
Tracks
Chuyên gia Lãnh đạo Công nghệ Điện tử Google Cloud
8 giờ
Nếu bạn làm việc trong một nhóm dữ liệu, kịch bản này hẳn không xa lạ: tồn đọng của bạn đang chất đống các yêu cầu phát sinh. Người dùng nghiệp vụ liên tục cần các biến thể đơn giản của báo cáo hiện có và hỏi, "Bạn có thể nhóm theo danh mục sản phẩm không?", hoặc "Điều này so với tháng trước như thế nào?" Trong khi họ chờ đến lượt được trả lời, kỹ sư dữ liệu và nhà phân tích của bạn lại vùi đầu vào các tác vụ SQL lặp lại.
Với Conversational Analytics trong BigQuery, bạn cuối cùng có thể chuyển điểm nghẽn. Tính năng này đưa một động cơ suy luận do AI hỗ trợ trực tiếp vào BigQuery Studio, cho phép người dùng đặt câu hỏi bằng ngôn ngữ tự nhiên và ngay lập tức nhận được dữ liệu, biểu đồ, cùng SQL được tạo ra.
Trong hướng dẫn này, bạn sