
Kursus
Pengantar Manajemen Risiko Portofolio dengan Python
4 Hr
29.3K
Setelah mengumpulkan data dan menghabiskan waktu berjam-jam untuk membersihkannya, Anda akhirnya bisa mulai mengeksplorasi! Tahap ini, yang sering disebut Exploratory Data Analysis (EDA), mungkin merupakan langkah terpenting dalam sebuah proyek data. Wawasan yang diperoleh dari EDA akan memengaruhi semua hal berikutnya.
Sebagai contoh, salah satu langkah wajib dalam EDA adalah memeriksa bentuk distribusi. Mengidentifikasi bentuk dengan benar akan memengaruhi banyak keputusan selanjutnya dalam proyek, seperti:
dan seterusnya. Meskipun ada visual untuk membantu tugas ini, Anda memerlukan metrik yang lebih andal untuk mengkuantifikasi berbagai karakteristik distribusi. Dua metrik tersebut adalah skewness dan kurtosis. Keduanya dapat digunakan untuk menilai seberapa mirip distribusi Anda dengan distribusi normal yang sempurna.
Dengan menuntaskan artikel ini, Anda akan mempelajari secara rinci:
Mari kita mulai!
Kita melihat distribusi normal di mana-mana: pengukuran tubuh manusia, bobot objek, skor IQ, hasil tes, bahkan di gym:

Selain menjadi distribusi favorit alam, distribusi ini juga disukai hampir semua algoritma machine learning. Ada yang membutuhkannya untuk meningkatkan dan menstabilkan performa, ada juga yang enggan bekerja dengan baik pada apa pun selain distribusi normal (ya, model linear, ini tentang Anda).
Jadi, untuk memenuhi kebutuhan algoritme akan kenormalan, kita memerlukan cara untuk mengukur seberapa mirip (atau tidak mirip) distribusi kita dibandingkan kurva lonceng yang sempurna.
Mari mulai dari ekornya. Pada distribusi normal yang sempurna, kedua ekornya sama panjang. Namun, ketika ada ketidaksimetrian antar ekor sehingga tampak condong, tertekan ke satu sisi, kita menyebutnya skewed (miring). Dan benar, kita mengukur tingkat ketidaksimetrian ini dengan skewness.
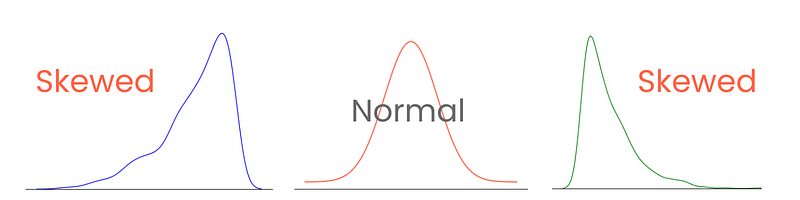
Mengategorikan dan mengukur skewness dengan benar memberikan wawasan tentang bagaimana nilai tersebar di sekitar mean dan memengaruhi pilihan teknik statistik serta transformasi data. Misalnya, distribusi yang sangat miring mungkin diuntungkan oleh teknik normalisasi atau penskalaan agar lebih menyerupai distribusi normal. Ini akan membantu kinerja model.
Ada tiga jenis skewness: positif, negatif, dan nol.
Mari mulai dari yang terakhir. Distribusi dengan skewness nol memiliki karakteristik berikut:
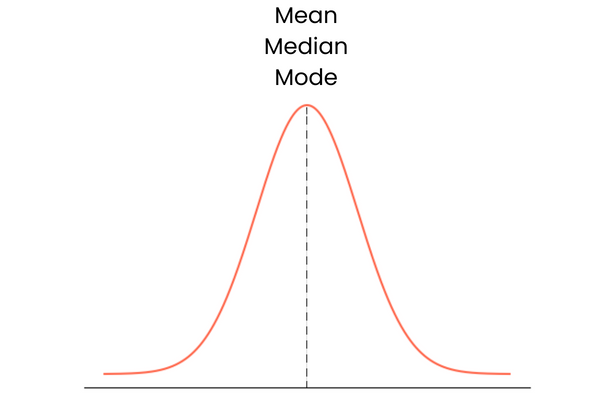
Dalam praktiknya, mean, median, dan modus mungkin tidak membentuk garis lurus yang sempurna saling menumpuk. Posisi mereka bisa sedikit berjauhan, tetapi perbedaannya terlalu kecil untuk berarti.
