
Programa
Fundamentos de machine learning Em Python
16 h
A modelagem de equações estruturais (SEM) nos permite investigar as relações causais entre as variáveis e entender como cada uma delas contribui para o desempenho geral. O SEM é uma ferramenta poderosa que combina análise fatorial e análise de regressão múltipla para analisar as relações entre diversas variáveis. Isso é um pouco semelhante a como, em nossa vida diária, consideramos como fatores como postura, confiança e habilidades de comunicação afetam coletivamente algo como o desempenho em uma entrevista.
Vamos agora explorar o SEM, seus aplicativos e exemplos práticos em Python. Se você não conhece algumas das ideias centrais, como a ideia de fatores latentes, também pode experimentar nosso curso de análise de fatores.
A modelagem de equações estruturais representa as relações causais entre variáveis latentes e observadas. As variáveis observadas são o que podemos medir diretamente. Os construtos latentes são inferidos e não medidos diretamente.
Para capturar efetivamente essas relações, o SEM é dividido em dois componentes principais: o modelo de medição e o modelo estrutural. O modelo de medição especifica as relações entre as variáveis observadas e suas variáveis latentes correspondentes, enquanto o modelo estrutural especifica as relações entre as variáveis latentes.
Técnicas estatísticas como correlação e regressão são ineficientes no estudo de relações multivariadas complexas. O SEM é adequado para modelar construções complexas e multifacetadas que são medidas com erro. Também é útil porque ajuda a especificar um sistema de relacionamentos. Os métodos tradicionais nos ajudam a estudar uma variável independente e um conjunto de preditores. Embora correlação não seja causalidade, o SEM nos ajuda a entender a relação causal entre a variável observada e os construtos latentes.
Algumas das aplicações do SEM incluem:
Aqui estão alguns dos principais conceitos da modelagem de equações estruturais:
Embora o SEM seja ótimo para modelar relações casuais, ele tem algumas suposições subjacentes sobre os dados. As premissas incluem:
Há diferentes tipos de modelagem de equações estruturais. Em nenhuma ordem específica, eles são:
O desenvolvimento de um modelo SEM em Python requer apenas algumas etapas; podemos usar a biblioteca semopy para facilitar esse processo. O tutorial a seguir pressupõe que você esteja familiarizado com a sintaxe do Python.
pip install semopyObservação: Para usuários do macOS. Se você encontrar esse erro ao instalar o pacote:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstale o graphviz por meio do homebrew em seu terminal
brew install graphvizAntes de baixarmos o conjunto de dados e criarmos o modelo, vamos dedicar um minuto para definir todos os construtos. Ou seja, precisaremos identificar as variáveis latentes e observadas. No caso de nosso conjunto de dados, as variáveis observadas foram fornecidas a nós como recursos rotulados e são x1 a x3 e y1 a y8. As variáveis latentes que queremos estudar têm estes nomes, que explicaremos: ind60, dem60, dem65.
y1: liberdade de imprensa, 1960
y2: liberdade de oposição política, 1960
y3: imparcialidade das eleições, 1960
y4: eficácia da legislatura eleita, 1960
y5 -y8: são as mesmas variáveis que y1-y4, respectivamente, medidas em 1965
x1: o PNB per capita, 1960
x2: o consumo de energia per capita, 1960
x3: a porcentagem da força de trabalho na indústria, 1960
ind60variável latente exógena na industrialização.
dem60variável latente endógena sobre democracia em 1960.
dem65variável latente endógena sobre democracia em 1965.
O objetivo é definir um modelo teórico para especificar a relação entre os construtos latentes e as variáveis observadas.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Aqui, especificaremos as relações entre os próprios construtos latentes.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Aqui, queremos especificar as variáveis que são altamente correlacionadas entre si.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Para este tutorial, usaremos o conjunto de dados PoliticalDemocracy.csv fornecido por semopy. Você pode baixá-lo visitando este repositório do GitHub.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Precisamos combinar as definições estruturais e de medição em uma especificação de modelo.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Em seguida, definimos o modelo e ajustamos os dados
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Vamos plotar o resultado do modelo para entender a representação do caminho. O gráfico será salvo como political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()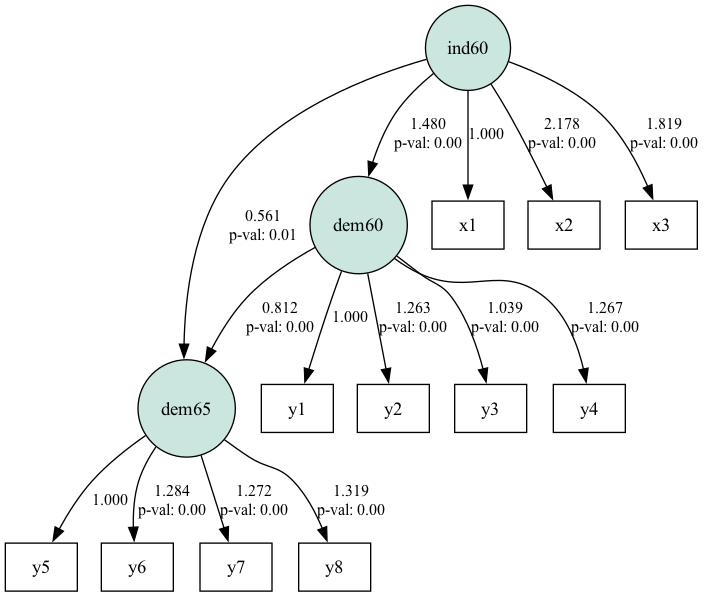
Diagrama de caminho SEM para o conjunto de dados de democracia política. Fonte: Imagem do autor
O diagrama mostra como o caminho relaciona os construtos latentes (em círculos) e as variáveis observadas. Os coeficientes de caminho mais próximos de 1 ou -1 mostram relações fortes entre as variáveis e os próximos de 0 mostram relações fracas.
Os desvios padrão na tabela estão dentro do intervalo. Valores maiores podem indicar multicolinearidade ou má especificação do modelo. Os valores de p determinam a significância estatística dos coeficientes de caminho. Um valor de p menor que 0,05 geralmente indica que o caminho é estatisticamente significativo. Vemos dois casos em que o valor de p é maior que 0,05.
Em suma, os resultados mostram que o site ind60 influencia significativamente o site dem60, que, por sua vez, influencia significativamente o site dem65.
O modelo hipotético deve corresponder às relações observadas para avaliar a adequação do modelo SEM. Vários índices de ajuste são usados para avaliar a adequação do modelo aos dados. Aqui estão os comumente usados:
Alguns desafios comuns da técnica de modelagem de equações estruturais são os seguintes:
Neste artigo, analisamos o SEM em profundidade, incluindo suas aplicações, implementação, vantagens e limitações. O SEM é uma ferramenta poderosa para examinar relações complexas e interações causais entre variáveis observadas e latentes. Você deve experimentá-lo em Python ou R em seu próximo projeto de análise.
Se você estiver interessado na ideia de modelagem de equações estruturais, mas preferir o R, poderá fazer o curso Structural Equation Modeling with lavaan in R, que tem instruções detalhadas passo a passo. Você também pode embarcar na carreira de Estatístico em R. Se você estiver comprometido com o Python, leia a documentação do semopy para obter mais casos de uso do SEM no Python. Por fim, se você estiver interessado em modelos avançados em Python que preveem e explicam, e em explorar ideias de arquitetura de modelos e seleção de recursos, experimente nossa carreira de Cientista de Aprendizado de Máquina em Python.
Aprenda com a DataCamp
Programa
Programa
Curso
Tutorial
Sejal Jaiswal
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Tutorial
DataCamp Team
Tutorial
Avinash Navlani


