
Corso
Introduzione alla gestione del rischio di portafoglio in Python
4 h
29.3K
Dopo aver raccolto i dati e aver passato ore a ripulirli, puoi finalmente iniziare a esplorarli! Questa fase, spesso chiamata Exploratory Data Analysis (EDA), è probabilmente il passaggio più importante in un progetto di dati. Le intuizioni ricavate dall’EDA influenzano tutto ciò che viene dopo.
Per esempio, uno dei passaggi imprescindibili nell’EDA è controllare le forme delle distribuzioni. Identificare correttamente la forma influenza molte decisioni successive nel progetto, come:
e così via. Sebbene esistano visualizzazioni per farlo, servono metriche più affidabili per quantificare diverse caratteristiche delle distribuzioni. Due di queste metriche sono asimmetria e curtosi. Puoi usarle per valutare quanto le tue distribuzioni assomigliano a una distribuzione normale perfetta.
Al termine di questo articolo, imparerai nel dettaglio:
Iniziamo!
Vediamo la distribuzione normale ovunque: misure del corpo umano, pesi degli oggetti, punteggi del QI, risultati dei test, o persino in palestra:

Oltre a essere la distribuzione preferita dalla natura, è amata universalmente da quasi tutti gli algoritmi di machine learning. Alcuni la desiderano per migliorare e stabilizzare le prestazioni, altri si rifiutano del tutto di funzionare bene con qualcosa di diverso dalla distribuzione normale (sì, sto parlando con voi, modelli lineari).
Quindi, per soddisfare il bisogno di normalità degli algoritmi, ci serve un modo per misurare quanto le nostre distribuzioni siano simili (o dissimili) rispetto alla curva perfetta a campana.
Partiamo dalle code. In una distribuzione normale perfetta, le code hanno uguale lunghezza. Quando però c’è asimmetria tra le code, che dà un aspetto inclinato, schiacciato da un lato, diciamo che è asimmetrica. E, come avrai intuito, misuriamo il grado di questa asimmetria con l’asimettria (skewness).
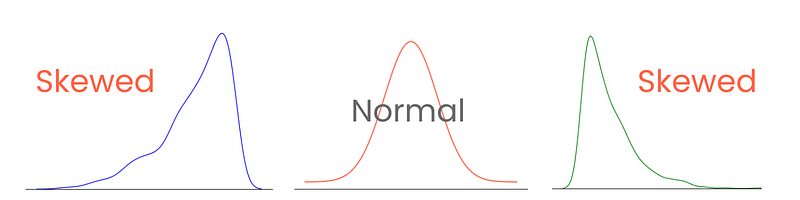
Classificare e misurare correttamente l’asimmetria offre indicazioni su come i valori sono distribuiti attorno alla media e influenza la scelta delle tecniche statistiche e delle trasformazioni dei dati. Per esempio, distribuzioni molto asimmetriche possono trarre vantaggio da tecniche di normalizzazione o scaling per farle assomigliare di più a una distribuzione normale. Questo può aiutare le prestazioni del modello.
Esistono tre tipi di asimmetria: positiva, negativa e nulla.
Partiamo dall’ultima. Una distribuzione con asimmetria nulla ha le seguenti caratteristiche:
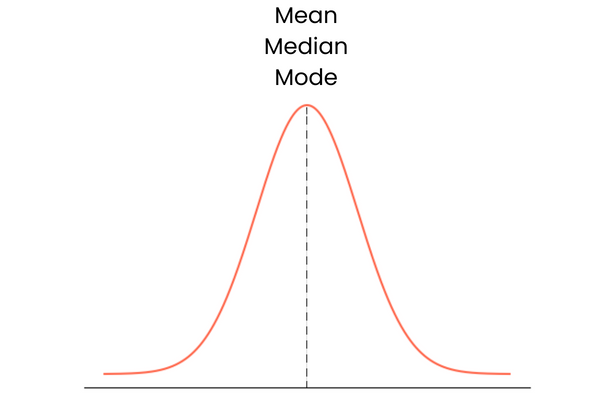
In pratica, media, mediana e moda potrebbero non formare una linea retta perfettamente sovrapposta. Potrebbero essere leggermente distanti tra loro, ma la differenza sarebbe troppo piccola per contare.
