
Cursus
Principes fondamentaux des agents IA
6 h
GLM 5.1 est l’un des meilleurs modèles open que vous puissiez faire tourner aujourd’hui, et Artificial Analysis le décrit actuellement comme le modèle open-weights de référence dans son Intelligence Index. Z.ai en fait aussi une sortie phare pour le code, le raisonnement et les workflows agentiques.
Source : AI Model & API Providers Analysis | Artificial Analysis
L’exécuter en local vous donne un contrôle accru sur l’ensemble du workflow. Vos données restent dans votre environnement, et vous pouvez tester des prompts, créer des intégrations et l’utiliser dans des projets de code avec davantage de confidentialité et moins de risques liés à l’exposition de données externes.
Dans ce tutoriel, vous allez configurer un environnement H100 RunPod, exécuter GLM 5.1 en local, le tester via des appels API, le connecter au SDK Python OpenAI, y accéder via une WebUI et l’intégrer à Claude Code.
Commencez par ouvrir l’onglet Pods dans RunPod et sélectionnez une machine H100 SXM. Pour le template, choisissez la dernière option PyTorch afin de disposer d’un environnement prêt à l’emploi pour exécuter des workloads de modèles.
Avant le déploiement, mettez à jour le stockage du pod. Réglez le disque du conteneur sur 100 Go et le disque volume sur 300 Go pour disposer de suffisamment d’espace pour les fichiers du modèle, les dépendances et les téléchargements en cache.
Nous ferons tout le travail dans le répertoire monté /workspace afin de tout garder au même endroit. Exposez également le port 8910, que nous utiliserons à la fois pour le serveur de modèle local et pour la llama.cpp WebUI.
Ensuite, ajoutez votre jeton Hugging Face comme variable d’environnement nommée HF_TOKEN.
Une fois ces paramètres définis, vérifiez le récapitulatif du pod et cliquez sur Deploy On-Demand. Après le démarrage du pod, ouvrez l’instance JupyterLab associée.
Dans JupyterLab, lancez un nouveau terminal et exécutez les commandes suivantes pour installer les paquets système requis :
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Maintenant que le pod est prêt, l’étape suivante consiste à compiler llama.cpp avec le support CUDA afin d’exploiter le GPU H100 pour l’inférence locale.
Commencez par cloner le dépôt llama.cpp depuis GitHub :
git clone https://github.com/ggml-org/llama.cppEnsuite, configurez la build et placez les fichiers générés dans un dossier build séparé :
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Après cela, compilez en mode Release optimisé les principaux binaires dont nous avons besoin :
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Enfin, copiez les binaires compilés dans le dossier principal de llama.cpp pour faciliter leur exécution ultérieure :
cp llama.cpp/build/bin/llama-* llama.cppÀ l’issue de cette étape, vous disposerez des principaux outils llama.cpp, dont llama-server, que nous utiliserons plus tard pour exécuter GLM 5.1 en local.
Avant de télécharger le modèle, il est utile de comprendre pourquoi nous utilisons la version 2 bits pour cette configuration.
Le modèle GLM 5.1 complet compte 744 milliards de paramètres, dont 40 milliards actifs, une fenêtre de contexte de 200 k, et nécessite environ 1,65 To d’espace disque. C’est bien trop volumineux pour un usage local pratique.
La version Unsloth Dynamic 2-bit GGUF réduit la taille à environ 220–236 Go, soit près de 80 % d’espace en moins, tout en conservant des couches clés en plus haute précision pour de meilleures performances.
C’est donc le bon choix pour notre matériel. Avec 80 Go de VRAM et 125 Go de RAM, cette version quantifiée reste gourmande en ressources, mais devient bien plus réaliste à exécuter en local, tout en offrant de bonnes performances pour le code et les workflows agentiques.
Passons maintenant à l’installation des outils nécessaires pour télécharger efficacement les fichiers du modèle.
Commencez par installer le package Hugging Face Hub avec le support hf_xet, ainsi que l’outil d’assistance hf-xet :
pip -q install -U "huggingface_hub[hf_xet]" hf-xetEnsuite, installez hf_transfer pour accélérer le téléchargement de gros modèles :
pip -q install -U hf_transferActivez ensuite les transferts haute performance pour des téléchargements plus rapides :
export HF_XET_HIGH_PERFORMANCE=1Enfin, téléchargez les fichiers du modèle GLM 5.1 dans un dossier local :
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Même dans cette version réduite, le téléchargement reste volumineux. Dans ma configuration, le modèle 2 bits a pris environ 17 minutes ; ne vous inquiétez pas si cela prend un peu de temps.

Il est temps de lancer le serveur local et de charger le modèle en mémoire.
