
Program
Makine Öğrenimi Temelleri Python'da
16 sa
Yapısal eşitlik modellemesi (SEM), değişkenler arasındaki nedensel ilişkileri incelememizi ve her birinin genel performansa nasıl katkıda bulunduğunu anlamamızı sağlar. SEM, birden çok değişken arasındaki ilişkileri analiz etmek için faktör analizi ile çoklu regresyon analizini birleştiren güçlü bir araçtır. Bu, günlük hayatımızda duruş, özgüven ve iletişim becerileri gibi faktörlerin örneğin mülakat performansını birlikte nasıl etkilediğini düşünmemize biraz benzer.
Şimdi SEM’i, kullanım alanlarını ve Python ile pratik örneklerini inceleyelim. Gizil faktör kavramı gibi bazı temel fikirlere yeniyseniz, Faktör Analizi kursumuzu da deneyebilirsiniz.
Yapısal eşitlik modellemesi, gizil ve gözlenen değişkenler arasındaki nedensel ilişkileri temsil eder. Gözlenen değişkenler doğrudan ölçebildiklerimizdir. Gizil yapılar ise dolaylı olarak çıkarılır, doğrudan ölçülmez.
Bu ilişkileri etkili şekilde yakalayabilmek için SEM iki ana bileşene ayrılır: ölçüm modeli ve yapısal model. Ölçüm modeli, gözlenen değişkenlerle bunlara karşılık gelen gizil değişkenler arasındaki ilişkileri belirtirken; yapısal model, gizil değişkenler arasındaki ilişkileri belirtir.
Korelasyon ve regresyon gibi istatistiksel teknikler, karmaşık çok değişkenli ilişkileri incelemede verimsiz kalır. SEM, hata ile ölçülen karmaşık, çok boyutlu yapıları modellemek için uygundur. Ayrıca bir ilişki sistemini belirlemeye yardımcı olduğu için de faydalıdır. Geleneksel yöntemler, bir bağımlı değişken ile bir dizi yordayıcıyı incelememize yardımcı olur. Korelasyon nedensellik değildir; SEM ise gözlenen değişken ile gizil yapılar arasındaki nedensel ilişkiyi anlamamıza yardımcı olur.
SEM’in bazı kullanım alanları şunlardır:
Yapısal eşitlik modellemesindeki bazı temel kavramlar şunlardır:
SEM, nedensel ilişkileri modellemede harika olsa da veri hakkında bazı temel varsayımlara sahiptir. Bu varsayımlar şunlardır:
Farklı yapısal eşitlik modelleme türleri vardır. Özel bir sıralama olmaksızın şunlardır:
Python’da bir SEM modeli geliştirmek yalnızca birkaç adım gerektirir; bunu kolaylaştırmak için semopy kütüphanesini kullanabiliriz. Aşağıdaki eğitim, Python söz dizimine aşina olduğunuzu varsayar.
pip install semopyNot: macOS kullanıcıları için. Paketi kurarken şu hatayla karşılaşırsanız:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHTerminalinizde Homebrew üzerinden graphviz kurun
brew install graphvizVeri kümemizi indirmeden ve modelimizi oluşturmadan önce, tüm yapılarımızı tanımlamaya bir dakika ayıralım. Yani, gizil ve gözlenen değişkenleri belirlememiz gerekecek. Veri kümemiz özelinde, gözlenen değişkenler etiketli özellikler olarak bize sağlanmıştır ve x1’den x3’e ve y1’den y8’e kadar uzanırlar. İncelemek istediğimiz gizil değişkenlerin ise açıklayacağımız şu adları vardır: ind60, dem60, dem65.
y1: basın özgürlüğü, 1960
y2: siyasi muhalefet özgürlüğü, 1960
y3: seçimlerin adilliği, 1960
y4: seçilmiş yasama organının etkililiği, 1960
y5 -y8: sırasıyla y1-y4 ile aynı değişkenler olup 1965 yılında ölçülmüştür
x1: kişi başına GSYİH, 1960
x2: kişi başına enerji tüketimi, 1960
x3: sanayideki işgücü yüzdesi, 1960
ind60: sanayileşme üzerine eksojen gizil değişken.
dem60: 1960 yılı demokrasisi üzerine endojen gizil değişken.
dem65: 1965 yılı demokrasisi üzerine endojen gizil değişken.
