
Tracks
Cơ bản về Trợ lý Trí tuệ Nhân tạo
6 giờ
GLM 5.1 là một trong những mô hình mã nguồn mở mạnh nhất mà bạn có thể chạy hiện nay, và Artificial Analysis hiện mô tả nó là mô hình open-weights dẫn đầu trên Intelligence Index của họ. Z.ai cũng định vị đây là bản phát hành chủ lực cho lập trình, suy luận và các quy trình agentic.
Nguồn: AI Model & API Providers Analysis | Artificial Analysis
Chạy cục bộ giúp bạn kiểm soát tốt hơn toàn bộ quy trình. Dữ liệu của bạn ở lại trong môi trường riêng, và bạn có thể thử nghiệm prompt, xây dựng tích hợp, cũng như dùng cho dự án lập trình với nhiều quyền riêng tư hơn và ít lo ngại về rò rỉ dữ liệu ra bên ngoài.
Trong hướng dẫn này, bạn sẽ thiết lập môi trường H100 RunPod, chạy GLM 5.1 cục bộ, kiểm thử bằng các lệnh gọi API, kết nối với OpenAI Python SDK, truy cập qua WebUI và tích hợp với Claude Code.
Bắt đầu bằng cách vào thẻ Pods trong RunPod và chọn máy H100 SXM. Với mẫu (template), chọn tùy chọn PyTorch mới nhất để có sẵn môi trường chạy workload mô hình.
Trước khi triển khai, hãy cập nhật cài đặt lưu trữ của pod. Đặt container disk thành 100GB và volume disk thành 300GB để đủ chỗ cho tệp mô hình, phụ thuộc và bộ nhớ đệm tải xuống.
Chúng ta sẽ làm mọi việc trong thư mục được mount /workspace để mọi thứ nằm cùng một nơi. Bạn cũng nên mở cổng 8910, chúng ta sẽ dùng cho cả máy chủ mô hình cục bộ và llama.cpp WebUI.
Tiếp theo, thêm token Hugging Face của bạn như một biến môi trường tên HF_TOKEN.
Sau khi thiết lập xong, hãy xem lại tóm tắt pod và nhấp Deploy On-Demand. Khi pod khởi động, mở phiên bản JupyterLab đi kèm.
Bên trong JupyterLab, mở một terminal mới và chạy các lệnh sau để cài đặt các gói hệ thống cần thiết:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Giờ pod đã sẵn sàng, bước tiếp theo là build llama.cpp với hỗ trợ CUDA để có thể dùng GPU H100 cho suy luận cục bộ.
Đầu tiên, clone kho llama.cpp từ GitHub:
git clone https://github.com/ggml-org/llama.cppTiếp theo, cấu hình build và đặt các tệp build được tạo vào thư mục build riêng:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Sau đó, biên dịch các binary chính cần dùng ở chế độ Release tối ưu hóa:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Cuối cùng, sao chép các binary đã biên dịch vào thư mục chính llama.cpp để sau này chạy thuận tiện hơn:
cp llama.cpp/build/bin/llama-* llama.cppKết thúc bước này, bạn sẽ có các công cụ llama.cpp chính sẵn sàng, bao gồm llama-server, chúng ta sẽ dùng để chạy GLM 5.1 cục bộ.
Trước khi tải mô hình, sẽ hữu ích nếu bạn hiểu vì sao chúng ta dùng phiên bản 2-bit cho thiết lập này.
Mô hình GLM 5.1 đầy đủ có 744B tham số, với 40B tham số hoạt động, cửa sổ ngữ cảnh 200K, và cần khoảng 1,65TB dung lượng đĩa. Điều này quá lớn cho thiết lập cục bộ thực tế.
Phiên bản Unsloth Dynamic 2-bit GGUF giảm kích thước xuống khoảng 220–236GB, cắt giảm yêu cầu lưu trữ khoảng 80% trong khi vẫn giữ các lớp quan trọng ở độ chính xác cao hơn để cải thiện hiệu năng.
