
Cursus
Introductie tot portefeuillerisicobeheer in Python
4 Hr
29.3K
Na het verzamelen van data en uren schoonmaken kun je ein-de-lijk gaan verkennen! Deze fase, vaak Exploratory Data Analysis (EDA) genoemd, is misschien wel de belangrijkste stap in een dataproject. De inzichten uit EDA hebben invloed op alles wat daarna komt.
Een van de must-do stappen in EDA is bijvoorbeeld het controleren van de vormen van verdelingen. De vorm correct bepalen beïnvloedt later in het project veel keuzes, zoals:
enzovoort. Hoewel er visuals zijn om de taak te doen, heb je betrouwbaardere metrics nodig om verschillende kenmerken van verdelingen te kwantificeren. Twee van zulke metrics zijn skewness en kurtosis. Je kunt ze gebruiken om te beoordelen hoezeer jouw verdelingen lijken op een perfecte, normale verdeling.
Na het lezen van dit artikel weet je in detail:
Laten we beginnen!
We zien de normale verdeling overal: lichaamsmaten, gewichten van objecten, IQ-scores, toetsresultaten of zelfs in de sportschool:

Behalve dat het de favoriete verdeling van de natuur is, is hij ook geliefd bij bijna alle machinelearningalgoritmen. Sommigen willen hem om hun prestaties te verbeteren en te stabiliseren, anderen weigeren ronduit goed te werken met iets anders dan een normale verdeling (ik kijk naar jullie, lineaire modellen).
Dus, om aan de behoefte van de algoritmen aan normaliteit te voldoen, hebben we een manier nodig om te meten hoe (on)gelijk onze eigen verdelingen zijn aan de perfecte klokvormige curve.
Laten we beginnen met de staarten. In een perfecte normale verdeling zijn de staarten even lang. Maar als er asymmetrie tussen de staarten is, waardoor de verdeling scheef of naar één kant gedrukt lijkt, zeggen we dat hij skewed is. En je raadt het al: we meten de mate van deze asymmetrie met skewness.
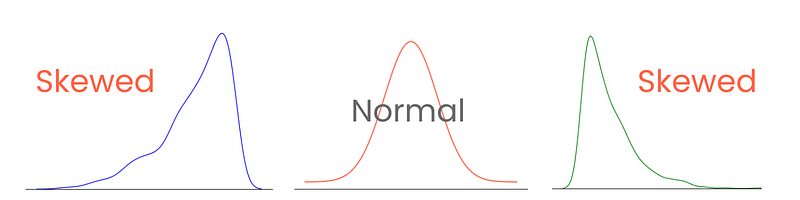
Skewness correct categoriseren en meten geeft inzicht in hoe waarden rond het gemiddelde verspreid zijn en beïnvloedt de keuze van statistische technieken en datatransformaties. Zo kunnen sterk scheve verdelingen baat hebben bij normalisatie- of scalingtechnieken om meer op een normale verdeling te lijken. Dat helpt de modelprestaties.
Er zijn drie typen skewness: positief, negatief en nul skewness.
Laten we met de laatste beginnen. Een verdeling met nul skewness heeft de volgende kenmerken:
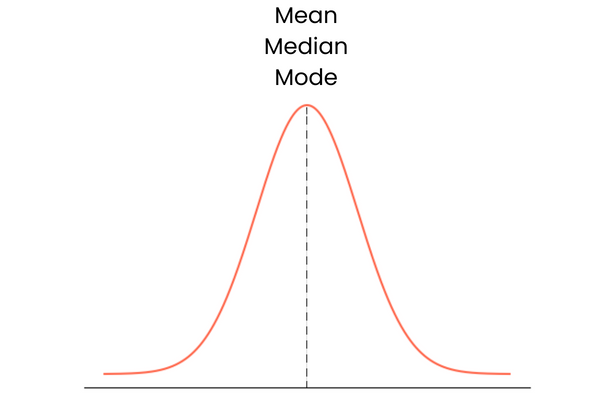
In de praktijk vormen mean, median en mode misschien geen perfect overlappende rechte lijn. Ze kunnen iets van elkaar af liggen, maar het verschil is te klein om uit te maken.