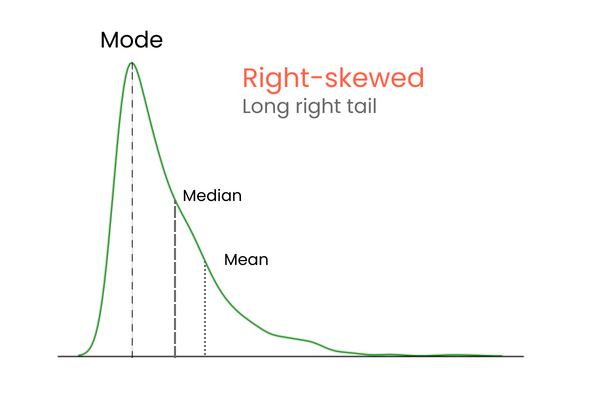
Pada distribusi dengan skewness positif (right-skewed):
Pada distribusi dengan skewness negatif (left-skewed):
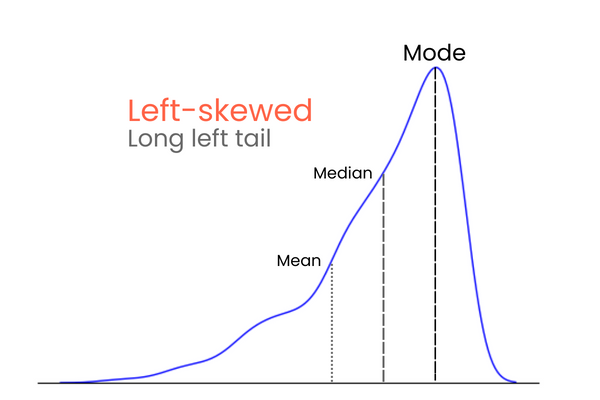
Untuk mengingat perbedaan antara skewness positif dan negatif, pikirkan seperti ini: jika Anda ingin menaikkan mean suatu distribusi, Anda harus menambahkan nilai yang jauh lebih tinggi daripada mean ke dalam distribusi. Untuk menurunkan mean, lakukan kebalikannya — masukkan nilai yang jauh lebih rendah daripada mean ke dalam distribusi. Jadi, jika mayoritas nilai ekstrem lebih tinggi daripada mean, skewness akan positif karena mereka menaikkan mean. Jika mayoritas nilai ekstrem lebih kecil daripada mean, skewness negatif karena mereka menurunkan mean.
Ada banyak cara untuk menghitung skewness, tetapi yang paling sederhana adalah koefisien skewness kedua Pearson, juga dikenal sebagai median skewness.
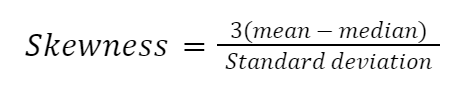
Mari kita implementasikan rumusnya secara manual di Python:
import numpy as np
import pandas as pd
import seaborn as sns
# Example dataset
diamonds = sns.load_dataset("diamonds")
diamond_prices = diamonds["price"]
mean_price = diamond_prices.mean()
median_price = diamond_prices.median()
std = diamond_prices.std()
skewness = (3 * (mean_price - median_price)) / std
>>> print(
f"The Pierson's second skewness score of diamond prices distribution is {skewness:.5f}"
)
The Pierson's second skewness score of diamond prices distribution is 1.15189
Rumus lain yang sangat dipengaruhi oleh karya Karl Pearson adalah rumus berbasis momen untuk mengaproksimasi skewness. Rumus ini lebih andal dan diberikan sebagai berikut:
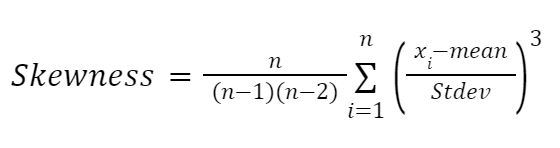
Di sini:
Mari kita implementasikan di Python juga:
def moment_based_skew(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
# Divide the formula into two parts
first_part = n / ((n - 1) * (n - 2))
second_part = np.sum(((distribution - mean) / std) ** 3)
skewness = first_part * second_part
return skewness
>>> moment_based_skew(diamond_prices)
1.618440289857168
Jika Anda tidak ingin menghitung skewness secara manual (seperti saya), Anda bisa menggunakan metode bawaan dari pandas atau scipy:
# Pandas version
diamond_prices.skew()
1.618395283383529
# SciPy version
from scipy.stats import skew
skew(diamond_prices)
1.6183502776053016
Walaupun semua rumus aproksimasi skewness menghasilkan skor yang berbeda, perbedaannya terlalu kecil untuk signifikan atau mengubah kategorisasi kemiringan. Misalnya, semua metode yang kita gunakan hari ini memakai rumus berbeda di balik layar, namun hasilnya sangat berdekatan.
Setelah menghitung skewness, Anda dapat mengategorikan tingkat kemiringannya:
Sementara skewness berfokus pada sebaran (ekor) dari distribusi normal, kurtosis lebih menyoroti tinggi puncak. Metode ini memberi tahu kita seberapa runcing atau datar distribusi normal (atau mirip normal) kita. Istilah ini, yang berarti melengkung atau melengkung busur dari bahasa Yunani, pertama kali diciptakan, tak mengejutkan, oleh matematikawan Inggris Karl Pearson (yang mendedikasikan hidupnya mempelajari distribusi peluang).
Kurtosis tinggi mengindikasikan:
Sebaliknya, kurtosis rendah mengindikasikan:
Bergantung pada derajatnya, distribusi memiliki tiga jenis kurtosis:
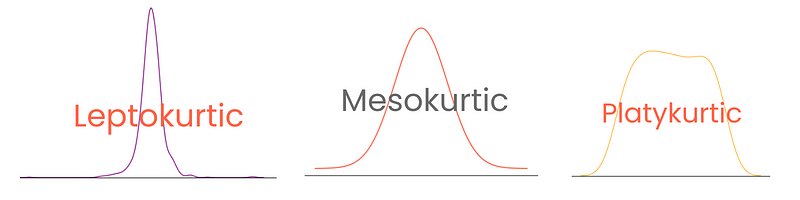
Perlu dicatat bahwa di sini, excess kurtosis didefinisikan sebagai kurtosis - 3, dengan menganggap kurtosis distribusi normal sebagai 0. Dengan cara ini, skor kurtosis menjadi lebih mudah ditafsirkan.
Anda dapat menghitung kurtosis di Python dengan cara yang sama seperti skewness menggunakan pandas atau SciPy:
from scipy.stats import kurtosis
kurtosis(diamond_prices)
2.177382669056634
Pandas menawarkan dua fungsi untuk kurtosis: kurt dan kurtosis. Yang pertama khusus untuk Pandas Series, sementara yang lainnya dapat digunakan pada DataFrame.
diamond_prices.kurt()
2.17769575924869
# Select numeric features and calculate kurtosis
diamonds.select_dtypes(include="number").kurtosis()
carat 1.256635
depth 5.739415
table 2.801857
price 2.177696
x -0.618161
y 91.214557
z 47.086619
dtype: float64
Sekali lagi, angkanya berbeda untuk distribusi yang sama karena pandas dan SciPy menggunakan rumus yang berbeda.
Jika Anda menginginkan perhitungan kurtosis secara manual, Anda dapat menggunakan rumus berikut:
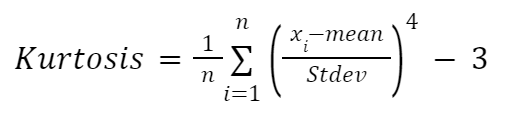
Di sini:
Kita akan mengimplementasikan rumus tersebut di dalam sebuah fungsi lagi:
def moment_based_kurtosis(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
kurtosis = (1 / n) * sum(((distribution - mean) / std) ** 4) - 3
return kurtosis
>>> moment_based_kurtosis(diamond_prices)
2.1773826690576463
Dan kita mengetahui bahwa harga berlian memiliki excess kurtosis sebesar 2,18, yang berarti jika kita plot distribusinya, ia akan memiliki puncak yang lebih tajam dibandingkan distribusi normal.
Jadi, mari kita lakukan!
Salah satu visual terbaik untuk melihat bentuk, dan dengan demikian skewness serta kurtosis suatu distribusi, adalah plot kernel density estimate (KDE). Visual ini tersedia melalui Seaborn:
import matplotlib.pyplot as plt
sns.kdeplot(diamond_prices)
plt.title("KDE plot of diamond prices")
plt.xlabel("Price ($)")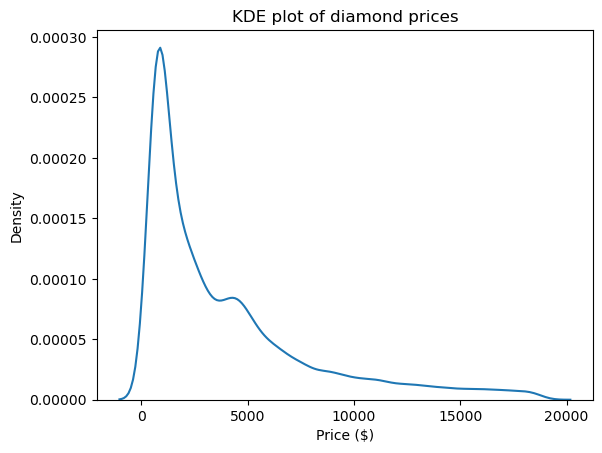
Plot ini selaras dengan angka yang kita lihat sejauh ini: distribusinya memiliki ekor kanan yang panjang, menandakan skewness positif, dan memiliki puncak yang sangat tajam, yang sesuai dengan kurtosis tinggi.
KDE bukan satu-satunya plot untuk melihat bentuk. Kita juga bisa menggunakan histogram:
sns.histplot(diamonds["carat"])
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")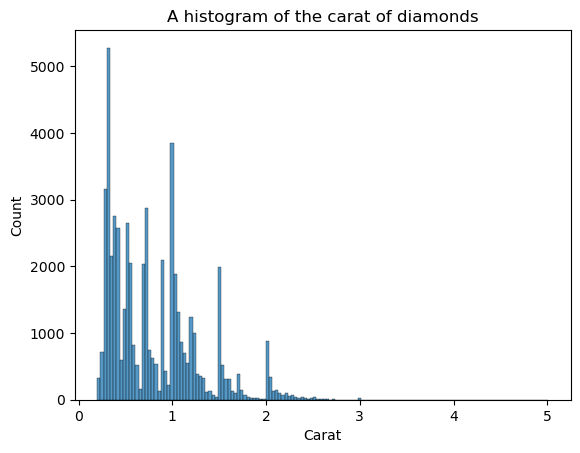
Kekurangan histogram adalah Anda harus memilih sendiri jumlah bin (jumlah batang). Di sini, batang terlalu banyak sehingga menimbulkan noise pada visual — kita tidak bisa mendefinisikan bentuknya dengan jelas. Jadi, mari kurangi jumlah bin:
sns.histplot(diamonds["carat"], bins=25)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")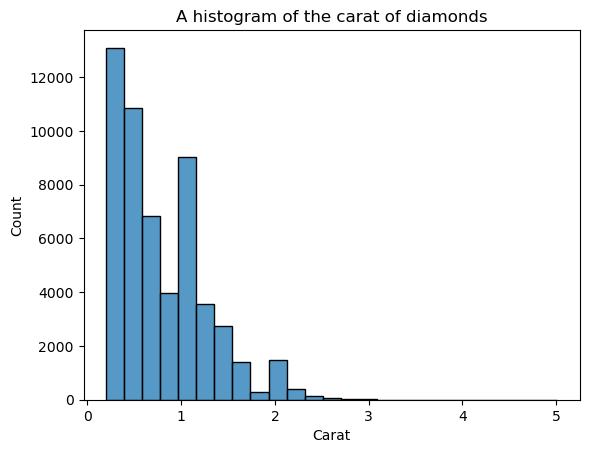
Sekarang, bentuknya lebih terdefinisi, tetapi kita masih bisa meningkatkannya. Dengan menyetel kde=True di dalam histplot, kita dapat memplot KDE distribusi di atas batang:
sns.histplot(diamonds["carat"], bins=25, kde=True)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")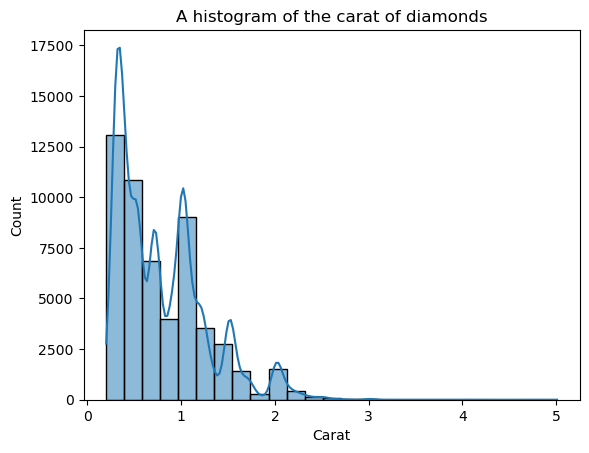
Garis KDE yang ditumpangkan tampak bergerigi, bukan kurva halus yang memungkinkan kita melihat bentuk umum. Penyebabnya adalah distribusi karat secara alami bergerigi dan jauh dari distribusi normal.
Namun, kita bisa mengurangi sensitivitas KDE terhadap fluktuasi ini dengan menyesuaikan bandwidth. Ini dilakukan menggunakan parameter bw_adjust, yang nilai default-nya 1:
# Change the bandwidth from 1 to 3
sns.kdeplot(diamonds["carat"], bw_adjust=3, color="red")
plt.title("KDE of diamond carats");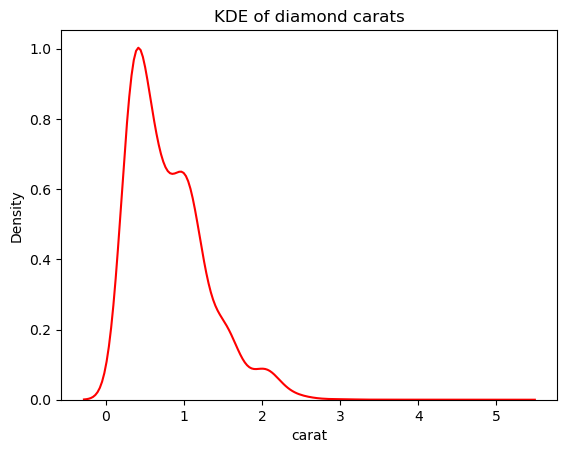
Versi ini jauh lebih tidak bergerigi dibandingkan KDE yang ditumpangkan tadi. Untuk menyesuaikan bandwidth KDE saat menggunakan histogram yang ditumpangi KDE, Anda dapat menggunakan parameter kde_kws:
ax = sns.histplot(
diamonds["carat"],
kde=True,
kde_kws=dict(bw_adjust=3),
bins=25,
)
plt.title("An overlaid histogram of diamond carats");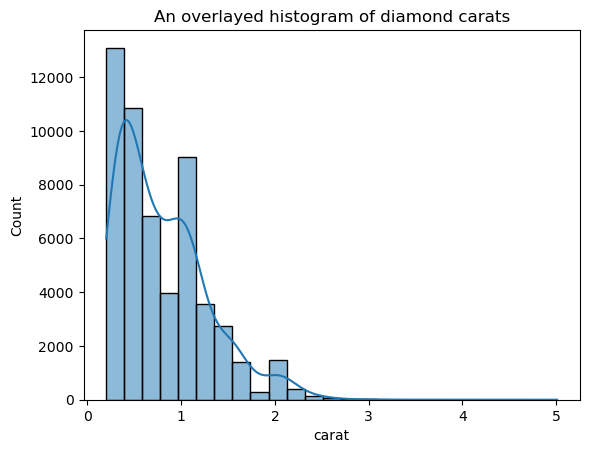
kde_kws menerima parameter apa pun yang dapat diterima oleh fungsi kdeplot untuk mengendalikan komputasi KDE.
Salah satu trik yang bisa Anda gunakan ketika memplot KDE adalah menghapus semua elemen selain garis KDE. Karena tujuan utama KDE adalah melihat bentuk distribusi, detail lain seperti penanda sumbu, garis tepi (spine), dan label terkadang tidak diperlukan:
sns.kdeplot(diamond_prices, color="red")
# Remove the spine from three sides
sns.despine(top=True, right=True, left=True)
# Remove the ticks and ticklabels
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
# Set a title
plt.title("Diamond prices", fontdict=dict(fontsize=20));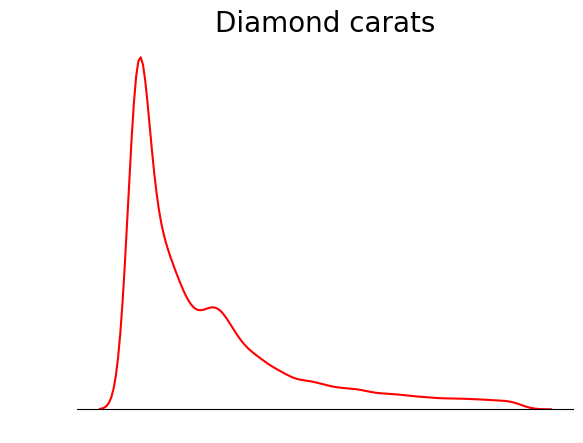
Plot ini jauh lebih rapi. Anda bisa lebih meningkatkannya dengan menambahkan garis untuk menandai posisi mean, median, dan modus:
sns.kdeplot(diamond_prices, color="red")
sns.despine(top=True, right=True, left=True)
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
plt.title("Diamond prices", fontdict=dict(fontsize=20))
# Find the mean, median, mode
mean_price = diamonds["price"].mean()
median_price = diamonds["price"].median()
mode_price = diamonds["price"].mode().squeeze()
# Add vertical lines at the position of mean, median, mode
plt.axvline(mean_price, label="Mean")
plt.axvline(median_price, color="black", label="Median")
plt.axvline(mode_price, color="green", label="Mode")
plt.legend();
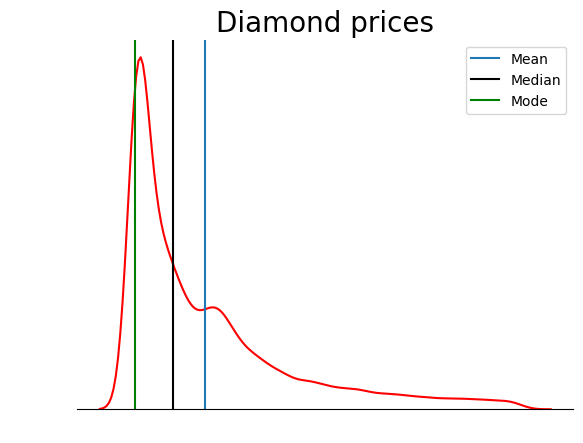
Plot ini memverifikasi apa yang kita bahas di bagian jenis-jenis skewness: pada distribusi yang miring positif, mean lebih tinggi daripada median, dan modus lebih rendah daripada mean maupun median.
Skewness dan kurtosis, yang sering terlewat dalam Exploratory Data Analysis, mengungkap wawasan penting tentang sifat suatu distribusi.
Skewness mengisyaratkan kemiringan data, apakah condong ke kiri atau ke kanan, memperlihatkan ketidaksimetri (jika ada). Skew positif berarti ekor memanjang ke kanan, sedangkan skew negatif mengarah ke sebaliknya.
Kurtosis berkaitan dengan puncak dan ekor. Kurtosis tinggi mempertajam puncak dan memberatkan ekor, sementara kurtosis rendah menyebarkan data sehingga ekor menjadi lebih ringan.
Jika Anda ingin mempelajari lebih lanjut tentang skewness dan kurtosis, Anda dapat melihat kursus analisis kuantitatif unggulan yang diajarkan para pakar industri di DataCamp berikut ini:
Pelajari Lebih Lanjut!
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
