
Track
Machine Learning Fundamentals in Python
16 hr
Structural equation modeling (SEM) allows us to investigate causal relationships among variables and understand how each contributes to overall performance. SEM is a powerful tool that combines factor analysis and multiple regression analysis to analyze relationships among multiple variables. This is somewhat similar to how, in our daily lives, we consider how factors like posture, confidence, and communication skills collectively impact something like interview performance.
Let’s now explore SEM, its applications, and practical examples in Python. If you are new to some of the central ideas, such as the idea of latent factors, you can also try our Factor Analysis course.
Structural equation modeling represents the causal relationships between latent and observed variables. The observed variables are what we can measure directly. Latent constructs are inferred and not measured directly.
To effectively capture these relationships, SEM is divided into two main components:: the measurement model and the structural model. The measurement model specifies the relationships between observed variables and their corresponding latent variables, while the structural model specifies the relationships between latent variables.
Statistical techniques like correlation and regression are inefficient in studying complex multivariate relationships. SEM is suitable for modeling complex, multifaceted constructs that are measured with error. It is also useful because it helps specify a system of relationships. Traditional methods help us study an independent variable and a set of predictors. While correlation is not causation, SEM helps us understand the causal relationship between the observed variable and latent constructs.
Some of the applications of SEM include:
Here are some of the core concepts in structural equation modeling:
While SEM is great for modeling casual relationships, it has some underlying assumptions on the data. The assumptions include:
There are different types of structural equation modeling. In no particular order, they are:
Developing an SEM model in Python only requires a few steps; we can use the semopy library to make it easy. The following tutorial assumes that you are familiar with Python syntax.
pip install semopyNote: For macOS users. If you encounter this error while installing the package:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstall graphviz through homebrew in your terminal
brew install graphvizBefore we download our dataset and create our model, let’s take a minute to define all of our constructs. That is, we will need to identify the latent and observed variables. In the case of our dataset, the observed variables have been provided to us as labeled features and they are x1 to x3 and y1 to y8. The latent variables we want to study have these names, which we will explain: ind60, dem60, dem65.
y1: freedom of the press, 1960
y2: freedom of political opposition, 1960
y3: fairness of elections, 1960
y4: effectiveness of elected legislature, 1960
y5 -y8: are the same variables as y1-y4, respectively, measured in 1965
x1: the GNP per capita, 1960
x2: the energy consumption per capita, 1960
x3: the percentage of labor force in industry, 1960
ind60: exogenous latent variable on industralization.
dem60: endogenous latent variable on democracy at 1960.
dem65: endogenous latent variable on democracy at 1965.
The goal is to define a theoretical model to specify the relationship between the latent constructs and observed variables.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Here, we will specify the relationships between the latent constructs themselves.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Here, we want to specify variables that are highly correlated with each other.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5For this tutorial, we will use the PoliticalDemocracy.csv dataset provided by semopy. You can download it by visiting this GitHub repository.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')We need to combine the structural and measurement definitions into a model specification.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Next, we define the model and fit the data
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())We will plot the model's result to understand the path representation. The plot will be saved as political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()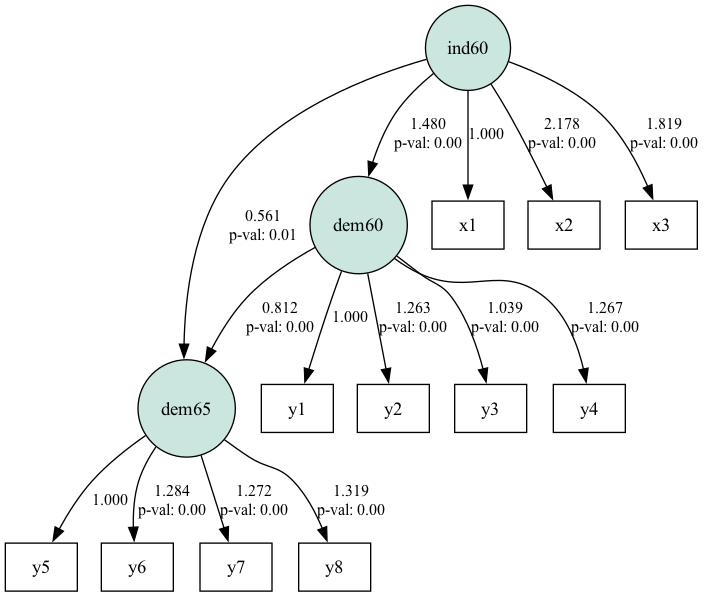
SEM path diagram for political democracy dataset. Source: Image by Author
The diagram shows how the path relates the latent constructs (in circles) and the observed variables. Path coefficients closer to 1 or -1 show strong relationships between variables and those near 0 show weak relationships.
The standard deviations in the table are within the range. Larger values may indicate multicollinearity or model misspecification. The p-values determine the statistical significance of the path coefficients. A p-value less than 0.05 usually indicates that the path is statistically significant. We see 2 cases where the p-value is greater than 0.05.
All-in-all, the results show that ind60 significantly influences dem60, which, in turn, significantly influences dem65.
The hypothesized model should match the observed relationships to assess SEM model fit. Various fit indices are used to assess how well the model fits the data. Here are commonly used ones:
Some common challenges of the structural equation modeling technique include the following:
In this article, we reviewed SEM in depth, including its applications, implementation, advantages, and limitations. SEM is a powerful tool for examining complex relationships and causal interactions among observed and latent variables. You should try it out in Python or R for your next analysis project.
If you are interested in the idea of structural equqtion modeling but you prefer R, you can take Structural Equation Modeling with lavaan in R course, which has detailed step-by-step instructions. You can also embark on the Statistician in R career track. If you are committed to Python, read up on the semopy documentation for more use cases of SEM in Python. Finally, if you are interested in advanced Python models that both predict and explain, and exploring ideas of model architecture and feature selection, try our Machine Learning Scientist in Python career track.
Learn with DataCamp
Track
Track
Course
blog
Kurtis Pykes
9 min
Tutorial
Josef Waples
Tutorial
Vidhi Chugh
Tutorial
Vinod Chugani
Tutorial
Vahab Khademi
Tutorial
Amberle McKee