In una distribuzione con asimmetria positiva (a destra):
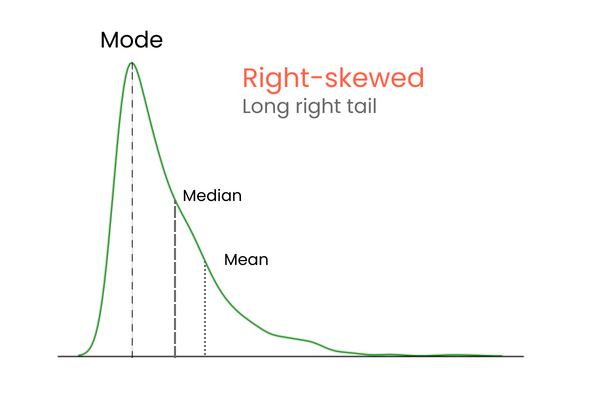
In una distribuzione con asimmetria negativa (a sinistra):
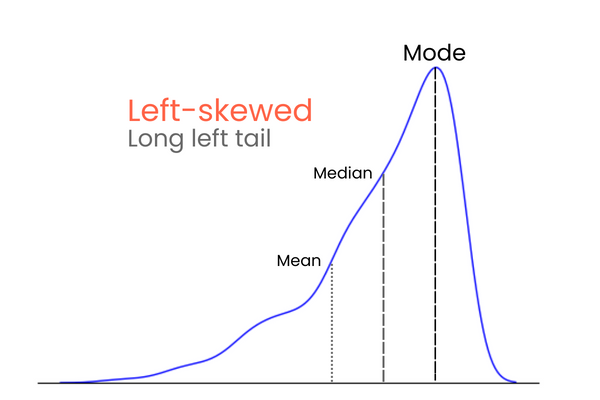
Per ricordare la differenza tra asimmetria positiva e negativa, pensa così: se vuoi aumentare la media di una distribuzione, devi aggiungere alla distribuzione valori molto più alti della media. Per abbassare la media, devi fare il contrario — introdurre valori molto più bassi della media. Quindi, se la maggior parte dei valori estremi è superiore alla media, l’asimettria sarà positiva perché aumentano la media. Se la maggior parte dei valori estremi è inferiore alla media, l’asimettria è negativa perché abbassano la media.
Ci sono molti modi per calcolare l’asimmetria, ma il più semplice è il secondo coefficiente di asimmetria di Pearson, noto anche come asimmetria rispetto alla mediana.
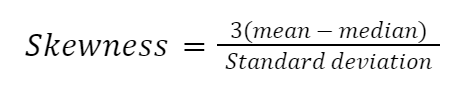
Implementiamo la formula manualmente in Python:
import numpy as np
import pandas as pd
import seaborn as sns
# Example dataset
diamonds = sns.load_dataset("diamonds")
diamond_prices = diamonds["price"]
mean_price = diamond_prices.mean()
median_price = diamond_prices.median()
std = diamond_prices.std()
skewness = (3 * (mean_price - median_price)) / std
>>> print(
f"The Pierson's second skewness score of diamond prices distribution is {skewness:.5f}"
)
The Pierson's second skewness score of diamond prices distribution is 1.15189
Un’altra formula, molto influenzata dai lavori di Karl Pearson, è la formula basata sui momenti per approssimare l’asimmetria. È più affidabile ed è la seguente:
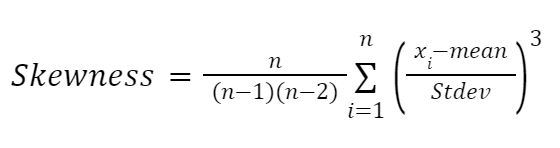
Dove:
Implementiamola anche in Python:
def moment_based_skew(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
# Divide the formula into two parts
first_part = n / ((n - 1) * (n - 2))
second_part = np.sum(((distribution - mean) / std) ** 3)
skewness = first_part * second_part
return skewness
>>> moment_based_skew(diamond_prices)
1.618440289857168
Se non vuoi calcolare l’asimmetria manualmente (come me), puoi usare i metodi integrati di pandas o scipy:
# Pandas version
diamond_prices.skew()
1.618395283383529
# SciPy version
from scipy.stats import skew
skew(diamond_prices)
1.6183502776053016
Anche se tutte le formule per approssimare l’asimmetria restituiscono punteggi diversi, le differenze sono troppo piccole per essere significative o cambiare la classificazione dell’asimmetria. Per esempio, tutti i metodi usati qui adottano formule diverse “sotto il cofano”, ma i risultati sono molto vicini.
Una volta calcolata l’asimmetria, puoi classificarne il grado:
Mentre l’asimmetria si concentra sulla dispersione (le code) della distribuzione normale, la curtosi si concentra maggiormente sull’altezza. Ci dice quanto è appuntita o piatta la nostra distribuzione normale (o simile alla normale). Il termine, che dal greco significa curvato o arcuato, fu coniato, non a sorpresa, dal matematico britannico Karl Pearson (che ha dedicato la vita allo studio delle distribuzioni di probabilità).
Un’alta curtosi indica:
D’altra parte, una bassa curtosi indica:
A seconda del grado, le distribuzioni presentano tre tipi di curtosi:
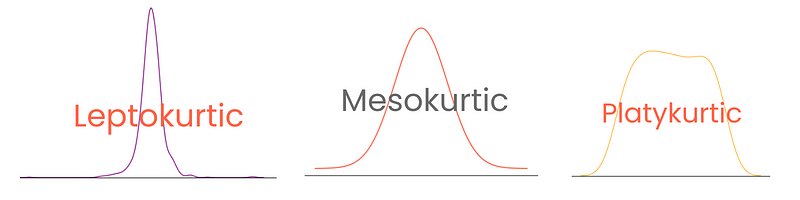
Nota che qui, la curtosi in eccesso è definita come curtosi - 3, trattando la curtosi della distribuzione normale come 0. In questo modo, i punteggi di curtosi sono più interpretabili.
Puoi calcolare la curtosi in Python allo stesso modo dell’asimettria usando pandas o SciPy:
from scipy.stats import kurtosis
kurtosis(diamond_prices)
2.177382669056634
Pandas offre due funzioni per la curtosi: kurt e kurtosis. La prima è esclusiva delle Series di Pandas, mentre l’altra può essere usata sui DataFrame.
diamond_prices.kurt()
2.17769575924869
# Select numeric features and calculate kurtosis
diamonds.select_dtypes(include="number").kurtosis()
carat 1.256635
depth 5.739415
table 2.801857
price 2.177696
x -0.618161
y 91.214557
z 47.086619
dtype: float64
Di nuovo, i numeri differiscono per la distribuzione perché pandas e SciPy usano formule diverse.
Se vuoi un calcolo manuale della curtosi, puoi usare la seguente formula:
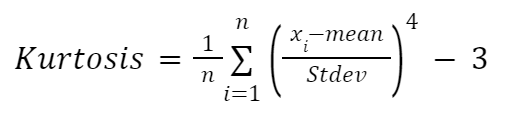
Dove:
Implementeremo di nuovo la formula all’interno di una funzione:
def moment_based_kurtosis(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
kurtosis = (1 / n) * sum(((distribution - mean) / std) ** 4) - 3
return kurtosis
>>> moment_based_kurtosis(diamond_prices)
2.1773826690576463
E scopriamo che i prezzi dei diamanti hanno una curtosi in eccesso di 2,18, il che significa che, se tracciamo la distribuzione, avrà un picco più appuntito rispetto a una distribuzione normale.
Quindi, facciamolo!
Una delle migliori visualizzazioni per vedere la forma e quindi l’asimmetria e la curtosi delle distribuzioni è il grafico della stima della densità tramite kernel (KDE). È disponibile in Seaborn:
import matplotlib.pyplot as plt
sns.kdeplot(diamond_prices)
plt.title("KDE plot of diamond prices")
plt.xlabel("Price ($)")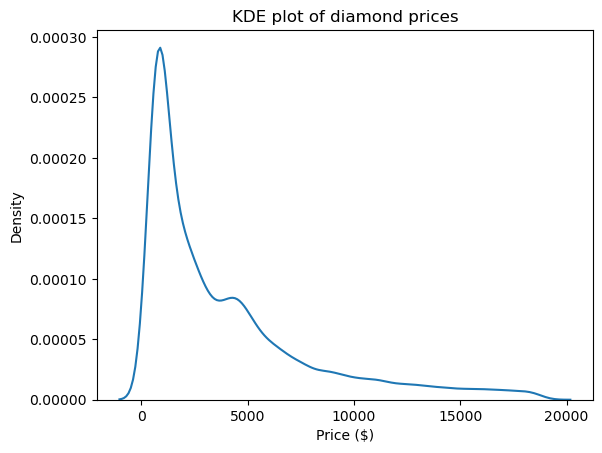
Questo grafico è coerente con i numeri visti finora: la distribuzione ha una lunga coda destra, che indica un’asimettria positiva, e un picco molto appuntito, che corrisponde a una curtosi alta.
Il KDE non è l’unico grafico per vedere la forma. Possiamo usare anche gli istogrammi:
sns.histplot(diamonds["carat"])
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")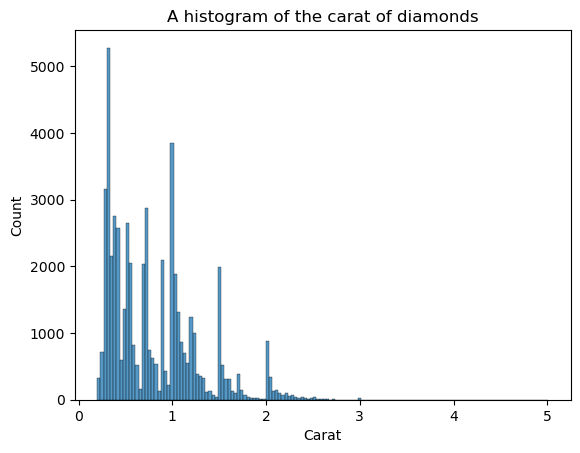
Lo svantaggio degli istogrammi è che devi scegliere tu il numero di bin (il numero di barre). Qui ci sono troppe barre che creano rumore nella visuale — non riusciamo a definire chiaramente la forma. Quindi, riduciamo il numero di bin:
sns.histplot(diamonds["carat"], bins=25)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")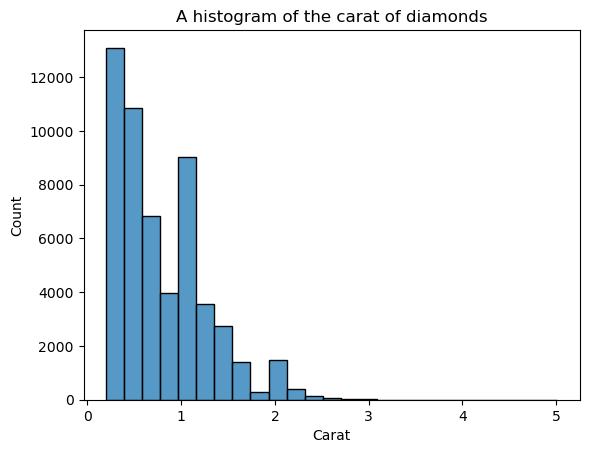
Ora la forma è più definita, ma possiamo migliorarla ancora. Impostando kde=True dentro histplot, possiamo tracciare un KDE della distribuzione sopra le barre:
sns.histplot(diamonds["carat"], bins=25, kde=True)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")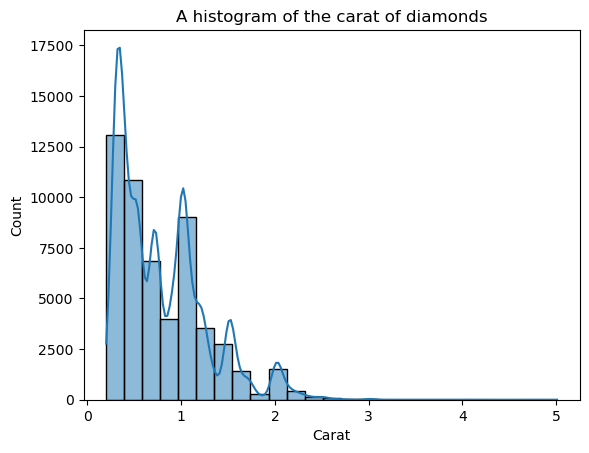
La linea KDE sovrapposta appare frastagliata, non la curva liscia che ci permette di vedere la forma generale. Il motivo è che la distribuzione dei carati è naturalmente irregolare e lontana dalla distribuzione normale.
Possiamo però ridurre la sensibilità del KDE a queste fluttuazioni regolando l’ampiezza di banda. Si fa con il parametro bw_adjust, che per impostazione predefinita è 1:
# Change the bandwidth from 1 to 3
sns.kdeplot(diamonds["carat"], bw_adjust=3, color="red")
plt.title("KDE of diamond carats");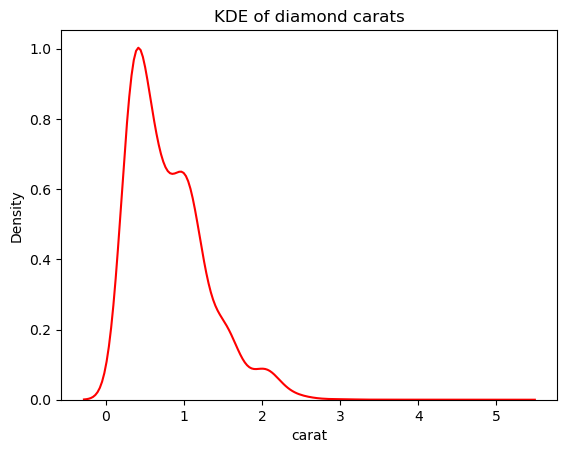
Questa versione è molto meno frastagliata rispetto al KDE sovrapposto. Per regolare l’ampiezza di banda del KDE quando usi un istogramma con KDE sovrapposto, puoi usare il parametro kde_kws:
ax = sns.histplot(
diamonds["carat"],
kde=True,
kde_kws=dict(bw_adjust=3),
bins=25,
)
plt.title("An overlaid histogram of diamond carats");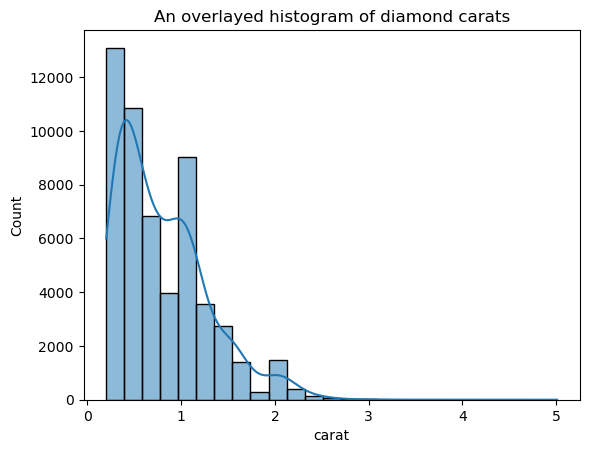
kde_kws accetta qualsiasi parametro previsto dalla funzione kdeplot che controlli il calcolo del KDE.
