tracks
구글 클라우드 디지털 리더
8
데이터 팀에서 일하고 있다면 이런 상황이 익숙할 것입니다. 백로그가 애드혹 요청으로 넘쳐납니다. 비즈니스 사용자는 기존 보고서의 간단한 변형을 끊임없이 요청하며, “제품 카테고리로 묶어줄 수 있나요?”, “지난달과 비교하면 어떤가요?”라고 묻습니다. 답을 기다리는 동안 데이터 엔지니어와 분석가는 반복적인 SQL 작업에 파묻힙니다.
BigQuery의 대화형 분석을 사용하면 병목을 마침내 옮길 수 있습니다. 이 기능은 AI 기반 추론 엔진을 BigQuery Studio에 직접 제공하여, 사용자가 자연어로 질문하고 즉시 데이터, 차트, 생성된 SQL을 받아볼 수 있게 해줍니다.
이 가이드에서는 BigQuery에서 대화형 분석을 설정하고 사용하는 방법을 알아봅니다. 직접 데이터 에이전트를 구축하고, 구성하고, 개선하여 조직이 데이터를 안전하게 대화하듯 다룰 수 있도록 합니다.
대화형 분석은 수동 SQL 질의에서 자연어 대화로 데이터 상호작용의 방식을 전환합니다. SELECT 문을 작성하는 대신, 비즈니스 맥락을 이해하고 실제 테이블을 기반으로 답을 반환하는 데이터 에이전트와 대화를 나눕니다.
이는 단순한 텍스트-투-SQL 파서가 아니라, 진정한 데이터 민주화를 향한 중대한 도약입니다.
비기술 사용자도 실시간 인사이트에 독립적으로 접근할 수 있고, 데이터 전문가에게는 데이터셋을 빠르게 탐색하고 보고를 자동화할 수 있는 방식을 제공합니다.
BigQuery의 대화형 분석의 핵심에는 Gemini 제품군 모델이 구동하는 추론 엔진이 있습니다. 데이터 에이전트는 구조화된 다단계 파이프라인을 사용하여 인사이트가 귀하의 특정 데이터 맥락에 근거하도록 보장합니다.
Google Cloud는 데이터 스택의 다양한 계층에서 대화형 분석을 제공합니다. 올바른 진입점을 선택하는 것은 사용자와 비즈니스 로직이 어디에 있는지에 따라 달라집니다.
|
기능 |
BigQuery 대화형 분석 |
Looker 대화형 분석 |
Data Studio (BigQuery 에이전트 연동) |
|
적합 대상 |
맞춤형 애플리케이션을 구축하는 데이터 팀, 분석가, 개발자 |
거버넌스된 대시보드용 인사이트가 필요한 비즈니스 사용자 |
경량 BI 보고를 선호하는 비즈니스 사용자 |
|
근거화 방식 |
데이터 웨어하우스 스키마, 테이블 메타데이터, 검증된 쿼리에 직접 근거 |
LookML(시맨틱 레이어) |
사전 구축된 BigQuery 데이터 에이전트에 직접 연결 |
|
데이터 접근 |
구조화, 예측(ML), 비정형 데이터를 분석 가능 |
엄격히 구조화되고 모델링된 데이터 |
구조화 데이터 |
|
출시 상태 |
프리뷰(2026년 5월 기준) |
일반 제공 |
프리뷰 |
어떤 경로를 선택해야 할까요?
이 튜토리얼은 데이터가 존재하는 곳에서 에이전트를 가장 빠르게 프로토타이핑하고 프로덕션에 적용할 수 있는 BigQuery에 초점을 맞춥니다.
설정에 앞서 데이터 에이전트의 아키텍처를 이해하는 것이 중요합니다. Google Cloud 환경에서 데이터 에이전트는 중심 추상화 계층입니다. BigQuery 자산과 Gemini 제품군 모델의 추론 기능을 결합합니다.
원시 테이블을 직접 노출하는 대신, 데이터 에이전트는 질문을 해석하고 안전한 SQL을 생성하며 신뢰할 수 있는 답을 반환하는 데 필요한 모든 것을 구성합니다. 데이터 소스, 지침, 검증된 로직의 조합 덕분에 BigQuery의 대화형 분석은 표준 텍스트-투-SQL 도구보다 더 신뢰할 수 있습니다.
지식 소스는 모든 데이터 에이전트의 기초 계층입니다. 에이전트가 접근하고 질의할 수 있는 데이터를 정확히 정의합니다.
자산 유형: 테이블, 뷰, 사용자 정의 함수(UDF)를 지식 소스로 연결할 수 있습니다.
확장성: 여러 지식 소스를 하나의 에이전트에 연결할 수 있습니다. 이를 통해 에이전트가 서로 다른 비즈니스 영역의 정보를 결합할 수 있습니다.
액세스 제어: 특정 지식 소스를 정의하면 에이전트가 권한이 부여된 데이터 내에서만 작동하도록 보장합니다.
에이전트의 지능은 제공되는 맥락에 달려 있습니다. 이는 범용 모델이 회사의 언어를 이해하도록 만드는 핵심입니다.
사용자 지정 지침, 동의어, 비즈니스 용어집을 정의하면 에이전트가 특정 도메인에 근거를 둘 수 있습니다. 예를 들어 “Top Customers”가 평생 가치(LTV)가 1,000달러를 초과하는 사용자를 의미하도록 학습시킬 수 있습니다.
핵심 근거화 요소:
사용자 지정 지침: “매출 보고서에서 내부 테스트 계정은 항상 제외한다.”와 같은 상위 수준 지시를 제공합니다.
비즈니스 용어집: store_id를 “지점 위치”로 매핑하는 등 기술 용어를 자연어로 연결합니다.
필드 메타데이터: “총매출”과 “순이익” 같은 특정 변수의 뉘앙스를 에이전트가 이해하도록 돕는 설명입니다.
지침과 메타데이터가 좋을수록 에이전트의 정확도가 높아집니다.
검증된 쿼리(이전 명칭: Golden Queries)는 진실의 원천 역할을 하는 사전 정의된 질문-답변 쌍입니다. 특정 질문을 전문가가 검토한 SQL에 매핑하여, 에이전트가 중요한 KPI에 대해 올바른 조인 경로와 필터를 사용하도록 합니다.
이러한 쿼리는 BigQuery ML(BQML) 기능을 포함할 수 있습니다. 이를 통해 에이전트는 데이터 과학자가 정의한 정확한 모델 파라미터를 사용하여 이탈 예측이나 판매 예측과 같은 고급 요청을 처리할 수 있습니다. 일단 검증되면, 이러한 자산은 Dataplex Universal Catalog를 통해 관리되어 조직 전반의 일관성을 보장합니다.
이제 구성 요소를 이해했으니, 실제로 첫 번째 데이터 에이전트를 구축하고 구성해 보겠습니다.
튜토리얼을 따라 하려면 다음 사전 준비 사항을 확인하세요.
첫 에이전트를 만들기 전에 Google Cloud 프로젝트를 구성하고 사용자 계정에 필요한 권한이 있는지 확인해야 합니다. 데이터 에이전트는 기존 데이터 위에서 동작하는 계층이므로 보안과 기능 모두를 위해 올바른 IAM(Identity and Access Management) 구성이 매우 중요합니다.
다음 단계를 따르세요.
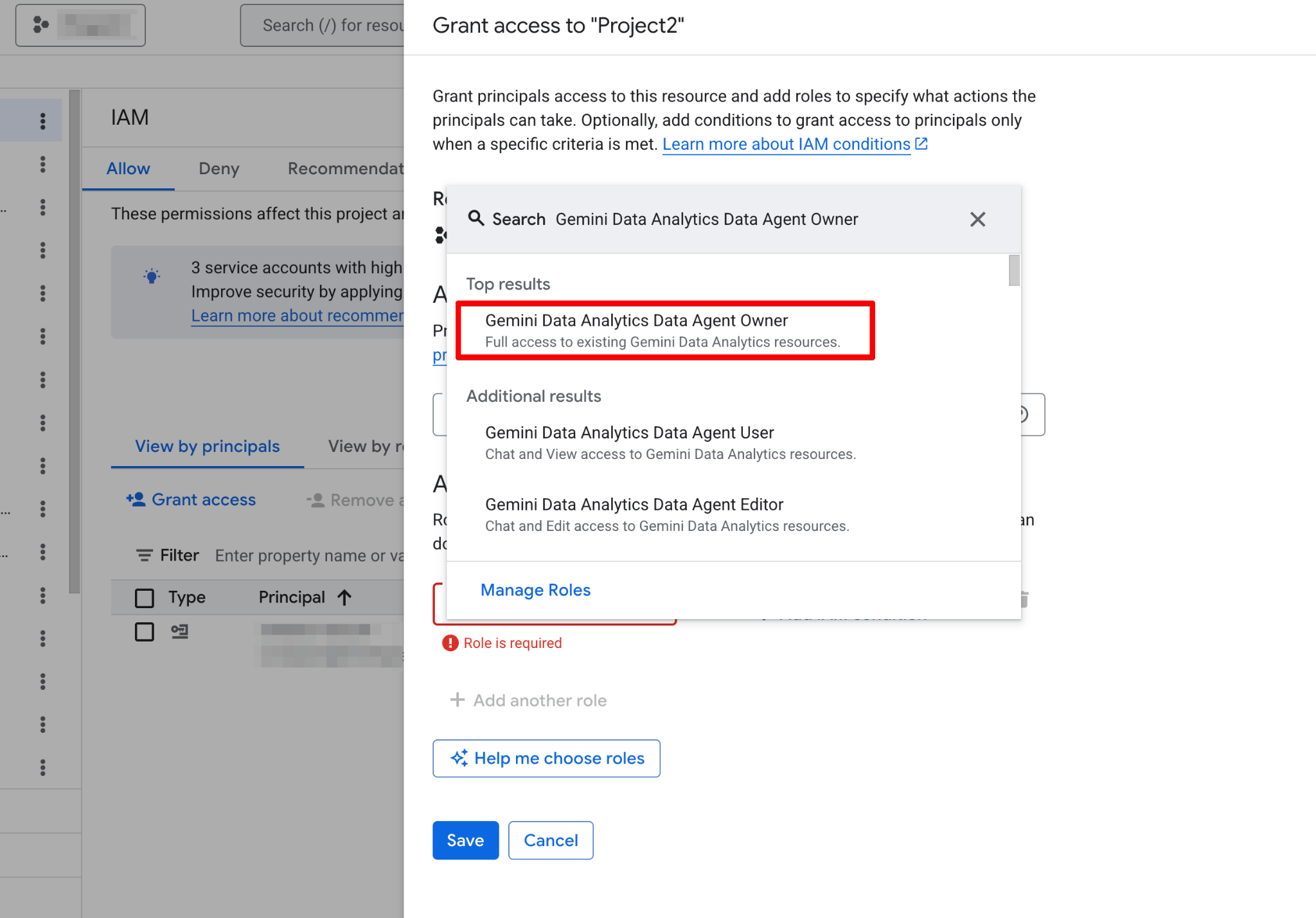
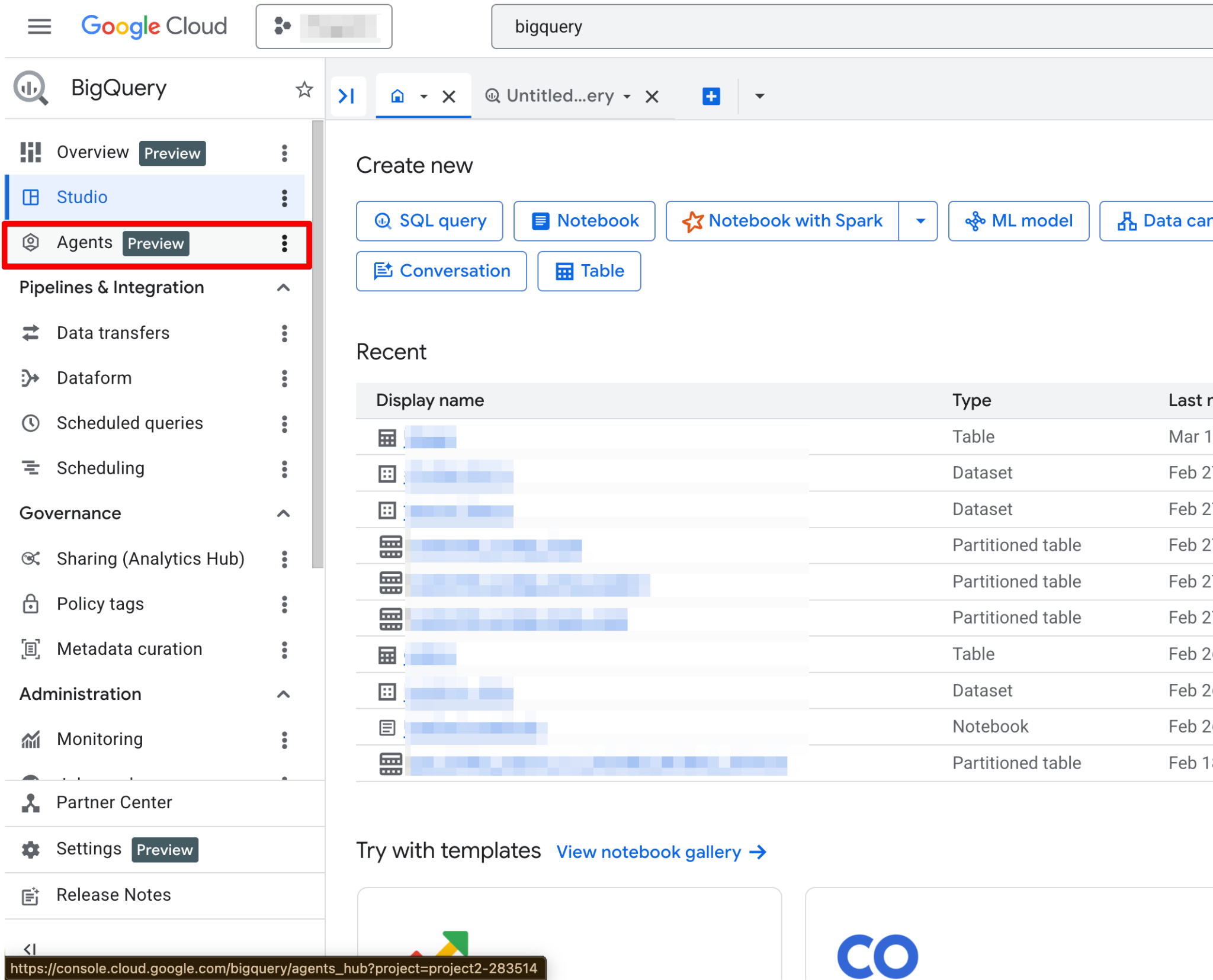
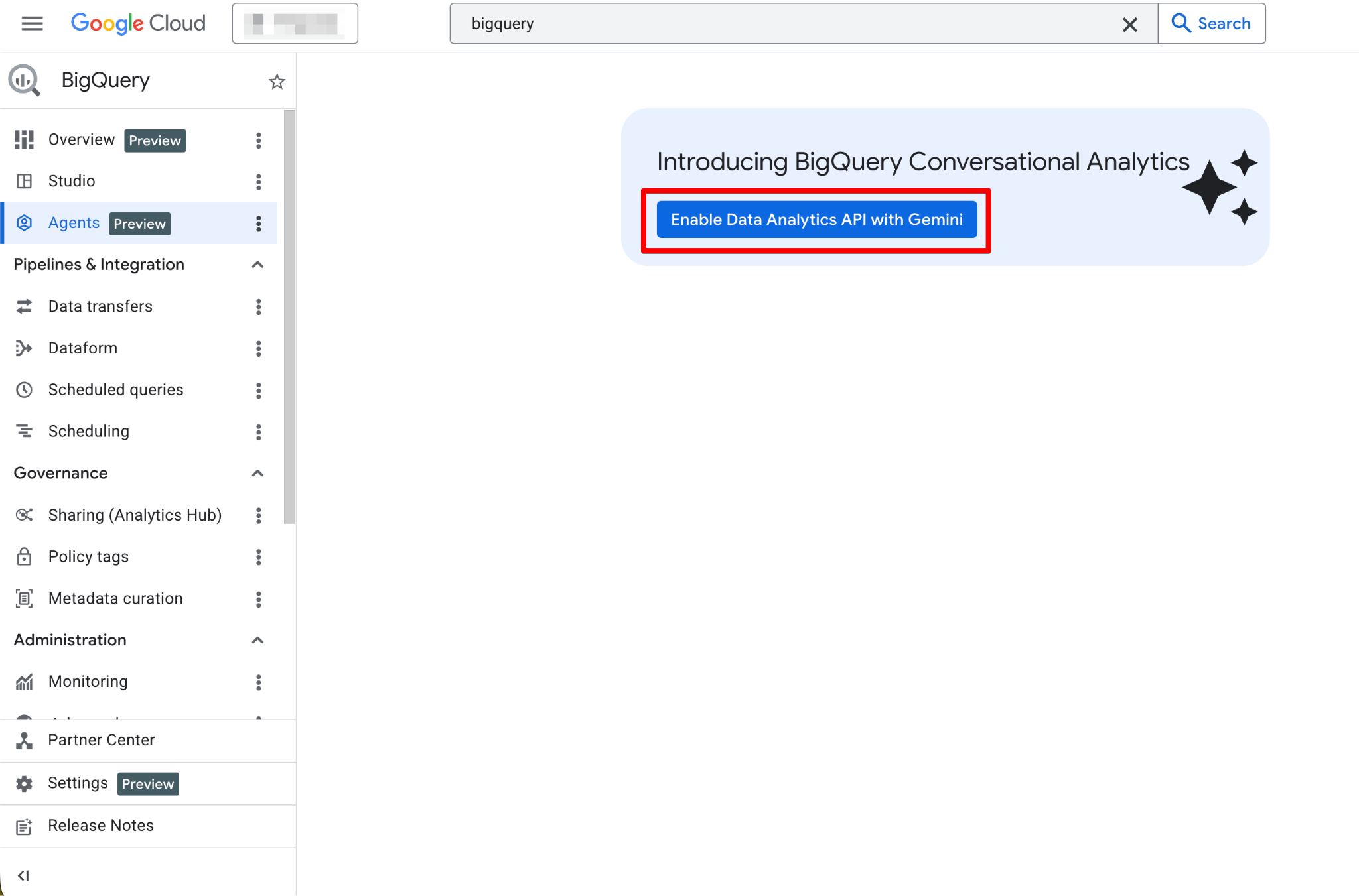
활성화되면 Agents 페이지를 완전히 사용할 수 있습니다. 이제 새 에이전트 페이지가 보일 것입니다.
에이전트 카탈로그는 BigQuery Studio 내에서 데이터 에이전트를 생성, 관리, 버전 관리하는 데 사용됩니다.
에이전트 카탈로그에서 확인할 수 있는 것:
에이전트 수명 주기는 다음 구조를 따릅니다(Draft → Created → Published):
에이전트 카드를 클릭하면 상세 보기, 대화 시작, 편집(Owner 권한 보유 시)을 할 수 있습니다. 인터페이스에는 에이전트나 데이터 소스와의 과거 채팅을 관리할 수 있는 Conversations 탭도 포함되어 있습니다.
이제 기초가 마련되었으니 처음부터 데이터 에이전트를 만들어 보겠습니다. bigquery-public-data.austin_bikeshare 데이터셋을 사용하여 원시 여행 데이터를 대화형 인터페이스로 변환합니다. 두 개의 테이블을 사용합니다.
bikeshare_trips — 자세한 여행 단위 데이터
bikeshare_stations — 정류장 메타데이터
에이전트 생성 시작
이 두 필드는 나중에 에이전트를 빠르게 식별하는 데 도움이 됩니다. 설정이 끝나면 앞서 다룬 세 가지 핵심 구성 요소, 즉 지식 소스, 지침, (이후) 검증된 쿼리를 구성할 준비가 된 것입니다.
지식 소스는 에이전트가 접근할 수 있는 데이터를 정확히 정의합니다. 소스는 적고 집중될수록 정확도는 높고 비용은 낮습니다. 편집기의 Knowledge sources 섹션에서 Add source를 클릭합니다. austin_bikeshare를 검색하고 소스로 bikeshare_trips와 bikeshare_stations를 선택합니다.
추가하는 각 테이블에 대해 Customize를 클릭합니다.
Gemini가 자동으로 설명을 생성하고 열 메타데이터를 제안합니다. 모든 내용을 검토해 정확한 제안을 수락하고, 필요한 수정을 한 다음 Update를 클릭하세요.
자주 하는 실수는 한 번에 50개 테이블을 추가하는 것입니다. 핵심 테이블 2–3개로 시작하세요. 이렇게 하면 에이전트의 로직을 디버깅하기가 더 쉽습니다. 핵심 쿼리가 정확해지면 지식을 얼마든지 확장할 수 있습니다.
다음으로 지침으로 에이전트를 근거화해야 합니다. “매출에 대한 질문에 답하라” 같은 일반 프롬프트를 적는 대신, BigQuery의 데이터 에이전트 인터페이스는 AI의 쿼리 생성을 안내할 수 있도록 매우 구조화된 맥락을 제공할 수 있게 해줍니다. 회사의 정확한 데이터 사전을 신입 분석가에게 온보딩한다고 생각해 보세요.
Instructions 필드를 사용해 구조화된 비즈니스 맥락을 제공하세요. 다음은 바로 붙여넣어 사용할 수 있는 완전한 예시입니다.
동의어: 열의 대체 용어를 정의해 에이전트가 자연어 변형을 이해하도록 합니다. 예: “Journey”, “Ride”, “Commute”는 모두 bikeshare_trips 테이블의 한 레코드를 의미합니다. “Dock”, “Hub”, “Station”은 bikeshare_stations 테이블의 한 레코드를 의미합니다.
핵심 필드: 분석에 가장 중요한 필드를 강조합니다. 이는 사용자의 질문이 포괄적일 때 에이전트가 어떤 열을 우선시할지 알려줍니다. 예: 일반 보고에서는 trip_id, start_station_name, end_station_name, subscriber_type, start_time, duration_minutes를 우선시합니다.
제외 필드: 데이터 에이전트가 엄격히 피해야 하는 열을 지정합니다. 이는 사용 중단된 열이나 관련 없는 데이터를 숨기는 데 매우 유용합니다. 예: 대부분의 분석에서 bikeshare_trips 테이블의 bike_id 열은 비즈니스 질문에 거의 필요하지 않으므로 사용하지 마세요.
필터링과 그룹화: 데이터를 분할하는 표준 방법을 지시합니다. 예: 별도 지정이 없으면 duration_minutes < 1인 여행(오작동 시작 또는 테스트 주행)은 항상 제외하세요. 사용자가 “정류장별” 또는 “상위 정류장”을 요청하면 기본적으로 데이터를 start_station_name으로 그룹화합니다.
조인 관계: 에이전트가 여러 테이블에서 데이터를 가져오므로, 서로 연결되는 방식을 명시적으로 정의하세요. 이렇게 하면 잘못된 외래 키를 추측하지 않게 됩니다. 예: bikeshare_trips 테이블을 bikeshare_stations 테이블과 bikeshare_trips.start_station_id를 bikeshare_stations.station_id에 매칭해 조인합니다( end_station_id도 동일하게 적용).
위의 내용을 Instructions 필드에 하나의 깔끔한 블록으로 결합할 수 있습니다. 다음은 구조화된 가이던스를 반영한 다듬어진 버전입니다.
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).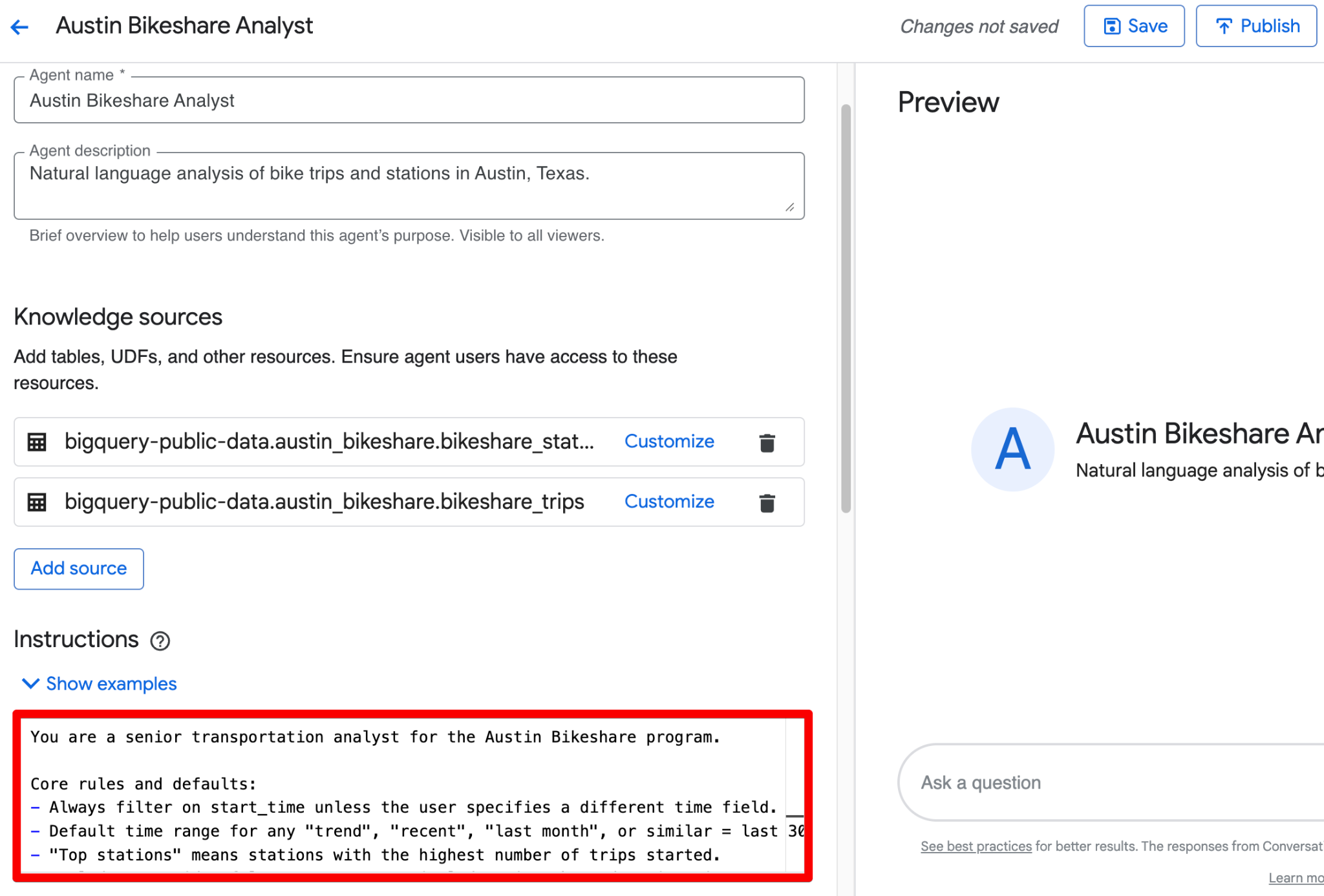
중요한 이유: 이 필드를 비워 두면 “상위 매출은 무엇이었나?” 같은 모호한 질문에 대해 에이전트가 잘못된 테이블을 조인하거나, 비활성 계정에서 데이터를 끌어오거나, 사용 중단된 데이터를 포함할 수 있습니다. 다섯 범주에 걸쳐 지침을 구조화하면 생성된 SQL이 확립된 비즈니스 로직을 엄격히 준수하도록 보장합니다.
지침 외에도 에이전트 내에서 직접 용어집 항목을 정의할 수 있으며, 권장됩니다. 이는 에이전트가 비즈니스 전문 용어, 약어, 파생 개념을 일관되게 해석하는 데 도움이 됩니다.
Glossary 섹션(대개 Instructions 근처)에서 Add term을 클릭하고 용어, 정의, 동의어(쉼표로 구분)를 입력해 항목을 만드세요.
Austin Bikeshare 데이터셋에 권장되는 용어집 항목은 다음과 같습니다.
| 용어 | 정의 | 동의어 |
duration_minutes |
여행 소요 시간(분). 사용자 대상 답변과 계산에는 항상 이 값을 사용합니다 | ride time, trip length, duration, ride duration |
ridership |
자전거 여행 시작 횟수(카운트)의 총합 | trips, rides, journeys, bike usage, commute count |
peak_hours |
start_time에서 추출한 시(hour)를 기준으로 오전 피크(7–9) 또는 저녁 피크(16–19) 시간대 |
rush hour, busy hours, high demand period |
subscriber_type |
라이더 유형 — 구독자(월간 또는 연간 패스 보유자) 또는 고객(1회 이용) | user type, membership type, pass holder, member, casual rider |
false_start |
아주 짧은 여행(보통 1분 미만)으로, 테스트 주행 또는 실수로 잠금 해제했을 가능성이 큽니다. 일반적으로 분석에서 제외해야 합니다 | test ride, invalid trip, short trip |
필요에 따라 start_station_name, end_station_name 또는 “평균 여행 시간”, “긴 여행” 같은 파생 지표에 대한 항목을 추가할 수 있습니다.
용어집을 사용하면, 예를 들어 다음 분기에 “Long Ride”의 공식 정의를 45분으로 변경하기로 경영진이 결정했을 때 데이터 거버넌스 팀이 Dataplex에서 한 번만 업데이트하면 됩니다. 해당 용어집과 연결된 모든 데이터 에이전트가 즉시 새로운 로직을 채택해 조직 전반의 일관성을 유지할 수 있습니다.
지식 소스, 지침, 용어집을 구성했으면 게시 전에 에이전트를 테스트할 시간입니다.
화면 오른쪽의 Preview 창으로 스크롤하세요. 이 라이브 채팅 인터페이스를 통해 에이전트를 구축하면서 실시간으로 상호작용할 수 있습니다. 질문을 하고, 에이전트의 추론을 검토하고, 생성된 SQL을 확인하며, 빠르게 반복할 수 있습니다.
Preview 창에는 다음이 표시됩니다.
다음 네 가지 점점 복잡해지는 쿼리를 시도해 보세요(데이터셋의 2024년까지의 데이터 범위에 맞게 조정).
에이전트의 응답에서 보게 될 것:
요약 — 결과에 대한 자연어 설명
쿼리 결과 — 데이터가 담긴 깔끔한 테이블(예: 총 여행 건수, 상위 정류장, 평균 소요 시간)
인사이트 — 결과를 비즈니스 맥락에서 해석한 핵심 포인트
생성된 SQL — Open in Editor를 클릭하면 에이전트가 작성한 전체 SQL을 볼 수 있습니다( start_time으로 올바르게 필터링하고 duration_minutes >= 1을 적용해 오작동 시작 주행을 제외하는 것을 확인할 수 있습니다).
