
programa
Fundamentos de agentes de IA
6 h
GLM 5.1 es uno de los modelos open más potentes que puedes ejecutar hoy. Artificial Analysis lo describe actualmente como el modelo de pesos abiertos líder en su Intelligence Index. Z.ai también lo presenta como un lanzamiento de referencia para programación, razonamiento y flujos de trabajo agentic.
Fuente: AI Model & API Providers Analysis | Artificial Analysis
Ejecutarlo en local te da más control sobre todo el flujo. Tus datos se quedan en tu propio entorno y puedes probar prompts, crear integraciones y usarlo en proyectos de código con más privacidad y menos riesgo de exposición externa.
En este tutorial, vas a configurar un entorno H100 en RunPod, ejecutar GLM 5.1 en local, probarlo con llamadas API, conectarlo al SDK de Python de OpenAI, acceder a él desde una WebUI e integrarlo con Claude Code.
Empieza yendo a la pestaña Pods en RunPod y selecciona una máquina H100 SXM. Para la plantilla, elige la opción más reciente de PyTorch, así tendrás un entorno listo para ejecutar cargas de trabajo de modelos.
Antes de desplegar, actualiza la configuración de almacenamiento del pod. Ajusta el disco del contenedor a 100GB y el disco de volumen a 300GB para tener espacio suficiente para los archivos del modelo, dependencias y descargas en caché.
Haremos todo dentro del directorio montado /workspace para que todo quede en un solo sitio. También deberías exponer el puerto 8910, que usaremos tanto para el servidor local del modelo como para la WebUI de llama.cpp WebUI.
A continuación, añade tu token de Hugging Face como una variable de entorno llamada HF_TOKEN.
Cuando esté listo, revisa el resumen del pod y haz clic en Deploy On-Demand. Cuando el pod se inicie, abre la instancia de JupyterLab asociada.
Dentro de JupyterLab, abre un terminal nuevo y ejecuta estos comandos para instalar los paquetes de sistema necesarios:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Ahora que el pod está listo, el siguiente paso es compilar llama.cpp con soporte CUDA para que pueda usar la H100 para inferencia local.
Primero, clona el repositorio de llama.cpp desde GitHub:
git clone https://github.com/ggml-org/llama.cppDespués, configura la build y coloca los archivos generados en una carpeta build separada:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
A continuación, compila los binarios principales que necesitamos en modo Release optimizado:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Por último, copia los binarios compilados a la carpeta principal de llama.cpp para que sea más fácil ejecutarlos después:
cp llama.cpp/build/bin/llama-* llama.cppAl final de este paso tendrás listas las herramientas principales de llama.cpp, incluido llama-server, que usaremos más adelante para ejecutar GLM 5.1 en local.
Antes de descargar el modelo, conviene entender por qué usamos la versión de 2 bits para esta configuración.
El modelo GLM 5.1 completo tiene 744B parámetros, con 40B parámetros activos, una ventana de contexto de 200K y requiere aproximadamente 1,65TB de espacio en disco. Es demasiado grande para un entorno local práctico.
La versión Unsloth Dynamic 2-bit GGUF reduce el tamaño a unos 220–236GB, recortando el requisito de almacenamiento alrededor de un 80% y manteniendo capas importantes a mayor precisión para un mejor rendimiento.
Eso convierte al modelo de 2 bits en la opción adecuada para nuestro hardware. Con 80GB de VRAM y 125GB de RAM, esta versión cuantizada sigue siendo exigente, pero es mucho más realista de ejecutar en local y aun así ofrece buen rendimiento para programación y flujos agentic.
Ahora vamos a instalar las herramientas necesarias para descargar los archivos del modelo de forma eficiente.
Primero, instala el paquete Hugging Face Hub con soporte hf_xet, junto con el asistente hf-xet:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetDespués, instala hf_transfer para acelerar descargas grandes de modelos:
pip -q install -U hf_transferLuego, activa las transferencias de alto rendimiento para descargar más rápido:
export HF_XET_HIGH_PERFORMANCE=1Por último, descarga los archivos del modelo GLM 5.1 en una carpeta local:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Incluso esta versión más pequeña sigue siendo una descarga grande. En mi caso, el modelo de 2 bits tardó unos 17 minutos, así que no te preocupes si tarda un poco.

Ahora toca lanzar el servidor local y cargar el modelo en memoria.