Exécutez la commande suivante :
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfL’argument principal à surveiller ici est --fit on. Il indique au serveur de placer automatiquement le plus possible du modèle sur le GPU, en déportant le reste vers la RAM système. C’est particulièrement utile dans notre configuration, car cela nous aide à faire tourner un très grand modèle en répartissant la charge entre les 80 Go de VRAM et les 125 Go de RAM sans avoir à gérer manuellement le placement des couches.
Les autres arguments gèrent principalement le nom du serveur, le port, les réglages de performance, le batching et la longueur de contexte pour l’inférence.
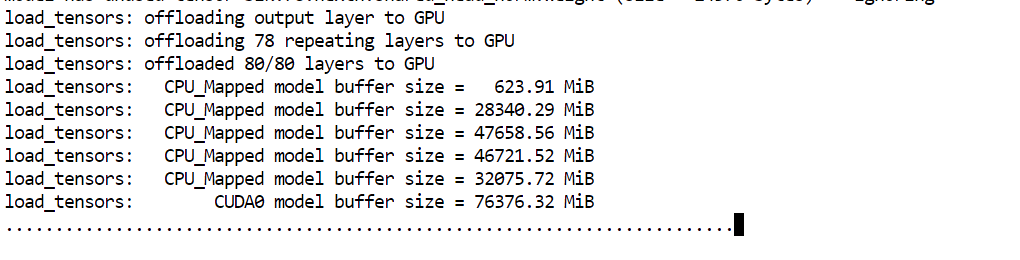
Une fois le modèle chargé, un message indique que le serveur écoute sur : http://0.0.0.0:8910.

À ce stade, GLM 5.1 fonctionne en local et est prêt pour les tests de l’étape suivante.
Avec le serveur en route, la prochaine étape consiste à vérifier que le modèle répond correctement via son API locale.
Ouvrez un nouveau terminal dans JupyterLab pour laisser le serveur tourner dans le premier. Envoyez ensuite une requête de test simple avec curl :
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Cette requête envoie un prompt à votre serveur GLM 5.1 local et lui demande de générer une réponse courte. Les éléments clés à noter sont l’URL du serveur local, le nom du modèle et le format messages utilisé dans le corps de la requête.
Si tout fonctionne, le terminal renverra une réponse JSON contenant la sortie du modèle.

Maintenant que l’API locale fonctionne, connectez-la au SDK Python OpenAI. C’est utile car de nombreuses applications et scripts existants utilisent déjà le client OpenAI : le pointer vers votre serveur GLM 5.1 local simplifie grandement l’intégration.
Commencez par mettre à jour pip et installer le package OpenAI :
python -m pip install --upgrade pip
pip install openaiEnsuite, exécutez un court script Python qui connecte le SDK à votre serveur local :
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYL’idée principale ici est que nous n’appelons pas l’API cloud d’OpenAI. Nous utilisons le même SDK, mais en changeant le base_url pour qu’il pointe vers le serveur GLM 5.1 local qui tourne sur le port 8910.
Si tout est correctement configuré, la sortie devrait être :
CanberraLa dernière version du serveur llama.cpp inclut aussi une WebUI intégrée, ce qui vous permet d’interagir avec votre modèle GLM 5.1 local via une interface de chat, et pas uniquement via le terminal ou des appels API.
Pour l’ouvrir, retournez sur votre tableau de bord RunPod et ouvrez l’onglet Connect de votre pod. Comme le port 8910 est déjà exposé, cliquez sur le lien HTTP Service associé. Cela ouvrira la WebUI de llama.cpp dans un nouvel onglet de votre navigateur.
Une fois la page chargée, vous pouvez commencer à discuter directement avec le modèle. Saisissez votre premier prompt : la réponse devrait apparaître en quelques secondes. Dans ma configuration, le débit de génération était d’environ 8 tokens par seconde, ce qui est honorable pour un modèle de cette taille.
Pour un test rapide, demandez-lui de créer une simple application Hello World. Il a généré des exemples fonctionnels dans plusieurs langages populaires.
Maintenant que GLM 5.1 tourne en local, connectez-le à Claude Code. C’est un test pertinent, car GLM 5.1 est présenté comme un solide modèle de codage : l’utiliser dans un workflow d’agent de code donne une meilleure idée de ses performances sur des tâches de développement réelles.
