
Programa
Google Cloud Digital Leader
8 h
Se você trabalha em um time de dados, este cenário provavelmente soa familiar: seu backlog está lotado de solicitações ad hoc. As áreas de negócio pedem variações simples de relatórios existentes o tempo todo: "Você pode agrupar por categoria de produto?" ou "Como isso se compara ao mês passado?" Enquanto esperam na fila por uma resposta, seus engenheiros e analistas de dados ficam soterrados em tarefas repetitivas de SQL.
Com o Conversational Analytics no BigQuery, dá para mudar esse gargalo de lugar. Esse recurso leva um mecanismo de raciocínio com IA direto para o BigQuery Studio, permitindo que usuários façam perguntas em linguagem natural e recebam instantaneamente dados, gráficos e SQL gerado.
Neste guia, você vai aprender a configurar e usar analytics conversacional no BigQuery. Você vai criar, configurar e aprimorar seus próprios agentes de dados, para que sua organização possa conversar com os dados com segurança.
Analytics conversacional muda a interação com dados de consultas SQL manuais para conversas em linguagem natural. Em vez de escrever instruções SELECT, você conversa com um agente de dados que entende o contexto do seu negócio e devolve respostas baseadas nas suas tabelas reais.
Isso não é apenas um parser básico de texto para SQL; é um passo importante rumo à verdadeira democratização de dados.
Permite que usuários não técnicos acessem insights em tempo real de forma independente, e dá aos profissionais de dados um jeito rápido de explorar conjuntos de dados e automatizar relatórios.
No coração do analytics conversacional do BigQuery está um mecanismo de raciocínio impulsionado pela família de modelos Gemini. Os agentes de dados usam um pipeline estruturado em múltiplas etapas para garantir que os insights se baseiem no seu contexto de dados específico:
O Google Cloud oferece analytics conversacional em diferentes camadas da sua stack de dados. A escolha da melhor porta de entrada depende dos seus usuários e de onde vive sua lógica de negócio:
|
Recurso |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (via BigQuery Agents) |
|
Melhor para |
Times de dados, analistas e desenvolvedores que constroem apps personalizados |
Usuários de negócio que precisam de insights governados e prontos para dashboards |
Usuários de negócio que preferem BI leve para relatórios |
|
Método de grounding |
Esquemas do data warehouse, metadados de tabelas e queries verificadas |
LookML (camada semântica) |
Conectado diretamente a agentes de dados do BigQuery pré-criados |
|
Acesso a dados |
Pode analisar dados estruturados, preditivos (ML) e não estruturados |
Dados estritamente estruturados e modelados |
Dados estruturados |
|
Status de lançamento |
Prévia (em maio de 2026) |
Disponível de forma geral |
Prévia |
Qual caminho escolher?
Este tutorial foca no BigQuery como a forma mais rápida para times de dados prototiparem e colocarem agentes em produção diretamente onde os dados estão.
É importante entender a arquitetura de um agente de dados antes de configurá-lo. No ambiente Google Cloud, um agente de dados é a camada central de abstração. Ele combina os ativos do BigQuery com as capacidades de raciocínio da família de modelos Gemini.
Em vez de expor tabelas brutas diretamente, um agente de dados configura tudo o que o modelo precisa para interpretar perguntas, gerar SQL seguro e retornar respostas confiáveis. Essa combinação de fontes de dados, instruções e lógica verificada torna o analytics conversacional do BigQuery mais confiável do que ferramentas padrão de texto para SQL.
Fontes de conhecimento são a camada fundamental de qualquer agente de dados. Elas definem exatamente a quais dados o agente pode acessar e consultar.
Tipos de ativos: Tables, Views e User Defined Functions (UDFs) podem se conectar como fontes de conhecimento.
Escalabilidade: Várias fontes de conhecimento podem se conectar a um único agente. Isso permite combinar informações de diferentes áreas de negócio.
Controle de acesso: Definir fontes específicas garante que o agente opere apenas dentro de dados autorizados.
A inteligência de um agente depende do contexto fornecido. Isso é essencial para fazer um modelo genérico entender a linguagem de uma empresa.
Ao definir instruções personalizadas, sinônimos e glossários de negócio, o agente fica ancorado em um domínio específico. Por exemplo, é possível ensinar ao agente que "Top Customers" se refere a usuários com lifetime value (LTV) acima de US$ 1.000.
Elementos-chave de grounding:
Instruções personalizadas: Forneça diretrizes de alto nível, como "Sempre exclua contas de teste internas dos relatórios de receita".
Glossários de negócio: Mapeie termos técnicos para linguagem natural, por exemplo, store_id para "Local da loja".
Metadados de campos: Descrições que ajudam o agente a entender nuances de variáveis específicas, como "Receita bruta" versus "Lucro líquido".
Quanto melhores suas instruções e metadados, maior a precisão do agente.
Consultas verificadas, antes chamadas de Golden Queries, são pares de pergunta e resposta pré-definidos que servem como fonte de verdade. Ao mapear perguntas específicas para SQL revisado por especialistas, o agente usa os joins e filtros corretos para KPIs críticos.
Essas queries podem incluir funções do BigQuery ML (BQML). Isso permite que o agente atenda solicitações avançadas, como gerar previsões de churn ou de vendas, usando exatamente os parâmetros de modelo definidos pelos cientistas de dados. Depois de verificadas, esses ativos são gerenciados via Dataplex Universal Catalog, garantindo consistência em toda a organização.
Agora que você entendeu os blocos de construção, vamos partir para criar e configurar seu primeiro agente de dados.