Điều đó khiến mô hình 2-bit phù hợp với phần cứng của chúng ta. Với 80GB VRAM và 125GB RAM, phiên bản đã lượng tử hóa này vẫn tiêu tốn tài nguyên nhưng thực tế hơn nhiều để chạy cục bộ, đồng thời vẫn cho hiệu suất tốt cho lập trình và quy trình agentic.
Giờ hãy cài các công cụ cần để tải tệp mô hình hiệu quả.
Trước hết, cài gói Hugging Face Hub với hỗ trợ hf_xet, cùng với tiện ích hf-xet:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetTiếp theo, cài hf_transfer để tăng tốc tải mô hình lớn:
pip -q install -U hf_transferSau đó, bật truyền tải hiệu năng cao để tải xuống nhanh hơn:
export HF_XET_HIGH_PERFORMANCE=1Cuối cùng, tải tệp mô hình GLM 5.1 vào một thư mục cục bộ:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Ngay cả phiên bản nhỏ hơn này vẫn là một lần tải lớn. Trong thiết lập của tôi, mô hình 2-bit mất khoảng 17 phút để hoàn tất, nên đừng lo nếu mất nhiều thời gian một chút.

Giờ là lúc khởi chạy máy chủ cục bộ và nạp mô hình vào bộ nhớ.
Chạy lệnh sau:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfTham số chính cần chú ý ở đây là --fit on. Tham số này báo cho máy chủ tự động đặt nhiều phần của mô hình nhất có thể lên GPU, và đẩy phần còn lại xuống RAM hệ thống. Điều này đặc biệt hữu ích trong thiết lập của chúng ta, vì nó giúp chạy một mô hình rất lớn trên 80GB VRAM và 125GB RAM sẵn có mà không phải tự điều khiển vị trí các lớp.
Các tham số khác chủ yếu xử lý tên máy chủ, cổng, cài đặt hiệu năng, batching và độ dài ngữ cảnh cho suy luận.
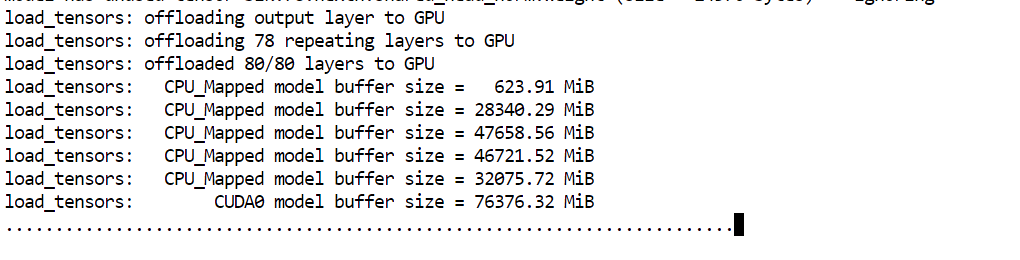
Khi mô hình nạp xong, bạn sẽ thấy thông báo cho biết máy chủ đang lắng nghe tại: http://0.0.0.0:8910.

Tại thời điểm đó, GLM 5.1 đã chạy cục bộ và sẵn sàng được kiểm thử ở bước tiếp theo.
Khi máy chủ đang chạy, bước tiếp theo là đảm bảo mô hình phản hồi đúng thông qua API cục bộ.
Mở một terminal mới trong JupyterLab để máy chủ tiếp tục chạy ở terminal ban đầu. Sau đó gửi một yêu cầu kiểm thử đơn giản với curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Yêu cầu này gửi một prompt tới máy chủ GLM 5.1 đang chạy cục bộ của bạn và yêu cầu nó tạo một phản hồi ngắn. Những điểm chính cần để ý là URL máy chủ cục bộ, tên mô hình và định dạng messages được dùng trong phần thân yêu cầu.
Nếu mọi thứ hoạt động đúng, terminal sẽ trả về phản hồi JSON chứa đầu ra của mô hình.

