
Lernpfad
Grundlagen des maschinellen Lernens in Python
16 Std.
Mit der Strukturgleichungsmodellierung (SEM) können wir die kausalen Beziehungen zwischen den Variablen untersuchen und verstehen, wie jede einzelne zur Gesamtleistung beiträgt. Die SEM ist ein leistungsstarkes Instrument, das die Faktorenanalyse und die multiple Regressionsanalyse kombiniert, um die Beziehungen zwischen mehreren Variablen zu analysieren. Das ist in etwa so, wie wir in unserem täglichen Leben berücksichtigen, wie sich Faktoren wie Körperhaltung, Selbstvertrauen und Kommunikationsfähigkeiten zusammen auf die Leistung bei einem Vorstellungsgespräch auswirken.
Jetzt wollen wir uns mit SEM, seinen Anwendungen und praktischen Beispielen in Python beschäftigen. Wenn dir einige der zentralen Ideen, wie z. B. die Idee der latenten Faktoren, neu sind, kannst du auch unseren Kurs zur Faktorenanalyse ausprobieren.
Die Strukturgleichungsmodellierung stellt die kausalen Beziehungen zwischen latenten und beobachteten Variablen dar. Die beobachteten Variablen sind das, was wir direkt messen können. Latente Konstrukte werden abgeleitet und nicht direkt gemessen.
Um diese Beziehungen effektiv zu erfassen, wird die SEM in zwei Hauptkomponenten unterteilt: das Messmodell und das Strukturmodell. Das Messmodell beschreibt die Beziehungen zwischen den beobachteten Variablen und ihren entsprechenden latenten Variablen, während das Strukturmodell die Beziehungen zwischen den latenten Variablen beschreibt.
Statistische Verfahren wie Korrelation und Regression sind bei der Untersuchung komplexer multivariater Beziehungen ineffizient. Die SEM eignet sich für die Modellierung komplexer, vielschichtiger Konstrukte, die mit Fehlern gemessen werden. Es ist auch nützlich, weil es hilft, ein System von Beziehungen zu definieren. Traditionelle Methoden helfen uns, eine unabhängige Variable und eine Reihe von Prädiktoren zu untersuchen. Obwohl Korrelation nicht gleichbedeutend mit Kausalität ist, hilft uns die SEM, die kausale Beziehung zwischen der beobachteten Variable und den latenten Konstrukten zu verstehen.
Einige der Anwendungen von SEM sind:
Hier sind einige der wichtigsten Konzepte der Strukturgleichungsmodellierung:
Die SEM eignet sich zwar hervorragend für die Modellierung zufälliger Beziehungen, aber sie geht von einigen Annahmen über die Daten aus. Zu den Annahmen gehören:
Es gibt verschiedene Arten der Strukturgleichungsmodellierung. In keiner bestimmten Reihenfolge sind sie das:
Die Entwicklung eines SEM-Modells in Python erfordert nur wenige Schritte; wir können die Bibliothek semopy verwenden, um es einfach zu machen. Das folgende Tutorial setzt voraus, dass du mit der Python-Syntax vertraut bist.
pip install semopyHinweis: Für macOS-Nutzer. Wenn du bei der Installation des Pakets auf diesen Fehler stößt:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstalliere graphviz über Homebrew in deinem Terminal
brew install graphvizBevor wir unseren Datensatz herunterladen und unser Modell erstellen, nehmen wir uns eine Minute Zeit, um alle unsere Konstrukte zu definieren. Das heißt, wir müssen die latenten und beobachteten Variablen identifizieren. Im Fall unseres Datensatzes wurden uns die beobachteten Variablen als gelabelte Merkmale zur Verfügung gestellt und sie sind x1 bis x3 und y1 bis y8. Die latenten Variablen, die wir untersuchen wollen, haben diese Namen, die wir erklären werden: ind60, dem60, dem65.
y1: Pressefreiheit, 1960
y2: Freiheit der politischen Opposition, 1960
y3: Fairness der Wahlen, 1960
y4Effektivität der gewählten Legislative, 1960
y5 -y8: sind die gleichen Variablen wie y1-y4, jeweils gemessen im Jahr 1965
x1: das BSP pro Kopf, 1960
x2: der Energieverbrauch pro Kopf, 1960
x3: der Prozentsatz der Arbeitskräfte in der Industrie, 1960
ind60: exogene latente Variable zur Industrialisierung.
dem60: endogene latente Variable zur Demokratie im Jahr 1960.
dem65: endogene latente Variable zur Demokratie im Jahr 1965.
Das Ziel ist es, ein theoretisches Modell zu definieren, das die Beziehung zwischen den latenten Konstrukten und den beobachteten Variablen beschreibt.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Hier werden wir die Beziehungen zwischen den latenten Konstrukten selbst beschreiben.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Hier wollen wir Variablen angeben, die stark miteinander korreliert sind.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Für dieses Tutorial verwenden wir den PoliticalDemocracy.csv Datensatz, der von semopy bereitgestellt wird. Du kannst es in diesem GitHub-Repository herunterladen.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Wir müssen die Struktur- und Messdefinitionen in einer Modellspezifikation kombinieren.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Als nächstes definieren wir das Modell und passen die Daten an
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Wir werden das Ergebnis des Modells aufzeichnen, um die Pfaddarstellung zu verstehen. Der Plot wird als political_sem_model.png gespeichert.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()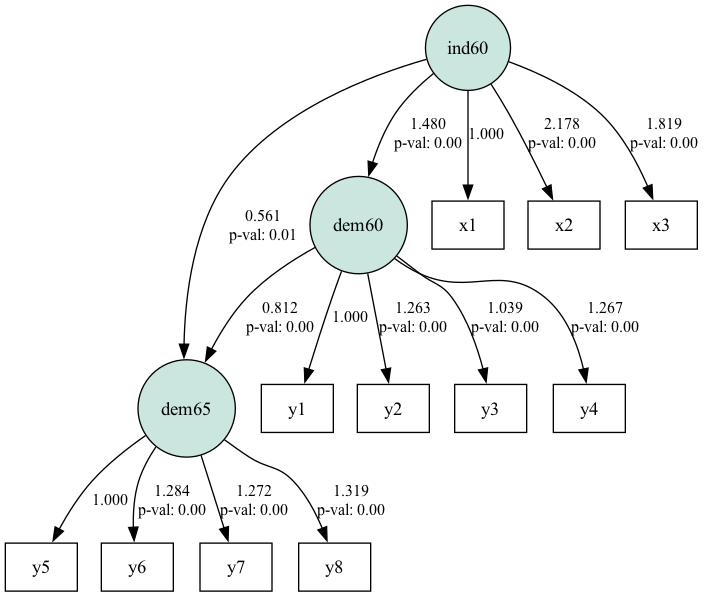
SEM-Pfaddiagramm für den Datensatz zur politischen Demokratie. Quelle: Bild vom Autor
Das Diagramm zeigt, wie der Pfad die latenten Konstrukte (in Kreisen) und die beobachteten Variablen miteinander verbindet. Pfadkoeffizienten, die näher bei 1 oder -1 liegen, zeigen starke Beziehungen zwischen den Variablen an, während solche nahe 0 schwache Beziehungen anzeigen.
Die Standardabweichungen in der Tabelle liegen innerhalb der Spanne. Größere Werte können auf Multikollinearität oder eine Fehlspezifizierung des Modells hinweisen. Die p-Werte bestimmen die statistische Signifikanz der Pfadkoeffizienten. Ein p-Wert von weniger als 0,05 bedeutet normalerweise, dass der Pfad statistisch signifikant ist. Wir sehen 2 Fälle, in denen der p-Wert größer als 0,05 ist.
Alles in allem zeigen die Ergebnisse, dass ind60 einen signifikanten Einfluss auf dem60 hat, was wiederum einen signifikanten Einfluss auf dem65 hat.
Das hypothetische Modell sollte mit den beobachteten Beziehungen übereinstimmen, damit das SEM-Modell passt. Verschiedene Anpassungsindizes werden verwendet, um zu beurteilen, wie gut das Modell zu den Daten passt. Hier sind die am häufigsten verwendeten:
Zu den allgemeinen Herausforderungen der Strukturgleichungsmodellierung gehören die folgenden:
In diesem Artikel haben wir uns ausführlich mit dem SEM beschäftigt, einschließlich seiner Anwendungen, Umsetzung, Vorteile und Grenzen. Die SEM ist ein leistungsstarkes Instrument zur Untersuchung komplexer Beziehungen und kausaler Wechselwirkungen zwischen beobachteten und latenten Variablen. Du solltest es in Python oder R für dein nächstes Analyseprojekt ausprobieren.
Wenn du dich für die Idee der Strukturgleichungsmodellierung interessierst, aber R bevorzugst, kannst du den Kurs Strukturgleichungsmodellierung mit Lavaan in R besuchen, der eine detaillierte Schritt-für-Schritt-Anleitung enthält. Du kannst auch die Laufbahn Statistiker/in in R einschlagen. Wenn du dich für Python entscheidest, lies die Semopy-Dokumentation für weitere Anwendungsfälle von SEM in Python. Wenn du dich für fortgeschrittene Python-Modelle interessierst, die sowohl Vorhersagen als auch Erklärungen liefern, und Ideen für die Modellarchitektur und die Auswahl von Merkmalen erforschen möchtest, solltest du unseren Karrierepfad Machine Learning Scientist in Python ausprobieren.
Lernen mit DataCamp
Lernpfad
Lernpfad
Kurs
Blog
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Derrick Mwiti
Tutorial
Javier Canales Luna
Tutorial
Laiba Siddiqui

