLM 5.1 zählt aktuell zu den stärksten offenen Modellen, die du heute lokal ausführen kannst. Artificial Analysis führt es derzeit als führendes Open-Weights-Modell in seinem Intelligenzindex. Z.ai positioniert es zudem als Flaggschiff für Coding, Reasoning und agentische Workflows.
Quelle: AI Model & API Providers Analysis | Artificial Analysis
Die lokale Ausführung gibt dir mehr Kontrolle über den gesamten Workflow. Deine Daten bleiben in deiner Umgebung, und du kannst Prompts testen, Integrationen bauen und das Modell in Coding-Projekten nutzen – mit mehr Privatsphäre und weniger Risiko externer Datenexponierung.
In diesem Tutorial richtest du eine H100-RunPod-Umgebung ein, führst GLM 5.1 lokal aus, testest es per API-Calls, verbindest es mit dem OpenAI Python SDK, greifst über eine WebUI darauf zu und integrierst es in Claude Code.
Wechsle zunächst im Pods-Tab von RunPod und wähle eine H100 SXM-Maschine. Als Vorlage nimmst du die aktuelle PyTorch-Option – damit steht dir eine lauffertige Umgebung für Modell-Workloads zur Verfügung.
Bevor du deployst, passe die Pod-Speichereinstellungen an. Setze den Container-Datenträger auf 100 GB und den Volume-Datenträger auf 300 GB. So hast du genug Platz für Modellfiles, Abhängigkeiten und Caches.
Wir arbeiten komplett im gemounteten Verzeichnis /workspace, damit alles an einem Ort bleibt. Außerdem solltest du den Port 8910 öffnen – den nutzen wir sowohl für den lokalen Modellserver als auch für die llama.cpp WebUI.
Als Nächstes fügst du deinen Hugging Face Token als Umgebungsvariable HF_TOKEN hinzu.
Wenn alles passt, prüfe die Pod-Zusammenfassung und klicke auf Deploy On-Demand. Öffne anschließend die zugehörige JupyterLab-Instanz.
Starte in JupyterLab ein neues Terminal und installiere die benötigten Systempakete:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Nachdem der Pod bereit ist, baust du llama.cpp mit CUDA-Unterstützung, damit die H100-GPU für lokale Inferenz genutzt werden kann.
Klonen wir zuerst das llama.cpp-Repository von GitHub:
git clone https://github.com/ggml-org/llama.cppAls Nächstes konfigurierst du den Build und legst die erzeugten Dateien in einen separaten build-Ordner:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Danach kompilierst du die wichtigsten Binaries im optimierten Release-Modus:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Zum Schluss kopierst du die kompilierten Binaries in den Hauptordner von llama.cpp, damit sie später einfacher aufzurufen sind:
cp llama.cpp/build/bin/llama-* llama.cppAm Ende dieses Schritts stehen dir die wichtigsten llama.cpp-Tools zur Verfügung, inklusive llama-server, den wir gleich nutzen, um GLM 5.1 lokal auszuführen.
Bevor wir das Modell laden, kurz zur Erklärung, warum wir hier die 2-Bit-Version verwenden.
Das vollständige GLM 5.1-Modell hat 744B Parameter, davon 40B aktive Parameter, ein 200K-Kontextfenster und benötigt rund 1,65 TB Speicherplatz. Das ist für ein lokales Setup schlicht zu groß.
Die Version Unsloth Dynamic 2-bit GGUF reduziert die Größe auf etwa 220–236 GB – rund 80 % weniger –, behält aber wichtige Schichten in höherer Präzision für bessere Performance.
Damit passt die 2-Bit-Variante gut zu unserer Hardware. Mit 80 GB VRAM und 125 GB RAM bleibt sie zwar ressourcenintensiv, ist lokal aber deutlich realistischer zu betreiben – und liefert trotzdem starke Ergebnisse für Coding und agentische Workflows.
Installieren wir nun die Tools, um die Modelldateien effizient herunterzuladen.
Zuerst installierst du das Hugging Face Hub-Paket mit hf_xet-Support sowie den hf-xet-Helper:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetAls Nächstes installierst du hf_transfer, um große Downloads zu beschleunigen:
pip -q install -U hf_transferAktiviere anschließend High-Performance-Transfers für schnellere Downloads:
export HF_XET_HIGH_PERFORMANCE=1Zum Schluss lädst du die GLM-5.1-Modelldateien in einen lokalen Ordner:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Auch diese kleinere Variante ist noch ein großer Download. In meinem Setup dauerte die 2-Bit-Version rund 17 Minuten – mach dir also keine Sorgen, wenn es etwas länger läuft.

Jetzt startest du den lokalen Server und lädst das Modell in den Speicher.
