
Program
AI Ajanının Temelleri
6 sa
GLM 5.1 bugün yerelde çalıştırabileceğiniz en güçlü açık modellerden biridir ve Artificial Analysis şu anda bunu Zekâ Endeksi’nde önde gelen açık-ağırlıklı model olarak tanımlıyor. Z.ai ayrıca onu kodlama, akıl yürütme ve ajan tabanlı iş akışları için amiral gemisi bir sürüm olarak konumlandırıyor.
Kaynak: AI Model & API Providers Analysis | Artificial Analysis
Modeli yerelde çalıştırmak, tüm iş akışı üzerinde size daha fazla kontrol sağlar. Verileriniz kendi ortamınızda kalır; istemleri test edebilir, entegrasyonlar oluşturabilir ve daha fazla gizlilikle, dış veri sızıntısı endişesi olmadan kodlama projelerinde kullanabilirsiniz.
Bu eğitimde bir H100 RunPod ortamı kuracak, GLM 5.1’i yerelde çalıştıracak, API çağrılarıyla test edecek, OpenAI Python SDK’sına bağlayacak, WebUI üzerinden erişecek ve Claude Code ile entegre edeceksiniz.
Öncelikle RunPod’da Pods sekmesine gidin ve bir H100 SXM makinesi seçin. Şablon olarak en güncel PyTorch seçeneğini tercih edin; böylece model iş yüklerini çalıştırmaya hazır bir ortamınız olur.
Dağıtmadan önce pod depolama ayarlarını güncelleyin. Container diskini 100GB, volume diskini ise 300GB olarak ayarlayın; böylece model dosyaları, bağımlılıklar ve önbelleğe alınan indirmeler için yeterli alanınız olur.
Tüm çalışmayı bağlanan /workspace dizini içinde yapacağız; böylece her şey tek bir yerde kalır. Ayrıca 8910 numaralı portu da açmalısınız; bunu hem yerel model sunucusu hem de llama.cpp WebUI için kullanacağız.
Ardından, Hugging Face belirtecinizi HF_TOKEN adlı bir ortam değişkeni olarak ekleyin.
Bunu ayarladıktan sonra pod özetini gözden geçirin ve Deploy On-Demand’e tıklayın. Pod başladıktan sonra ona bağlı JupyterLab örneğini açın.
JupyterLab içinde yeni bir terminal başlatın ve gerekli sistem paketlerini kurmak için aşağıdaki komutları çalıştırın:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Artık pod hazır olduğuna göre, sıradaki adım llama.cpp’yi CUDA desteğiyle derlemek; böylece yerel çıkarım için H100 GPU’yu kullanabilir.
Önce GitHub’dan llama.cpp deposunu klonlayın:
git clone https://github.com/ggml-org/llama.cppArdından derlemeyi yapılandırın ve oluşturulan derleme dosyalarını ayrı bir build klasörüne yerleştirin:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Sonrasında, ihtiyaç duyduğumuz ana ikilileri optimize edilmiş Release kipinde derleyin:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Son olarak, derlenen ikilileri ileride daha kolay çalıştırmak için ana llama.cpp klasörüne kopyalayın:
cp llama.cpp/build/bin/llama-* llama.cppBu adımın sonunda, daha sonra GLM 5.1’i yerelde çalıştırmak için kullanacağımız llama-server dâhil temel llama.cpp araçları hazır olacaktır.
Modeli indirmeden önce, bu kurulum için neden 2-bit sürümü kullandığımızı anlamak faydalıdır.
Tam GLM 5.1 modeli 744B parametreye, 40B aktif parametreye ve 200K bağlam penceresine sahiptir ve yaklaşık 1,65TB disk alanı gerektirir. Bu, pratik bir yerel kurulum için fazlasıyla büyüktür.
Unsloth Dynamic 2-bit GGUF sürümü boyutu yaklaşık 220–236GB’a düşürür; depolama gereksinimini yaklaşık %80 oranında azaltırken, daha iyi performans için önemli katmanları daha yüksek hassasiyette tutar.
