
Leerpad
Basisprincipes van machine learning in Python
16 Hr
Structural equation modeling (SEM) stelt ons in staat om causale relaties tussen variabelen te onderzoeken en te begrijpen hoe elke variabele bijdraagt aan de algehele prestatie. SEM is een krachtig hulpmiddel dat factoranalyse en meervoudige regressie combineert om relaties tussen meerdere variabelen te analyseren. Dat lijkt een beetje op hoe we in het dagelijks leven kijken naar hoe factoren zoals houding, zelfvertrouwen en communicatieve vaardigheden samen de prestatie tijdens een sollicitatiegesprek beïnvloeden.
Laten we SEM, de toepassingen en praktische voorbeelden in Python verkennen. Als je nieuw bent met enkele kernideeën, zoals het concept van latente factoren, probeer dan ook onze cursus Factoranalyse.
Structural equation modeling geeft de causale relaties weer tussen latente en geobserveerde variabelen. De geobserveerde variabelen zijn wat we direct kunnen meten. Latente constructen worden afgeleid en niet direct gemeten.
Om deze relaties effectief vast te leggen, is SEM verdeeld in twee hoofdcomponenten: het meetmodel en het structurele model. Het meetmodel specificeert de relaties tussen geobserveerde variabelen en hun bijbehorende latente variabelen, terwijl het structurele model de relaties tussen latente variabelen specificeert.
Statistische technieken zoals correlatie en regressie zijn niet efficiënt voor het bestuderen van complexe multivariate relaties. SEM is geschikt voor het modelleren van complexe, veelzijdige constructen die met meetfouten worden gemeten. Het is ook nuttig omdat het helpt om een systeem van relaties te specificeren. Traditionele methoden helpen ons een afhankelijke variabele en een set voorspellers te bestuderen. Hoewel correlatie geen causaliteit is, helpt SEM ons de causale relatie tussen de geobserveerde variabele en latente constructen te begrijpen.
Enkele toepassingen van SEM zijn onder andere:
Hier zijn enkele van de kernconcepten in structural equation modeling:
Hoewel SEM uitstekend is voor het modelleren van causale relaties, zijn er enkele onderliggende aannames over de data. De aannames omvatten:
Er zijn verschillende typen structural equation modeling. Zonder specifieke volgorde zijn dat:
Een SEM-model ontwikkelen in Python vergt maar een paar stappen; we kunnen de bibliotheek semopy gebruiken om het eenvoudig te maken. In de volgende tutorial gaan we ervan uit dat je bekend bent met de Python-syntax.
pip install semopyLet op: Voor macOS-gebruikers. Als je deze fout tegenkomt tijdens het installeren van het pakket:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstalleer graphviz via Homebrew in je terminal
brew install graphvizVoordat we onze dataset downloaden en ons model maken, nemen we even de tijd om al onze constructen te definiëren. We moeten dus de latente en geobserveerde variabelen identificeren. In het geval van onze dataset zijn de geobserveerde variabelen aan ons gegeven als gelabelde features en dat zijn x1 tot en met x3 en y1 tot en met y8. De latente variabelen die we willen bestuderen hebben deze namen, die we zullen uitleggen: ind60, dem60, dem65.
y1: persvrijheid, 1960
y2: vrijheid van politieke oppositie, 1960
y3: eerlijkheid van verkiezingen, 1960
y4: effectiviteit van gekozen wetgevende macht, 1960
y5 -y8: dezelfde variabelen als y1-y4, respectievelijk, gemeten in 1965
x1: het bnp per hoofd van de bevolking, 1960
x2: het energieverbruik per hoofd van de bevolking, 1960
x3: het percentage van de beroepsbevolking in de industrie, 1960
ind60: exogene latente variabele over industrialisatie.
dem60: endogene latente variabele over democratie in 1960.
dem65: endogene latente variabele over democratie in 1965.