Führe folgenden Befehl aus:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfWichtig ist hier vor allem --fit on. Damit belegt der Server automatisch so viel wie möglich des Modells auf der GPU und lagert den Rest in den Systemspeicher aus. Das ist in unserem Setup besonders hilfreich, um ein sehr großes Modell über die verfügbaren 80 GB VRAM und 125 GB RAM zu verteilen, ohne Layer manuell platzieren zu müssen.
Die übrigen Argumente regeln hauptsächlich Servernamen, Port, Performance-Settings, Batching und Kontextlänge für die Inferenz.
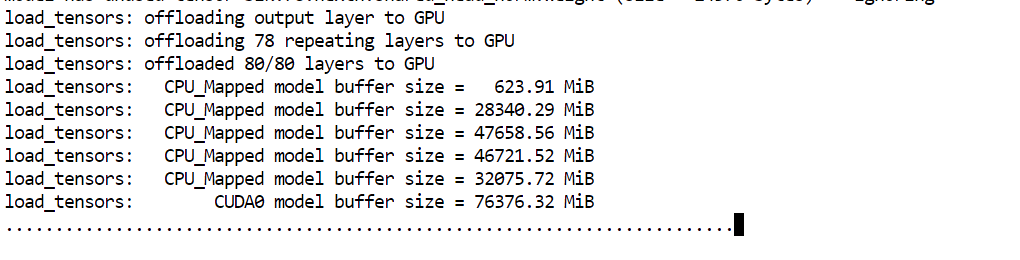
Sobald das Modell geladen ist, siehst du die Meldung, dass der Server unter http://0.0.0.0:8910 lauscht.

Damit läuft GLM 5.1 lokal und ist bereit für die Tests im nächsten Schritt.
Wenn der Server läuft, prüfst du als Nächstes, ob das Modell korrekt über seine lokale API antwortet.
Öffne ein neues Terminal in JupyterLab, damit der Server im ersten Terminal weiterläuft. Sende dann eine einfache Testanfrage mit curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Die Anfrage schickt einen Prompt an deinen lokal laufenden GLM-5.1-Server und fordert eine kurze Antwort an. Achte vor allem auf die lokale Server-URL, den Modellnamen und das Format von messages im Request-Body.
Wenn alles funktioniert, bekommst du im Terminal eine JSON-Antwort mit der Modellausgabe.

Nachdem die lokale API läuft, verbindest du sie mit dem OpenAI Python SDK. Das ist praktisch, weil viele bestehende Apps und Skripte bereits den OpenAI-Client verwenden – wenn du ihn auf deinen lokalen GLM-5.1-Server zeigst, wird die Integration deutlich einfacher.
Aktualisiere zuerst pip und installiere das OpenAI-Paket:
python -m pip install --upgrade pip
pip install openaiFühre anschließend ein kurzes Python-Skript aus, das das SDK mit deinem lokalen Server verbindet:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYWichtig: Wir rufen hier nicht die OpenAI-Cloud-API auf. Wir nutzen zwar dasselbe SDK, ändern aber die base_url, damit sie auf den lokalen GLM-5.1-Server auf Port 8910 zeigt.
Wenn alles korrekt konfiguriert ist, lautet die Ausgabe:
CanberraDer aktuelle llama.cpp-Server bringt eine integrierte WebUI mit. So kannst du mit deinem lokalen GLM-5.1-Modell über eine einfache Chatoberfläche interagieren, statt nur Terminal oder API-Calls zu verwenden.
Öffne dazu im RunPod-Dashboard den Tab Connect für deinen Pod. Da Port 8910 bereits freigegeben ist, klicke auf den Link bei HTTP Service für diesen Port. Dadurch öffnet sich die llama.cpp-WebUI in einem neuen Browser-Tab.
Sobald die Seite geladen ist, kannst du direkt mit dem Modell chatten. Tippe deinen ersten Prompt ein – die Antwort sollte nach wenigen Sekunden erscheinen. In meinem Setup lag die Generationsrate bei rund 8 Tokens pro Sekunde – solide für ein Modell dieser Größe.
Für einen schnellen Test bitte es, eine einfache Hello-World-App zu erstellen. Es liefert funktionierende Beispiele in mehreren gängigen Programmiersprachen.
Nachdem GLM 5.1 lokal läuft, verbindest du es mit Claude Code. Das ist ein sinnvoller Test, weil GLM 5.1 als starkes Coding-Modell gilt – im agentischen Coding-Workflow zeigt sich, wie es bei realen Entwicklungsaufgaben performt.
Starte mit der Installation von Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Füge anschließend Claude Code zu deinem Shell-PATH hinzu, damit der Befehl claude im Terminal verfügbar ist:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcKonfiguriere danach Claude Code so, dass es auf deinen lokalen GLM-5.1-Server statt auf die gehostete Anthropic-API zeigt:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFLade anschließend deine Shell-Konfiguration neu, damit die Umgebungsvariablen aktiv werden:
source ~/.bashrcLege nun einen Testordner an und starte Claude Code darin:
mkdir -p test-claude-local
cd test-claude-local
claudeBeim ersten Start kann Claude Code einige Setup-Schritte abfragen, z. B. Theme wählen oder dem Arbeitsverzeichnis vertrauen. Danach kannst du Aufgaben vergeben.
Für einen ersten Test nutze diesen Prompt:
Build the simple Hello World app in Python
So prüfst du, ob Claude Code Anfragen erfolgreich an deinen lokalen GLM-5.1-Server sendet und zur Codegenerierung nutzt.
In meinem Test funktionierte das Setup, wirkte aber deutlich langsamer als die vorherigen Tests.
Bei längeren Kontexten und Coding-Prompts sank die Geschwindigkeit auf etwa 2 Tokens pro Sekunde, und das Modell verbrachte oft zu viel Zeit mit Reasoning, bevor es selbst einfache Antworten ausgab.
Das ist einer der zentralen Trade-offs mit GLM 5.1 in diesem Workflow: Es ist leistungsfähig, kann sich für leichte Coding-Aufgaben aber langsamer und zu ausschweifend anfühlen.
In diesem Abschnitt findest du typische Stolpersteine bei der lokalen Ausführung von GLM 5.1 – und wie du sie schnell behebst.
Meist ist das Modell zu groß für die verfügbare GPU- und Systemspeicher-Kapazität. Nutze eine kleinere Quantisierung oder reduziere die Kontextgröße. llama.cpp unterstützt außerdem --fit on, um das Modell automatisch über den verfügbaren Speicher zu verteilen.
Stelle sicher, dass du den korrekt freigegebenen Port aus RunPod öffnest – nicht die JupyterLab-URL. Der llama.cpp-Server bringt eine eigene WebUI mit, entscheidend ist also der Serverport. Die URL sollte auf 0.0.0.0:8910 im freigegebenen HTTP-Dienst zeigen.
Meist liegt es an einer Abweichung bei Base-URL oder Endpunkt. llama.cpp unterstützt OpenAI-kompatible Routen und Anthropic-Messages-kompatible Routen. Prüfe, ob dein Tool auf den richtigen Pfad zeigt, z. B. /v1 oder /v1/messages.
Das kann passieren, weil die Performance sowohl vom Client als auch vom Modellverhalten im Backend abhängt. Claude Code lässt sich über Einstellungen und Umgebungsvariablen konfigurieren. Langsame Antworten entstehen oft dadurch, dass das Modell länger „denkt“ oder generiert.
Größere Kontextfenster und längere Generierungen erhöhen Speicherlast und Antwortzeiten. Reduziere Kontextgröße, Promptlänge oder Generierungsparameter, um lokale Setups zu beschleunigen.
Insgesamt war das lokale Setup von GLM 5.1 recht unkompliziert. Modell herunterladen, Server starten und für Basisfälle testen – das ging ohne großen Aufwand. Für einfache lokale Experimente ist der Prozess gut machbar.
Herausfordernder wird es, wenn du agentische Coding-Workflows fahren willst. Dann brauchst du mehr RAM und VRAM, und die Token-Generierung verlangsamt sich spürbar, sobald das Kontextfenster voll wird. Auch wenn das Modell anfangs flott wirkt, kostet der Thinking-Mode Zeit. Für lokale Nutzung lohnt es sich daher oft, den Thinking-Mode zu deaktivieren, wenn Geschwindigkeit zählt.
Neben der Performance zählt auch die Praxis: Ein lokales Modell bedeutet, den Modellserver zu betreiben, die GPU einzurichten und Infrastrukturthemen selbst zu lösen. Es wird zudem schwieriger, wenn GPU-Vermieter wie RunPod oder Vast.ai knapp sind – was aufgrund der wachsenden Nachfrage häufiger vorkommt.
Deshalb ist oft eine gemanagte API der sinnvollere Weg. Du gibst etwas Privatsphäre und Kontrolle ab, bekommst dafür aber mehr Geschwindigkeit, weniger Wartung und ein deutlich reibungsloseres Erlebnis bei größeren oder komplexeren Coding-Aufgaben. Wenn die Kosten nur wenige Dollar im Monat betragen, ist das oft der bessere Deal, als alles selbst zu managen.
Wenn du experimentieren, lernen oder GLM 5.1 für leichtere lokale Aufgaben nutzen willst, ist die lokale Ausführung eine gute Option. Geht es dir um verlässliches agentisches Coding im größeren Maßstab, ist ein Managed Service meist der praktischere Weg. Für einen detaillierten Vergleich empfehle ich unseren Leitfaden GLM-5 vs GPT-5.3-Codex.
Agentische KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
Tutorial
Stephen Gruppetta