
programa
Fundamentos del aprendizaje automático en Python
16 h
El modelado de ecuaciones estructurales (SEM) nos permite investigar las relaciones causales entre variables y comprender cómo contribuye cada una de ellas al rendimiento global. El SEM es una potente herramienta que combina el análisis factorial y el análisis de regresión múltiple para analizar las relaciones entre múltiples variables. Esto es algo similar a cómo, en nuestra vida diaria, consideramos cómo factores como la postura, la confianza y las habilidades de comunicación influyen colectivamente en algo como el rendimiento en una entrevista.
Exploremos ahora el SEM, sus aplicaciones y ejemplos prácticos en Python. Si no conoces algunas de las ideas centrales, como la idea de los factores latentes, también puedes probar nuestro curso de Análisis Factorial.
El modelado de ecuaciones estructurales representa las relaciones causales entre las variables latentes y las observadas. Las variables observadas son las que podemos medir directamente. Los constructos latentes se infieren y no se miden directamente.
Para captar eficazmente estas relaciones, el SEM se divide en dos componentes principales: el modelo de medida y el modelo estructural. El modelo de medida especifica las relaciones entre las variables observadas y sus correspondientes variables latentes, mientras que el modelo estructural especifica las relaciones entre las variables latentes.
Las técnicas estadísticas como la correlación y la regresión son ineficaces para estudiar relaciones multivariantes complejas. El SEM es adecuado para modelizar constructos complejos y polifacéticos que se miden con error. También es útil porque ayuda a especificar un sistema de relaciones. Los métodos tradicionales nos ayudan a estudiar una variable independiente y un conjunto de predictores. Aunque correlación no es causalidad, el SEM nos ayuda a comprender la relación causal entre la variable observada y los constructos latentes.
Algunas de las aplicaciones del SEM son
He aquí algunos de los conceptos básicos del modelado de ecuaciones estructurales:
Aunque el SEM es estupendo para modelizar relaciones casuales, tiene algunas suposiciones subyacentes sobre los datos. Los supuestos incluyen:
Existen distintos tipos de modelos de ecuaciones estructurales. Sin ningún orden en particular, son:
Desarrollar un modelo SEM en Python sólo requiere unos pocos pasos; podemos utilizar la biblioteca semopy para hacerlo fácilmente. El siguiente tutorial asume que estás familiarizado con la sintaxis de Python.
pip install semopyNota: Para usuarios de macOS. Si encuentras este error al instalar el paquete:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstala graphviz a través de homebrew en tu terminal
brew install graphvizAntes de descargar nuestro conjunto de datos y crear nuestro modelo, dediquemos un minuto a definir todos nuestros constructos. Es decir, tendremos que identificar las variables latentes y observadas. En el caso de nuestro conjunto de datos, las variables observadas se nos han proporcionado como características etiquetadas y son x1 a x3 y y1 a y8. Las variables latentes que queremos estudiar tienen estos nombres, que explicaremos: ind60, dem60, dem65.
y1libertad de prensa, 1960
y2libertad de oposición política, 1960
y3: imparcialidad de las elecciones, 1960
y4eficacia de la legislatura elegida, 1960
y5 -y8: son las mismas variables que y1-y4, respectivamente, medidas en 1965
x1el PNB per cápita, 1960
x2el consumo de energía per cápita, 1960
x3porcentaje de mano de obra en la industria, 1960
ind60variable latente exógena sobre la industrialización.
dem60: variable latente endógena sobre la democracia en 1960.
dem65: variable latente endógena sobre la democracia en 1965.
El objetivo es definir un modelo teórico que especifique la relación entre los constructos latentes y las variables observadas.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Aquí especificaremos las relaciones entre los propios constructos latentes.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Aquí queremos especificar variables que estén muy correlacionadas entre sí.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Para este tutorial, utilizaremos el conjunto de datos PoliticalDemocracy.csv proporcionado por semopy. Puedes descargarlo visitando este repositorio de GitHub.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Tenemos que combinar las definiciones estructurales y de medición en una especificación del modelo.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""A continuación, definimos el modelo y ajustamos los datos
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Trazaremos el resultado del modelo para comprender la representación de la trayectoria. La parcela se guardará como political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()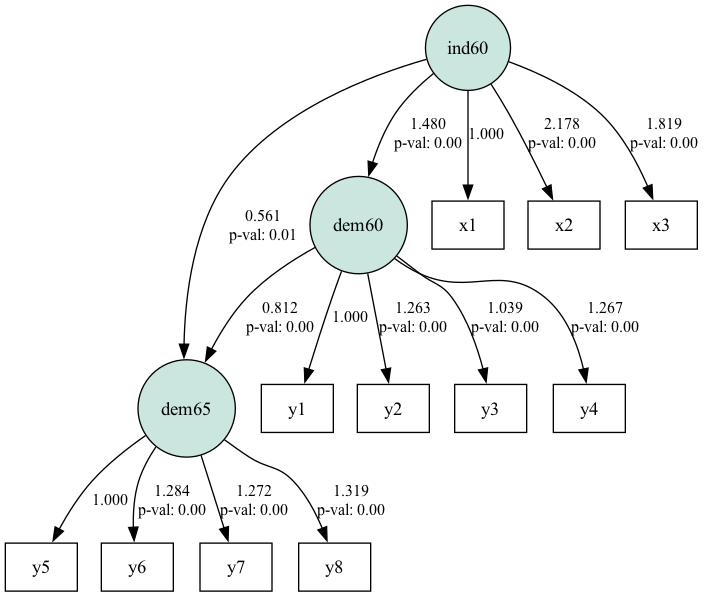
Diagrama SEM del conjunto de datos de la democracia política. Fuente: Imagen del autor
El diagrama muestra cómo el camino relaciona los constructos latentes (en círculos) y las variables observadas. Los coeficientes de trayectoria más cercanos a 1 o -1 muestran relaciones fuertes entre las variables y los cercanos a 0 muestran relaciones débiles.
Las desviaciones típicas de la tabla están dentro del intervalo. Los valores más altos pueden indicar multicolinealidad o una mala especificación del modelo. Los valores p determinan la significación estadística de los coeficientes del camino. Un valor p inferior a 0,05 suele indicar que la trayectoria es estadísticamente significativa. Vemos 2 casos en los que el valor p es superior a 0,05.
En conjunto, los resultados muestran que ind60 influye significativamente en dem60, que, a su vez, influye significativamente en dem65.
El modelo hipotetizado debe coincidir con las relaciones observadas para evaluar el ajuste del modelo SEM. Se utilizan varios índices de ajuste para evaluar lo bien que el modelo se ajusta a los datos. Aquí tienes los más utilizados:
Algunos de los retos habituales de la técnica de modelización de ecuaciones estructurales son los siguientes:
En este artículo, revisamos el SEM en profundidad, incluyendo sus aplicaciones, implementación, ventajas y limitaciones. El SEM es una potente herramienta para examinar relaciones complejas e interacciones causales entre variables observadas y latentes. Deberías probarlo en Python o R para tu próximo proyecto de análisis.
Si te interesa la idea del modelado de ecuaciones estructurales pero prefieres R, puedes seguir el curso Structural Equation Modeling with lavaan in R, que contiene instrucciones detalladas paso a paso. También puedes emprender la carrera de Estadístico en R. Si estás comprometido con Python, lee la documentación de semopy para conocer más casos de uso de SEM en Python. Por último, si te interesan los modelos avanzados de Python que predicen y explican, y explorar ideas de arquitectura de modelos y selección de características, prueba nuestra trayectoria profesional de Científico de Aprendizaje Automático en Python.
Aprende con DataCamp
programa
programa
Curso
blog
Natassha Selvaraj
15 min
Tutorial
Kurtis Pykes
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Joleen Bothma