In een verdeling met positieve skewness (rechts-scheef):
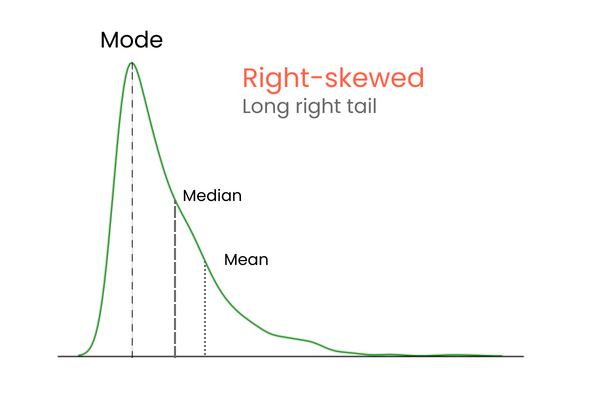
In een verdeling met negatieve skewness (links-scheef):
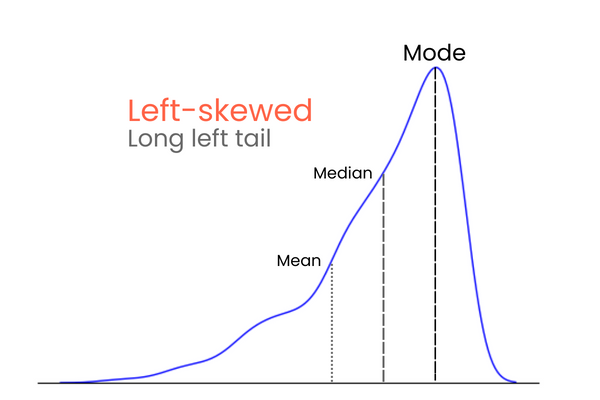
Om het verschil tussen positieve en negatieve skewness te onthouden, kun je het zo zien: als je het gemiddelde van een verdeling wilt verhogen, moet je veel hogere waarden dan het gemiddelde toevoegen. Om het gemiddelde te verlagen, doe je het omgekeerde — voeg veel lagere waarden dan het gemiddelde toe. Dus als de meerderheid van de extreme waarden hoger is dan het gemiddelde, is de skewness positief omdat ze het gemiddelde verhogen. Als de meerderheid van de extreme waarden kleiner is dan het gemiddelde, is de skewness negatief omdat ze het gemiddelde verlagen.
Er zijn veel manieren om skewness te berekenen, maar de eenvoudigste is Pearsons tweede skewnesscoëfficiënt, ook wel median skewness genoemd.
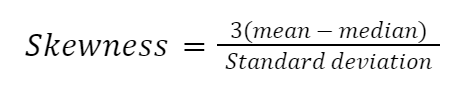
Laten we de formule handmatig implementeren in Python:
import numpy as np
import pandas as pd
import seaborn as sns
# Example dataset
diamonds = sns.load_dataset("diamonds")
diamond_prices = diamonds["price"]
mean_price = diamond_prices.mean()
median_price = diamond_prices.median()
std = diamond_prices.std()
skewness = (3 * (mean_price - median_price)) / std
>>> print(
f"The Pierson's second skewness score of diamond prices distribution is {skewness:.5f}"
)
The Pierson's second skewness score of diamond prices distribution is 1.15189
Een andere formule die sterk beïnvloed is door het werk van Karl Pearson is de momentgebaseerde formule om skewness te benaderen. Die is betrouwbaarder en luidt als volgt:
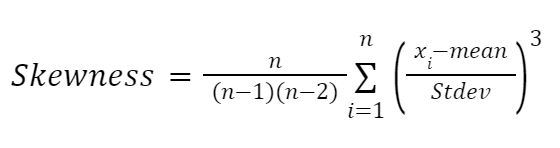
Hierbij:
Laten we het ook in Python implementeren:
def moment_based_skew(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
# Divide the formula into two parts
first_part = n / ((n - 1) * (n - 2))
second_part = np.sum(((distribution - mean) / std) ** 3)
skewness = first_part * second_part
return skewness
>>> moment_based_skew(diamond_prices)
1.618440289857168
Als je skewness niet handmatig wilt berekenen (zoals ik), kun je ingebouwde methoden uit pandas of scipy gebruiken:
# Pandas version
diamond_prices.skew()
1.618395283383529
# SciPy version
from scipy.stats import skew
skew(diamond_prices)
1.6183502776053016
Hoewel alle formules om skewness te benaderen verschillende scores opleveren, zijn de verschillen te klein om significant te zijn of de categorisatie van de scheefheid te veranderen. Alle methoden die we vandaag hebben gebruikt hanteren onder de motorkap verschillende formules, maar de resultaten liggen dicht bij elkaar.
