
Programa
Fundamentos de agentes de IA
6 h
O GLM 5.1 é um dos modelos open mais fortes que você pode executar hoje, e o Artificial Analysis atualmente o descreve como o modelo de open weights líder no seu Intelligence Index. A Z.ai também o apresenta como um lançamento de destaque para coding, raciocínio e fluxos de trabalho com agentes.
Fonte: AI Model & API Providers Analysis | Artificial Analysis
Rodar o modelo localmente dá mais controle sobre todo o fluxo. Seus dados permanecem no seu ambiente, e você pode testar prompts, criar integrações e usá-lo em projetos de código com mais privacidade e menos risco de exposição externa.
Neste tutorial, você vai configurar um ambiente H100 no RunPod, rodar o GLM 5.1 localmente, testá-lo com chamadas de API, conectá-lo ao OpenAI Python SDK, acessá-lo via WebUI e integrá-lo ao Claude Code.
Comece acessando a aba Pods no RunPod e selecionando uma máquina H100 SXM. No template, escolha a opção mais recente do PyTorch para ter um ambiente pronto para cargas de trabalho de modelos.
Antes de fazer o deploy, atualize as configurações de armazenamento do pod. Defina o container disk para 100GB e o volume disk para 300GB para garantir espaço suficiente para os arquivos do modelo, dependências e downloads em cache.
Vamos fazer tudo dentro do diretório montado /workspace para manter tudo organizado. Você também deve expor a porta 8910, que vamos usar tanto para o servidor local do modelo quanto para o llama.cpp WebUI.
Em seguida, adicione seu token do Hugging Face como uma variável de ambiente chamada HF_TOKEN.
Depois disso, revise o resumo do pod e clique em Deploy On-Demand. Quando o pod iniciar, abra a instância do JupyterLab anexada a ele.
No JupyterLab, abra um novo terminal e rode os comandos abaixo para instalar os pacotes de sistema necessários:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Com o pod pronto, o próximo passo é compilar o llama.cpp com suporte a CUDA para usar a H100 na inferência local.
Primeiro, clone o repositório do llama.cpp no GitHub:
git clone https://github.com/ggml-org/llama.cppDepois, configure a build e coloque os arquivos gerados em uma pasta build separada:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Em seguida, compile os binários principais em modo Release otimizado:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Por fim, copie os binários compilados para a pasta principal do llama.cpp para facilitar a execução depois:
cp llama.cpp/build/bin/llama-* llama.cppAo final deste passo, você terá as principais ferramentas do llama.cpp prontas, incluindo o llama-server, que vamos usar para rodar o GLM 5.1 localmente.
Antes de baixar o modelo, vale entender por que estamos usando a versão de 2 bits nesta configuração.
O modelo GLM 5.1 completo tem 744B parâmetros, com 40B parâmetros ativos, janela de contexto de 200K e exige cerca de 1,65TB de disco. É grande demais para um setup local prático.
A versão Unsloth Dynamic 2-bit GGUF reduz o tamanho para aproximadamente 220–236GB, cortando a exigência de armazenamento em cerca de 80% e mantendo camadas importantes em maior precisão para melhor desempenho.
Isso torna o modelo de 2 bits a escolha certa para nosso hardware. Com 80GB de VRAM e 125GB de RAM, essa versão quantizada ainda exige recursos, mas é muito mais realista para rodar localmente e oferece ótimo desempenho para coding e fluxos com agentes.
Agora, vamos instalar as ferramentas necessárias para baixar os arquivos do modelo com eficiência.
Primeiro, instale o pacote Hugging Face Hub com suporte a hf_xet, junto com o auxiliar hf-xet:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetDepois, instale o hf_transfer para acelerar o download de modelos grandes:
pip -q install -U hf_transferEm seguida, ative transferências de alta performance para baixar mais rápido:
export HF_XET_HIGH_PERFORMANCE=1Por fim, baixe os arquivos do GLM 5.1 para uma pasta local:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Mesmo essa versão menor ainda é um download grande. No meu setup, o modelo de 2 bits levou cerca de 17 minutos, então não se preocupe se demorar um pouco.

Agora é hora de iniciar o servidor local e carregar o modelo na memória.
Rode o comando a seguir:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfO principal argumento aqui é --fit on. Ele instrui o servidor a colocar automaticamente o máximo possível do modelo na GPU, descarregando o restante para a RAM do sistema. Isso é especialmente útil neste setup, pois ajuda a rodar um modelo muito grande aproveitando os 80GB de VRAM e os 125GB de RAM sem precisar gerenciar manualmente a alocação de camadas.
Os outros argumentos cuidam do nome do servidor, porta, ajustes de performance, batching e tamanho de contexto para a inferência.
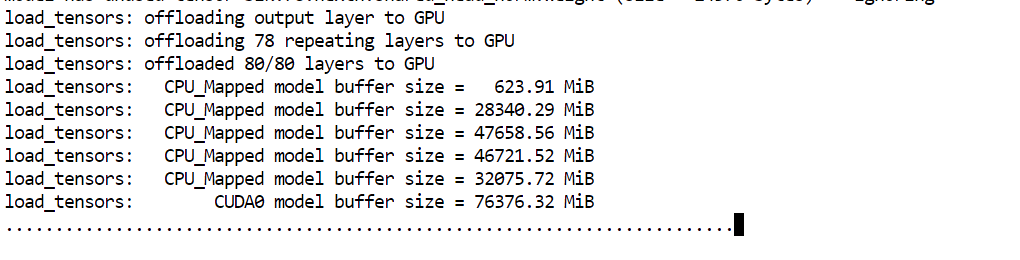
Quando o modelo terminar de carregar, você verá a mensagem informando que o servidor está ouvindo em: http://0.0.0.0:8910.

Pronto: o GLM 5.1 está rodando localmente e pronto para testes no próximo passo.
Com o servidor rodando, o próximo passo é garantir que o modelo está respondendo corretamente via API local.
Abra um novo terminal no JupyterLab para manter o servidor ativo no terminal original. Em seguida, envie um teste simples com curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Essa requisição envia um prompt ao seu servidor local do GLM 5.1 e pede uma resposta curta. Os pontos principais aqui são a URL do servidor local, o nome do modelo e o formato de messages usado no corpo da requisição.
Se tudo estiver certo, o terminal vai retornar um JSON com a saída do modelo.

Com a API local funcionando, o próximo passo é conectá-la ao OpenAI Python SDK. Isso é útil porque muitos apps e scripts já usam o cliente da OpenAI; apontá-lo para o seu servidor local do GLM 5.1 facilita muito a integração.
Primeiro, atualize o pip e instale o pacote OpenAI:
python -m pip install --upgrade pip
pip install openaiDepois, rode um script Python curto que conecta o SDK ao seu servidor local:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYO ponto principal é que não estamos chamando a API em nuvem da OpenAI. Estamos usando o mesmo SDK, mas mudando o base_url para apontar para o servidor local do GLM 5.1 rodando na porta 8910.
Se tudo estiver configurado corretamente, a saída deve ser:
CanberraA versão mais recente do servidor llama.cpp também inclui um WebUI integrado, o que permite interagir com seu GLM 5.1 local por uma interface de chat simples, e não apenas pelo terminal ou chamadas de API.
Para abrir, volte ao seu dashboard do RunPod e abra a aba Connect do seu pod. Como a porta 8910 já está exposta, clique no link de HTTP Service dessa porta. Isso vai abrir o WebUI do llama.cpp em uma nova aba do navegador.
Assim que a página carregar, você já pode começar a conversar com o modelo. Digite seu primeiro prompt e a resposta deve aparecer em alguns segundos. No meu setup, o modelo gerava em cerca de 8 tokens por segundo, uma velocidade sólida para um modelo desse porte.
Para um teste rápido, peça para criar um app Hello World simples. Ele gerou exemplos funcionais em várias linguagens populares.
Com o GLM 5.1 rodando localmente, o próximo passo é conectá-lo ao Claude Code. Esse é um teste útil, pois o GLM 5.1 é apresentado como um forte modelo para coding; usá-lo em um fluxo de agente para desenvolvimento dá uma noção melhor de como ele atua em tarefas reais.
Start instalando o Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Depois, adicione o Claude Code ao PATH do shell para que o comando claude funcione no terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcEm seguida, configure o Claude Code para apontar para o seu servidor local do GLM 5.1 em vez da API hospedada da Anthropic:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFDepois, recarregue sua configuração do shell para aplicar essas variáveis de ambiente:
source ~/.bashrcAgora, crie uma pasta de teste e inicie o Claude Code dentro dela:
mkdir -p test-claude-local
cd test-claude-local
claudeNa primeira execução, o Claude Code pode pedir alguns passos de setup, como escolher um tema ou confiar no diretório de trabalho. Depois disso, você já pode passar tarefas.
Para um primeiro teste simples, tente este prompt:
Build the simple Hello World app in Python
Isso permite verificar se o Claude Code está enviando requisições ao seu servidor local do GLM 5.1 e usando-o para gerar código.
Na minha experiência, essa configuração funcionou, mas ficou visivelmente mais lenta do que nos testes anteriores.
Com prompts mais longos e estilo de coding, a velocidade caiu para cerca de 2 tokens por segundo, e o modelo frequentemente gastou muito tempo raciocinando antes de produzir respostas simples.
Esse é um dos principais trade-offs que notei com o GLM 5.1 nesse fluxo: ele é capaz, mas pode ser mais lento e verboso do que você deseja para tarefas leves de coding.
Esta seção cobre alguns problemas comuns ao rodar o GLM 5.1 localmente e como resolvê-los rapidamente.
Geralmente significa que o modelo é grande demais para a GPU e memória disponíveis. Tente uma quantização menor ou reduza o contexto. O llama.cpp também suporta --fit on, que ajuda a ajustar automaticamente o modelo na memória disponível.
Confirme se você está abrindo a porta exposta correta no RunPod e não a URL do JupyterLab. O servidor do llama.cpp inclui seu próprio WebUI; portanto, é a porta do servidor que importa, e a URL deve apontar para 0.0.0.0:8910 no serviço HTTP exposto.
Geralmente é desencontro de base URL ou endpoint. O llama.cpp suporta rotas compatíveis com OpenAI e com Anthropic Messages, então verifique se sua ferramenta aponta para o caminho correto, como /v1 ou /v1/messages.
Isso pode acontecer porque a performance depende tanto do cliente quanto do comportamento do modelo no backend. O Claude Code permite ajustes por configurações e variáveis de ambiente, mas respostas lentas geralmente se devem ao tempo maior de raciocínio ou geração do modelo.
Janelas de contexto maiores e gerações longas aumentam a pressão de memória e o tempo de resposta. Reduzir o tamanho do contexto, o comprimento do prompt ou os parâmetros de geração ajuda a melhorar a velocidade em setups locais.
No geral, configurar o GLM 5.1 localmente foi bem direto. Baixar o modelo, subir o servidor e testá-lo para usos básicos não exigiu muito esforço. Para experimentos locais simples, o processo é bem tranquilo.
O desafio aparece quando você quer usá-lo para fluxos de coding com agentes. Isso exige mais RAM e VRAM, e a geração de tokens pode desacelerar bastante conforme a janela de contexto enche. Mesmo que o modelo pareça rápido no começo, o thinking mode adiciona muita latência; para uso local, muitas vezes faz mais sentido desativá-lo se a velocidade for importante.
Além da performance, há o lado prático. Rodar um modelo local significa gerenciar o servidor do modelo, configurar a GPU e lidar com infraestrutura por conta própria. Fica mais difícil quando plataformas de aluguel de GPU como RunPod ou Vast.ai têm disponibilidade limitada, algo cada vez mais comum com a demanda em alta.
Por isso, em muitos casos, uma API gerenciada pode ser a melhor escolha. Você abre mão de um pouco de privacidade e controle, mas ganha velocidade, menos manutenção e uma experiência muito mais suave para tarefas de coding maiores ou mais complexas. Se o custo for de alguns dólares por mês, pode valer muito a pena em comparação a gerenciar tudo sozinho.
Então, se seu objetivo é experimentar, aprender ou rodar o GLM 5.1 em tarefas locais leves, rodá-lo localmente é uma boa opção. Mas se você busca coding com agentes de forma confiável e em escala, um serviço gerenciado costuma ser o caminho mais prático. Para uma comparação detalhada, recomendo conferir nosso guia GLM-5 vs GPT-5.3-Codex.
Cursos de IA com agentes
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Moez Ali