Bu nedenle 2-bit model donanımımız için doğru seçimdir. 80GB VRAM ve 125GB RAM ile bu kantize sürüm hâlâ kaynak yoğun olsa da yerelde çalıştırmak çok daha gerçekçidir ve kodlama ile ajan tabanlı iş akışları için güçlü performans sunar.
Şimdi, model dosyalarını verimli biçimde indirmek için gereken araçları kuralım.
Önce, hf_xet desteğiyle Hugging Face Hub paketini ve hf-xet yardımcı aracını kurun:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetArdından, büyük model indirmelerini hızlandırmak için hf_transfer kurun:
pip -q install -U hf_transferSonrasında, daha hızlı indirmeler için yüksek performanslı transferleri etkinleştirin:
export HF_XET_HIGH_PERFORMANCE=1Son olarak GLM 5.1 model dosyalarını yerel bir klasöre indirin:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Bu daha küçük sürüm bile hâlâ büyük bir indirme boyutuna sahiptir. Benim kurulumumda 2-bit modelin indirilmesi yaklaşık 17 dakika sürdü; bu yüzden biraz zaman alırsa endişelenmeyin.

Şimdi yerel sunucuyu başlatma ve modeli belleğe yükleme zamanı.
Aşağıdaki komutu çalıştırın:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfBurada dikkat edilmesi gereken ana argüman --fit on’dur. Bu, sunucuya modelin olabildiğince büyük kısmını otomatik olarak GPU’ya yerleştirmesini, kalanını ise sistem RAM’ine aktarmasını söyler. Bu, özellikle bizim kurulumumuzda yararlıdır; çünkü 80GB VRAM ve 125GB RAM arasında çok büyük bir modeli, katman yerleşimini elle yönetmeden çalıştırmamıza yardımcı olur.
Diğer argümanlar çoğunlukla sunucu adı, port, performans ayarları, toplu işleme ve çıkarım için bağlam uzunluğunu yönetir.
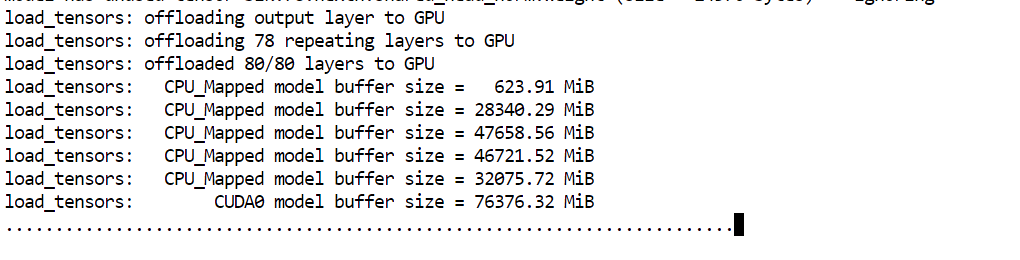
Model yüklemeyi tamamladığında, sunucunun şu adreste dinlediğini belirten bir mesaj göreceksiniz: http://0.0.0.0:8910.

Bu noktada GLM 5.1 yerelde çalışır durumdadır ve bir sonraki adımda test edilmeye hazırdır.
Sunucu çalışırken, sıradaki adım modelin yerel API üzerinden doğru yanıt verip vermediğini doğrulamaktır.
Sunucunun ilk terminalde çalışmaya devam edebilmesi için JupyterLab içinde yeni bir terminal açın. Ardından basit bir test isteğini curl ile gönderin:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Bu istek, yerelde çalışan GLM 5.1 sunucunuza bir istem gönderir ve kısa bir yanıt üretmesini ister. Burada dikkat edilecek başlıca noktalar; yerel sunucu URL’si, model adı ve istek gövdesinde kullanılan messages biçimidir.
Her şey doğru çalışıyorsa, terminal model çıktısını içeren bir JSON yanıt döndürecektir.

Yerel API çalıştığına göre, sıradaki adım onu OpenAI Python SDK’ya bağlamaktır. Bu kullanışlıdır; çünkü mevcut uygulama ve betiklerin çoğu hâlihazırda OpenAI istemcisini kullanır; onu yerel GLM 5.1 sunucunuza yönlendirmek entegrasyonu çok daha kolaylaştırır.