추천 후속 질문 — 하단의 유용한 프롬프트(예: “2024년 6월 상위 10개 출발 정류장은?”, “일별 여행 횟수를 예측…” 등)
시각화 — 자동 생성된 차트(상위 5개 정류장 예시처럼 순위에는 막대 차트)
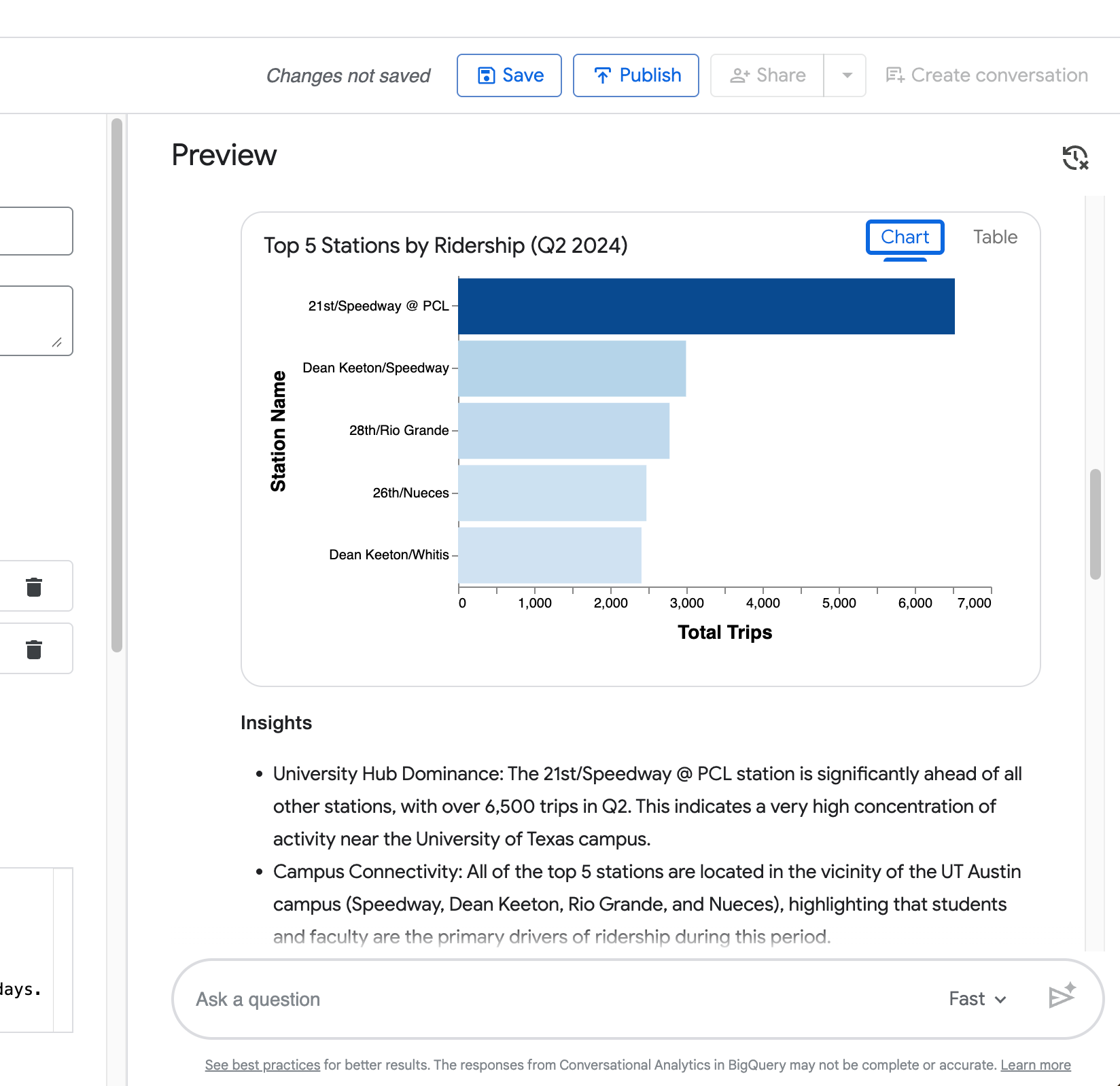
네 번째 쿼리(“방금 비교를 Zilker Park 정류장에 한해서만 보여주세요”)는 에이전트가 이전 질문의 맥락을 유지할 수 있음을 보여줍니다.
다음 스크린샷에서 볼 수 있듯, 전체 요청을 반복하지 않아도 주중 vs 주말 소요 시간 비교가 Zilker Park으로 정확히 좁혀집니다.
테스트 팁:
에이전트가 명확하고 정확하며 구조화된 답을 지속적으로 제공하면 상단의 Save를 클릭한 다음 Publish를 클릭하세요. 이제 Austin Bikeshare Analyst 에이전트를 사용할 준비가 되었습니다!
지침과 용어집이 잘 되어 있어도 데이터 에이전트가 비즈니스 규칙을 가끔 오해하거나 일관되지 않은 답을 생성할 수 있습니다.
검증된 쿼리를 사용하면 중요한 질문이나 자주 묻는 질문을 올바르게 처리하는 방법을 에이전트에게 명시적으로 가르칠 수 있습니다. 각 검증된 쿼리는 자연어 질문과 사용해야 하는 정확한 SQL로 구성됩니다.
이는 에이전트의 추론을 고품질 예시로 고정(anchor)시키며, “그럭저럭 괜찮은” 에이전트에서 프로덕션 준비된 에이전트로 발전시키는 가장 효과적인 방법 중 하나입니다.
에이전트 편집기에서 Verified Queries 섹션으로 스크롤합니다. 검증된 쿼리를 추가하는 쉬운 방법이 두 가지 있습니다.
Add query를 클릭합니다. 검증된 쿼리 추가 화면이 표시되며, 여기서 다음을 수행할 수 있습니다.
View Gemini-generated suggestions를 클릭합니다. 그러면 Gemini가 지식 소스를 기반으로 관련 질문을 제안하는 “Review suggested verified queries” 화면이 열립니다.
다음 작업을 할 수 있습니다.
Austin Bikeshare 데이터셋에 적합한 검증된 쿼리 예시는 다음과 같습니다.
질문:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;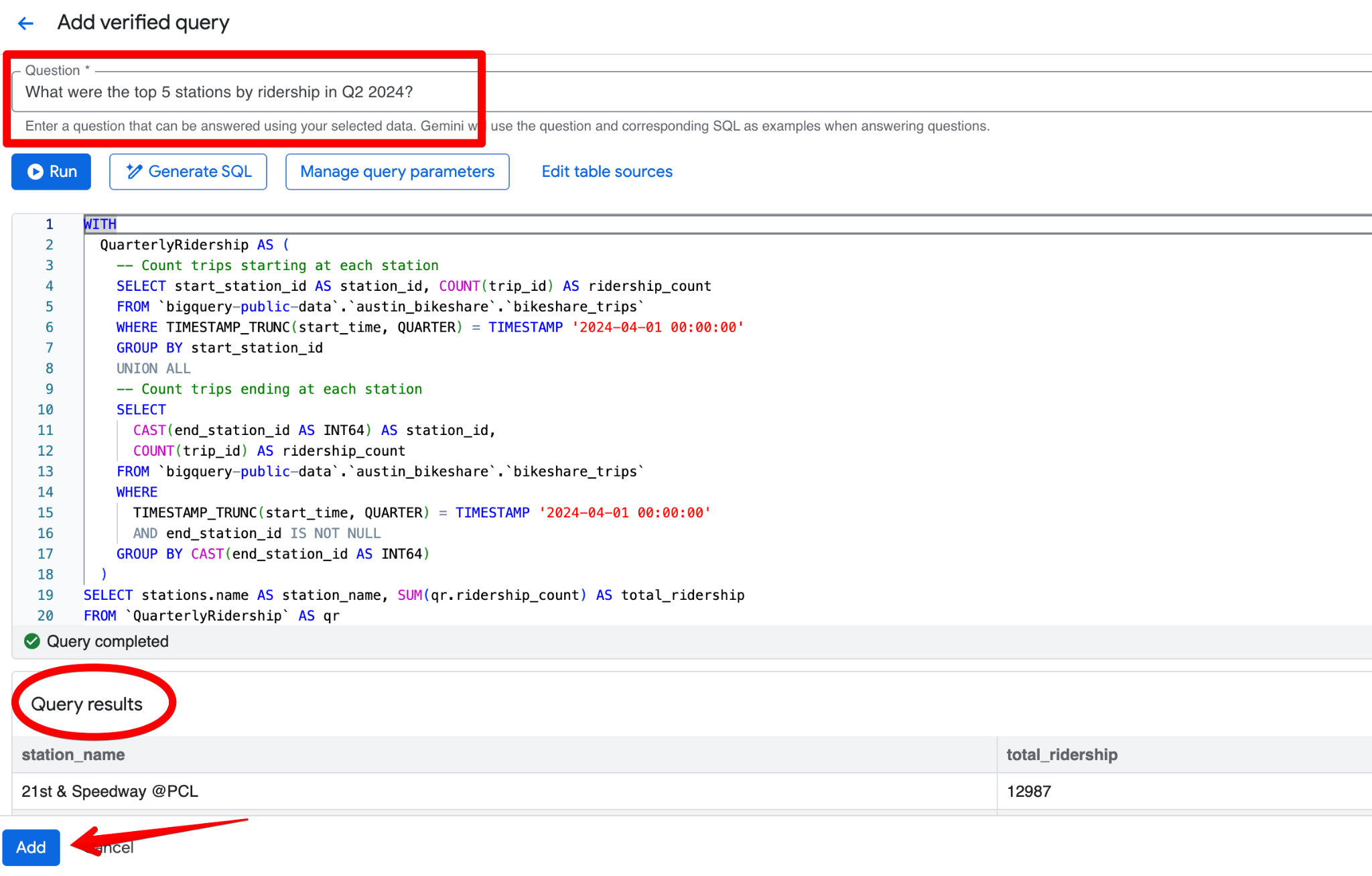
에이전트가 처음에 그럴듯한 답을 주더라도, 생성된 SQL을 검토하고 검증된 쿼리를 추가하면 정확도와 일관성을 크게 높일 수 있습니다.
다음 실용적인 워크플로를 따르세요.
예를 들어 “2024년 6월 평균 여행 시간은 얼마였나요?”라고 물었다고 가정해 보겠습니다. 초기 응답에서 에이전트는 26.68분을 반환하고 1분 미만의 여행을 올바르게 제외합니다. 그런데 팀의 표준 비즈니스 규칙이 5분 미만의 여행은 제외하는 것이라면 어떻게 할까요?
생성된 SQL을 열어(Open in Editor 경유) 보면 필터가 duration_minutes >= 1로만 설정되어 있음을 확인합니다.
Verified Queries 섹션에서 Add query 를 클릭하고 다음 항목을 생성하세요.
질문:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes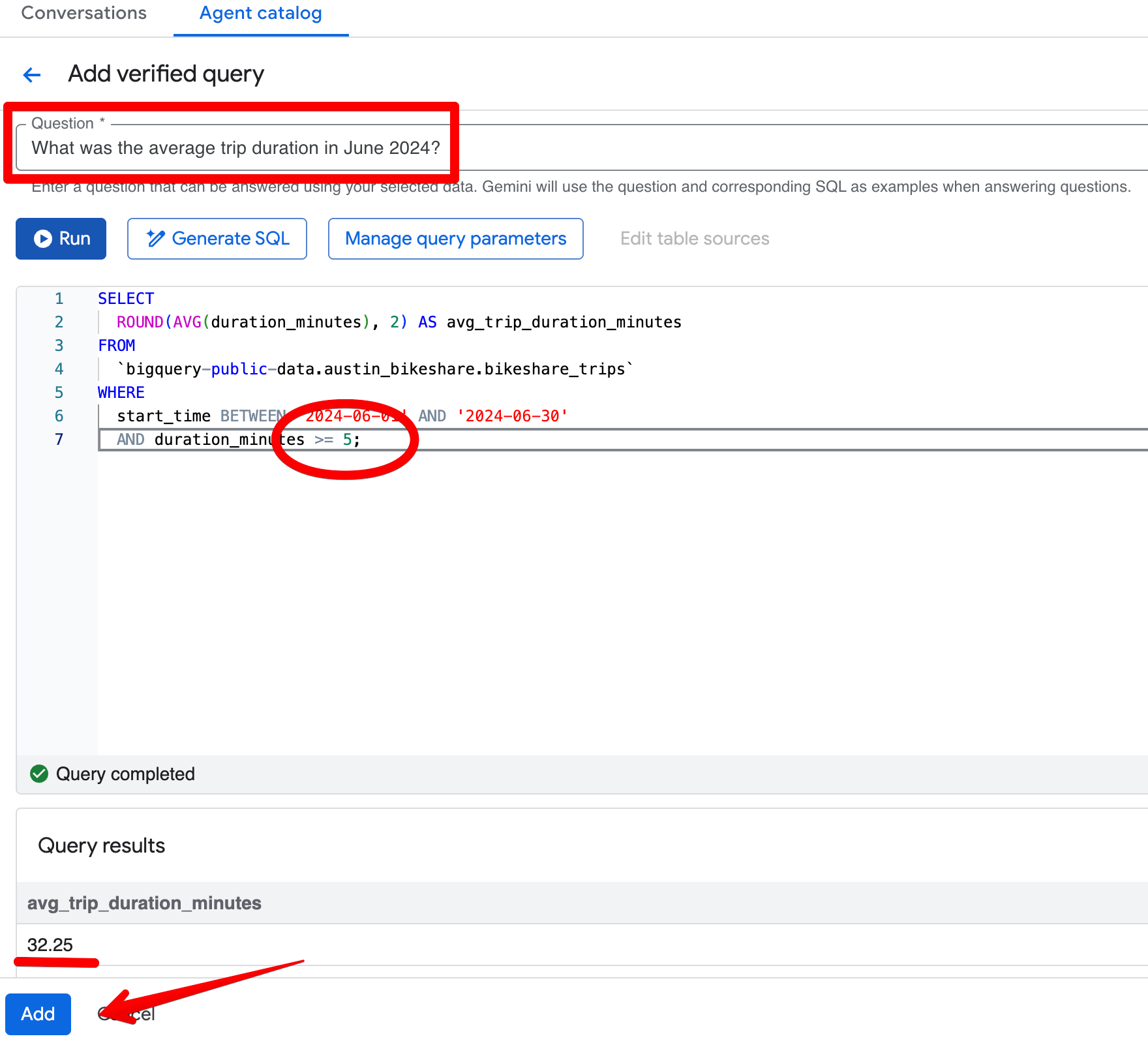
검증된 쿼리를 저장한 뒤 Preview 창에서 같은 질문을 다시 하세요. 이제 에이전트는 약 32.08분을 일관되게 반환하며 더 엄격한 5분 임계값을 적용합니다. 결과는 “의미 있는” 여행에 대한 귀하의 비즈니스 관점과 더 잘 부합하게 됩니다.
BigQuery의 대화형 분석은 BigQuery ML 기능, 비정형 데이터, Google Cloud 생태계 전반의 손쉬운 공유를 기본 지원함으로써 단순 텍스트-투-SQL 도구와 차별화됩니다.
가장 큰 차별점 중 하나는 에이전트가 자연어에서 BigQuery ML 함수를 직접 호출해 과거 보고를 넘어선 미래 지향 인사이트로 나아갈 수 있다는 점입니다.
예를 들어, 데이터 에이전트에게 2024년 추세를 바탕으로 향후 30일간의 일별 여행 건수를 예측하라고 요청할 수 있습니다. 그러면 AI.FORECAST를 호출하고, 2024년 7월에 대한 예측을 생성하여 과거 일별 여행(파란 선)과 30일 예측(주황 선), 그리고 음영 처리된 95% 신뢰 구간을 함께 보여주는 멋진 차트를 제공합니다.
머신러닝 알고리즘이 유용한 또 다른 방법은 데이터에 이상이 있는지 감지하는 것입니다. 예를 들어 2024년 6월 동안의 일별 승차 수에서 이상을 감지하라고 요청하면 AI.DETECT_ANOMALIES를 호출해 2024년 6월을 이전 달과 비교하고, 시계열 테이블과 함께 꺾은선 차트를 반환합니다.
이 경우 95% 신뢰수준에서 공식적인 이상치는 없었지만, 6월 19일을 승차 수가 눈에 띄게 떨어진 준-이상치(92.1% 확률)로 표시했습니다.
대부분의 대화형 BI 도구는 데이터가 행과 열로 깔끔히 정리되어 있지 않으면 실패합니다. 그러나 BigQuery는 Object Table을 지원하여 Google Cloud Storage에 저장된 비정형 데이터(PDF, 이미지, 원시 텍스트 로그 등)를 분석할 수 있습니다.
데이터 에이전트는 Gemini의 멀티모달 기능으로 구동되므로, 구조화된 지표와 비정형 파일을 동시에 추론할 수 있습니다. 이는 BigQuery만의 거대한 차별점입니다.
오브젝트 테이블에 라이더 설문 PDF나 정류장 점검 이미지가 있다면 “2024년 2분기 라이더 설문 PDF의 주요 불만을 요약하세요.”라고 요청하세요. 에이전트가 비정형 파일을 읽고 구조화된 여행 데이터와 정보를 결합합니다
데이터 팀은 BigQuery Studio에서 데이터 에이전트를 구축하고 테스트하지만, 최종 사용자는 전혀 다른 애플리케이션에서 일합니다. Google은 에이전트를 GCP 콘솔에서 분리해 비즈니스 사용자가 이미 일하는 곳에서 만날 수 있도록 쉽게 해줍니다.
직접 맞춤형 채팅 애플리케이션을 만들어 보고 싶다면 공식 Introduction to Conversational Analytics in BigQuery에서 더 자세히 읽어보세요.
핵심 원칙은 하나입니다. 대화형 분석은 데이터 팀의 답변을 기다리는 병목을 “올바른 질문을 하는 것”으로 전환한다는 점입니다.
이는 민주화이지만 데이터 팀이 불필요해진다는 뜻은 아닙니다. AI 에이전트의 지능은 그 주변에 구축한 가드레일만큼입니다. 데이터 에이전트의 정확성과 안전성은 전적으로 귀하가 제공하는 지침, 맥락, 스키마 아키텍처에 달려 있습니다.
가장 효과적인 대화형 에이전트를 구축하려면 여전히 기저 데이터 웨어하우스에 대한 강한 이해가 필요합니다. 귀하나 팀이 이러한 핵심 역량을 강화하고 이러한 AI 기능을 구동하는 플랫폼을 숙달하고 싶다면, 오늘 DataCamp의 Introduction to BigQuery 과정을 확인해 보세요!
Google Cloud 강좌
tracks
courses
courses