
Kurs
Python ile Portföy Risk Yönetimine Giriş
4 sa
29.3K
Verileri topladıktan ve saatlerce temizledikten sonra, nihayet keşfetmeye başlayabilirsiniz! Sıkça Keşifsel Veri Analizi (Exploratory Data Analysis, EDA) olarak adlandırılan bu aşama, bir veri projesindeki belki de en önemli adımdır. EDA’dan elde edilen içgörüler, sonraki her şeyi etkiler.
Örneğin, EDA’da mutlaka yapılması gereken adımlardan biri dağılım şekillerini kontrol etmektir. Şekli doğru belirlemek, projede daha sonra verilecek birçok kararı etkiler. Örneğin:
vb. İş için görseller olsa da, dağılımların çeşitli özelliklerini nicelleştirmek için daha güvenilir ölçütlere ihtiyaç vardır. Bu ölçütlerden ikisi çarpıklık (skewness) ve basıklık (kurtosis)tir. Bunları, dağılımlarınızın kusursuz normal dağılıma ne kadar benzediğini değerlendirmek için kullanabilirsiniz.
Bu makaleyi bitirdiğinizde ayrıntılı olarak şunları öğreneceksiniz:
Haydi başlayalım!
Normal dağılımı her yerde görürüz: insan vücut ölçümleri, nesnelerin ağırlıkları, IQ puanları, sınav sonuçları, hatta spor salonunda bile:

Doğanın favori dağılımı olmasının yanı sıra, neredeyse tüm makine öğrenimi algoritmaları tarafından da sevilir. Bazıları performanslarını iyileştirmek ve istikrara kavuşturmak için normal dağılımı ister, bazıları ise normal dağılım dışında pek iyi çalışmayı reddeder (sana söylüyorum, doğrusal modeller).
Dolayısıyla algoritmaların normallik ihtiyacını karşılamak için, kendi dağılımlarımızın kusursuz çan eğrisiyle ne kadar benzer (veya benzemediğini) ölçmenin bir yoluna ihtiyaç duyarız.
Kuyruklardan başlayalım. Kusursuz bir normal dağılımda kuyruklar eşit uzunluktadır. Ancak kuyruklar arasında asimetri varsa ve dağılım bir tarafa doğru eğilmiş, sıkışmış görünüyorsa, çarpık olduğunu söyleriz. Ve tahmin ettiğiniz gibi, bu asimetrinin derecesini çarpıklıkla ölçeriz.
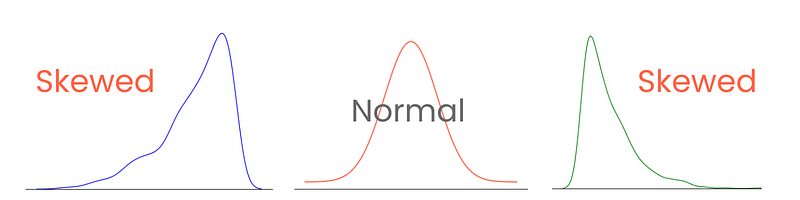
Çarpıklığı doğru kategorize etmek ve ölçmek, değerlerin ortalama etrafında nasıl yayıldığına dair içgörüler sağlar ve istatistiksel teknikler ile veri dönüşümlerinin seçimlerini etkiler. Örneğin, yüksek derecede çarpık dağılımlar, normalleştirme veya ölçekleme tekniklerinden fayda sağlayarak normal dağılıma daha çok benzetilebilir. Bu da model performansına yardımcı olur.
Üç tür çarpıklık vardır: pozitif, negatif ve sıfır çarpıklık.
Sonuncusundan başlayalım. Sıfır çarpıklığa sahip bir dağılım şu özelliklere sahiptir:
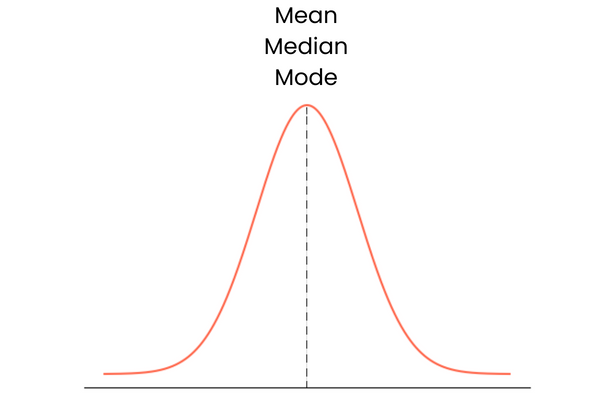
Pratikte, ortalama, medyan ve mod kusursuz biçimde üst üste binen düz bir çizgi oluşturmayabilir. Birbirlerinden biraz uzak olabilirler ancak fark önemsiz denecek kadar küçüktür.
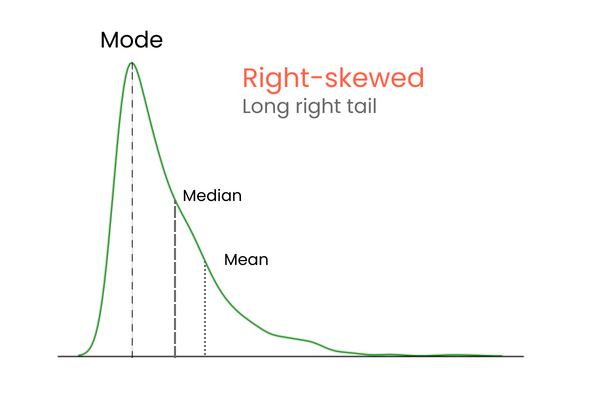
Pozitif çarpıklığa (sağa çarpık) sahip bir dağılımda:
Negatif çarpıklığa (sola çarpık) sahip bir dağılımda:
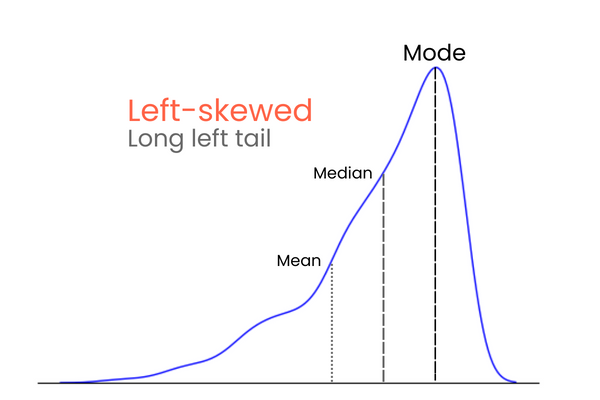
Pozitif ve negatif çarpıklık farkını akılda tutmak için şöyle düşünün: Bir dağılımın ortalamasını artırmak istiyorsanız, dağılıma ortalamadan çok daha yüksek değerler eklemelisiniz. Ortalama değerini düşürmek için bunun tersini yapmalısınız — dağılıma ortalamadan çok daha düşük değerler eklemelisiniz. Dolayısıyla aşırı değerlerin çoğu ortalamadan yüksekse, çarpıklık pozitiftir çünkü ortalamayı artırırlar. Aşırı değerlerin çoğu ortalamadan küçükse, çarpıklık negatiftir çünkü ortalamayı düşürürler.
Çarpıklığı hesaplamanın birçok yolu vardır, ancak en basiti Pearson’ın ikinci çarpıklık katsayısıdır; medyan çarpıklık olarak da bilinir.
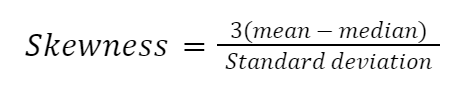
Formülü Python’da elle uygulayalım:
import numpy as np
import pandas as pd
import seaborn as sns
# Example dataset
diamonds = sns.load_dataset("diamonds")
diamond_prices = diamonds["price"]
mean_price = diamond_prices.mean()
median_price = diamond_prices.median()
std = diamond_prices.std()
skewness = (3 * (mean_price - median_price)) / std
>>> print(
f"The Pierson's second skewness score of diamond prices distribution is {skewness:.5f}"
)
The Pierson's second skewness score of diamond prices distribution is 1.15189
Karl Pearson’ın çalışmalarından büyük ölçüde etkilenen bir diğer formül ise çarpıklığı momentlere dayalı olarak yaklaşıklamak için kullanılır. Daha güvenilirdir ve şu şekilde verilir:
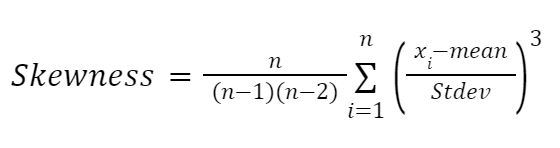
Burada:
Bunu da Python’da uygulayalım:
def moment_based_skew(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
# Divide the formula into two parts
first_part = n / ((n - 1) * (n - 2))
second_part = np.sum(((distribution - mean) / std) ** 3)
skewness = first_part * second_part
return skewness
>>> moment_based_skew(diamond_prices)
1.618440289857168
Çarpıklığı elle hesaplamak istemiyorsanız (benim gibi), pandas veya scipy’nin yerleşik yöntemlerini kullanabilirsiniz:
# Pandas version
diamond_prices.skew()
1.618395283383529
# SciPy version
from scipy.stats import skew
skew(diamond_prices)
1.6183502776053016
Tüm çarpıklık yaklaşım formülleri farklı skorlar döndürse de, aralarındaki farklar önemsizdir veya çarpıklığın kategorisini değiştirecek kadar büyük değildir. Örneğin, bugün kullandığımız tüm yöntemler kaputun altında farklı formüllerden yararlanır, fakat sonuçlar birbirine çok yakındır.
Çarpıklığı hesapladıktan sonra çarpıklığın derecesini kategorize edebilirsiniz:
Çarpıklık normal dağılımın yayılımına (kuyruklarına) odaklanırken, basıklık (kurtosis) daha çok yüksekliğe odaklanır. Normal (veya normale benzer) dağılımımızın ne kadar sivri veya düz olduğunu söyler. Yunancada kavisli/kemerli anlamına gelen bu terim, şaşırtıcı olmayan bir biçimde, Britanyalı matematikçi Karl Pearson tarafından ortaya atılmıştır (ömrünü olasılık dağılımlarını incelemeye adamıştır).
Yüksek basıklık şunları gösterir:
Öte yandan düşük basıklık şunları gösterir:
Derecesine bağlı olarak, dağılımlar üç tür basıklığa sahiptir:
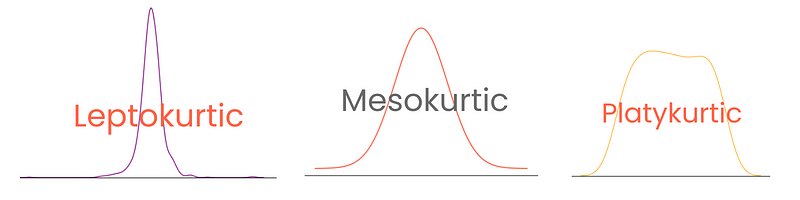
Burada aşırı basıklıkın basıklık - 3 olarak tanımlandığını ve normal dağılımın basıklığının 0 kabul edildiğini unutmayın. Bu şekilde basıklık skorları daha yorumlanabilir hale gelir.
Basıklığı Python’da, çarpıklıkta olduğu gibi pandas veya SciPy ile hesaplayabilirsiniz:
from scipy.stats import kurtosis
kurtosis(diamond_prices)
2.177382669056634
Pandas, basıklık için iki işlev sunar: kurt ve kurtosis. İlki yalnızca Pandas Series için geçerlidir, diğeri ise DataFrame’ler üzerinde kullanılabilir.
diamond_prices.kurt()
2.17769575924869
# Select numeric features and calculate kurtosis
diamonds.select_dtypes(include="number").kurtosis()
carat 1.256635
depth 5.739415
table 2.801857
price 2.177696
x -0.618161
y 91.214557
z 47.086619
dtype: float64
Yine, sayılar farklılık gösterir çünkü pandas ve SciPy farklı formüller kullanır.
Basıklığı elle hesaplamak isterseniz aşağıdaki formülü kullanabilirsiniz:
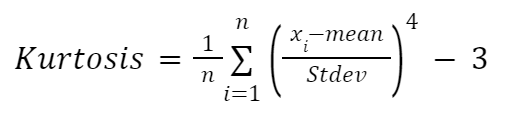
Burada:
Formülü yine bir fonksiyon içinde uygulayalım:
def moment_based_kurtosis(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
kurtosis = (1 / n) * sum(((distribution - mean) / std) ** 4) - 3
return kurtosis
>>> moment_based_kurtosis(diamond_prices)
2.1773826690576463
Ve görüyoruz ki elmas fiyatlarının aşırı basıklığı 2.18’dir; bu da dağılımı çizersek normal dağılıma göre daha sivri bir tepeye sahip olacağı anlamına gelir.
Öyleyse, bunu yapalım!
Dağılımların şeklini ve dolayısıyla çarpıklık ile basıklığını görmek için en iyi görsellerden biri çekirdek yoğunluk kestirimi (kernel density estimate, KDE) grafiğidir. Seaborn üzerinden kullanılabilir:
import matplotlib.pyplot as plt
sns.kdeplot(diamond_prices)
plt.title("KDE plot of diamond prices")
plt.xlabel("Price ($)")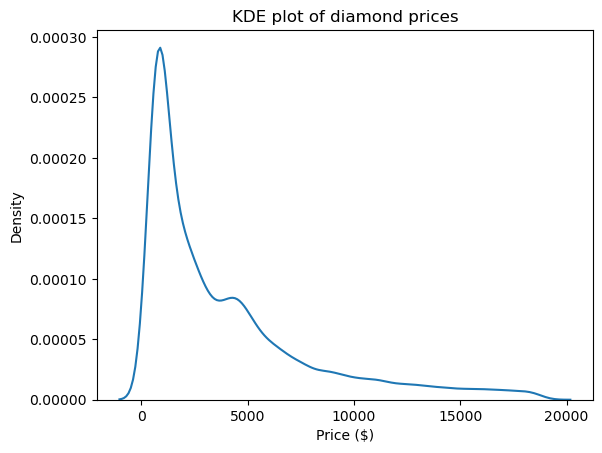
Bu grafik, şimdiye dek gördüğümüz sayılarla uyumludur: dağılımın uzun bir sağ kuyruğu vardır, bu da pozitif çarpıklığa işaret eder ve çok sivri bir tepeye sahiptir; bu da yüksek basıklığa karşılık gelir.
Şekli görmek için yalnızca KDE yok; histogramları da kullanabiliriz:
sns.histplot(diamonds["carat"])
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")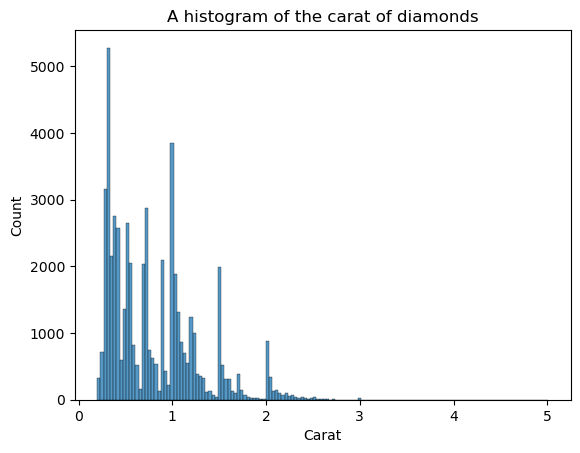
Histogramların dezavantajı, kutu (bar) sayısını kendiniz seçmeniz gerekmesidir. Burada çok fazla bar var ve görselde gürültü oluşturuyor — şekli net biçimde belirleyemiyoruz. O hâlde, kutu sayısını azaltalım:
sns.histplot(diamonds["carat"], bins=25)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")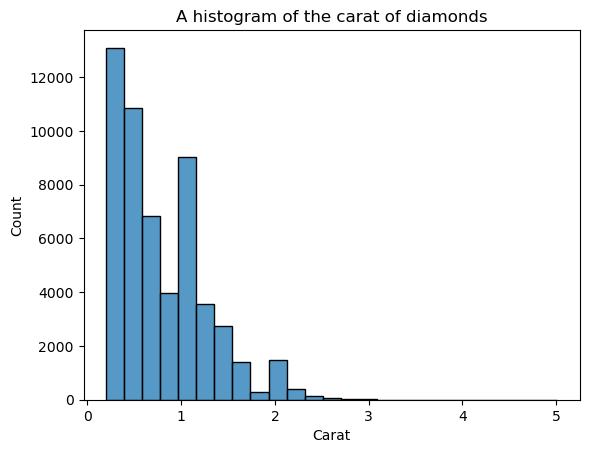
Şimdi şekil daha belirgin, ancak daha da iyileştirebiliriz. histplot içinde kde=True ayarlayarak, barların üzerine dağılımın KDE’sini çizebiliriz:
sns.histplot(diamonds["carat"], bins=25, kde=True)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")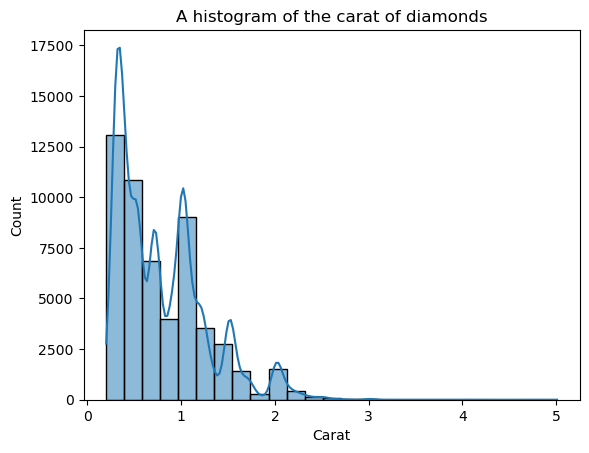
Bindirilmiş KDE çizgisi tırtıklı görünüyor; genel şekli görmemizi sağlayan pürüzsüz bir eğri değil. Bu tırtıklılığın nedeni, karat dağılımının doğası gereği sivri ve normal dağılımdan oldukça uzak olmasıdır.
Ancak, bant genişliğini ayarlayarak KDE’nin bu dalgalanmalara duyarlılığını azaltabiliriz. Bu, varsayılanı 1 olan bw_adjust parametresiyle yapılır:
# Change the bandwidth from 1 to 3
sns.kdeplot(diamonds["carat"], bw_adjust=3, color="red")
plt.title("KDE of diamond carats");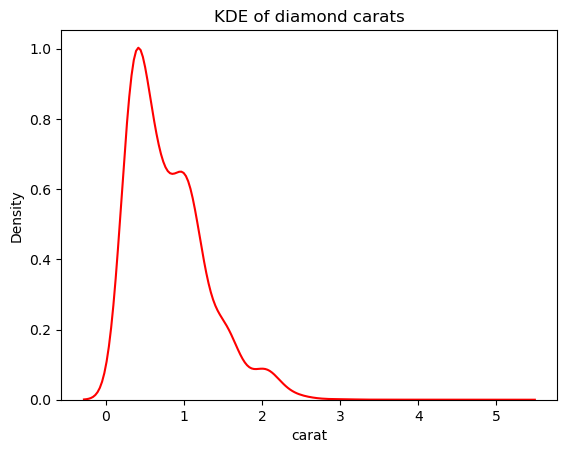
Bu sürüm, bindirilmiş KDE grafiğine göre çok daha az sivri görünüyor. Histogram üzerine KDE bindirirken KDE bant genişliğini ayarlamak için kde_kws parametresini kullanabilirsiniz:
ax = sns.histplot(
diamonds["carat"],
kde=True,
kde_kws=dict(bw_adjust=3),
bins=25,
)
plt.title("An overlaid histogram of diamond carats");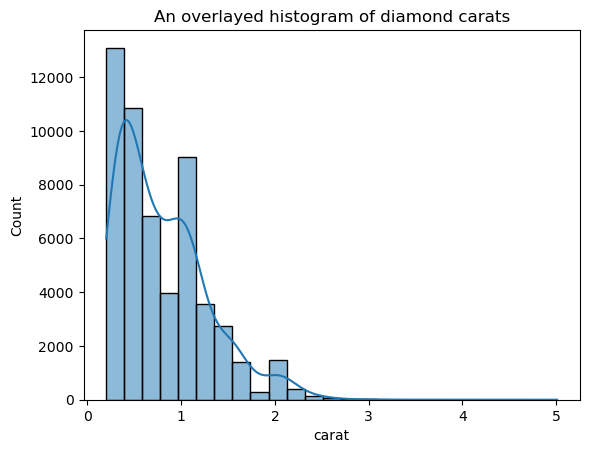
kde_kws, KDE hesaplamasını kontrol eden kdeplot işlevinin kabul ettiği herhangi bir parametreyi kabul eder.
KDE çizerken kullanabileceğiniz bir püf noktası da KDE çizgisi dışında her şeyi kaldırmaktır. Bir KDE’nin ana amacı dağılım şeklini görmek olduğundan, eksen işaretleri, çerçeve çizgileri ve etiketler gibi diğer ayrıntılar bazen gereksiz olabilir:
sns.kdeplot(diamond_prices, color="red")
# Remove the spine from three sides
sns.despine(top=True, right=True, left=True)
# Remove the ticks and ticklabels
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
# Set a title
plt.title("Diamond prices", fontdict=dict(fontsize=20));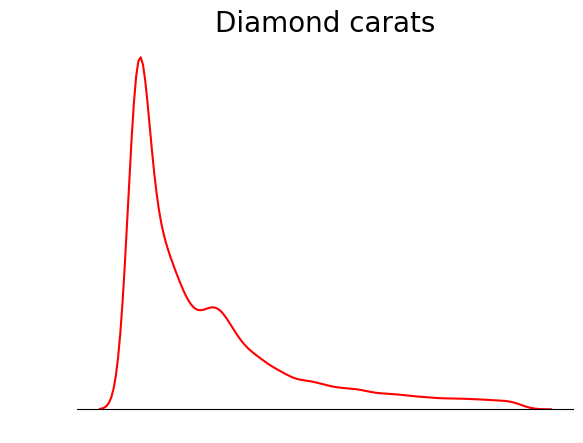
Bu grafik çok daha derli toplu. Grafiği, ortalama, medyan ve modun konumunu göstermek için çizgiler ekleyerek daha da iyileştirebilirsiniz:
sns.kdeplot(diamond_prices, color="red")
sns.despine(top=True, right=True, left=True)
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
plt.title("Diamond prices", fontdict=dict(fontsize=20))
# Find the mean, median, mode
mean_price = diamonds["price"].mean()
median_price = diamonds["price"].median()
mode_price = diamonds["price"].mode().squeeze()
# Add vertical lines at the position of mean, median, mode
plt.axvline(mean_price, label="Mean")
plt.axvline(median_price, color="black", label="Median")
plt.axvline(mode_price, color="green", label="Mode")
plt.legend();
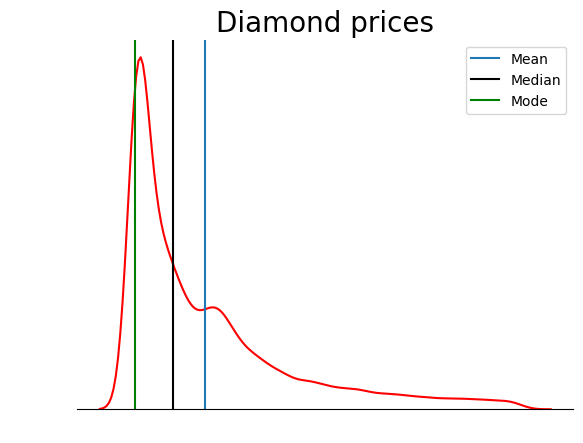
Bu grafik, çarpıklık türleri bölümünde tartıştıklarımızı doğrular: pozitif çarpık bir dağılımda ortalama, medyandan yüksektir ve mod hem ortalama hem medyandan düşüktür.
Keşifsel Veri Analizi sırasında sıkça gözden kaçan çarpıklık ve basıklık, dağılımların doğası hakkında önemli içgörüler sunar.
Çarpıklık, verinin sola mı yoksa sağa mı meylettiğine, yani varsa asimetrisine işaret eder. Pozitif çarpıklık sağa uzayan bir kuyruk demektir; negatif çarpıklık ise tam tersidir.
Basıklık, tamamen tepeler ve kuyruklarla ilgilidir. Yüksek basıklık tepeleri sivriltir ve kuyrukları ağırlaştırır; düşük basıklık ise veriyi yayar ve kuyrukları hafifletir.
Çarpıklık ve basıklık hakkında daha fazla bilgi edinmek isterseniz, DataCamp’te sektör uzmanları tarafından verilen şu nitelikli nicel analiz kurslarına göz atabilirsiniz:
Daha Fazlasını Öğrenin!
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