Önce pip’i yükseltin ve OpenAI paketini kurun:
python -m pip install --upgrade pip
pip install openaiArdından, SDK’yı yerel sunucunuza bağlayan kısa bir Python betiği çalıştırın:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYBurada olan temel şey; OpenAI bulut API’sini çağırmıyor olmamız. Bunun yerine aynı SDK’yı kullanıyoruz; ancak base_url’yi yerel GLM 5.1 sunucusuna, yani 8910 portunda çalışan adrese işaret edecek şekilde değiştiriyoruz.
Her şey doğru kurulduysa çıktı şöyle olmalıdır:
CanberraEn yeni llama.cpp sunucusu yerleşik bir WebUI içerir; bu da yerel GLM 5.1 modelinizle yalnızca terminal veya API çağrıları yerine basit bir sohbet arayüzü üzerinden etkileşime geçebileceğiniz anlamına gelir.
Bunu açmak için RunPod panonuza geri dönün ve pod’unuz için Connect sekmesini açın. 8910 numaralı port zaten açık olduğundan, bu port için HTTP Service bağlantısına tıklayın. Bu, llama.cpp WebUI’ı yeni bir tarayıcı sekmesinde açacaktır.
Sayfa yüklendikten sonra, modelle doğrudan sohbet etmeye başlayabilirsiniz. İlk isteminizi yazın; yanıt birkaç saniye içinde görünmelidir. Benim kurulumumda model yaklaşık saniyede 8 token üretiyordu; bu boyuttaki bir model için gayet iyi bir hızdır.
Hızlı bir test için, ondan basit bir Hello World uygulaması oluşturmasını isteyin. Birçok popüler programlama dilinde çalışan örnekler üretti.
GLM 5.1 yerelde çalışır hâle geldiğine göre, sıradaki adım onu Claude Code ile bağlamaktır. Bu iyi bir testtir; çünkü GLM 5.1 güçlü bir kodlama modeli olarak konumlandırılır; onu bir kodlama ajanı iş akışında kullanmak, gerçek geliştirme görevlerindeki performansına dair daha iyi bir fikir verir.
Başlangıç olarak Claude Code’u kurun:
curl -fsSL https://claude.ai/install.sh | bash
Sonra, terminalden claude komutunu çalıştırabilmek için Claude Code’u kabuk PATH’inize ekleyin:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcArdından, Claude Code’u barındırılan Anthropic API’si yerine yerel GLM 5.1 sunucunuza işaret edecek şekilde yapılandırın:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFSonrasında, bu ortam değişkenlerinin etkinleşmesi için kabuk yapılandırmanızı yeniden yükleyin:
source ~/.bashrcŞimdi bir test klasörü oluşturun ve içinde Claude Code’u başlatın:
mkdir -p test-claude-local
cd test-claude-local
claudeClaude Code ilk kez başlatıldığında, tema seçimi veya çalışma dizinine güvenme gibi birkaç kurulum adımını tamamlamanızı isteyebilir. Bunlar bittiğinde görevler vermeye başlayabilirsiniz.
Basit bir ilk test için şu istemi deneyin:
Build the simple Hello World app in Python
Bu, Claude Code’un istekleri yerel GLM 5.1 sunucunuza başarıyla gönderip kod üretimi için kullanıp kullanmadığını kontrol etmenizi sağlar.
Deneyimlerime göre bu kurulum çalıştı; ancak önceki testlere kıyasla belirgin şekilde daha yavaştı.
Daha uzun bağlam ve kodlama tarzı istemlerde üretim hızı saniyede yaklaşık 2 tokene düştü ve model basit yanıtlardan önce bile sık sık fazla zaman düşünmeye harcadı.
Bu iş akışında GLM 5.1 ile fark ettiğim temel ödünlerden biri buydu: yetenekli; ancak hafif kodlama görevleri için istediğinizden daha yavaş ve daha ayrıntıcı olabilir.