Giờ API cục bộ đã hoạt động, bước tiếp theo là kết nối nó với OpenAI Python SDK. Điều này hữu ích vì nhiều ứng dụng và script hiện có đã dùng client OpenAI, nên trỏ client đó tới máy chủ GLM 5.1 cục bộ sẽ giúp tích hợp dễ dàng hơn nhiều.
Trước tiên, nâng cấp pip và cài gói OpenAI:
python -m pip install --upgrade pip
pip install openaiTiếp theo, chạy một script Python ngắn để kết nối SDK với máy chủ cục bộ của bạn:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYĐiểm chính ở đây là chúng ta không gọi OpenAI cloud API. Thay vào đó, chúng ta dùng cùng SDK nhưng thay đổi base_url để trỏ tới máy chủ GLM 5.1 cục bộ đang chạy trên cổng 8910.
Nếu mọi thứ được thiết lập đúng, đầu ra sẽ là:
CanberraMáy chủ llama.cpp mới nhất cũng bao gồm WebUI tích hợp sẵn, nghĩa là bạn có thể tương tác với mô hình GLM 5.1 cục bộ qua giao diện trò chuyện đơn giản thay vì chỉ dùng terminal hay gọi API.
Để mở, hãy quay lại bảng điều khiển RunPod và mở thẻ Connect cho pod của bạn. Vì cổng 8910 đã được mở, hãy nhấp vào liên kết HTTP Service cho cổng đó. Thao tác này sẽ mở WebUI của llama.cpp trong một tab trình duyệt mới.
Khi trang tải xong, bạn có thể bắt đầu trò chuyện trực tiếp với mô hình. Gõ prompt đầu tiên của bạn, và phản hồi sẽ xuất hiện trong vài giây. Trong thiết lập của tôi, mô hình tạo khoảng 8 token/giây, đây là tốc độ ổn cho mô hình cỡ này.
Để thử nhanh, hãy yêu cầu nó xây dựng một ứng dụng Hello World đơn giản. Nó đã tạo các ví dụ hoạt động trong nhiều ngôn ngữ lập trình phổ biến.
Giờ GLM 5.1 đã chạy cục bộ, bước tiếp theo là kết nối nó với Claude Code. Đây là một bài kiểm thử hữu ích vì GLM 5.1 được định vị là mô hình lập trình mạnh, nên dùng nó trong quy trình tác tử lập trình sẽ cho cảm nhận rõ hơn về hiệu năng trên tác vụ phát triển thực tế.
Start bằng cách cài đặt Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Tiếp theo, thêm Claude Code vào PATH của shell để lệnh claude hoạt động từ terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcSau đó, cấu hình Claude Code để trỏ tới máy chủ GLM 5.1 cục bộ thay vì Anthropic API được host:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFRồi tải lại cấu hình shell để các biến môi trường đó có hiệu lực:
source ~/.bashrcBây giờ, tạo một thư mục thử nghiệm và khởi chạy Claude Code trong đó:
mkdir -p test-claude-local
cd test-claude-local
claudeLần đầu Claude Code khởi động, có thể sẽ yêu cầu bạn hoàn tất vài bước thiết lập, như chọn giao diện hoặc cấp quyền thư mục làm việc. Xong xuôi, bạn có thể bắt đầu giao nhiệm vụ cho nó.
Với bài test đầu tiên đơn giản, hãy thử prompt này:
Build the simple Hello World app in Python
Điều này giúp bạn kiểm tra liệu Claude Code có gửi yêu cầu thành công tới máy chủ GLM 5.1 cục bộ và dùng nó để sinh mã hay không.
Theo trải nghiệm của tôi, thiết lập này hoạt động, nhưng chậm hơn đáng kể so với các thử nghiệm trước đó.
Với ngữ cảnh dài và prompt kiểu lập trình, tốc độ sinh giảm xuống khoảng 2 token/giây, và mô hình thường dành quá nhiều thời gian suy luận trước khi đưa ra câu trả lời đơn giản.
Đó là một trong những đánh đổi chính tôi nhận thấy với GLM 5.1 trong quy trình này: nó có khả năng, nhưng có thể chậm và dài dòng hơn mức bạn muốn cho các tác vụ lập trình nhẹ.
