
Courses
Nhập môn Quản trị Rủi ro Danh mục bằng Python
4 giờ
29.3K
Sau khi thu thập dữ liệu và dành hàng giờ để làm sạch, cuối cùng bạn có thể bắt đầu khám phá! Giai đoạn này, thường gọi là Phân tích Dữ liệu Khám phá (EDA), có lẽ là bước quan trọng nhất trong một dự án dữ liệu. Những hiểu biết thu được từ EDA sẽ ảnh hưởng đến mọi thứ về sau.
Ví dụ, một trong những bước bắt buộc trong EDA là kiểm tra hình dạng của các phân phối. Xác định đúng hình dạng sẽ chi phối nhiều quyết định sau này trong dự án như:
v.v. Mặc dù có thể dùng biểu đồ để làm việc này, bạn cần những thước đo đáng tin cậy hơn để định lượng các đặc trưng của phân phối. Hai thước đo như vậy là độ lệch (skewness) và độ nhọn (kurtosis). Bạn có thể dùng chúng để đánh giá mức độ tương đồng giữa các phân phối của mình với phân phối chuẩn hoàn hảo.
Khi đọc xong bài viết này, bạn sẽ nắm rõ:
Bắt đầu thôi!
Ta thấy phân phối chuẩn ở khắp nơi: số đo cơ thể người, khối lượng vật thể, điểm IQ, kết quả kiểm tra, hay thậm chí trong phòng gym:

Bên cạnh việc là phân phối ưa thích của tự nhiên, nó còn được hầu hết các thuật toán máy học yêu thích. Một số muốn nó để cải thiện và ổn định hiệu năng, một số thì hầu như từ chối hoạt động tốt với bất cứ thứ gì ngoài phân phối chuẩn (đang nói bạn đấy, các mô hình tuyến tính).
Vì vậy, để đáp ứng nhu cầu “chuẩn mực” của thuật toán, ta cần cách đo lường mức độ tương đồng (hoặc không) giữa các phân phối của mình với đường cong hình chuông hoàn hảo.
Bắt đầu với phần đuôi. Ở phân phối chuẩn hoàn hảo, hai đuôi bằng nhau về độ dài. Nhưng khi có sự bất đối xứng giữa hai đuôi, tạo cảm giác nghiêng, “bẹp” về một phía, ta nói phân phối đó bị lệch. Và đúng như bạn đoán, ta đo mức độ bất đối xứng này bằng độ lệch.
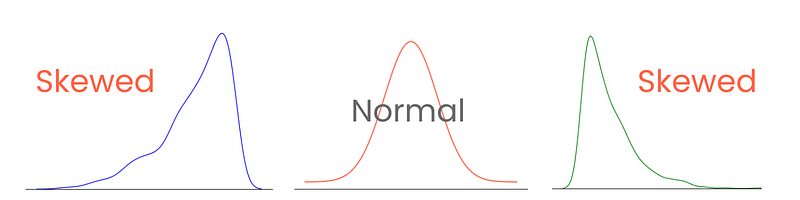
Phân loại và đo độ lệch chính xác cung cấp góc nhìn về cách các giá trị phân tán quanh trung bình và ảnh hưởng đến việc chọn kỹ thuật thống kê cũng như biến đổi dữ liệu. Ví dụ, những phân phối bị lệch mạnh có thể hưởng lợi từ các kỹ thuật chuẩn hóa hoặc tỷ lệ hóa để làm chúng giống phân phối chuẩn hơn, hỗ trợ hiệu năng mô hình.
Có ba loại độ lệch: dương, âm và bằng không.
Bắt đầu với loại cuối. Một phân phối có độ lệch bằng không có các đặc điểm sau:
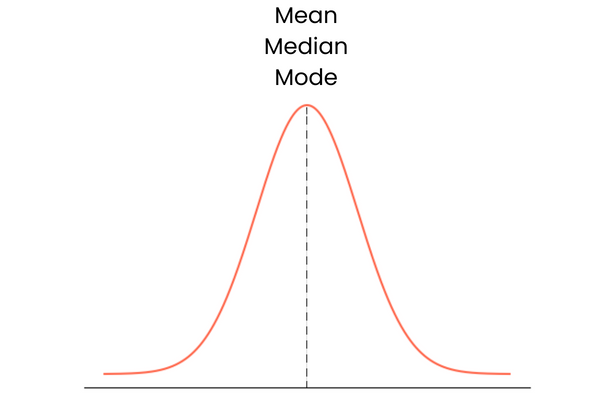
Trong thực tế, trung bình, trung vị và mode có thể không chồng khít hoàn hảo. Chúng có thể hơi lệch nhau nhưng khác biệt thường quá nhỏ để đáng kể.
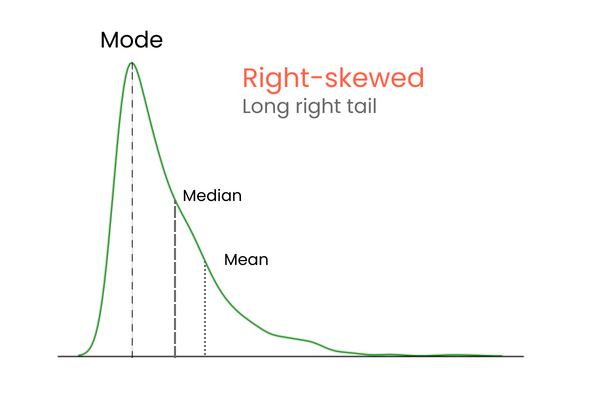
Trong một phân phối có độ lệch dương (lệch phải):
Trong một phân phối có độ lệch âm (lệch trái):
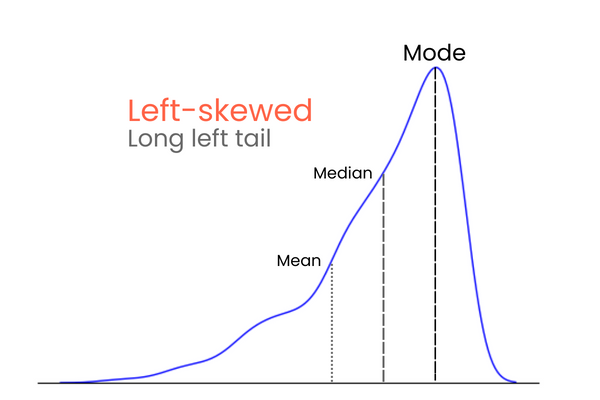
Để dễ nhớ sự khác biệt giữa lệch dương và lệch âm, hãy nghĩ thế này: nếu bạn muốn tăng trung bình của một phân phối, bạn nên thêm vào các giá trị cao hơn trung bình nhiều. Để giảm trung bình, làm ngược lại — thêm các giá trị thấp hơn trung bình nhiều. Vậy nên, nếu phần lớn các giá trị cực trị lớn hơn trung bình, độ lệch sẽ dương vì chúng làm tăng trung bình. Nếu phần lớn giá trị cực trị nhỏ hơn trung bình, độ lệch sẽ âm vì chúng làm giảm trung bình.
Có nhiều cách tính độ lệch, nhưng đơn giản nhất là hệ số độ lệch thứ hai của Pearson, còn gọi là độ lệch theo trung vị.