Para acompanhar nosso tutorial, garanta que você tem os seguintes pré-requisitos:
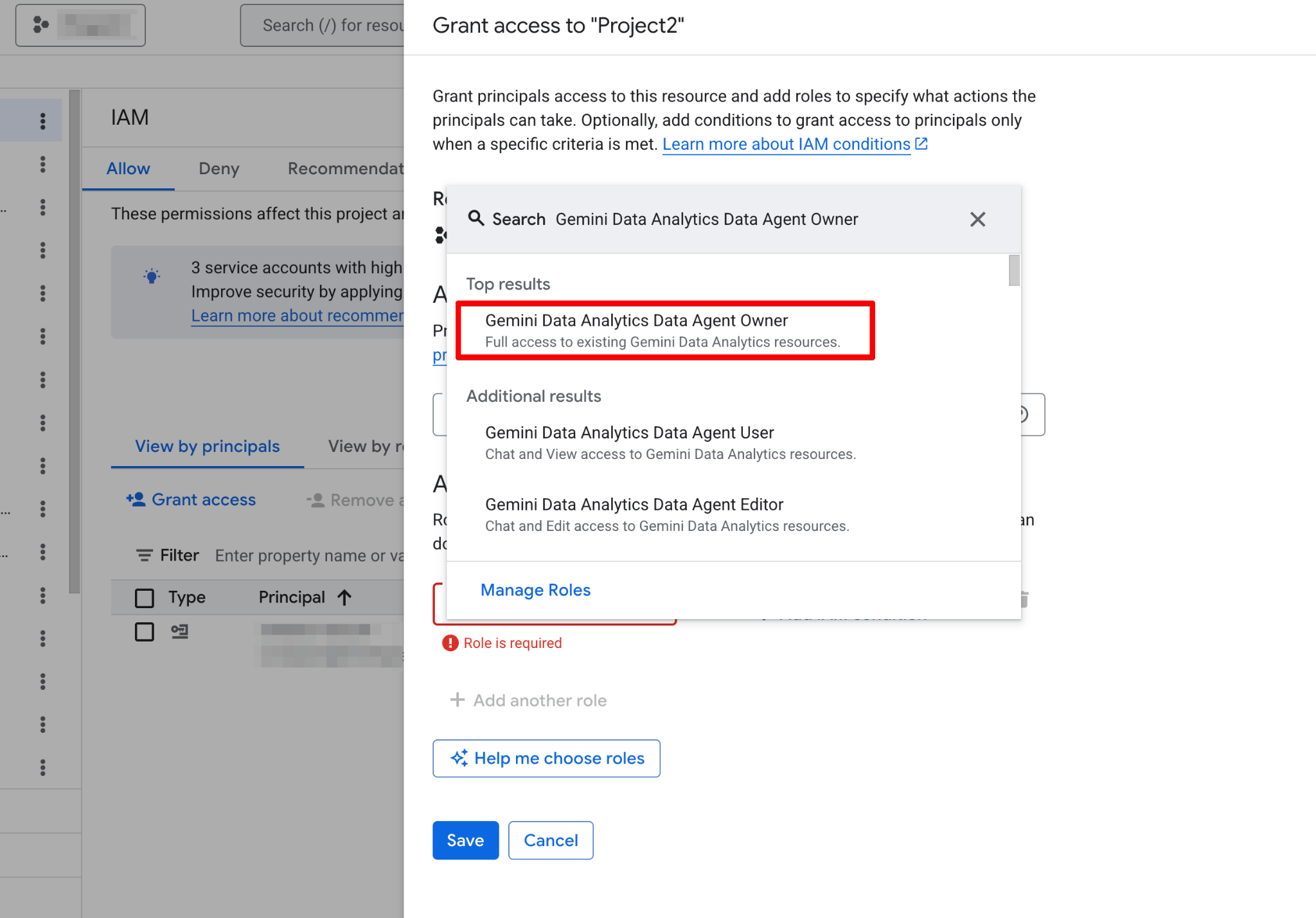
Antes de criar seu primeiro agente, é preciso configurar seu projeto no Google Cloud e garantir que sua conta de usuário tenha as permissões necessárias. Os Data Agents operam como uma camada sobre seus dados existentes, então a configuração correta de IAM (Identity and Access Management) é crítica para segurança e funcionalidade.
Siga estes passos:
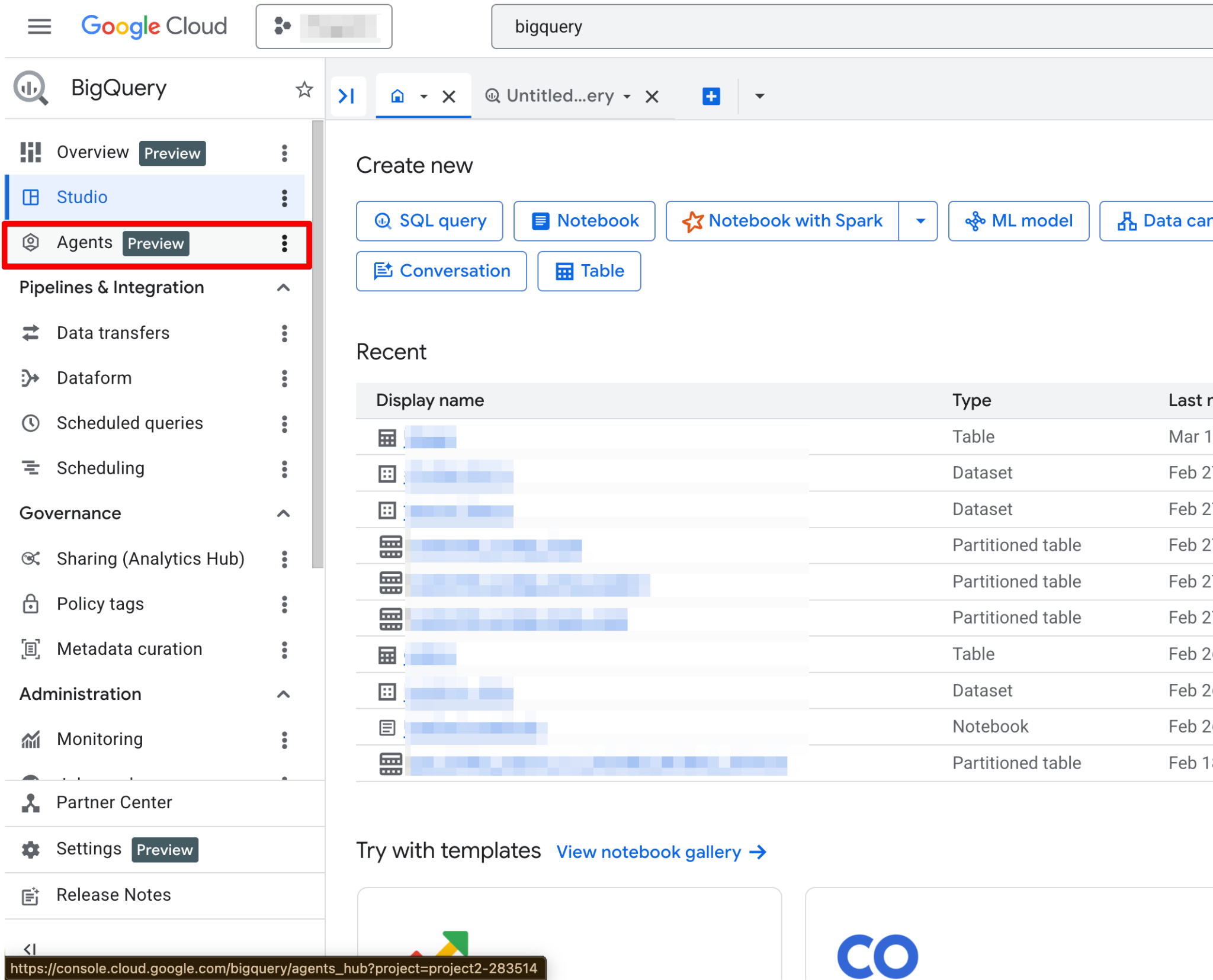
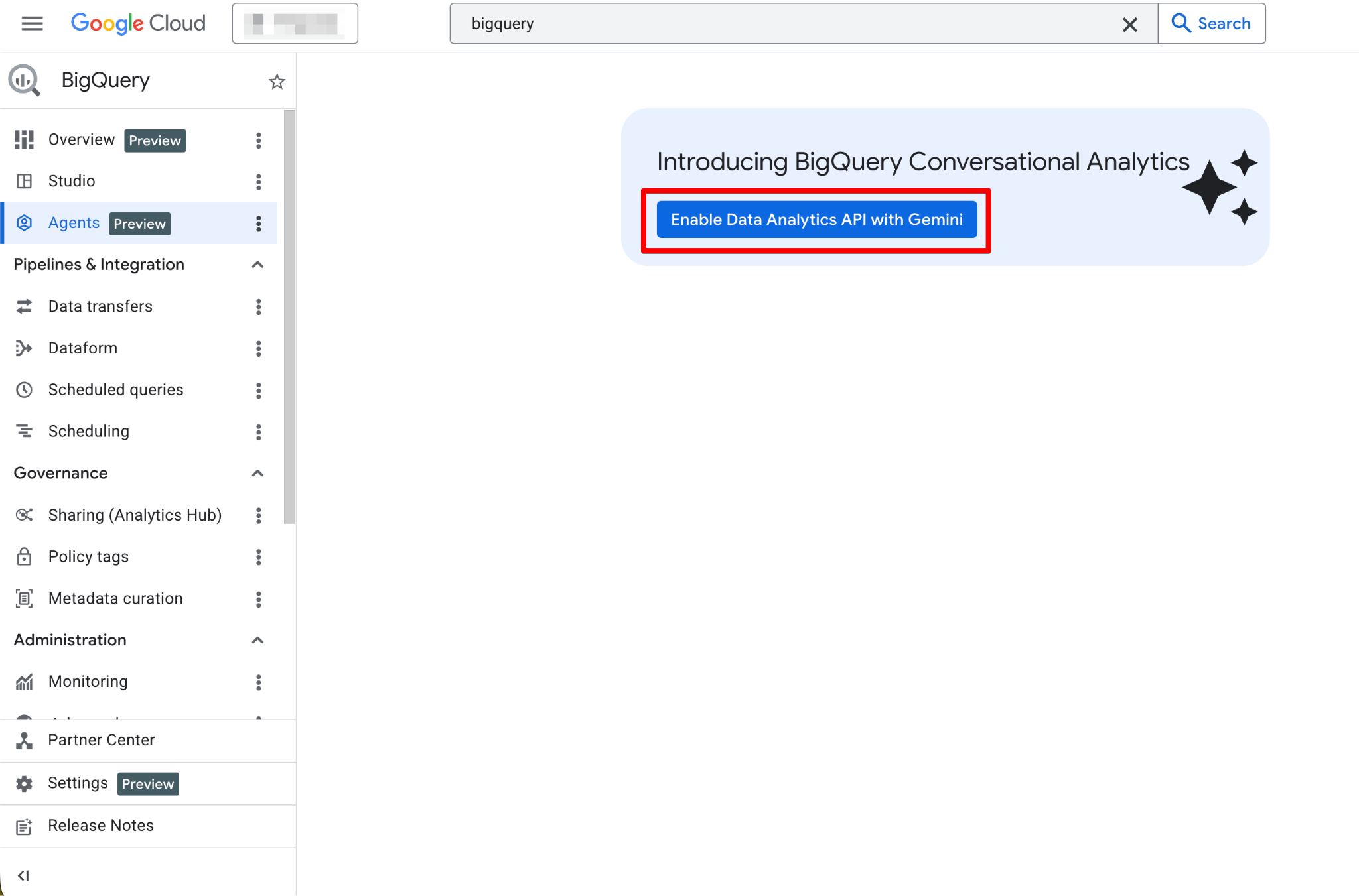
Depois de habilitar, a página Agents fica totalmente funcional. Você já deve ver a nova página de agente:
O Agent Catalog é usado para criar, gerenciar e versionar agentes de dados dentro do BigQuery Studio.
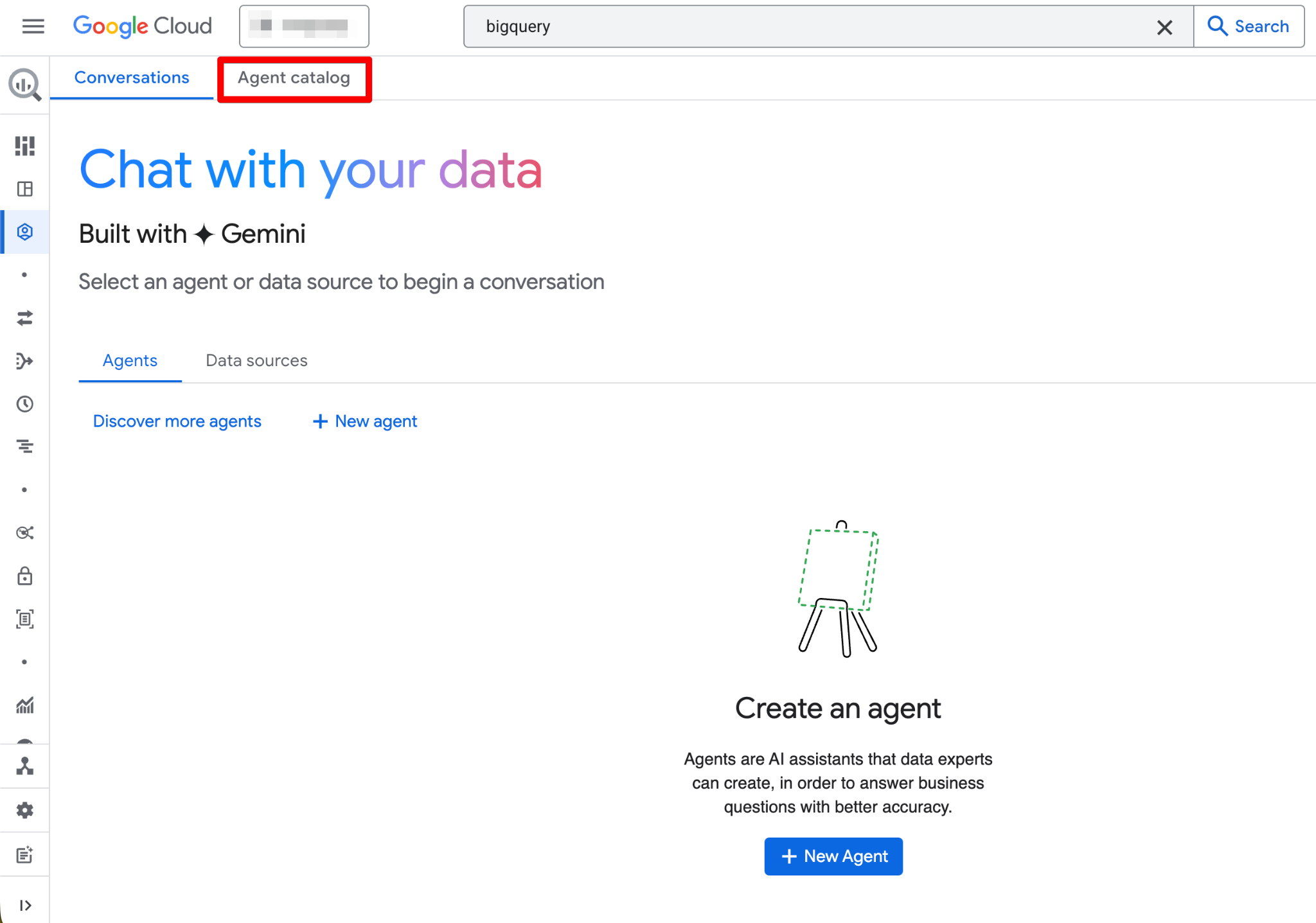
Veja o que você encontra no Agent Catalog:
O ciclo de vida do agente segue esta estrutura (Draft → Created → Published):
Clique em qualquer card de agente para abri-lo, ver detalhes, iniciar uma conversa ou editar (se você tiver permissões de Owner). A interface também inclui uma aba Conversations onde você pode gerenciar conversas anteriores com agentes ou fontes de dados.
Com a base pronta, vamos criar um Data Agent do zero. Vamos usar o dataset bigquery-public-data.austin_bikeshare para transformar dados brutos de viagens em uma interface conversacional. Usaremos duas tabelas:
bikeshare_trips — dados detalhados no nível de viagem
bikeshare_stations — metadados de estações
Iniciando a criação do agente
Esses dois campos ajudam você a identificar o agente rapidamente mais tarde. Depois de definidos, você está pronto para configurar os três blocos centrais que vimos: fontes de conhecimento, instruções e (depois) consultas verificadas.
Fontes de conhecimento definem exatamente a quais dados o agente pode acessar. Quanto menos e mais focadas as fontes, melhor a precisão e menor o custo. Na seção Knowledge sources do editor, clique em Add source. Pesquise por austin_bikeshare e selecione bikeshare_trips e bikeshare_stations como fontes.
Para cada tabela adicionada, clique em Customize.
O Gemini gera automaticamente uma descrição e sugere metadados de colunas. Revise tudo, aceite as sugestões corretas, faça ajustes e clique em Update.
Um erro comum é adicionar 50 tabelas de uma vez. Comece com 2–3 tabelas centrais. Isso facilita depurar a lógica do agente. Você sempre pode ampliar o conhecimento depois que as queries principais estiverem corretas.
Agora, você precisa ancorar seu agente com instruções. Em vez de escrever apenas um prompt genérico (por exemplo, "Responda perguntas sobre vendas"), a interface do agente de dados do BigQuery permite fornecer um contexto altamente estruturado para guiar a geração de queries pela IA. Pense nisso como integrar um novo analista com o dicionário de dados exato da sua empresa.
Use o campo Instructions para fornecer contexto de negócio estruturado. Aqui vai um exemplo completo e pronto para uso que você pode colar:
Sinônimos: Defina termos alternativos para suas colunas para que o agente entenda variações em linguagem natural. Exemplo: "Journey", "Ride" e "Commute" se referem a um registro na tabela bikeshare_trips. "Dock", "Hub" ou "Station" se referem a um registro na tabela bikeshare_stations.
Campos-chave: Destaque os campos mais importantes para análise. Isso indica ao agente quais colunas priorizar quando a pergunta do usuário for ampla. Exemplo: Priorize trip_id, start_station_name, end_station_name, subscriber_type, start_time e duration_minutes para relatórios gerais.
Campos excluídos: Especifique colunas que o agente deve evitar estritamente. Isso é muito útil para ocultar colunas obsoletas ou dados irrelevantes. Exemplo: Não use a coluna bike_id na tabela bikeshare_trips para a maioria das análises, pois ela raramente é necessária para questões de negócio.
Filtragem e agrupamento: Instrua o agente sobre formas padrão de recortar os dados. Exemplo: A menos que especificado, sempre filtre viagens com duration_minutes < 1 (são falsos inícios ou testes). Por padrão, agrupe por start_station_name quando o usuário pedir “por estação” ou “estações com mais movimento”.
Relacionamentos de join: Como nosso agente puxa de múltiplas tabelas, defina explicitamente como elas se conectam. Isso evita que o agente chute chaves estrangeiras erradas. Exemplo: Faça join da tabela bikeshare_trips com bikeshare_stations casando bikeshare_trips.start_station_id com bikeshare_stations.station_id (e similarmente para end_station_id).
Você pode combinar tudo isso em um bloco limpo no campo Instructions. Aqui vai uma versão polida e pronta para colar que incorpora a orientação estruturada:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).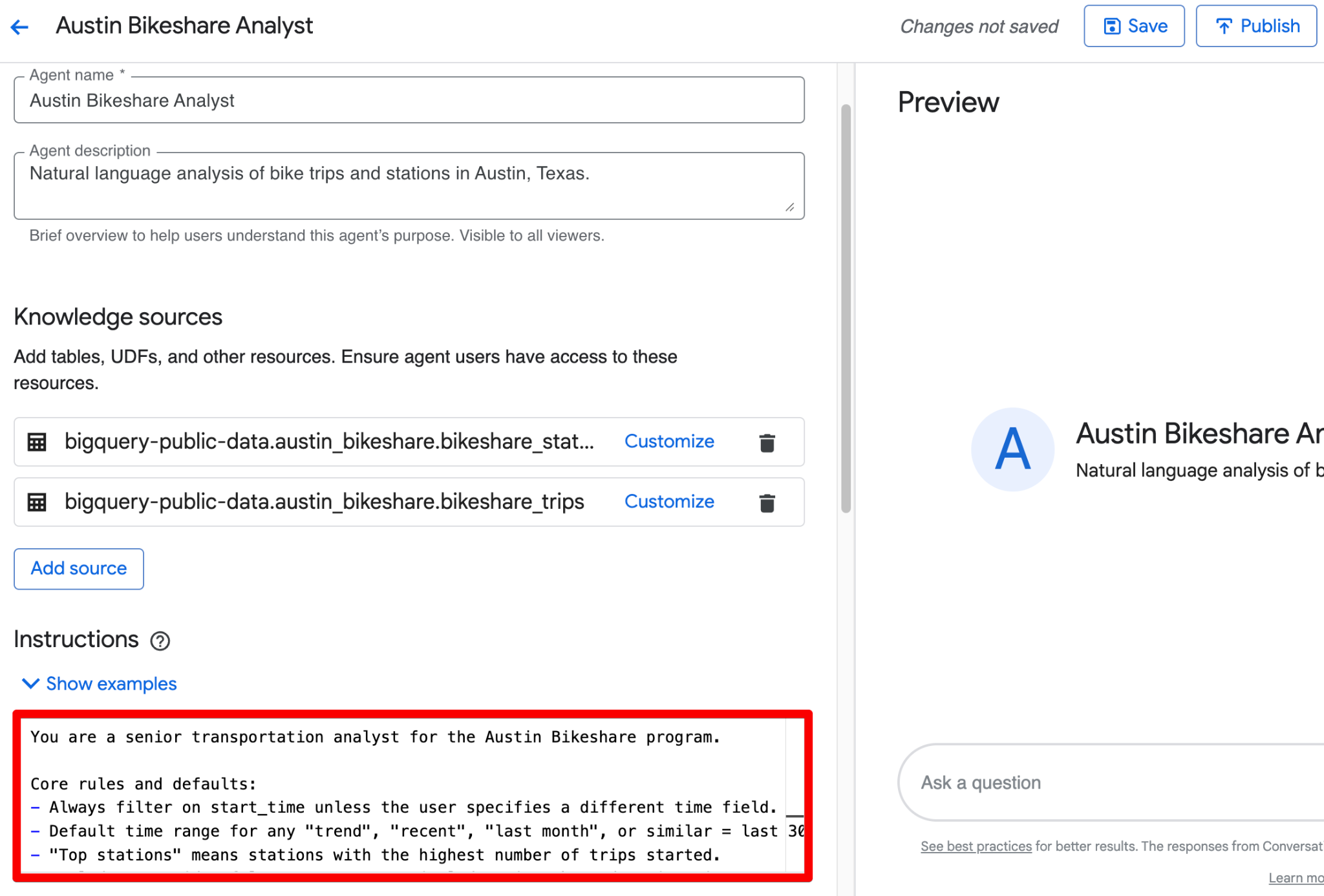
Por que isso importa: Se você deixar esses campos em branco, uma pergunta ambígua como "Quais foram nossas maiores vendas?" pode fazer o agente juntar tabelas erradas, puxar contas inativas ou incluir dados obsoletos. Ao estruturar suas instruções nessas cinco categorias, você garante que o SQL gerado siga à risca sua lógica de negócio.
Além das instruções, você pode (e deve) definir termos de glossário diretamente no agente. Eles ajudam o agente a interpretar jargões de negócio, abreviações e conceitos derivados de forma consistente.
Clique Add term na seção Glossary (geralmente perto de Instructions) e crie termos com termo, definição e sinônimos (separados por vírgula).
Aqui vão termos de glossário recomendados para o dataset Austin Bikeshare:
| Termo | Definição | Sinônimos |
duration_minutes |
Duração da viagem em minutos. Sempre use isso para respostas e cálculos voltados ao usuário | tempo de pedal, duração da viagem, duração, duração do trajeto |
ridership |
Número total (contagem) de viagens de bike iniciadas | viagens, corridas, trajetos, uso de bike, contagem de deslocamentos |
peak_hours |
Horas de pico da manhã (7–9) ou da tarde (16–19) com base na hora extraída de start_time |
hora do rush, horários de maior movimento, período de alta demanda |
subscriber_type |
Tipo de ciclista — Subscriber (assinante mensal ou anual) ou Customer (viagem avulsa | tipo de usuário, tipo de assinatura, assinante, membro, usuário casual |
false_start |
Uma viagem muito curta (geralmente menos de 1 minuto) que provavelmente é um teste ou desbloqueio acidental. Normalmente devem ser excluídas da análise | teste, viagem inválida, viagem curta |
Você pode adicionar mais termos conforme necessário (por exemplo, para start_station_name, end_station_name ou métricas derivadas como “duração média da viagem” ou “viagem longa”).
Ao usar glossários, se a liderança decidir mudar a definição oficial de “Viagem longa” para 45 minutos no próximo trimestre, seu time de governança de dados só precisa atualizar uma vez no Dataplex. Todo Data Agent conectado a esse glossário adota imediatamente a nova lógica, mantendo a consistência em toda a organização.
Depois de configurar fontes de conhecimento, instruções e termos de glossário, é hora de testar seu agente antes de publicar.
Role até o painel Preview à direita. Essa interface de chat ao vivo permite interagir com seu agente em tempo real enquanto você constrói. Você pode fazer perguntas, revisar o raciocínio do agente, inspecionar o SQL gerado e iterar rapidamente.
O painel Preview mostra:
Experimente estas quatro consultas de complexidade crescente (ajuste ao intervalo de dados do dataset até 2024):
O que você verá na resposta do agente:
Resumo — Uma explicação em linguagem natural dos resultados.
Resultado da consulta — Uma tabela limpa com os dados (por exemplo, total de viagens, principais estações ou duração média).
Insights — Tópicos com interpretações dos resultados no contexto do negócio.
SQL gerado — Clique em Open in Editor para ver a query completa criada pelo agente (você verá que ela filtra corretamente por start_time e aplica duration_minutes >= 1 para excluir falsos inícios).
Perguntas sugeridas — Prompts úteis no final (por exemplo, “Quais foram as top 10 estações de partida em junho de 2024?”, “Faça a previsão do número diário de viagens…”, etc.).
Visualização — Um gráfico gerado automaticamente (gráfico de barras para rankings, como no exemplo das top 5 estações).
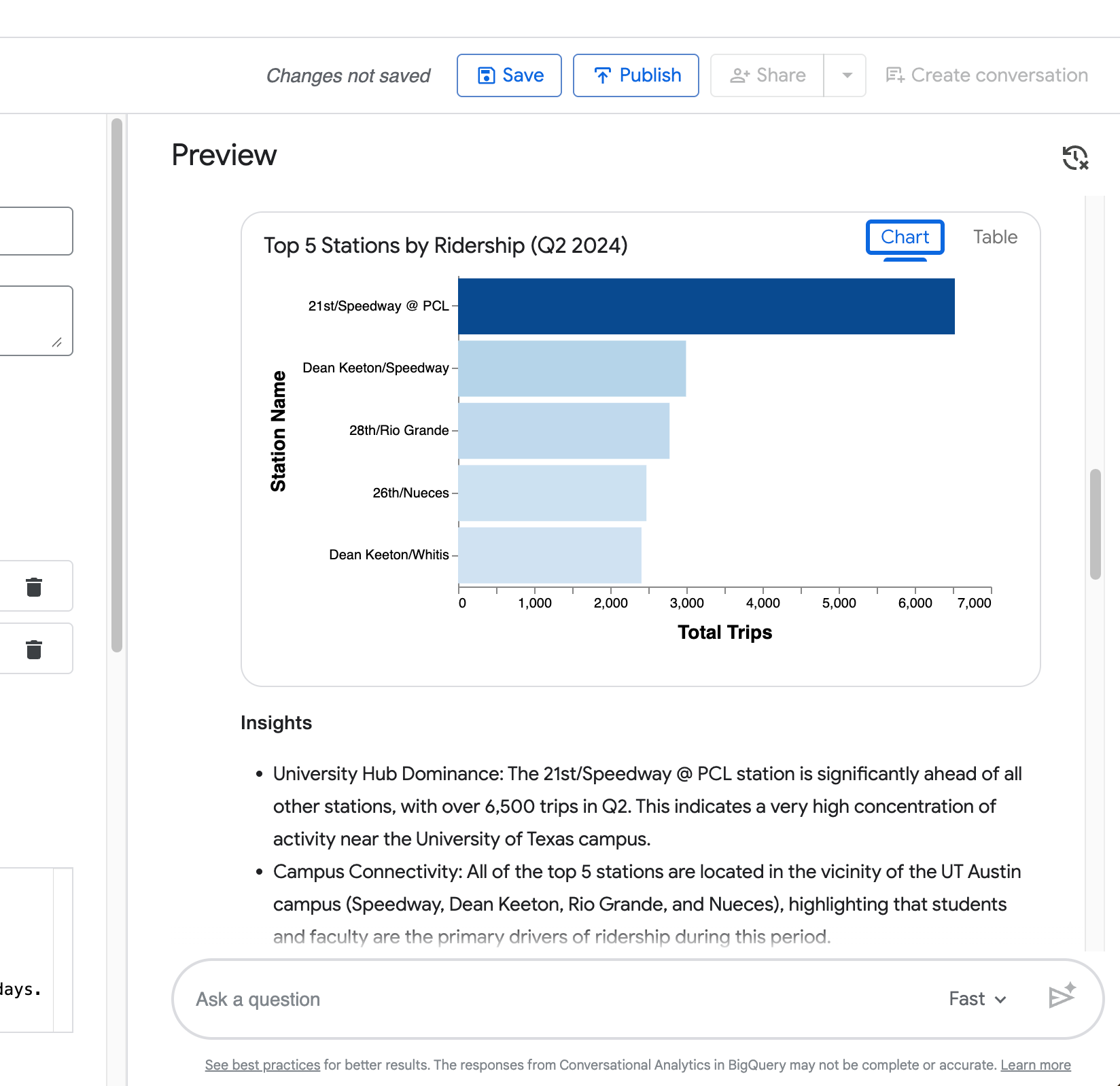
Sua quarta consulta (“Agora mostre a mesma comparação, mas apenas para a estação Zilker Park”) demonstra a capacidade do agente de reter o contexto da pergunta anterior.
Como você pode ver na captura a seguir, ele restringe corretamente a comparação de duração entre dias de semana e fins de semana para Zilker Park sem você repetir o pedido completo.
Dicas de teste:
Quando o agente passar a entregar respostas claras, precisas e bem estruturadas de forma consistente, clique em Save no topo e depois em Publish. Seu agente Austin Bikeshare Analyst está pronto para uso!
Mesmo com boas instruções e termos de glossário, seu agente de dados ainda pode ocasionalmente interpretar mal regras de negócio ou gerar respostas inconsistentes.
Consultas verificadas resolvem isso ao permitir que você ensine explicitamente ao agente a forma correta de lidar com perguntas importantes ou frequentes. Cada consulta verificada consiste em uma pergunta em linguagem natural pareada com o SQL exato que deve ser usado.
Elas funcionam como exemplos de alta qualidade que ancoram o raciocínio do agente e são uma das formas mais eficazes de evoluir de um agente “ok” para um pronto para produção.
No editor do agente, role até a seção Verified Queries. Você tem duas formas fáceis de adicionar consultas verificadas:
Clique em Add query. Você verá a tela Add verified query, onde pode:
Clique em View Gemini-generated suggestions. Isso abre a tela “Review suggested verified queries”, em que o Gemini propõe perguntas relevantes com base nas suas fontes de conhecimento.
Você pode:
Um bom exemplo de consulta verificada para o dataset Austin Bikeshare seria:
Pergunta:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;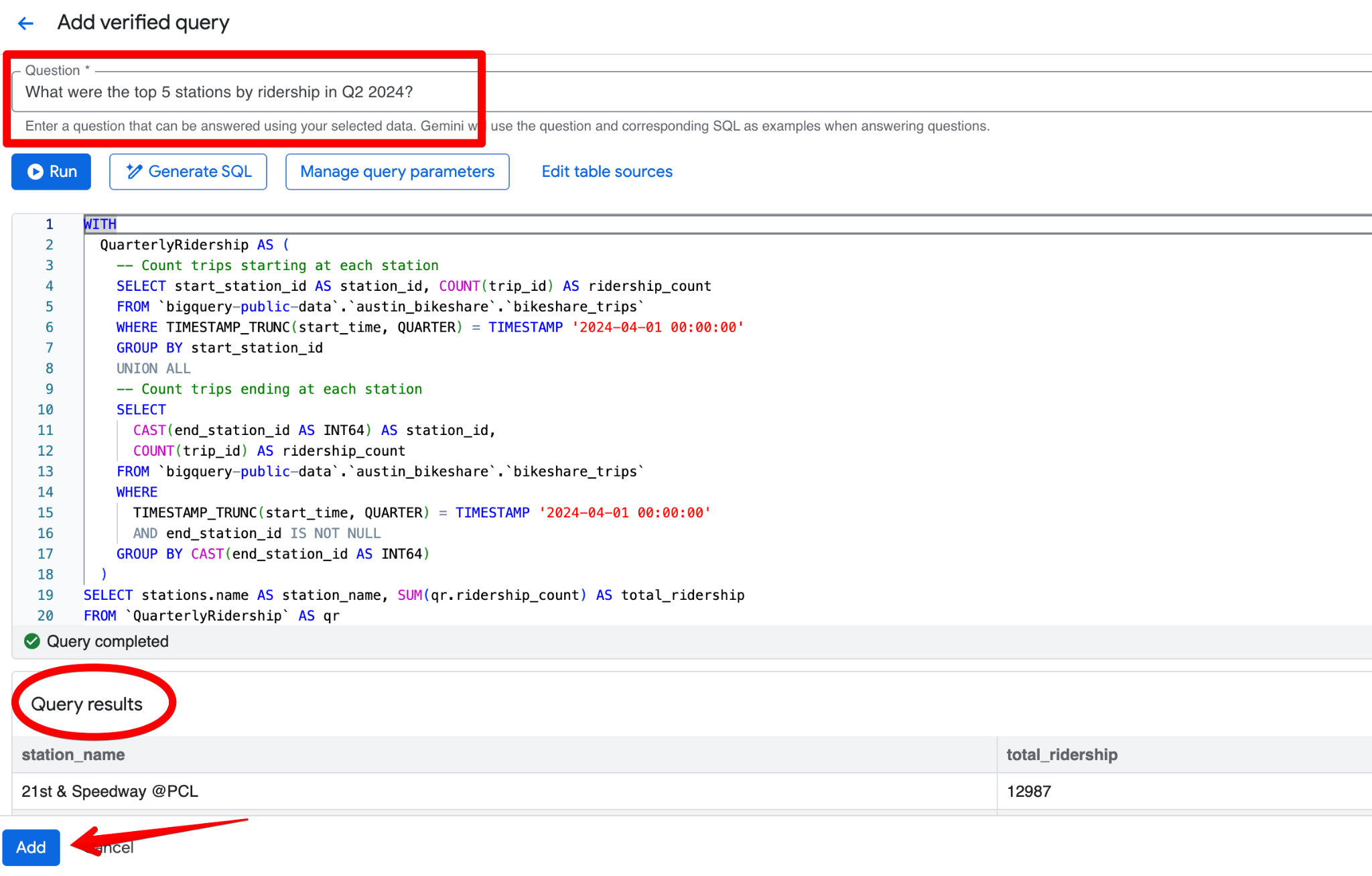
Mesmo quando o agente traz uma resposta razoável de primeira, você pode deixá-la muito mais precisa e consistente revisando o SQL gerado e adicionando consultas verificadas.
Siga este fluxo prático:
Digamos que você perguntou: “Qual foi a duração média das viagens em junho de 2024?” Na resposta inicial, o agente retorna 26,68 minutos e exclui corretamente viagens com menos de 1 minuto. Agora, suponha que a regra de negócio padrão do time seja excluir qualquer viagem com menos de 5 minutos.
Ao abrir o SQL gerado (via Open in Editor), você vê que o filtro está apenas em duration_minutes >= 1.
Clique em Add query na seção Verified Queries e crie esta entrada:
Pergunta:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes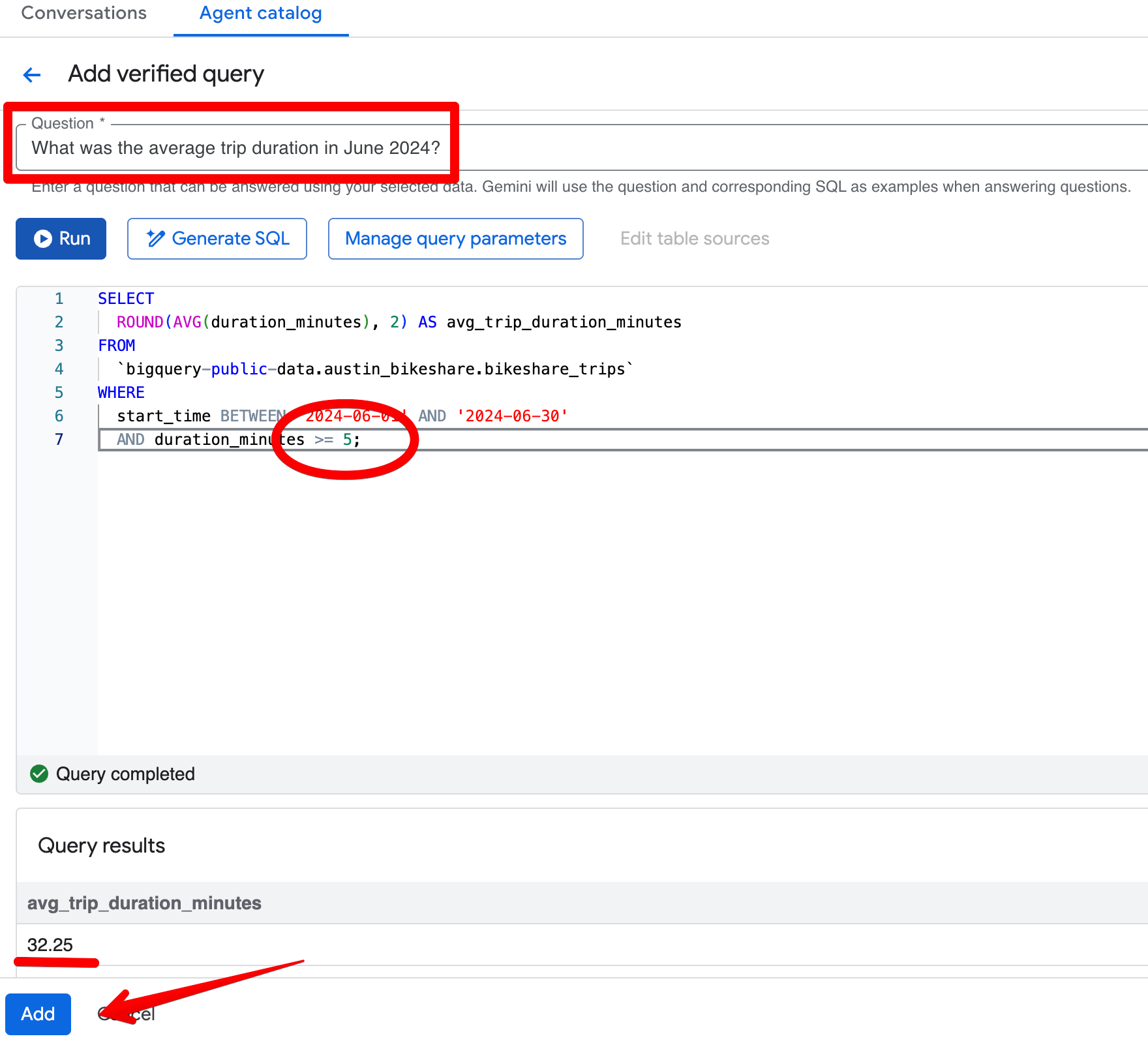
Depois de salvar a consulta verificada, refaça a mesma pergunta no painel Preview. O agente agora retorna de forma consistente ~32,08 minutos e aplica seu limite mais rigoroso de 5 minutos. Os resultados ficam mais alinhados com a sua visão de negócio de viagens “significativas”.
O analytics conversacional do BigQuery se destaca das ferramentas simples de texto para SQL por oferecer suporte nativo a funções do BigQuery ML, dados não estruturados e compartilhamento facilitado em todo o ecossistema do Google Cloud.
Um dos maiores diferenciais é a capacidade do agente de chamar funções do BigQuery ML diretamente a partir de linguagem natural, indo além de relatórios retrospectivos para insights preditivos.
Por exemplo, você pode pedir a um agente de dados para prever o número diário de viagens nos próximos 30 dias com base nas tendências de 2024. Ele acionará AI.FORECAST e gerará uma previsão para julho de 2024 junto com um gráfico mostrando as viagens diárias históricas (linha azul) e a previsão de 30 dias (linha laranja) com intervalo de confiança de 95% sombreado.
Outra forma como algoritmos de machine learning podem ajudar é detectando se há algo fora do esperado nos seus dados. Quando você, por exemplo, pede a um agente para detectar anomalias no ridership diário durante junho de 2024, ele invoca AI.DETECT_ANOMALIES, comparando junho de 2024 com meses anteriores, e retorna uma tabela de série temporal mais um gráfico de linha.
Nesse caso, não sinalizou anomalias formais ao nível de confiança de 95%, mas destacou 19 de junho como quase-anomalia (92,1% de probabilidade) com uma queda perceptível no ridership.
A maioria das ferramentas de BI conversacional falha quando os dados não estão organizados em linhas e colunas. O BigQuery, no entanto, suporta Object Tables, que permitem analisar dados não estruturados (como PDFs, imagens e logs de texto) armazenados no Google Cloud Storage.
Como o Data Agent é potencializado pelos recursos multimodais do Gemini, ele consegue raciocinar simultaneamente sobre seus métricos estruturados e seus arquivos não estruturados. Esse é um grande diferencial do BigQuery.
Se você tiver PDFs de pesquisas com usuários ou imagens de inspeção de estações em uma object table, basta pedir: “Resuma as principais reclamações dos PDFs da pesquisa de usuários do 2º tri de 2024.” O agente vai ler os arquivos não estruturados e combinar a informação com seus dados estruturados de viagens
Seu time de dados cria e testa Data Agents no BigQuery Studio, mas seus usuários finais provavelmente trabalham em aplicativos diferentes. O Google facilita desacoplar o agente do Console do GCP para você encontrar os usuários de negócio onde eles já estão.
Se quiser tentar criar você mesmo um aplicativo de chat personalizado, você também pode ler mais no Introduction to Conversational Analytics in BigQuery oficial.
Se existe um princípio-chave para levar daqui, é este: analytics conversacional desloca o gargalo analítico de esperar pelo time de dados para simplesmente fazer a pergunta certa.
Essa democratização não torna os times de dados obsoletos, mas muda seu papel. Um agente de IA só é tão inteligente quanto os trilhos de segurança que você constrói ao redor dele. A precisão e a segurança dos seus agentes de dados dependem inteiramente das instruções, do contexto e da arquitetura de esquemas que você fornece.
Para criar agentes conversacionais realmente eficazes, você ainda precisa dominar bem o data warehouse por trás de tudo. Se você ou seu time querem fortalecer essas competências e dominar a plataforma que potencializa esses recursos de IA, conheça hoje o curso Introduction to BigQuery da DataCamp!
Cursos do Google Cloud
Programa
Curso
Curso
blog
Javier Canales Luna
14 min
blog
Khalid Abdelaty
15 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Matt Crabtree
Tutorial
Matt Crabtree