Un trucco che puoi usare quando tracci i KDE è rimuovere tutto tranne la linea KDE. Poiché lo scopo principale di un KDE è vedere la forma della distribuzione, altri dettagli del grafico come i tick degli assi, le cornici e le etichette a volte sono superflui:
sns.kdeplot(diamond_prices, color="red")
# Remove the spine from three sides
sns.despine(top=True, right=True, left=True)
# Remove the ticks and ticklabels
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
# Set a title
plt.title("Diamond prices", fontdict=dict(fontsize=20));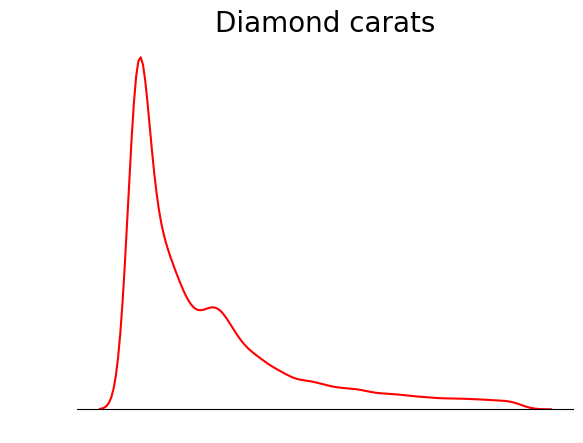
Questo grafico è molto più pulito. Puoi migliorarlo ulteriormente aggiungendo linee per indicare la posizione di media, mediana e moda:
sns.kdeplot(diamond_prices, color="red")
sns.despine(top=True, right=True, left=True)
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
plt.title("Diamond prices", fontdict=dict(fontsize=20))
# Find the mean, median, mode
mean_price = diamonds["price"].mean()
median_price = diamonds["price"].median()
mode_price = diamonds["price"].mode().squeeze()
# Add vertical lines at the position of mean, median, mode
plt.axvline(mean_price, label="Mean")
plt.axvline(median_price, color="black", label="Median")
plt.axvline(mode_price, color="green", label="Mode")
plt.legend();
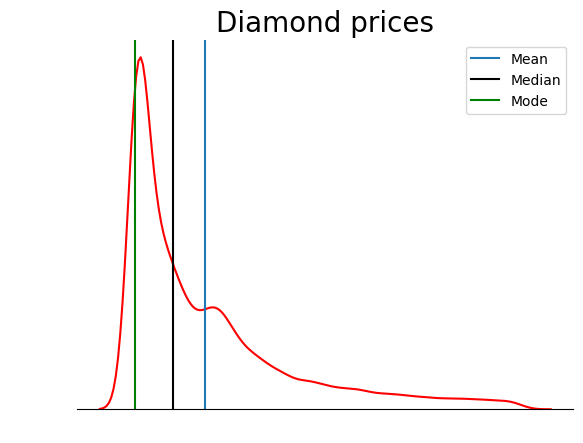
Questo grafico conferma quanto discusso nella sezione sui tipi di asimmetria: in una distribuzione con asimmetria positiva, la media è superiore alla mediana e la moda è inferiore sia alla media sia alla mediana.
Asimmetria e curtosi, spesso trascurate nell’Exploratory Data Analysis, rivelano informazioni importanti sulla natura delle distribuzioni.
L’asimettria indica l’inclinazione dei dati, verso sinistra o destra, rivelandone l’eventuale asimmetria. L’asimmetria positiva implica una coda che si allunga a destra, mentre quella negativa va nella direzione opposta.
La curtosi riguarda picchi e code. Una curtosi alta rende i picchi più appuntiti e appesantisce le code, mentre una curtosi bassa allarga i dati, alleggerendo le code.
Se vuoi approfondire asimmetria e curtosi, dai un’occhiata a questi ottimi corsi di analisi quantitativa tenuti da esperti del settore su DataCamp:
Scopri di più!
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

