
Leerpad
Basisprincipes van AI-agenten
6 Hr
GLM 5.1 is een van de sterkste open modellen die je vandaag kunt draaien, en Artificial Analysis beschrijft het momenteel als het leidende open-weights-model op zijn Intelligence Index. Z.ai positioneert het ook als een vlaggenschiprelease voor coderen, redeneren en agentische workflows.
Bron: AI Model & API Providers Analysis | Artificial Analysis
Het lokaal draaien geeft je meer controle over de volledige workflow. Je data blijft in je eigen omgeving, en je kunt prompts testen, integraties bouwen en het gebruiken in codeprojecten met meer privacy en minder zorgen over blootstelling van externe data.
In deze tutorial richt je een H100 RunPod-omgeving in, draai je GLM 5.1 lokaal, test je het met API-calls, koppel je het aan de OpenAI Python SDK, krijg je er toegang toe via een WebUI en integreer je het met Claude Code.
Begin door naar het Pods-tabblad in RunPod te gaan en een H100 SXM-machine te selecteren. Kies voor de template de nieuwste PyTorch-optie, zodat je een kant-en-klare omgeving hebt voor het draaien van modelworkloads.
Werk vóór het deployen de podopslag-instellingen bij. Zet de containerdisk op 100GB en de volumedisk op 300GB zodat je genoeg ruimte hebt voor de modelbestanden, dependencies en gecachte downloads.
We doen al het werk in de aangekoppelde map /workspace zodat alles op één plek blijft. Je moet ook poort 8910 openzetten, die we gebruiken voor zowel de lokale modelserver als de llama.cpp WebUI.
Voeg vervolgens je Hugging Face-token toe als een omgevingsvariabele met de naam HF_TOKEN.
Zodra dat is ingesteld, bekijk je de podsamenvatting en klik je op Deploy On-Demand. Open na het starten van de pod de JupyterLab-instantie die eraan is gekoppeld.
Start binnen JupyterLab een nieuwe terminal en voer de volgende commando’s uit om de vereiste systeempakketten te installeren:
apt-get update
apt-get install -y pciutils build-essential cmake curl git tmux libcurl4-openssl-dev
Nu de pod klaar is, is de volgende stap om llama.cpp te bouwen met CUDA-ondersteuning zodat de H100-GPU kan worden gebruikt voor lokale inferentie.
Clone eerst de llama.cpp-repository van GitHub:
git clone https://github.com/ggml-org/llama.cppConfigureer vervolgens de build en plaats de gegenereerde buildbestanden in een aparte map build:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
Compileer daarna de hoofd-binaries die we nodig hebben in geoptimaliseerde Release-modus:
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split
Kopieer ten slotte de gecompileerde binaries naar de hoofdmap van llama.cpp zodat ze later makkelijker uit te voeren zijn:
cp llama.cpp/build/bin/llama-* llama.cppAan het einde van deze stap heb je de belangrijkste llama.cpp-tools klaar, waaronder llama-server, die we later gebruiken om GLM 5.1 lokaal te draaien.
Voordat we het model downloaden, is het handig om te begrijpen waarom we voor deze setup de 2-bitversie gebruiken.
Het volledige GLM 5.1-model heeft 744B parameters, met 40B actieve parameters, een 200K contextvenster, en vereist ongeveer 1,65 TB schijfruimte. Dat is veel te groot voor een praktische lokale setup.
De Unsloth Dynamic 2-bit GGUF-versie verkleint de grootte tot ongeveer 220–236 GB, waardoor de opslagbehoefte met ongeveer 80% wordt teruggebracht, terwijl belangrijke lagen in hogere precisie behouden blijven voor betere prestaties.
Dat maakt het 2-bitmodel de juiste keuze voor onze hardware. Met 80 GB VRAM en 125 GB RAM is deze gekwantiseerde versie nog steeds veeleisend qua resources, maar veel realistischer lokaal te draaien en levert het nog steeds sterke prestaties voor coding- en agentische workflows.
Laten we nu de tools installeren die nodig zijn om de modelbestanden efficiënt te downloaden.
Installeer eerst het Hugging Face Hub-pakket met hf_xet-ondersteuning, samen met de hf-xet helper:
pip -q install -U "huggingface_hub[hf_xet]" hf-xetInstalleer vervolgens hf_transfer om grote modeldownloads te versnellen:
pip -q install -U hf_transferSchakel daarna high-performance transfers in voor snellere downloads:
export HF_XET_HIGH_PERFORMANCE=1Download ten slotte de GLM 5.1-modelbestanden naar een lokale map:
hf download unsloth/GLM-5.1-GGUF \
--local-dir models/GLM-5.1-GGUF \
--include "*UD-IQ2_M*"Zelfs deze kleinere versie is nog steeds een grote download. In mijn setup duurde het ongeveer 17 minuten voor het 2-bitmodel, dus maak je geen zorgen als het even duurt.

Tijd om de lokale server te starten en het model in het geheugen te laden.
Voer het volgende commando uit:
./llama.cpp/llama-server \
--model ./models/GLM-5.1-GGUF/UD-IQ2_M/GLM-5.1-UD-IQ2_M-00001-of-00006.gguf \
--alias "GLM-5.1" \
--host 0.0.0.0 \
--port 8910 \
--jinja \
--fit on \
--threads 16 \
--threads-batch 16 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--flash-attn on \
--temp 0.7 \
--top-p 0.95 \
--cont-batching \
--metrics \
--perfHet belangrijkste argument om hier op te letten is --fit on. Dit vertelt de server om automatisch zoveel mogelijk van het model op de GPU te plaatsen, terwijl de rest naar het systeemsgeheugen wordt offload. Dat is vooral nuttig in onze setup, omdat het helpt een zeer groot model te draaien over de beschikbare 80 GB VRAM en 125 GB RAM zonder handmatig de laagplaatsing te hoeven regelen.
De andere argumenten regelen vooral de servernaam, poort, prestatie-instellingen, batching en contextlengte voor inferentie.
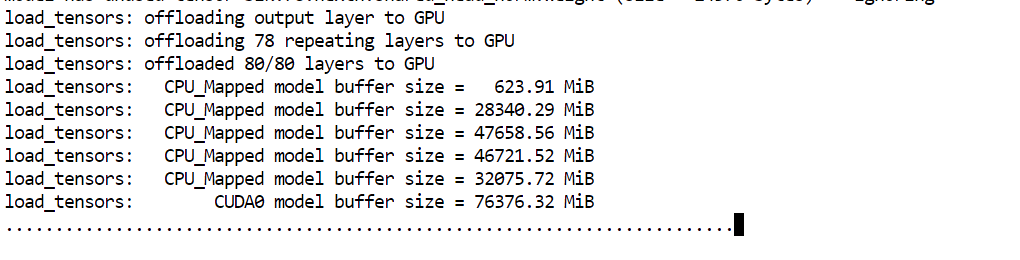
Zodra het model klaar is met laden, zie je een bericht dat de server luistert op: http://0.0.0.0:8910.

Op dat moment draait GLM 5.1 lokaal en is het klaar om te testen in de volgende stap.
Met de server draaiende is de volgende stap controleren of het model correct reageert via de lokale API.
Open een nieuwe terminal in JupyterLab zodat de server kan blijven draaien in de oorspronkelijke terminal. Stuur daarna een simpele testaanvraag met curl:
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: local-test" \
-d '{
"model": "GLM-5.1",
"max_tokens": 300,
"messages": [
{"role": "user", "content": "Write a Python hello world function."}
]
}'Deze request stuurt een prompt naar je lokaal draaiende GLM 5.1-server en vraagt om een kort antwoord te genereren. De belangrijkste punten hier zijn de lokale server-URL, de modelnaam en het messages-formaat in de requestbody.
Als alles goed werkt, geeft de terminal een JSON-response terug met de output van het model.

Nu de lokale API werkt, is de volgende stap om deze te koppelen aan de OpenAI Python SDK. Dit is handig omdat veel bestaande apps en scripts al de OpenAI-client gebruiken, dus deze naar je lokale GLM 5.1-server laten wijzen maakt integratie veel eenvoudiger.
Upgrade eerst pip en installeer het OpenAI-pakket:
python -m pip install --upgrade pip
pip install openaiVoer vervolgens een kort Python-script uit dat de SDK met je lokale server verbindt:
python - <<'PY'
from openai import OpenAI
client = OpenAI(
api_key="local-key",
, base_url="http://127.0.0.1:8910/v1",
)
resp = client.completions.create(
model="GLM-5.1",
prompt="Answer briefly and in plain text only.\n\nQuestion: What is the capital city of Australia?\nAnswer:",
temperature=0.2,
max_tokens=12,
)
print(resp.choices[0].text.strip())
PYHet belangrijkste hier is dat we niet de OpenAI cloud-API aanroepen. We gebruiken dezelfde SDK, maar veranderen de base_url zodat deze wijst naar de lokale GLM 5.1-server die draait op poort 8910.
Als alles correct is ingesteld, zou de output moeten zijn:
CanberraDe nieuwste llama.cpp-server bevat ook een ingebouwde WebUI, wat betekent dat je met je lokale GLM 5.1-model kunt praten via een eenvoudige chatinterface in plaats van alleen via de terminal of API-calls.
Om deze te openen, ga je terug naar je RunPod-dashboard en open je het tabblad Connect voor je pod. Omdat poort 8910 al is blootgelegd, klik je op de link HTTP Service voor die poort. Dit opent de llama.cpp WebUI in een nieuw browsertabblad.
Zodra de pagina is geladen, kun je direct met het model chatten. Typ je eerste prompt, en binnen enkele seconden zou het antwoord moeten verschijnen. In mijn setup genereerde het model met ongeveer 8 tokens per seconde, wat een prima snelheid is voor een model van deze grootte.
Voor een snelle test kun je vragen om een eenvoudige Hello World-app te bouwen. Het genereerde werkende voorbeelden in verschillende populaire programmeertalen.
Nu GLM 5.1 lokaal draait, is de volgende stap om het te verbinden met Claude Code. Dit is een nuttige test omdat GLM 5.1 gepositioneerd is als een sterk codemodel, dus het gebruiken binnen een coding-agentworkflow geeft een beter beeld van hoe het presteert op echte ontwikkeltaken.
Start met het installeren van Claude Code:
curl -fsSL https://claude.ai/install.sh | bash
Voeg daarna Claude Code toe aan je shell-PATH zodat het claude-commando werkt vanuit de terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrcConfigureer daarna Claude Code zodat het wijst naar je lokale GLM 5.1-server in plaats van de gehoste Anthropic API:
cat >> ~/.bashrc <<'EOF'
export ANTHROPIC_BASE_URL="http://127.0.0.1:8910"
export ANTHROPIC_AUTH_TOKEN="local-dev-token"
export ANTHROPIC_MODEL="GLM-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-5.1"
export API_TIMEOUT_MS=1200000
EOFLaad vervolgens je shellconfiguratie opnieuw zodat die omgevingsvariabelen van kracht worden:
source ~/.bashrcMaak nu een testmap en start Claude Code erin:
mkdir -p test-claude-local
cd test-claude-local
claudeDe eerste keer dat Claude Code start, kan het vragen om een paar setupstappen te voltooien, zoals het kiezen van een thema of het vertrouwen van de werkmap. Zodra dat klaar is, kun je taken gaan geven.
Probeer voor een eenvoudige eerste test deze prompt:
Build the simple Hello World app in Python
Hiermee kun je controleren of Claude Code succesvol requests naar je lokale GLM 5.1-server stuurt en deze gebruikt voor codegeneratie.
In mijn ervaring werkte deze setup, maar het was merkbaar trager dan de eerdere tests.
Bij langere context en prompts in codestijl daalde de genereersnelheid naar ongeveer 2 tokens per seconde, en het model besteedde vaak te veel tijd aan redeneren voordat het zelfs maar eenvoudige antwoorden gaf.
Dat is een van de belangrijkste trade-offs die ik merkte met GLM 5.1 in deze workflow: het is capabel, maar kan trager en uitgebreider zijn dan je zou willen voor lichte codingtaken.
In deze sectie behandelen we een paar veelvoorkomende problemen die je kunt tegenkomen bij het lokaal draaien van GLM 5.1 en hoe je ze snel oplost.
Dit betekent meestal dat het model te groot is voor het beschikbare GPU- en systeemgeheugen, dus probeer een kleinere quant of verlaag de contextgrootte. llama.cpp ondersteunt ook --fit on, wat helpt om het model automatisch over het beschikbare geheugen te verdelen.
Zorg dat je de juiste blootgestelde poort vanuit RunPod opent en niet de JupyterLab-URL. De llama.cpp-server bevat een eigen ingebouwde WebUI, dus de serverpoort is wat telt en de URL moet verwijzen naar 0.0.0.0:8910 op de blootgestelde HTTP-service.
Dit is meestal een mismatch in basis-URL of endpoint. llama.cpp ondersteunt OpenAI-compatibele routes en Anthropic Messages-compatibele routes, dus controleer of je tool naar het juiste pad wijst, zoals /v1 of /v1/messages.
Dit kan gebeuren omdat de performance afhangt van zowel de client als het gedrag van het backendmodel. Claude Code ondersteunt configuratie via instellingen en omgevingsvariabelen, maar tragere responses worden vaak veroorzaakt doordat het model langer nodig heeft om te redeneren of te genereren.
Langere contextvensters en grotere generaties vergroten de geheugendruk en responstijd. Het verkleinen van de contextgrootte, promptlengte of generatie-instellingen kan helpen om de snelheid in lokale setups te verbeteren.
Al met al was het opzetten van GLM 5.1 lokaal vrij eenvoudig. Het model downloaden, de server draaien en het testen voor basaal gebruik kostte niet veel moeite. Voor simpele lokale experimenten voelt het proces goed behapbaar.
De grootste uitdaging begint wanneer je het wilt gebruiken voor agentische codingworkflows. Dat vereist meer RAM en VRAM, en de tokensnelheid kan merkbaar dalen naarmate het contextvenster volloopt. Ook al kan het model in het begin snel aanvoelen, thinking mode voegt veel vertraging toe, dus voor lokaal gebruik is het vaak logischer om thinking mode uit te zetten als snelheid belangrijk is.
Naast performance is er ook de praktische kant. Een lokaal model draaien betekent zelf de modelserver beheren, GPU-setup regelen en met infrastructuurproblemen omgaan. Het wordt ook lastiger wanneer GPU-verhuurplatforms zoals RunPod of Vast.ai beperkte beschikbaarheid hebben, wat door de groeiende vraag vaker voorkomt.
Daarom kan in veel gevallen een beheerde API-optie de betere keuze zijn. Je levert wat privacy en controle in, maar je krijgt betere snelheid, minder onderhoud en een veel soepelere ervaring voor grotere of complexere codingtaken. Als de kosten slechts een paar dollar per maand zijn, kan dat een waardevolle ruil zijn vergeleken met alles zelf beheren.
Dus als je doel is om te experimenteren, te leren of GLM 5.1 te draaien voor lichtere lokale taken, is lokaal draaien een goede optie. Maar als je doel betrouwbare agentische coding op schaal is, is een beheerde service vaak het praktischere pad. Voor een gedetailleerde vergelijking raad ik onze gids GLM-5 vs GPT-5.3-Codex aan.
Agentic AI-cursussen
Leerpad
Cursus
Cursus