Ejecuta este comando:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfEl argumento clave aquí es --fit on. Indica al servidor que coloque automáticamente en la GPU la mayor parte posible del modelo y descargue el resto en la RAM del sistema. Es especialmente útil en nuestra configuración, porque ayuda a ejecutar un modelo muy grande repartido entre los 80GB de VRAM y los 125GB de RAM sin tener que gestionar manualmente la ubicación de las capas.
El resto de argumentos controlan principalmente el nombre del servidor, el puerto, los ajustes de rendimiento, el batching y la longitud de contexto para la inferencia.
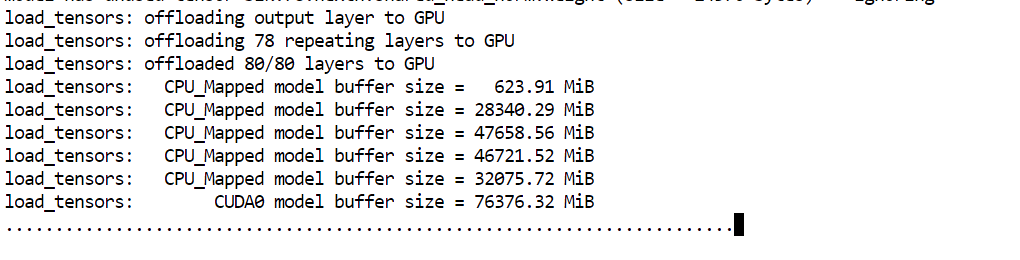
Cuando el modelo termine de cargar, verás un mensaje indicando que el servidor está escuchando en: http://0.0.0.0:8910.

En ese momento, GLM 5.1 está funcionando en local y listo para las pruebas del siguiente paso.
Con el servidor en marcha, el siguiente paso es comprobar que el modelo responde correctamente a través de su API local.
Abre un terminal nuevo dentro de JupyterLab para que el servidor siga ejecutándose en el original. Luego envía una solicitud de prueba con curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Esta solicitud envía un prompt a tu servidor local de GLM 5.1 y le pide que genere una respuesta breve. Fíjate en la URL del servidor local, el nombre del modelo y el formato de messages usado en el cuerpo de la petición.
Si todo funciona bien, el terminal devolverá una respuesta JSON con la salida del modelo.

Ahora que la API local funciona, el siguiente paso es conectarla al OpenAI Python SDK. Es útil porque muchas apps y scripts ya usan el cliente de OpenAI; apuntarlo a tu servidor local de GLM 5.1 facilita mucho la integración.
Primero, actualiza pip e instala el paquete de OpenAI:
python -m pip install --upgrade pip
pip install openaiLuego, ejecuta un script corto en Python que conecte el SDK a tu servidor local:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYLo importante aquí es que no estamos llamando a la API en la nube de OpenAI. Usamos el mismo SDK, pero cambiamos la base_url para que apunte al servidor local de GLM 5.1 que corre en el puerto 8910.
Si todo está bien configurado, la salida debería ser:
CanberraLa versión más reciente del servidor de llama.cpp incluye una WebUI integrada, así que puedes interactuar con tu modelo GLM 5.1 local desde una interfaz de chat sencilla, no solo con terminal o llamadas API.
Para abrirla, vuelve a tu panel de RunPod y abre la pestaña Connect de tu pod. Como el puerto 8910 ya está expuesto, haz clic en el enlace de HTTP Service para ese puerto. Se abrirá la WebUI de llama.cpp en una nueva pestaña del navegador.
Cuando cargue la página, puedes empezar a chatear con el modelo directamente. Escribe tu primer prompt y la respuesta debería aparecer en unos segundos. En mi caso, el modelo generaba a aproximadamente 8 tokens por segundo, una velocidad sólida para un modelo de este tamaño.
Para una prueba rápida, pídele que construya una app Hello World sencilla. Suele generar ejemplos funcionales en varios lenguajes populares.
Ahora que GLM 5.1 está corriendo en local, el siguiente paso es conectarlo con Claude Code. Es una buena prueba porque GLM 5.1 está orientado a programación; usarlo dentro de un flujo de agente de código permite ver mejor cómo rinde en tareas reales de desarrollo.
