
Tracks
Cơ bản về Học máy trong Python
16 giờ
Mô hình phương trình cấu trúc (SEM) cho phép chúng ta khảo sát các mối quan hệ nhân quả giữa các biến và hiểu mỗi biến đóng góp như thế nào vào hiệu suất tổng thể. SEM là một công cụ mạnh mẽ kết hợp phân tích nhân tố và hồi quy bội để phân tích mối quan hệ giữa nhiều biến. Điều này phần nào giống với cách trong đời sống hằng ngày, chúng ta cân nhắc các yếu tố như tư thế, sự tự tin và kỹ năng giao tiếp cùng nhau ảnh hưởng đến điều gì đó như hiệu suất phỏng vấn.
Giờ hãy cùng khám phá SEM, các ứng dụng của nó và ví dụ thực tế bằng Python. Nếu bạn mới làm quen với một số ý tưởng cốt lõi, chẳng hạn như khái niệm biến ẩn, bạn cũng có thể học khóa Phân tích Nhân tố của chúng tôi.
Mô hình phương trình cấu trúc thể hiện các mối quan hệ nhân quả giữa các biến ẩn và biến quan sát được. Biến quan sát được là những gì chúng ta có thể đo lường trực tiếp. Các cấu trúc ẩn được suy luận và không đo lường trực tiếp.
Để nắm bắt hiệu quả các mối quan hệ này, SEM được chia thành hai thành phần chính: mô hình đo lường và mô hình cấu trúc. Mô hình đo lường chỉ rõ mối quan hệ giữa các biến quan sát và các biến ẩn tương ứng, trong khi mô hình cấu trúc chỉ rõ mối quan hệ giữa các biến ẩn.
Các kỹ thuật thống kê như tương quan và hồi quy kém hiệu quả trong việc nghiên cứu các mối quan hệ đa biến phức tạp. SEM phù hợp để mô hình hóa các cấu trúc phức hợp, đa diện được đo lường có sai số. Nó cũng hữu ích vì giúp chỉ định một hệ thống các mối quan hệ. Các phương pháp truyền thống giúp chúng ta nghiên cứu một biến phụ thuộc và một tập biến dự báo. Dù tương quan không phải là nhân quả, SEM giúp chúng ta hiểu mối quan hệ nhân quả giữa biến quan sát được và các cấu trúc ẩn.
Một số ứng dụng của SEM bao gồm:
Dưới đây là một số khái niệm cốt lõi trong mô hình phương trình cấu trúc:
Dù SEM rất phù hợp để mô hình hóa các mối quan hệ nhân quả, nó có một số giả định nền tảng về dữ liệu. Các giả định gồm:
Có nhiều loại mô hình phương trình cấu trúc. Không theo thứ tự cụ thể, gồm có:
Phát triển một mô hình SEM trong Python chỉ cần vài bước; chúng ta có thể dùng thư viện semopy để đơn giản hóa. Hướng dẫn sau giả định rằng bạn đã quen với cú pháp Python.
pip install semopyLưu ý: Dành cho người dùng macOS. Nếu bạn gặp lỗi này khi cài đặt gói:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHCài đặt graphviz thông qua homebrew trong terminal của bạn
brew install graphvizTrước khi tải bộ dữ liệu và tạo mô hình, hãy dành chút thời gian để xác định các cấu trúc của chúng ta. Tức là, chúng ta sẽ cần xác định các biến ẩn và biến quan sát. Trong trường hợp bộ dữ liệu của chúng ta, các biến quan sát đã được cung cấp dưới dạng đặc trưng có nhãn và chúng là x1 đến x3 và y1 đến y8. Các biến ẩn chúng ta muốn nghiên cứu có các tên sau, sẽ được giải thích: ind60, dem60, dem65.
y1: tự do báo chí, 1960
y2: tự do đối lập chính trị, 1960
y3: tính công bằng của bầu cử, 1960
y4: hiệu quả của cơ quan lập pháp được bầu, 1960
y5 -y8: là các biến giống với y1-y4 tương ứng, đo lường năm 1965
x1: GNP bình quân đầu người, 1960
x2: mức tiêu thụ năng lượng bình quân đầu người, 1960
x3: tỷ lệ lực lượng lao động trong công nghiệp, 1960
ind60: biến ẩn ngoại sinh về công nghiệp hóa.
dem60: biến ẩn nội sinh về dân chủ năm 1960.
dem65: biến ẩn nội sinh về dân chủ năm 1965.
Mục tiêu là xác định một mô hình lý thuyết để chỉ rõ mối quan hệ giữa các cấu trúc ẩn và các biến quan sát.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Tại đây, chúng ta sẽ chỉ định các mối quan hệ giữa chính các cấu trúc ẩn.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Tại đây, chúng ta muốn chỉ định các biến có tương quan cao với nhau.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Trong hướng dẫn này, chúng ta sẽ dùng bộ dữ liệu PoliticalDemocracy.csv do semopy cung cấp. Bạn có thể tải xuống bằng cách truy cập kho GitHub này.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Chúng ta cần kết hợp phần định nghĩa cấu trúc và đo lường vào đặc tả mô hình.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Tiếp theo, chúng ta định nghĩa mô hình và fit dữ liệu
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Chúng ta sẽ vẽ kết quả của mô hình để hiểu biểu diễn đường dẫn. Biểu đồ sẽ được lưu dưới tên political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()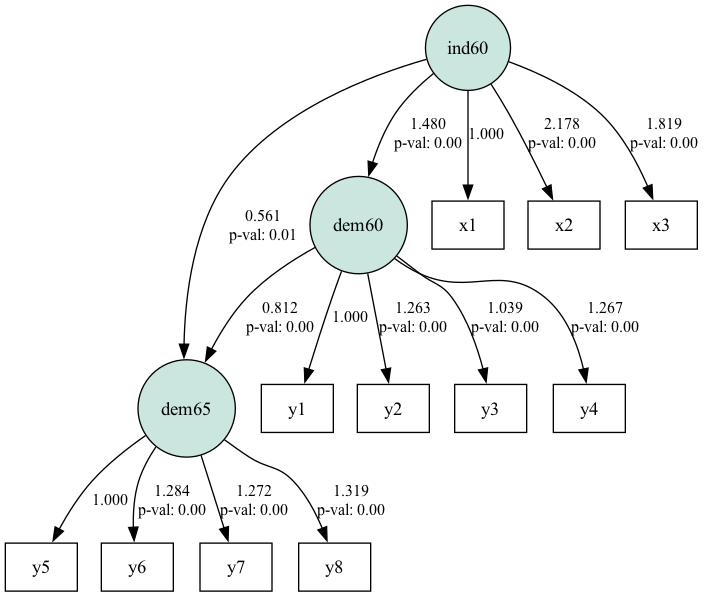
Sơ đồ đường dẫn SEM cho bộ dữ liệu dân chủ chính trị. Nguồn: Hình do Tác giả tạo
Sơ đồ cho thấy cách đường dẫn liên hệ các cấu trúc ẩn (trong hình tròn) và các biến quan sát. Hệ số đường dẫn gần 1 hoặc -1 cho thấy mối quan hệ mạnh giữa các biến, còn các giá trị gần 0 cho thấy mối quan hệ yếu.
Độ lệch chuẩn trong bảng nằm trong phạm vi chấp nhận được. Giá trị lớn có thể cho thấy đa cộng tuyến hoặc mô hình được chỉ định sai. Giá trị p xác định ý nghĩa thống kê của các hệ số đường dẫn. Giá trị p nhỏ hơn 0,05 thường cho thấy đường dẫn có ý nghĩa thống kê. Chúng ta thấy 2 trường hợp giá trị p lớn hơn 0,05.
Tổng thể, kết quả cho thấy ind60 ảnh hưởng đáng kể đến dem60, và đến lượt nó, dem60 ảnh hưởng đáng kể đến dem65.
Để đánh giá độ phù hợp mô hình SEM, mô hình giả thuyết nên khớp với các mối quan hệ quan sát được. Nhiều chỉ số độ phù hợp được dùng để đánh giá mức độ mô hình khớp với dữ liệu. Dưới đây là các chỉ số thường dùng:
Một số thách thức thường gặp của kỹ thuật mô hình phương trình cấu trúc bao gồm:
Trong bài viết này, chúng ta đã xem xét sâu về SEM, bao gồm ứng dụng, triển khai, ưu điểm và hạn chế. SEM là công cụ mạnh mẽ để khảo sát các mối quan hệ phức tạp và tương tác nhân quả giữa biến quan sát và biến ẩn. Bạn nên thử áp dụng trong Python hoặc R cho dự án phân tích tiếp theo của mình.
Nếu bạn quan tâm đến ý tưởng mô hình phương trình cấu trúc nhưng thích R hơn, bạn có thể học khóa Structural Equation Modeling với lavaan trong R, có hướng dẫn chi tiết từng bước. Bạn cũng có thể bắt đầu lộ trình nghề nghiệp Statistician in R. Nếu bạn gắn bó với Python, hãy đọc tài liệu semopy để biết thêm các trường hợp sử dụng SEM trong Python. Cuối cùng, nếu bạn quan tâm đến các mô hình Python nâng cao vừa dự đoán vừa giải thích, và muốn khám phá ý tưởng về kiến trúc mô hình và chọn đặc trưng, hãy thử lộ trình nghề nghiệp Machine Learning Scientist in Python của chúng tôi.
Học với DataCamp
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút