
Cursus
Principes fondamentaux de l'apprentissage automatique en Python
16 h
La modélisation par équations structurelles (SEM) nous permet d'étudier les relations causales entre les variables et de comprendre comment chacune d'entre elles contribue à la performance globale. Le SEM est un outil puissant qui combine l'analyse factorielle et l'analyse de régression multiple pour analyser les relations entre plusieurs variables. Cela ressemble un peu à la façon dont, dans notre vie quotidienne, nous considérons comment des facteurs tels que la posture, la confiance en soi et les compétences en matière de communication influencent collectivement les performances lors d'un entretien, par exemple.
Explorons maintenant le SEM, ses applications et des exemples pratiques en Python. Si vous ne connaissez pas certaines des idées centrales, telles que l'idée de facteurs latents, vous pouvez également suivre notre cours sur l 'analyse factorielle.
La modélisation par équations structurelles représente les relations causales entre les variables latentes et observées. Les variables observées sont celles que nous pouvons mesurer directement. Les concepts latents sont déduits et non mesurés directement.
Pour saisir efficacement ces relations, la SEM est divisée en deux composantes principales : le modèle de mesure et le modèle structurel. Le modèle de mesure spécifie les relations entre les variables observées et les variables latentes correspondantes, tandis que le modèle structurel spécifie les relations entre les variables latentes.
Les techniques statistiques telles que la corrélation et la régression sont inefficaces pour étudier les relations complexes à plusieurs variables. Le SEM est adapté à la modélisation de concepts complexes, à multiples facettes, qui sont mesurés avec erreur. Il est également utile parce qu'il permet de spécifier un système de relations. Les méthodes traditionnelles nous aident à étudier une variable indépendante et un ensemble de prédicteurs. Bien que la corrélation ne soit pas la causalité, le SEM nous aide à comprendre la relation causale entre la variable observée et les concepts latents.
Parmi les applications du SEM, on peut citer
Voici quelques-uns des concepts fondamentaux de la modélisation par équations structurelles :
Bien que le SEM soit très utile pour modéliser les relations occasionnelles, il repose sur des hypothèses sous-jacentes concernant les données. Les hypothèses sont les suivantes :
Il existe différents types de modèles d'équations structurelles. Il s'agit, sans ordre particulier, de
Le développement d'un modèle SEM en Python ne nécessite que quelques étapes ; nous pouvons utiliser la bibliothèque semopy pour faciliter les choses. Le tutoriel suivant suppose que vous êtes familiarisé avec la syntaxe de Python.
pip install semopyNote: Pour les utilisateurs de macOS. Si vous rencontrez cette erreur lors de l'installation du paquet :
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATHInstallez graphviz via homebrew dans votre terminal
brew install graphvizAvant de télécharger notre jeu de données et de créer notre modèle, prenons une minute pour définir toutes nos constructions. En d'autres termes, nous devons identifier les variables latentes et observées. Dans le cas de notre ensemble de données, les variables observées nous ont été fournies en tant que caractéristiques étiquetées et sont x1 à x3 et y1 à y8. Les variables latentes que nous voulons étudier portent ces noms, que nous allons expliquer : ind60, dem60, dem65.
y1Liberté de la presse, 1960
y2Liberté de l'opposition politique, 1960
y3L'équité des élections, 1960
y4Efficacité de la législature élue, 1960
y5 -y8: sont les mêmes variables que y1-y4, respectivement, mesurées en 1965
x1Le PNB par habitant, 1960
x2Consommation d'énergie par habitant, 1960
x3Pourcentage de la main-d'œuvre dans l'industrie, 1960
ind60: variable latente exogène sur l'industrialisation.
dem60: variable latente endogène sur la démocratie en 1960.
dem65: variable latente endogène sur la démocratie en 1965.
L'objectif est de définir un modèle théorique pour spécifier la relation entre les concepts latents et les variables observées.
# Measurement model
ind60 =~ x1 + x2 + x3
demo60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8Nous préciserons ici les relations entre les concepts latents eux-mêmes.
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60Ici, nous voulons spécifier des variables qui sont fortement corrélées entre elles.
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5Pour ce tutoriel, nous utiliserons le jeu de données PoliticalDemocracy.csv fourni par semopy. Vous pouvez le télécharger en visitant ce dépôt GitHub.
Import pandas as pd
data = pd.read_csv('PoliticalDemocracy.csv')Nous devons combiner les définitions structurelles et de mesure dans une spécification de modèle.
# Define the SEM model specification
model_spec = """
# Measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# Correlations
y1 ~~ y5
y2 ~~ y4
y2 ~~ y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y5
"""Ensuite, nous définissons le modèle et ajustons les données
import semopy
# Define the model
model = semopy.Model(model_spec)
#Fit the model
model.fit(data)
# Inspect the results
print(model.inspect())Nous allons tracer le résultat du modèle pour comprendre la représentation du chemin. Le tracé sera sauvegardé sous political_sem_model.png.
semopy.semplot(model, 'political_sem_model.png')
print("SEM Model diagram saved as 'political_sem_model.png'.")
img = plt.imread('political_sem_model.png')
plt.imshow(img)
plt.axis('off')
plt.show()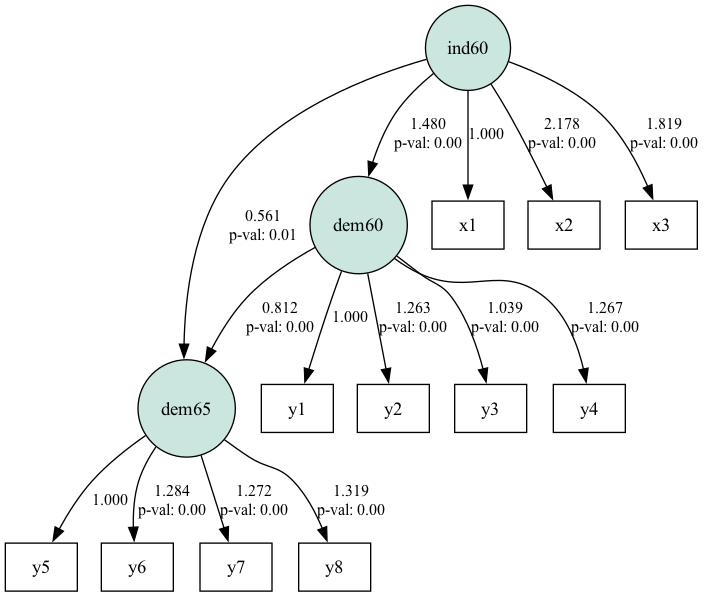
Diagramme de cheminement SEM pour l'ensemble de données sur la démocratie politique. Source : Image par l'auteur
Le diagramme montre comment le chemin relie les concepts latents (dans les cercles) et les variables observées. Les coefficients de cheminement proches de 1 ou de -1 indiquent des relations fortes entre les variables et ceux proches de 0 indiquent des relations faibles.
Les écarts types figurant dans le tableau se situent dans la fourchette. Des valeurs plus élevées peuvent indiquer une multicolinéarité ou une mauvaise spécification du modèle. Les valeurs p déterminent la signification statistique des coefficients de cheminement. Une valeur p inférieure à 0,05 indique généralement que le chemin est statistiquement significatif. Dans deux cas, la valeur p est supérieure à 0,05.
Dans l'ensemble, les résultats montrent que ind60 influence significativement dem60, qui à son tour influence significativement dem65.
Le modèle hypothétique doit correspondre aux relations observées pour évaluer l'adéquation du modèle SEM. Différents indices d'adéquation sont utilisés pour évaluer dans quelle mesure le modèle s'adapte aux données. Voici celles qui sont le plus souvent utilisées :
La technique de modélisation par équations structurelles pose souvent les problèmes suivants :
Dans cet article, nous avons examiné en profondeur le SEM, y compris ses applications, sa mise en œuvre, ses avantages et ses limites. Le SEM est un outil puissant pour examiner les relations complexes et les interactions causales entre les variables observées et latentes. Vous devriez l'essayer en Python ou en R pour votre prochain projet d'analyse.
Si vous êtes intéressé par l'idée de la modélisation des équations structurelles mais que vous préférez R, vous pouvez suivre le cours Structural Equation Modeling with lavaan in R, qui contient des instructions détaillées étape par étape. Vous pouvez également vous lancer dans le cursus de statisticien en R. Si vous êtes attaché à Python, lisez la documentation de semopy pour plus de cas d'utilisation de SEM en Python. Enfin, si vous êtes intéressé par des modèles Python avancés qui permettent à la fois de prédire et d'expliquer, et d'explorer les idées d'architecture de modèle et de sélection de caractéristiques, essayez notre cursus de carrière Machine Learning Scientist in Python.
Apprenez avec DataCamp
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
Tutoriel
DataCamp Team
Tutoriel
Abid Ali Awan
Tutoriel
Mark Pedigo