Commencez par installer Claude Code :
curl -fsSL https://claude.ai/install.sh | bash
Ajoutez ensuite Claude Code à votre PATH du shell pour que la commande claude fonctionne depuis le terminal :
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcConfigurez ensuite Claude Code pour qu’il pointe vers votre serveur GLM 5.1 local plutôt que vers l’API hébergée d’Anthropic :
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFRechargez ensuite votre configuration de shell pour appliquer ces variables d’environnement :
source ~/.bashrcCréez maintenant un dossier de test et lancez Claude Code à l’intérieur :
mkdir -p test-claude-local
cd test-claude-local
claudeAu premier démarrage, Claude Code peut vous demander quelques réglages initiaux, comme le choix d’un thème ou la confiance dans le répertoire de travail. Une fois terminé, vous pouvez commencer à lui soumettre des tâches.
Pour un premier test simple, essayez ce prompt :
Build the simple Hello World app in Python
Cela vous permet de vérifier si Claude Code envoie bien des requêtes à votre serveur GLM 5.1 local et l’utilise pour la génération de code.
D’après mon expérience, cette configuration fonctionne, mais elle était sensiblement plus lente que les tests précédents.
Avec un contexte plus long et des prompts orientés codage, la vitesse de génération est tombée autour de 2 tokens par seconde, et le modèle consacrait souvent trop de temps au raisonnement avant de produire des réponses pourtant simples.
C’est l’un des principaux arbitrages que j’ai constatés avec GLM 5.1 dans ce workflow : il est capable, mais peut se montrer plus lent et plus verbeux que souhaité pour des tâches de codage légères.
Cette section couvre quelques problèmes fréquents lors de l’exécution de GLM 5.1 en local et comment les résoudre rapidement.
Cela signifie généralement que le modèle est trop grand pour la mémoire GPU et système disponible. Essayez une quantification plus petite ou réduisez la taille de contexte. llama.cpp prend également en charge --fit on, qui aide à ajuster automatiquement le modèle à la mémoire disponible.
Assurez-vous d’ouvrir le bon port exposé depuis RunPod et non l’URL de JupyterLab. Le serveur llama.cpp inclut sa propre WebUI : c’est donc le port du serveur qui compte, et l’URL doit pointer vers 0.0.0.0:8910 sur le service HTTP exposé.
C’est généralement un problème d’URL de base ou d’endpoint. llama.cpp prend en charge des routes compatibles OpenAI et des routes compatibles Anthropic Messages : vérifiez que votre outil pointe vers le bon chemin, par exemple /v1 ou /v1/messages.
Cela peut arriver car les performances dépendent à la fois du client et du comportement du modèle côté serveur. Claude Code est configurable via des paramètres et des variables d’environnement, mais les réponses plus lentes proviennent souvent du temps de raisonnement ou de génération plus élevé du modèle.
Des fenêtres de contexte plus longues et des générations plus importantes augmentent la pression mémoire et le temps de réponse. Réduire la taille de contexte, la longueur du prompt ou les paramètres de génération peut aider à améliorer la vitesse en local.
Dans l’ensemble, la mise en place de GLM 5.1 en local s’est révélée assez simple. Télécharger le modèle, lancer le serveur et le tester pour des usages basiques ne demande pas beaucoup d’efforts. Pour des expérimentations locales simples, le processus est très abordable.
Les difficultés commencent lorsque vous souhaitez l’utiliser pour des workflows de codage agentiques. Cela requiert davantage de RAM et de VRAM, et la génération peut nettement ralentir à mesure que la fenêtre de contexte se remplit. Même si le modèle peut sembler rapide au départ, le mode « reasoning » ajoute beaucoup de latence : pour un usage local, il est souvent plus pertinent de le désactiver si la vitesse est prioritaire.
Au-delà des performances, l’aspect pratique compte aussi. Faire tourner un modèle en local implique de gérer le serveur de modèle, la configuration GPU et l’infrastructure. Cela devient également plus compliqué quand les plateformes de location de GPU comme RunPod ou Vast.ai manquent de disponibilité, phénomène de plus en plus fréquent avec la demande croissante.
C’est pourquoi, dans bien des cas, une API managée peut être le meilleur choix. Vous perdez un peu en confidentialité et en contrôle, mais vous gagnez en vitesse, en simplicité de maintenance et en fluidité pour des tâches de codage plus vastes ou plus complexes. Si le coût se limite à quelques dollars par mois, le compromis peut valoir la peine par rapport à une gestion 100 % maison.
Ainsi, si votre objectif est d’expérimenter, d’apprendre ou d’exécuter GLM 5.1 pour des tâches locales légères, l’exécuter en local est une bonne option. Mais si votre priorité est un codage agentique fiable à l’échelle, un service managé est souvent la voie la plus pragmatique. Pour une comparaison détaillée, nous vous recommandons notre guide GLM-5 vs GPT-5.3-Codex.
Cours sur l’IA agentique
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Tutoriel
Tutoriel
Mark Pedigo
Tutoriel
DataCamp Team
Tutoriel
Stephen Gruppetta