Amaç, gizil yapılar ile gözlenen değişkenler arasındaki ilişkiyi belirlemek için kuramsal bir model tanımlamaktır.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Burada, gizil yapıların kendi aralarındaki ilişkileri belirteceğiz.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Burada, birbiriyle yüksek korelasyon gösteren değişkenleri belirtmek istiyoruz.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Bu eğitim için, semopy tarafından sağlanan PoliticalDemocracy.csv veri kümesini kullanacağız. Şu GitHub deposunu ziyaret ederek indirebilirsiniz.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Yapısal ve ölçüm tanımlarını bir model belirtimine birleştirmemiz gerekiyor.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Sonraki adımda modeli tanımlayıp veriye uyduruyoruz
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Yol gösterimini anlamak için modelin sonucunu görselleştireceğiz. Grafik political_sem_model.png olarak kaydedilecektir.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()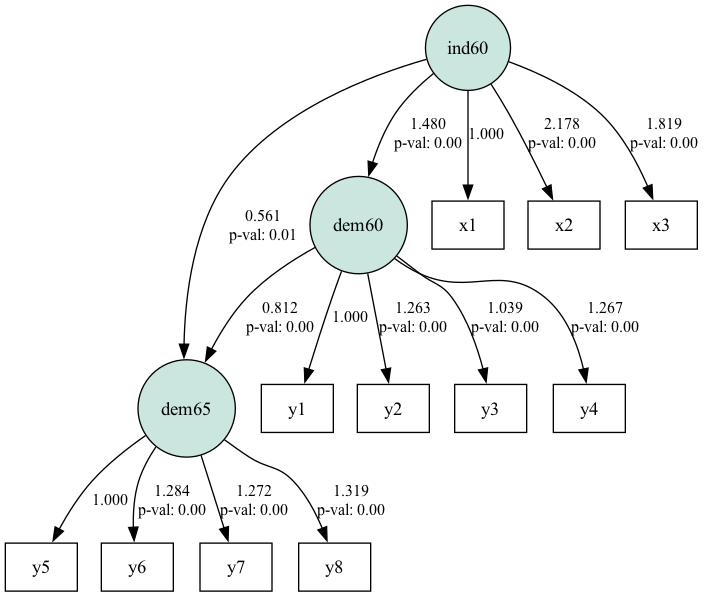
Siyasal demokrasi veri kümesi için SEM yol diyagramı. Kaynak: Yazarın görseli
Diyagram, yolun gizil yapılar (daireler içinde) ile gözlenen değişkenleri nasıl ilişkilendirdiğini gösterir. 1’e veya -1’e yakın yol katsayıları değişkenler arasında güçlü ilişkiler, 0’a yakın olanlar ise zayıf ilişkiler gösterir.
Tablodaki standart sapmalar makul aralıktadır. Daha büyük değerler çoklu doğrusal bağlantıya veya model belirtim hatasına işaret edebilir. p-değerleri, yol katsayılarının istatistiksel anlamlılığını belirler. 0,05’ten küçük p-değeri genellikle yolun istatistiksel olarak anlamlı olduğunu gösterir. p-değerinin 0,05’ten büyük olduğu 2 durum görüyoruz.
Genel olarak, sonuçlar ind60’ın dem60 üzerinde önemli bir etkisi olduğunu, bunun da sırayla dem65 üzerinde önemli bir etkiye sahip olduğunu gösteriyor.
SEM model uyumunu değerlendirmek için, varsayılan modelin gözlenen ilişkilerle eşleşmesi gerekir. Modelin veriye ne kadar iyi uyduğunu değerlendirmek için çeşitli uyum indeksleri kullanılır. Yaygın olanlardan bazıları şunlardır:
Yapısal eşitlik modelleme tekniğinin yaygın bazı zorlukları şunlardır:
Bu yazıda SEM’i; kullanım alanları, uygulaması, avantajları ve sınırlamalarıyla birlikte ayrıntılı olarak ele aldık. SEM, gözlenen ve gizil değişkenler arasındaki karmaşık ilişkileri ve nedensel etkileşimleri incelemek için güçlü bir araçtır. Bir sonraki analiz projenizde Python veya R ile denemelisiniz.
Yapısal eşitlik modellemesi fikri ilginizi çekiyor ancak R’i tercih ediyorsanız, adım adım ayrıntılı yönergeler içeren R’de lavaan ile Yapısal Eşitlik Modellemesi kursunu alabilirsiniz. Ayrıca R ile İstatistikçi kariyer yolculuğuna da başlayabilirsiniz. Python’a bağlıysanız, Python’da SEM’in daha fazla kullanım örneği için semopy dokümantasyonunu okuyun. Son olarak, hem tahmin eden hem de açıklayan gelişmiş Python modelleri, model mimarisi ve özellik seçimi fikirlerini keşfetmek ilginizi çekiyorsa, Python ile Makine Öğrenimi Bilimcisi kariyer yolunu deneyin.
DataCamp ile Öğrenin
Program
Program
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