Zodra je skewness hebt berekend, kun je de mate van scheefheid categoriseren:
Waar skewness zich richt op de spreiding (staarten) van de normale verdeling, focust kurtosis meer op de hoogte. Het vertelt ons hoe spits of plat onze normale (of normaal-achtige) verdeling is. De term, die in het Grieks gebogen of gewelfd betekent, werd voor het eerst geïntroduceerd door — niet verrassend — de Britse wiskundige Karl Pearson (hij besteedde zijn leven aan kansverdelingen).
Hoge kurtosis duidt op:
Lage kurtosis duidt daarentegen op:
Afhankelijk van de mate hebben verdelingen drie typen kurtosis:
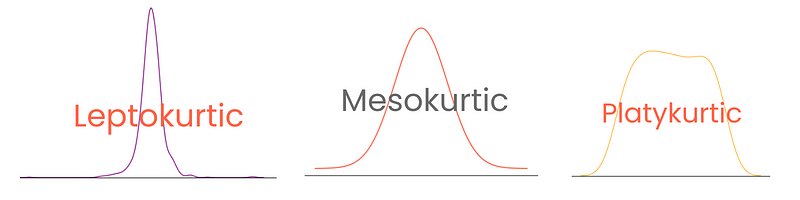
Let op dat excess kurtosis hier is gedefinieerd als kurtosis - 3, waarbij de kurtosis van de normale verdeling als 0 wordt beschouwd. Zo zijn kurtosisscores beter te interpreteren.
Je kunt kurtosis in Python op dezelfde manier berekenen als skewness met pandas of SciPy:
from scipy.stats import kurtosis
kurtosis(diamond_prices)
2.177382669056634
Pandas biedt twee functies voor kurtosis: kurt en kurtosis. De eerste is exclusief voor Pandas Series, terwijl je de andere op DataFrames kunt gebruiken.
diamond_prices.kurt()
2.17769575924869
# Select numeric features and calculate kurtosis
diamonds.select_dtypes(include="number").kurtosis()
carat 1.256635
depth 5.739415
table 2.801857
price 2.177696
x -0.618161
y 91.214557
z 47.086619
dtype: float64
Wederom verschillen de getallen voor de verdeling omdat pandas en SciPy verschillende formules gebruiken.
Als je kurtosis handmatig wilt berekenen, kun je de volgende formule gebruiken:
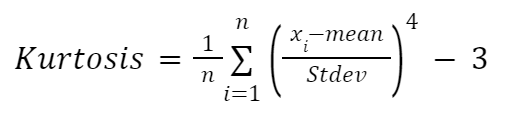
Hierbij:
We implementeren de formule opnieuw in een functie:
def moment_based_kurtosis(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
kurtosis = (1 / n) * sum(((distribution - mean) / std) ** 4) - 3
return kurtosis
>>> moment_based_kurtosis(diamond_prices)
2.1773826690576463
En zo ontdekken we dat diamantprijzen een excess kurtosis van 2,18 hebben, wat betekent dat de verdeling, als we die plotten, een scherpere piek heeft dan een normale verdeling.
Dus, laten we dat doen!
Een van de beste visuals om de vorm en dus de skewness en kurtosis van verdelingen te zien is een kernel density estimate (KDE)-plot. Die is beschikbaar via Seaborn:
import matplotlib.pyplot as plt
sns.kdeplot(diamond_prices)
plt.title("KDE plot of diamond prices")
plt.xlabel("Price ($)")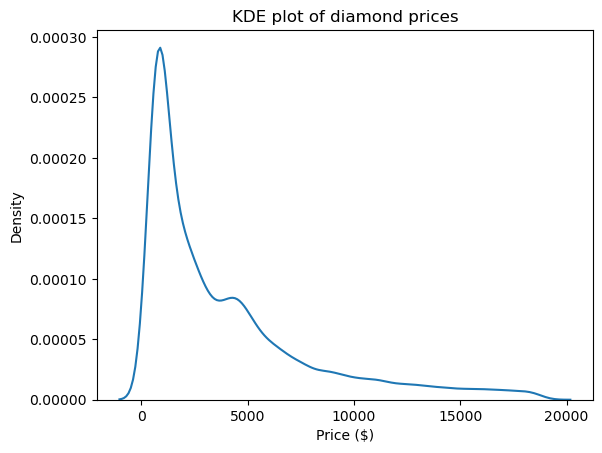
Deze plot komt overeen met de cijfers die we tot nu toe zagen: de verdeling heeft een lange rechterstaart, wat duidt op positieve skewness, en een zeer scherpe piek, wat overeenkomt met hoge kurtosis.
KDE is niet de enige plot om de vorm te zien. We kunnen ook histogrammen gebruiken:
sns.histplot(diamonds["carat"])
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")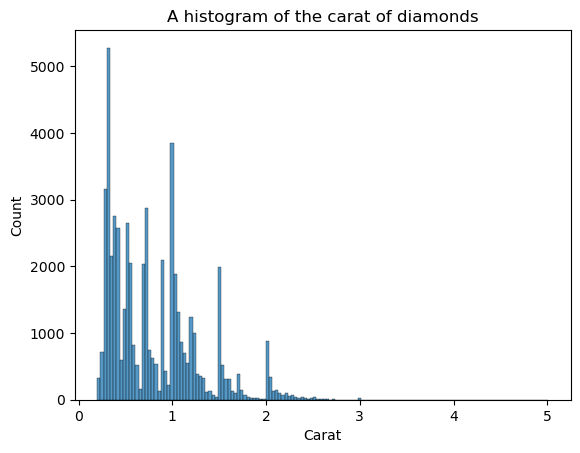
Het nadeel van histogrammen is dat je zelf het aantal bins (het aantal balken) moet kiezen. Hier zijn er te veel balken, wat ruis creëert in de visual — we kunnen de vorm niet duidelijk bepalen. Laten we daarom het aantal bins verlagen:
sns.histplot(diamonds["carat"], bins=25)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")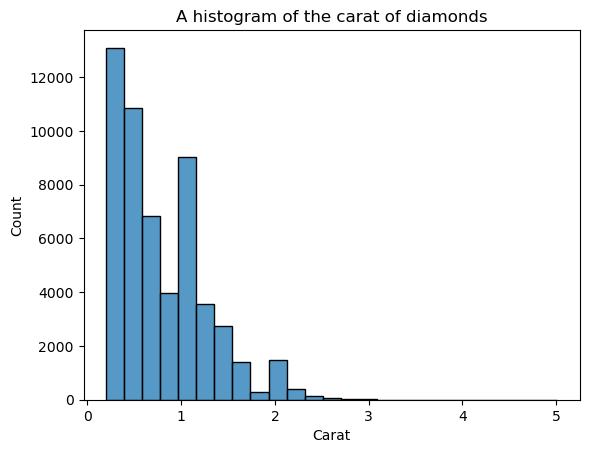
Nu is de vorm beter gedefinieerd, maar we kunnen het nog verbeteren. Door kde=True in histplot te zetten, kunnen we een KDE van de verdeling boven op de balken plotten:
sns.histplot(diamonds["carat"], bins=25, kde=True)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")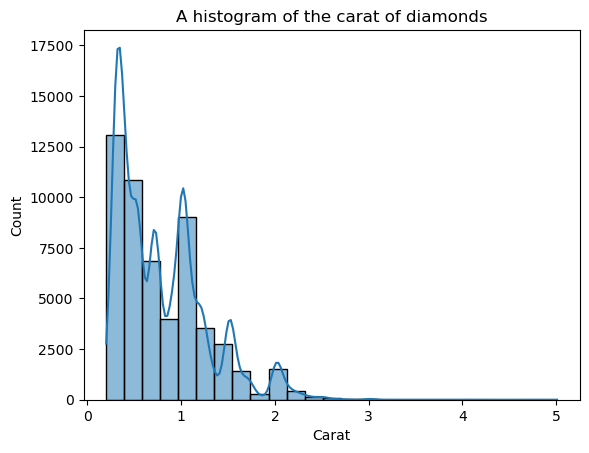
De overlayde KDE-lijn ziet er hoekig uit, niet de soepele curve die ons de algemene vorm laat zien. De reden is dat de karaatverdeling van nature spichtig is en ver van de normale verdeling afstaat.
We kunnen echter de gevoeligheid van de KDE voor deze fluctuaties verlagen door de bandbreedte aan te passen. Dit doe je met de parameter bw_adjust, die standaard 1 is:
# Change the bandwidth from 1 to 3
sns.kdeplot(diamonds["carat"], bw_adjust=3, color="red")
plt.title("KDE of diamond carats");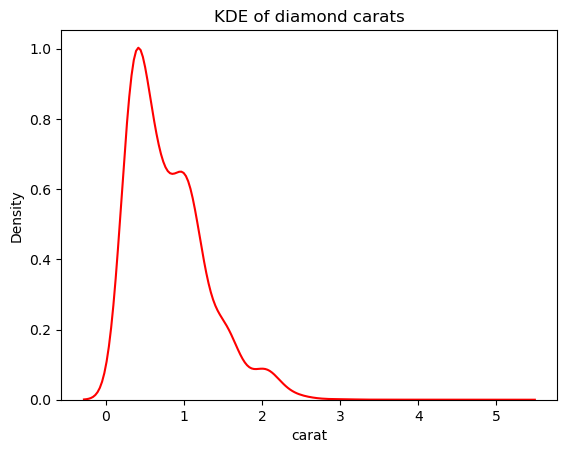
Deze versie oogt veel minder spichtig dan de overlayde KDE-plot. Om de KDE-bandbreedte aan te passen wanneer je een histogram met KDE gebruikt, kun je de parameter kde_kws gebruiken:
ax = sns.histplot(
diamonds["carat"],
kde=True,
kde_kws=dict(bw_adjust=3),
bins=25,
)
plt.title("An overlaid histogram of diamond carats");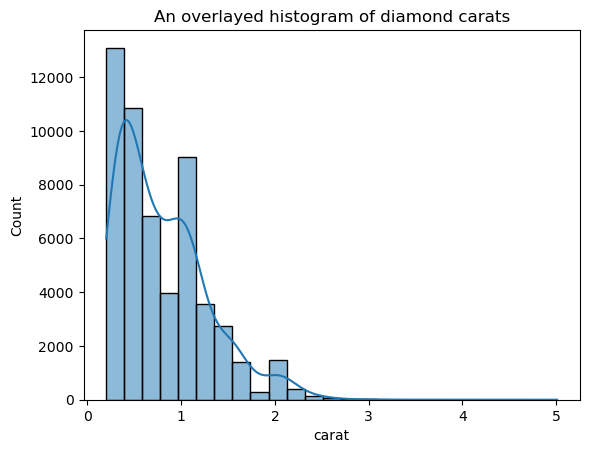
kde_kws accepteert elke parameter die ook door de functie kdeplot wordt geaccepteerd en die de KDE-berekening aanstuurt.
Een truc die je kunt gebruiken bij het plotten van KDE’s is alles weghalen behalve de KDE-lijn. Omdat het bij een KDE vooral gaat om de vorm van de verdeling, zijn andere details zoals as-ticks, spines en labels soms overbodig:
sns.kdeplot(diamond_prices, color="red")
# Remove the spine from three sides
sns.despine(top=True, right=True, left=True)
# Remove the ticks and ticklabels
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
# Set a title
plt.title("Diamond prices", fontdict=dict(fontsize=20));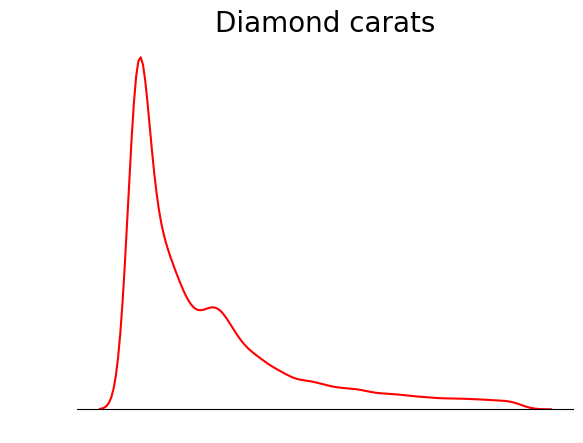
Deze plot is een stuk strakker. Je kunt de plot verder verbeteren door lijnen toe te voegen die de positie van mean, median en mode aangeven:
sns.kdeplot(diamond_prices, color="red")
sns.despine(top=True, right=True, left=True)
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
plt.title("Diamond prices", fontdict=dict(fontsize=20))
# Find the mean, median, mode
mean_price = diamonds["price"].mean()
median_price = diamonds["price"].median()
mode_price = diamonds["price"].mode().squeeze()
# Add vertical lines at the position of mean, median, mode
plt.axvline(mean_price, label="Mean")
plt.axvline(median_price, color="black", label="Median")
plt.axvline(mode_price, color="green", label="Mode")
plt.legend();
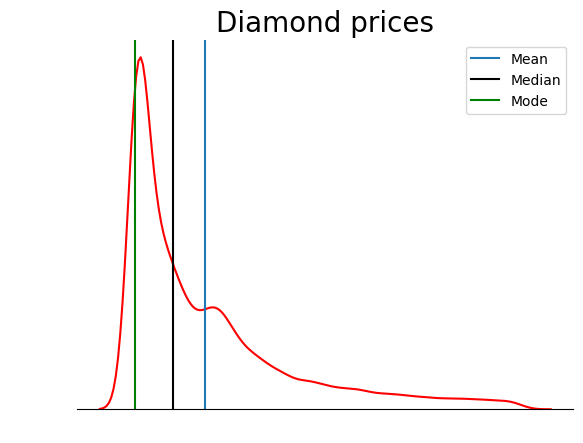
Deze plot bevestigt wat we in de sectie over typen skewness bespraken: in een positief scheve verdeling is het gemiddelde hoger dan de mediaan en is de modus lager dan zowel gemiddelde als mediaan.
Skewness en kurtosis, vaak over het hoofd gezien in Exploratory Data Analysis, onthullen belangrijke inzichten over de aard van verdelingen.
Skewness geeft een hint van de kanteling van data, of die naar links of rechts helt, en toont de asymmetrie (als die er is). Positieve skew betekent een staart die naar rechts uitstrekt, terwijl negatieve skew de andere kant op gaat.
Kurtosis draait om pieken en staarten. Hoge kurtosis verscherpt pieken en verzwaart de staarten, terwijl lage kurtosis data meer spreidt en de staarten lichter maakt.
Wil je meer leren over skewness en kurtosis? Bekijk dan deze uitstekende cursussen over kwantitatieve analyse, gegeven door industrie-experts op DataCamp:
Meer leren!
Cursus
Cursus
blog
Adel Nehme
15 min
