
Programma
Fondamenti di apprendimento automatico in Python
16 h
Il modeling a equazioni strutturali (SEM) ci permette di indagare le relazioni causali tra variabili e capire come ciascuna contribuisce alle prestazioni complessive. Il SEM è uno strumento potente che combina l’analisi fattoriale e la regressione multipla per analizzare le relazioni tra più variabili. È un po’ simile a quando, nella vita quotidiana, consideriamo come fattori come postura, sicurezza e capacità comunicative influiscano collettivamente su qualcosa come la performance in un colloquio.
Ora esploriamo il SEM, le sue applicazioni e alcuni esempi pratici in Python. Se sei alle prime armi con alcune idee centrali, come il concetto di fattori latenti, puoi anche provare il nostro corso di Analisi Fattoriale.
Il modeling a equazioni strutturali rappresenta le relazioni causali tra variabili latenti e osservate. Le variabili osservate sono ciò che possiamo misurare direttamente. I costrutti latenti sono inferiti e non misurati direttamente.
Per catturare efficacemente queste relazioni, il SEM è suddiviso in due componenti principali: il modello di misura e il modello strutturale. Il modello di misura specifica le relazioni tra le variabili osservate e le corrispondenti variabili latenti, mentre il modello strutturale specifica le relazioni tra le variabili latenti.
Tecniche statistiche come correlazione e regressione sono poco efficienti nello studio di relazioni multivariate complesse. Il SEM è adatto a modellare costrutti complessi e sfaccettati misurati con errore. È utile anche perché permette di specificare un sistema di relazioni. I metodi tradizionali ci aiutano a studiare una variabile dipendente e un insieme di predittori. Sebbene la correlazione non implichi causalità, il SEM ci aiuta a comprendere la relazione causale tra la variabile osservata e i costrutti latenti.
Alcune applicazioni del SEM includono:
Ecco alcuni concetti fondamentali nel modeling a equazioni strutturali:
Sebbene il SEM sia ottimo per modellare relazioni causali, prevede alcune assunzioni sui dati. Tra queste:
Esistono diversi tipi di modeling a equazioni strutturali. In ordine sparso, ecco i principali:
Sviluppare un modello SEM in Python richiede solo pochi passaggi; possiamo usare la libreria semopy per semplificare il tutto. Il seguente tutorial presuppone che tu conosca la sintassi di Python.
pip install semopyNota: per utenti macOS. Se incontri questo errore durante l’installazione del pacchetto:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstalla graphviz tramite Homebrew nel terminale
brew install graphvizPrima di scaricare il dataset e creare il modello, prendiamoci un minuto per definire tutti i costrutti. Ossia, dobbiamo identificare le variabili latenti e quelle osservate. Nel nostro dataset, le variabili osservate ci sono fornite come feature etichettate e sono da x1 a x3 e da y1 a y8. Le variabili latenti che vogliamo studiare hanno questi nomi, che spiegheremo: ind60, dem60, dem65.
y1: libertà di stampa, 1960
y2: libertà dell’opposizione politica, 1960
y3: correttezza delle elezioni, 1960
y4: efficacia del legislativo eletto, 1960
y5 -y8: sono le stesse variabili di y1-y4, rispettivamente, misurate nel 1965
x1: PNL pro capite, 1960
x2: consumo di energia pro capite, 1960
x3: percentuale della forza lavoro nell’industria, 1960
ind60: variabile latente esogena sull’industrializzazione.
dem60: variabile latente endogena sulla democrazia nel 1960.
dem65: variabile latente endogena sulla democrazia nel 1965.
L’obiettivo è definire un modello teorico per specificare la relazione tra costrutti latenti e variabili osservate.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Qui specificheremo le relazioni tra i costrutti latenti stessi.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Qui vogliamo specificare variabili fortemente correlate tra loro.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Per questo tutorial useremo il dataset PoliticalDemocracy.csv fornito da semopy. Puoi scaricarlo visitando questa repository GitHub.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Dobbiamo combinare le definizioni strutturali e di misura in una specifica di modello.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Poi definiamo il modello e adattiamo i dati
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Traceremo i risultati del modello per comprendere la rappresentazione dei percorsi. Il grafico verrà salvato come political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()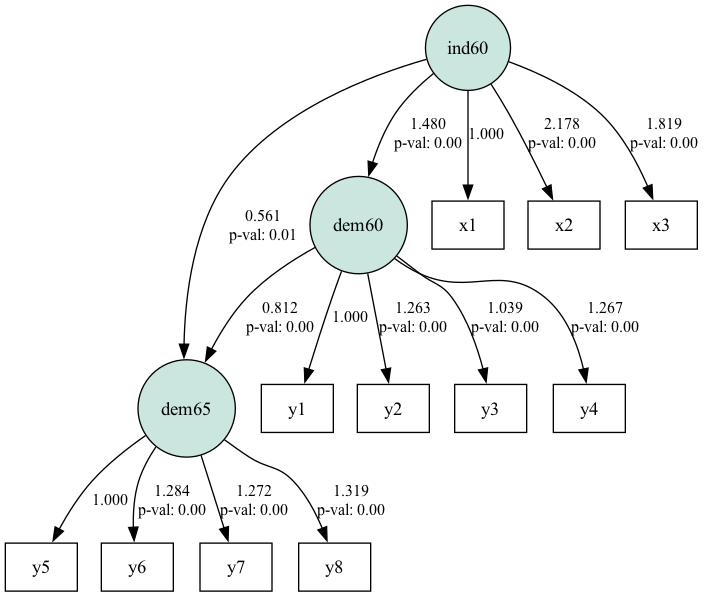
Diagramma dei percorsi SEM per il dataset sulla democrazia politica. Fonte: immagine dell’autore
Il diagramma mostra come i percorsi mettano in relazione i costrutti latenti (nei cerchi) e le variabili osservate. Coefficienti di percorso vicini a 1 o -1 indicano relazioni forti tra le variabili, mentre quelli vicini a 0 indicano relazioni deboli.
Le deviazioni standard nella tabella sono entro l’intervallo. Valori più elevati possono indicare multicollinearità o errata specificazione del modello. I p-value determinano la significatività statistica dei coefficienti di percorso. Un p-value inferiore a 0,05 in genere indica che il percorso è statisticamente significativo. Vediamo 2 casi in cui il p-value è maggiore di 0,05.
In generale, i risultati mostrano che ind60 influenza in modo significativo dem60, che a sua volta influenza significativamente dem65.
Per valutare l’aderenza del modello SEM, il modello ipotizzato dovrebbe corrispondere alle relazioni osservate. Si usano vari indici di aderenza per valutare quanto bene il modello si adatti ai dati. Ecco i più comuni:
Tra le sfide comuni della tecnica del modeling a equazioni strutturali ci sono le seguenti:
In questo articolo abbiamo esaminato in dettaglio il SEM, comprese applicazioni, implementazione, vantaggi e limiti. Il SEM è uno strumento potente per analizzare relazioni complesse e interazioni causali tra variabili osservate e latenti. Provalo in Python o in R per il tuo prossimo progetto di analisi.
Se ti interessa l’idea del modeling a equazioni strutturali ma preferisci R, puoi seguire il corso Structural Equation Modeling with lavaan in R, che offre istruzioni dettagliate passo passo. Puoi anche intraprendere il career track Statistician in R. Se invece punti su Python, leggi la documentazione di semopy per altri casi d’uso del SEM in Python. Infine, se ti interessano modelli Python avanzati che sappiano sia prevedere sia spiegare, ed esplorare idee di architetture di modello e selezione delle feature, prova il career track Machine Learning Scientist in Python.
Impara con DataCamp
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