Bu bölüm, GLM 5.1’i yerelde çalıştırırken karşılaşabileceğiniz birkaç yaygın sorunu ve bunları hızlıca nasıl çözeceğinizi kapsar.
Bu genellikle modelin mevcut GPU ve sistem belleği için çok büyük olduğu anlamına gelir; daha küçük bir kantizasyona geçin veya bağlam boyutunu azaltın. llama.cpp ayrıca modeli mevcut bellek boyunca otomatik olarak yerleştirmeye yardımcı olan --fit on seçeneğini de destekler.
RunPod’dan doğru açık portu açtığınızdan ve JupyterLab URL’sini kullanmadığınızdan emin olun. llama.cpp sunucusu kendi yerleşik WebUI’ını içerir; bu nedenle önemli olan sunucu portudur ve URL, açık HTTP hizmetinde 0.0.0.0:8910’a işaret etmelidir.
Bu genellikle temel URL veya uç nokta uyuşmazlığıdır. llama.cpp OpenAI uyumlu yolları ve Anthropic Messages uyumlu yolları destekler; bu yüzden aracınızın /v1 veya /v1/messages gibi doğru yola işaret ettiğini kontrol edin.
Bunun nedeni, performansın hem istemciye hem de arka uçtaki model davranışına bağlı olması olabilir. Claude Code ayarlar ve ortam değişkenleri aracılığıyla yapılandırmayı destekler; ancak yavaş yanıtların nedeni çoğunlukla modelin daha uzun süre düşünmesi veya üretmesidir.
Daha uzun bağlam pencereleri ve daha büyük üretimler bellek baskısını ve yanıt süresini artırır. Bağlam boyutunu, istem uzunluğunu veya üretim ayarlarını azaltmak, yerel kurulumlarda hızı artırmaya yardımcı olabilir.
Genel olarak, GLM 5.1’i yerelde kurmak oldukça sorunsuzdu. Modeli indirmek, sunucuyu çalıştırmak ve temel kullanım için test etmek pek çaba gerektirmedi. Basit yerel denemeler için süreç oldukça yönetilebilir hissettiriyor.
Asıl zorluk, onu ajan tabanlı kodlama iş akışları için kullanmak istediğinizde başlıyor. Bu, daha fazla RAM ve VRAM gerektirir ve bağlam penceresi doldukça token üretimi belirgin şekilde yavaşlayabilir. Model ilk başta hızlı hissettirse de düşünme modu çok fazla gecikme ekler; bu nedenle hız önemliyse yerel kullanımda düşünme modunu kapatmak çoğu zaman daha mantıklıdır.
Performansın ötesinde pratik taraf da var. Yerel bir modeli çalıştırmak, model sunucusunu yönetmek, GPU kurulumunu yapmak ve altyapı sorunlarıyla sizin ilgilenmeniz demektir. Ayrıca RunPod veya Vast.ai gibi GPU kiralama platformlarında sınırlı kullanılabilirlik olduğunda iş daha da zorlaşır; artan talep nedeniyle bu durum daha yaygın hâle geliyor.
Bu yüzden pek çok durumda yönetilen bir API seçeneği daha iyi olabilir. Bir miktar gizlilik ve kontrolden feragat edersiniz; ancak daha iyi hız, daha az bakım ve daha büyük veya daha karmaşık kodlama görevleri için çok daha sorunsuz bir deneyim elde edersiniz. Maliyet ayda sadece birkaç dolar ise, her şeyi kendiniz yönetmeye kıyasla buna değer bir değiş tokuş olabilir.
Dolayısıyla amacınız denemek, öğrenmek veya GLM 5.1’i daha hafif yerel görevlerde çalıştırmak ise yerelde çalıştırmak iyi bir seçenektir. Ancak amacınız ölçekli ve güvenilir ajan tabanlı kodlama ise, yönetilen bir hizmet çoğu zaman daha pratik bir yoldur. Ayrıntılı bir karşılaştırma için GLM-5 vs GPT-5.3-Codex rehberimize göz atmanızı öneririm.
Agentik Yapay Zekâ Kursları
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