Start instalando Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Después, añade Claude Code a tu PATH de la shell para poder usar el comando claude desde el terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcA continuación, configura Claude Code para que apunte a tu servidor local de GLM 5.1 en lugar de la API alojada de Anthropic:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFLuego recarga la configuración de tu shell para que esos variables de entorno entren en vigor:
source ~/.bashrcAhora crea una carpeta de prueba y lanza Claude Code dentro:
mkdir -p test-claude-local
cd test-claude-local
claudeLa primera vez que arranca Claude Code, puede pedirte completar algunos pasos, como elegir un tema o confiar en el directorio de trabajo. Cuando termines, ya puedes empezar a darle tareas.
Para una primera prueba sencilla, usa este prompt:
Build the simple Hello World app in Python
Así comprobarás si Claude Code envía correctamente las solicitudes a tu servidor local de GLM 5.1 y lo usa para generar código.
En mi experiencia, esta configuración funcionó, pero fue notablemente más lenta que las pruebas anteriores.
Con prompts más largos y de estilo coding, la velocidad de generación bajó a unos 2 tokens por segundo, y el modelo a menudo dedicaba demasiado tiempo a razonar antes de producir respuestas simples.
Este es uno de los principales compromisos que noté con GLM 5.1 en este flujo: es capaz, pero puede ser más lento y verboso de lo que te gustaría para tareas ligeras de programación.
En esta sección repasamos algunos problemas habituales al ejecutar GLM 5.1 en local y cómo resolverlos rápido.
Suele significar que el modelo es demasiado grande para la memoria disponible de GPU y sistema. Prueba con una cuantización más pequeña o reduce el tamaño de contexto. llama.cpp también admite --fit on, que ayuda a ajustar el modelo automáticamente a la memoria disponible.
Asegúrate de abrir el puerto expuesto correcto desde RunPod y no la URL de JupyterLab. El servidor de llama.cpp incluye su propia WebUI integrada, así que el puerto del servidor es el que importa, y la URL debe apuntar a 0.0.0.0:8910 en el servicio HTTP expuesto.
Normalmente es un desajuste de base URL o endpoint. llama.cpp admite rutas compatibles con OpenAI y con Anthropic Messages, así que comprueba que tu herramienta apunta a la ruta correcta, como /v1 o /v1/messages.
Puede ocurrir porque el rendimiento depende tanto del cliente como del comportamiento del modelo en backend. Claude Code se puede configurar mediante ajustes y variables de entorno, pero las respuestas lentas suelen deberse a que el modelo tarda más en razonar o generar.
Ventanas de contexto más amplias y generaciones mayores aumentan la presión de memoria y el tiempo de respuesta. Reducir el tamaño de contexto, la longitud del prompt o los parámetros de generación puede ayudar a mejorar la velocidad en entornos locales.
En general, poner GLM 5.1 en marcha en local es bastante directo. Descargar el modelo, lanzar el servidor y probarlo para usos básicos no requiere mucho esfuerzo. Para experimentos locales sencillos, el proceso es muy asumible.
El reto aparece cuando quieres usarlo para flujos de programación agentic. Eso exige más RAM y VRAM, y la generación de tokens puede ralentizarse notablemente a medida que se llena la ventana de contexto. Aunque al principio el modelo puede parecer rápido, el modo de "reasoning" añade bastante demora, así que en local suele tener sentido desactivarlo si te importa la velocidad.
Más allá del rendimiento, también está la parte práctica. Ejecutar un modelo en local implica gestionar el servidor del modelo, la configuración de GPU y los temas de infraestructura por tu cuenta. También se complica cuando plataformas de alquiler de GPU como RunPod o Vast.ai tienen disponibilidad limitada, algo cada vez más común por la alta demanda.
Por eso, en muchos casos, una API gestionada puede ser la mejor opción. Renuncias a algo de privacidad y control, pero ganas velocidad, menos mantenimiento y una experiencia mucho más fluida para tareas de programación más grandes o complejas. Si el coste es de solo unos pocos dólares al mes, puede compensar frente a gestionarlo todo tú.
Así que, si tu objetivo es experimentar, aprender o ejecutar GLM 5.1 para tareas locales ligeras, usarlo en local es una buena opción. Pero si buscas programación agentic fiable a escala, a menudo un servicio gestionado es el camino más práctico. Para una comparativa detallada, te recomiendo leer nuestra guía GLM-5 vs GPT-5.3-Codex.
Cursos de IA agentic
programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan

