
Program
Dasar-Dasar Pembelajaran Mesin dalam Python
16 Hr
Structural equation modeling (SEM) memungkinkan kita menyelidiki hubungan kausal antar variabel dan memahami bagaimana masing-masing berkontribusi terhadap kinerja keseluruhan. SEM adalah alat yang kuat yang menggabungkan analisis faktor dan analisis regresi berganda untuk menganalisis hubungan antar banyak variabel. Ini agak mirip dengan bagaimana, dalam kehidupan sehari-hari, kita mempertimbangkan bagaimana faktor seperti postur, kepercayaan diri, dan keterampilan komunikasi secara kolektif memengaruhi sesuatu seperti performa saat wawancara.
Sekarang mari kita jelajahi SEM, penerapannya, dan contoh praktisnya di Python. Jika Anda baru pada beberapa gagasan inti, seperti konsep faktor laten, Anda juga dapat mencoba kursus Analisis Faktor kami.
Structural equation modeling merepresentasikan hubungan kausal antara variabel laten dan variabel teramati. Variabel teramati adalah yang dapat kita ukur secara langsung. Konstruk laten disimpulkan dan tidak diukur secara langsung.
Untuk menangkap hubungan ini secara efektif, SEM dibagi menjadi dua komponen utama: model pengukuran dan model struktural. Model pengukuran menetapkan hubungan antara variabel teramati dan variabel laten yang sesuai, sedangkan model struktural menetapkan hubungan antar variabel laten.
Teknik statistik seperti korelasi dan regresi kurang efisien untuk mempelajari hubungan multivariat yang kompleks. SEM cocok untuk memodelkan konstruk yang kompleks dan multidimensi yang diukur dengan kesalahan. Ini juga berguna karena membantu menspesifikasikan suatu sistem hubungan. Metode tradisional membantu kita mempelajari satu variabel independen dan sekumpulan prediktor. Meskipun korelasi bukanlah kausalitas, SEM membantu kita memahami hubungan kausal antara variabel teramati dan konstruk laten.
Beberapa penerapan SEM meliputi:
Berikut beberapa konsep inti dalam structural equation modeling:
Meskipun SEM sangat baik untuk memodelkan hubungan kausal, ada beberapa asumsi yang mendasari pada data. Asumsinya meliputi:
Ada berbagai jenis structural equation modeling. Tanpa urutan tertentu, di antaranya:
Mengembangkan model SEM di Python hanya memerlukan beberapa langkah; kita dapat menggunakan pustaka semopy untuk memudahkannya. Tutorial berikut mengasumsikan bahwa Anda familiar dengan sintaks Python.
pip install semopyCatatan: Untuk pengguna macOS. Jika Anda menemui error ini saat menginstal paket:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstal graphviz melalui homebrew di terminal Anda
brew install graphvizSebelum kita mengunduh dataset dan membuat model, mari luangkan waktu sejenak untuk mendefinisikan semua konstruk kita. Artinya, kita perlu mengidentifikasi variabel laten dan teramati. Dalam kasus dataset kita, variabel teramati telah disediakan kepada kita sebagai fitur berlabel yaitu x1 hingga x3 dan y1 hingga y8. Variabel laten yang ingin kita pelajari memiliki nama berikut, yang akan kita jelaskan: ind60, dem60, dem65.
y1: kebebasan pers, 1960
y2: kebebasan oposisi politik, 1960
y3: keadilan pemilu, 1960
y4: efektivitas badan legislatif terpilih, 1960
y5 -y8: merupakan variabel yang sama dengan y1-y4, masing-masing, diukur pada 1965
x1: PNB per kapita, 1960
x2: konsumsi energi per kapita, 1960
x3: persentase angkatan kerja di industri, 1960
ind60: variabel laten eksogen tentang industrialisasi.
dem60: variabel laten endogen tentang demokrasi pada 1960.
dem65: variabel laten endogen tentang demokrasi pada 1965.
Tujuannya adalah mendefinisikan model teoretis untuk menspesifikasikan hubungan antara konstruk laten dan variabel teramati.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Di sini, kita akan menspesifikasikan hubungan antar konstruk laten itu sendiri.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Di sini, kita ingin menspesifikasikan variabel-variabel yang berkorelasi tinggi satu sama lain.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Untuk tutorial ini, kita akan menggunakan dataset PoliticalDemocracy.csv yang disediakan oleh semopy. Anda dapat mengunduhnya dengan mengunjungi repositori GitHub ini.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Kita perlu menggabungkan definisi struktural dan pengukuran ke dalam sebuah spesifikasi model.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Selanjutnya, kita mendefinisikan model dan menyesuaikannya pada data
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Kita akan memplot hasil model untuk memahami representasi jalur. Plot akan disimpan sebagai political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()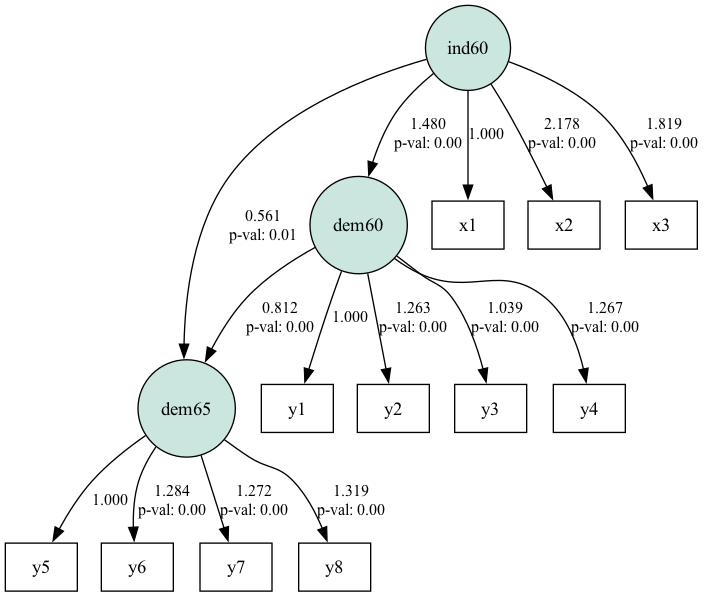
Diagram jalur SEM untuk dataset demokrasi politik. Sumber: Gambar oleh Penulis
Diagram menunjukkan bagaimana jalur menghubungkan konstruk laten (dalam lingkaran) dan variabel teramati. Koefisien jalur yang mendekati 1 atau -1 menunjukkan hubungan yang kuat antar variabel dan yang mendekati 0 menunjukkan hubungan yang lemah.
Simpangan baku dalam tabel berada dalam kisaran yang wajar. Nilai yang lebih besar dapat mengindikasikan multikolinearitas atau kesalahan spesifikasi model. Nilai p menentukan signifikansi statistik koefisien jalur. Nilai p kurang dari 0,05 biasanya menunjukkan bahwa jalur tersebut signifikan secara statistik. Kita melihat 2 kasus di mana nilai p lebih besar dari 0,05.
Secara keseluruhan, hasilnya menunjukkan bahwa ind60 berpengaruh signifikan terhadap dem60, yang pada gilirannya berpengaruh signifikan terhadap dem65.
Model yang dihipotesiskan harus sesuai dengan hubungan yang teramati untuk menilai kelayakan model SEM. Berbagai indeks kelayakan digunakan untuk menilai seberapa baik model sesuai dengan data. Berikut beberapa yang umum digunakan:
Beberapa tantangan umum dari teknik structural equation modeling meliputi hal-hal berikut:
Dalam artikel ini, kita meninjau SEM secara mendalam, termasuk penerapan, implementasi, kelebihan, dan keterbatasannya. SEM adalah alat yang kuat untuk menguji hubungan kompleks dan interaksi kausal antara variabel teramati dan laten. Anda sebaiknya mencobanya di Python atau R untuk proyek analisis berikutnya.
Jika Anda tertarik pada gagasan structural equation modeling tetapi lebih menyukai R, Anda dapat mengambil kursus Structural Equation Modeling with lavaan in R, yang memiliki petunjuk langkah demi langkah yang terperinci. Anda juga dapat memulai jalur karier Statistician in R. Jika Anda berkomitmen pada Python, bacalah dokumentasi semopy untuk lebih banyak use case SEM di Python. Terakhir, jika Anda tertarik pada model Python tingkat lanjut yang sekaligus memprediksi dan menjelaskan, serta mengeksplorasi gagasan arsitektur model dan pemilihan fitur, coba jalur karier Machine Learning Scientist in Python kami.
Belajar bersama DataCamp
Program
Program
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