Het doel is om een theoretisch model te definiëren dat de relatie tussen de latente constructen en geobserveerde variabelen specificeert.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Hier specificeren we de relaties tussen de latente constructen zelf.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Hier willen we variabelen specificeren die sterk met elkaar correleren.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Voor deze tutorial gebruiken we de dataset PoliticalDemocracy.csv die door semopy wordt geleverd. Je kunt deze downloaden via deze GitHub-repository.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')We moeten de structurele en meetdefinities combineren in een modelspecificatie.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Vervolgens definiëren we het model en passen we de data
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())We plotten het resultaat van het model om de padrepresentatie te begrijpen. De plot wordt opgeslagen als political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()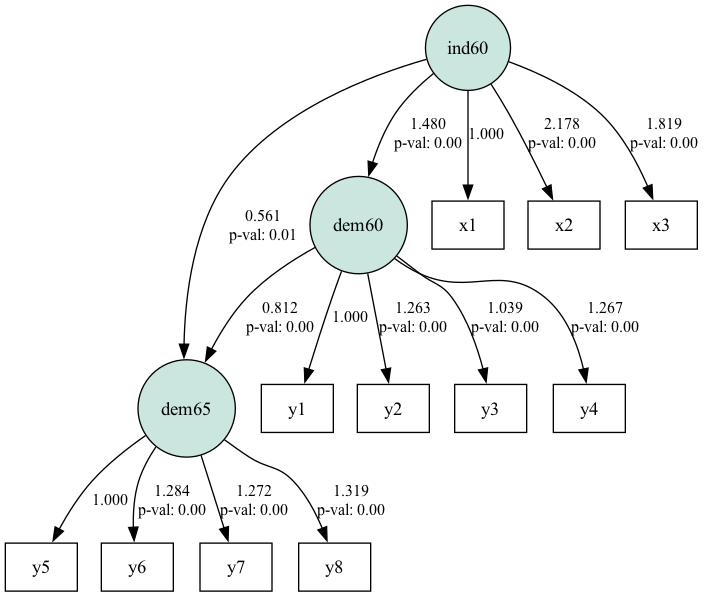
SEM-padendiagram voor de politieke-democratie-dataset. Bron: afbeelding door de auteur
Het diagram laat zien hoe het pad de latente constructen (in cirkels) en de geobserveerde variabelen relateert. Padcoëfficiënten dichter bij 1 of -1 duiden op sterke relaties tussen variabelen en die nabij 0 op zwakke relaties.
De standaarddeviaties in de tabel vallen binnen het bereik. Grotere waarden kunnen duiden op multicollineariteit of een onjuist gespecificeerd model. De p-waarden bepalen de statistische significantie van de padcoëfficiënten. Een p-waarde kleiner dan 0,05 duidt meestal op een statistisch significant pad. We zien twee gevallen waarin de p-waarde groter is dan 0,05.
Al met al laten de resultaten zien dat ind60 een significante invloed heeft op dem60, dat op zijn beurt een significante invloed heeft op dem65.
Het veronderstelde model moet overeenkomen met de geobserveerde relaties om de SEM-model fit te beoordelen. Er worden verschillende fit-indices gebruikt om te beoordelen hoe goed het model bij de data past. Hier zijn veelgebruikte:
Enkele veelvoorkomende uitdagingen van de structural equation modeling-techniek zijn de volgende:
In dit artikel hebben we SEM uitgebreid besproken, inclusief de toepassingen, implementatie, voordelen en beperkingen. SEM is een krachtig instrument voor het onderzoeken van complexe relaties en causale interacties tussen geobserveerde en latente variabelen. Probeer het eens uit in Python of R voor je volgende analyseproject.
Als je geïnteresseerd bent in het idee van structural equation modeling maar de voorkeur geeft aan R, kun je de cursus Structural Equation Modeling with lavaan in R volgen, met gedetailleerde stapsgewijze instructies. Je kunt ook starten met het Statistician in R-carrièrepad. Als je je aan Python commit, lees dan de semopy-documentatie voor meer use-cases van SEM in Python. Ben je tot slot geïnteresseerd in geavanceerde Python-modellen die zowel voorspellen als verklaren, en wil je ideeën over modelarchitectuur en featureselectie verkennen, probeer dan ons carrièrepad Machine Learning Scientist in Python.
Leren met DataCamp
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