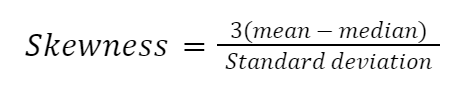
Hãy hiện thực công thức này thủ công trong Python:
import numpy as np
import pandas as pd
import seaborn as sns
# Example dataset
diamonds = sns.load_dataset("diamonds")
diamond_prices = diamonds["price"]
mean_price = diamond_prices.mean()
median_price = diamond_prices.median()
std = diamond_prices.std()
skewness = (3 * (mean_price - median_price)) / std
>>> print(
f"The Pierson's second skewness score of diamond prices distribution is {skewness:.5f}"
)
The Pierson's second skewness score of diamond prices distribution is 1.15189
Một công thức khác chịu ảnh hưởng lớn từ các công trình của Karl Pearson là công thức dựa trên moment để xấp xỉ độ lệch. Nó đáng tin cậy hơn và được cho bởi:
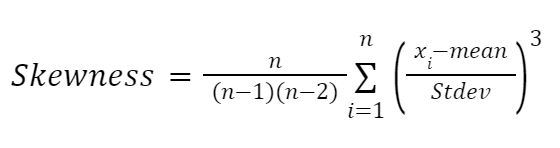
Trong đó:
Hãy hiện thực nó trong Python nữa:
def moment_based_skew(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
# Divide the formula into two parts
first_part = n / ((n - 1) * (n - 2))
second_part = np.sum(((distribution - mean) / std) ** 3)
skewness = first_part * second_part
return skewness
>>> moment_based_skew(diamond_prices)
1.618440289857168
Nếu bạn không muốn tự tính (giống tôi), bạn có thể dùng phương thức dựng sẵn từ pandas hoặc scipy:
# Pandas version
diamond_prices.skew()
1.618395283383529
# SciPy version
from scipy.stats import skew
skew(diamond_prices)
1.6183502776053016
Mặc dù các công thức xấp xỉ độ lệch trả về điểm số khác nhau, khác biệt của chúng quá nhỏ để có ý nghĩa hoặc làm thay đổi cách phân loại độ lệch. Chẳng hạn, tất cả phương pháp hôm nay dùng các công thức khác nhau bên dưới, nhưng kết quả rất gần nhau.
Khi đã tính được độ lệch, bạn có thể phân loại mức độ lệch:
Trong khi độ lệch tập trung vào độ lan rộng (đuôi) của phân phối chuẩn, độ nhọn tập trung nhiều hơn vào chiều cao. Nó cho biết phân phối chuẩn (hoặc giống chuẩn) của ta nhọn hay phẳng đến mức nào. Thuật ngữ này, có nghĩa là cong hoặc vòm trong tiếng Hy Lạp, lần đầu được đặt ra bởi, không ngạc nhiên, nhà toán học người Anh Karl Pearson (người dành cả đời nghiên cứu các phân phối xác suất).
Độ nhọn cao cho thấy:
Ngược lại, độ nhọn thấp cho thấy:
Tùy theo mức độ, các phân phối có ba loại độ nhọn:
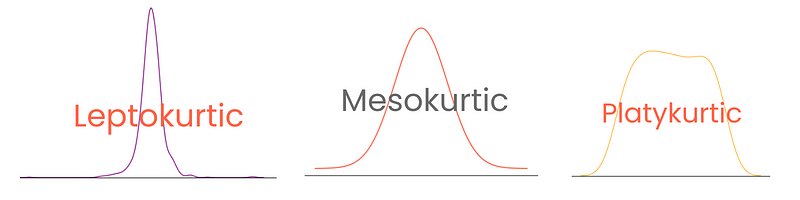
Lưu ý rằng ở đây, độ nhọn dư (excess kurtosis) được định nghĩa là kurtosis - 3, coi độ nhọn của phân phối chuẩn là 0. Cách này khiến điểm số độ nhọn dễ diễn giải hơn.
Bạn có thể tính độ nhọn trong Python tương tự như độ lệch bằng pandas hoặc SciPy:
from scipy.stats import kurtosis
kurtosis(diamond_prices)
2.177382669056634
Pandas cung cấp hai hàm cho độ nhọn: kurt và kurtosis. Cái đầu dành riêng cho Series của Pandas, còn cái sau có thể dùng trên DataFrame.
diamond_prices.kurt()
2.17769575924869
# Select numeric features and calculate kurtosis
diamonds.select_dtypes(include="number").kurtosis()
carat 1.256635
depth 5.739415
table 2.801857
price 2.177696
x -0.618161
y 91.214557
z 47.086619
dtype: float64
Một lần nữa, các con số khác nhau do pandas và SciPy dùng công thức khác nhau.
Nếu bạn muốn tính thủ công độ nhọn, có thể dùng công thức sau:
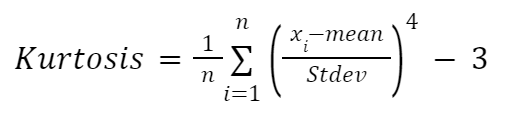
Trong đó:
Ta sẽ hiện thực công thức trong một hàm như trước:
def moment_based_kurtosis(distribution):
n = len(distribution)
mean = np.mean(distribution)
std = np.std(distribution)
kurtosis = (1 / n) * sum(((distribution - mean) / std) ** 4) - 3
return kurtosis
>>> moment_based_kurtosis(diamond_prices)
2.1773826690576463
Và ta thấy giá kim cương có độ nhọn dư là 2.18, nghĩa là nếu vẽ phân phối, nó sẽ có đỉnh nhọn hơn phân phối chuẩn.