Phần này đề cập một vài sự cố phổ biến khi chạy GLM 5.1 cục bộ và cách khắc phục nhanh.
Thường có nghĩa là mô hình quá lớn so với bộ nhớ GPU và hệ thống sẵn có, hãy thử một bản lượng tử thấp hơn hoặc giảm kích thước ngữ cảnh. llama.cpp cũng hỗ trợ --fit on, giúp tự động khớp mô hình với bộ nhớ sẵn có.
Đảm bảo bạn đang mở đúng cổng được expose từ RunPod chứ không phải URL JupyterLab. Máy chủ llama.cpp có WebUI tích hợp, vì vậy cổng của máy chủ mới là quan trọng, và URL phải trỏ tới 0.0.0.0:8910 trên dịch vụ HTTP được expose.
Thường là do không khớp base URL hoặc endpoint. llama.cpp hỗ trợ các route tương thích OpenAI và route tương thích Anthropic Messages, nên hãy kiểm tra công cụ của bạn đang trỏ đúng đường dẫn, như /v1 hoặc /v1/messages.
Điều này có thể xảy ra vì hiệu năng phụ thuộc cả vào client và hành vi của mô hình backend. Claude Code hỗ trợ cấu hình qua phần cài đặt và biến môi trường, nhưng phản hồi chậm thường do mô hình mất nhiều thời gian để suy luận hoặc sinh nội dung.
Cửa sổ ngữ cảnh dài hơn và sinh nội dung lớn hơn sẽ tăng áp lực bộ nhớ và thời gian phản hồi. Giảm kích thước ngữ cảnh, độ dài prompt hoặc cài đặt sinh có thể giúp cải thiện tốc độ trong thiết lập cục bộ.
Nhìn chung, thiết lập GLM 5.1 cục bộ khá đơn giản. Tải mô hình, chạy máy chủ và kiểm thử cho các mục đích cơ bản không tốn nhiều công sức. Với các thử nghiệm cục bộ đơn giản, quy trình khá dễ quản lý.
Thách thức chính bắt đầu khi bạn muốn dùng cho các quy trình agentic coding. Điều đó đòi hỏi nhiều RAM và VRAM hơn, và tốc độ sinh token có thể chậm đi đáng kể khi cửa sổ ngữ cảnh đầy dần. Dù ban đầu mô hình có thể thấy nhanh, chế độ "thinking" thêm nhiều độ trễ, nên với mục đích cục bộ, thường hợp lý hơn nếu tắt chế độ này khi tốc độ là ưu tiên.
Ngoài hiệu năng, còn có yếu tố thực tế cần cân nhắc. Chạy mô hình cục bộ đồng nghĩa bạn tự quản lý máy chủ mô hình, xử lý thiết lập GPU và các vấn đề hạ tầng. Việc này cũng khó hơn khi các nền tảng thuê GPU như RunPod hoặc Vast.ai khan hàng, điều đang trở nên phổ biến do nhu cầu tăng.
Vì vậy, trong nhiều trường hợp, dùng API được quản lý có thể là lựa chọn tốt hơn. Bạn có thể đánh đổi một phần quyền riêng tư và kiểm soát, nhưng nhận lại tốc độ tốt hơn, ít bảo trì và trải nghiệm mượt hơn cho các tác vụ lập trình lớn hoặc phức tạp. Nếu chi phí chỉ vài đô mỗi tháng, đây có thể là sự đánh đổi đáng giá so với việc tự quản lý mọi thứ.
Vậy nên, nếu mục tiêu của bạn là thử nghiệm, học hỏi, hoặc chạy GLM 5.1 cho các tác vụ nhẹ cục bộ, chạy cục bộ là một lựa chọn tốt. Nhưng nếu mục tiêu là agentic coding ổn định ở quy mô lớn, dịch vụ quản lý thường là con đường thực tế hơn. Để so sánh chi tiết, tôi khuyến nghị xem hướng dẫn GLM-5 vs GPT-5.3-Codex.
Khóa học về Agentic AI
Tracks
Courses
Courses