Vậy hãy cùng vẽ!
Một trong những biểu đồ tốt nhất để nhìn hình dạng và do đó cả độ lệch lẫn độ nhọn của phân phối là biểu đồ ước lượng mật độ nhân (KDE). Nó có sẵn trong Seaborn:
import matplotlib.pyplot as plt
sns.kdeplot(diamond_prices)
plt.title("KDE plot of diamond prices")
plt.xlabel("Price ($)")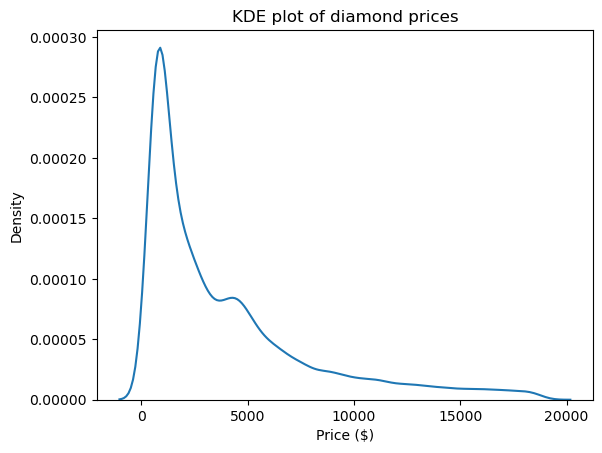
Biểu đồ này phù hợp với các con số ta đã thấy: phân phối có đuôi phải dài, biểu thị độ lệch dương, và có đỉnh rất nhọn, tương ứng với độ nhọn cao.
KDE không phải lựa chọn duy nhất để xem hình dạng. Ta cũng có thể dùng biểu đồ tần suất (histogram):
sns.histplot(diamonds["carat"])
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")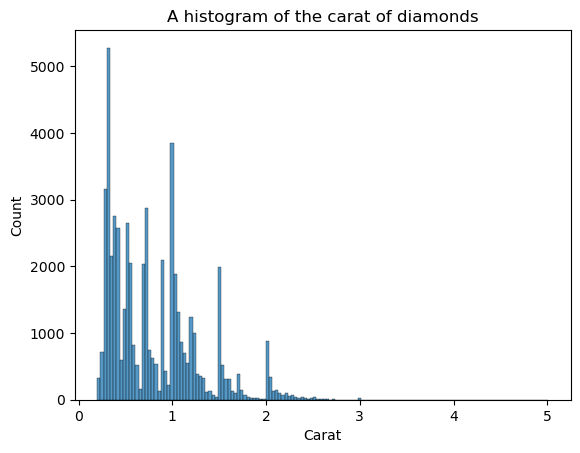
Nhược điểm của histogram là bạn phải tự chọn số lượng “bins” (số cột). Ở đây có quá nhiều cột gây nhiễu thị giác — ta không thể xác định rõ hình dạng. Vậy hãy giảm số bins:
sns.histplot(diamonds["carat"], bins=25)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")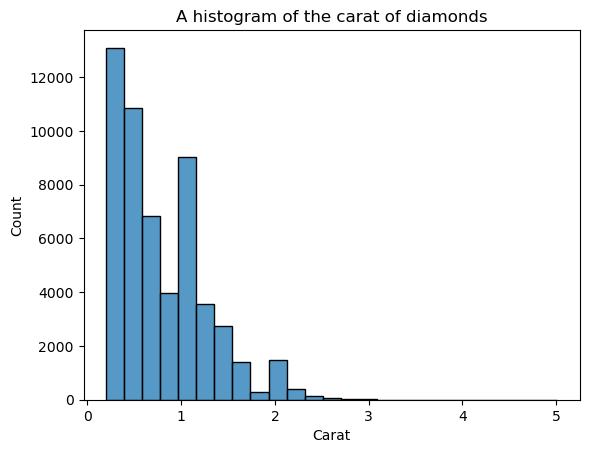
Giờ hình dạng rõ ràng hơn nhưng vẫn có thể cải thiện. Bằng cách đặt kde=True trong histplot, ta có thể vẽ thêm KDE chồng lên các cột:
sns.histplot(diamonds["carat"], bins=25, kde=True)
plt.xlabel("Carat")
plt.title("A histogram of the carat of diamonds")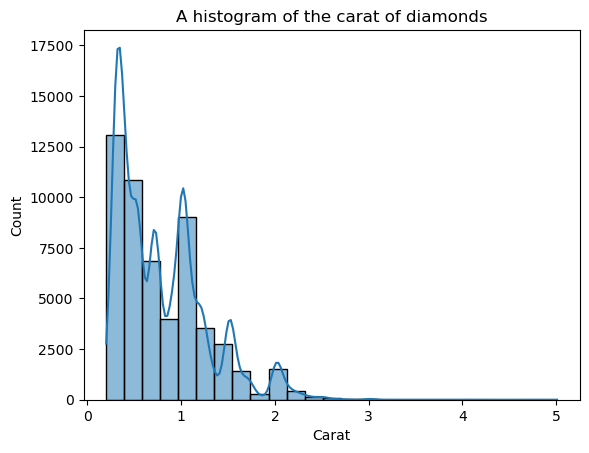
Đường KDE chồng lên trông răng cưa, không phải đường cong mượt giúp ta thấy hình dạng tổng quát. Lý do là phân phối carat vốn dĩ nhiều gai và xa phân phối chuẩn.
Tuy nhiên, ta có thể giảm độ nhạy của KDE với các dao động này bằng cách điều chỉnh băng thông. Làm điều này bằng tham số bw_adjust, mặc định là 1:
# Change the bandwidth from 1 to 3
sns.kdeplot(diamonds["carat"], bw_adjust=3, color="red")
plt.title("KDE of diamond carats");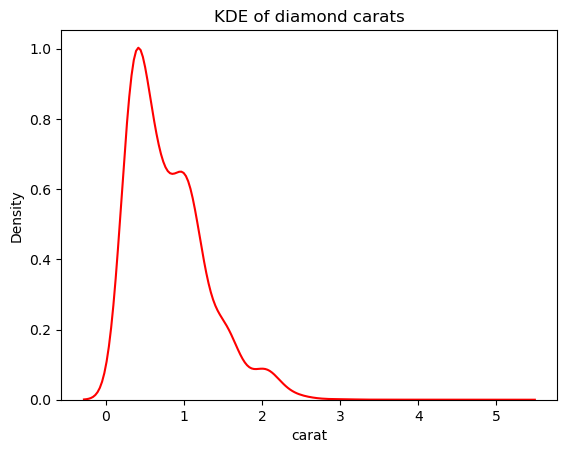
Phiên bản này ít gai hơn nhiều so với KDE chồng lên. Để điều chỉnh băng thông KDE khi dùng histogram chồng KDE, bạn có thể dùng tham số kde_kws:
ax = sns.histplot(
diamonds["carat"],
kde=True,
kde_kws=dict(bw_adjust=3),
bins=25,
)
plt.title("An overlaid histogram of diamond carats");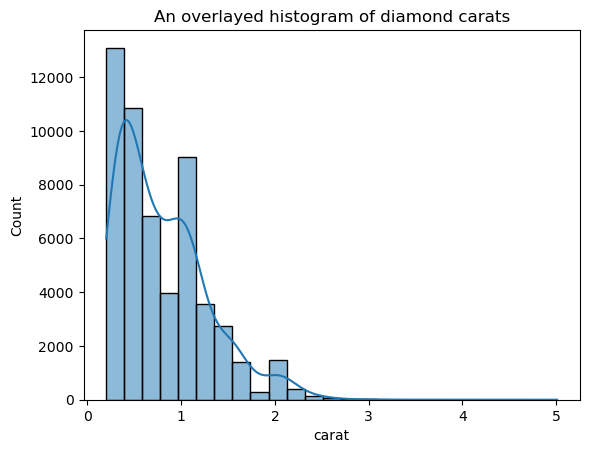
kde_kws chấp nhận mọi tham số mà hàm kdeplot hỗ trợ để điều khiển việc tính KDE.
Một mẹo khi vẽ KDE là loại bỏ mọi thứ ngoại trừ đường KDE. Vì mục đích chính của KDE là xem hình dạng phân phối, các chi tiết khác như vạch chia trục, khung viền và nhãn đôi khi không cần thiết:
sns.kdeplot(diamond_prices, color="red")
# Remove the spine from three sides
sns.despine(top=True, right=True, left=True)
# Remove the ticks and ticklabels
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
# Set a title
plt.title("Diamond prices", fontdict=dict(fontsize=20));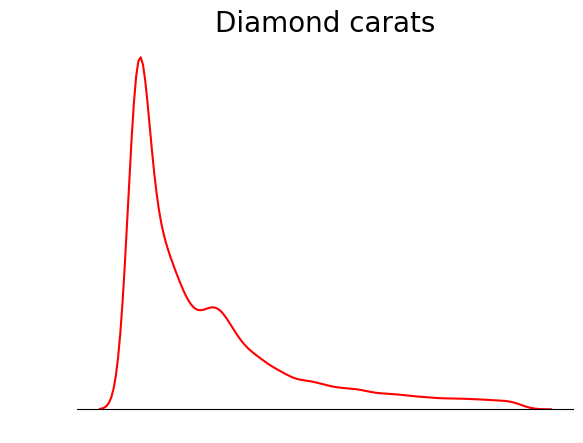
Biểu đồ này gọn gàng hơn nhiều. Bạn có thể cải thiện thêm bằng cách thêm các đường biểu thị vị trí trung bình, trung vị và mode:
sns.kdeplot(diamond_prices, color="red")
sns.despine(top=True, right=True, left=True)
plt.xticks([])
plt.yticks([])
plt.ylabel("")
plt.xlabel("")
plt.title("Diamond prices", fontdict=dict(fontsize=20))
# Find the mean, median, mode
mean_price = diamonds["price"].mean()
median_price = diamonds["price"].median()
mode_price = diamonds["price"].mode().squeeze()
# Add vertical lines at the position of mean, median, mode
plt.axvline(mean_price, label="Mean")
plt.axvline(median_price, color="black", label="Median")
plt.axvline(mode_price, color="green", label="Mode")
plt.legend();
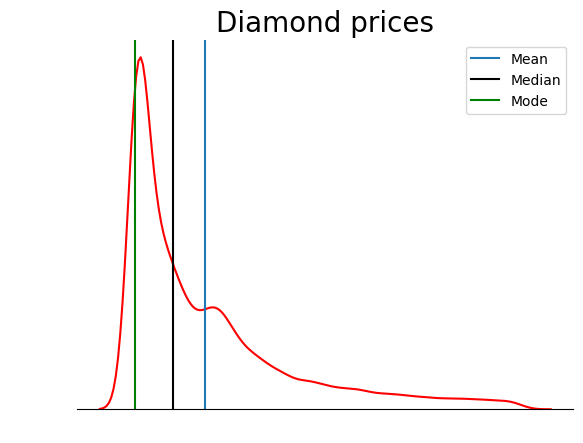
Biểu đồ này kiểm chứng những gì ta đã bàn ở phần các loại độ lệch: trong một phân phối lệch dương, trung bình cao hơn trung vị, và mode thấp hơn cả trung bình lẫn trung vị.
Độ lệch và độ nhọn, thường bị bỏ qua trong EDA, lại hé lộ những hiểu biết quan trọng về bản chất của các phân phối.
Độ lệch cho biết xu hướng nghiêng của dữ liệu, lệch trái hay phải, bộc lộ sự bất đối xứng (nếu có). Lệch dương nghĩa là đuôi kéo dài về bên phải, còn lệch âm thì ngược lại.
Độ nhọn nói về đỉnh và đuôi. Độ nhọn cao làm đỉnh nhọn hơn và đuôi nặng hơn, trong khi độ nhọn thấp khiến dữ liệu dàn trải, đuôi nhẹ hơn.
Nếu bạn muốn tìm hiểu sâu hơn về độ lệch và độ nhọn, bạn có thể xem các khóa học phân tích định lượng xuất sắc do các chuyên gia trong ngành giảng dạy trên DataCamp:
Tìm hiểu thêm!
Courses
Courses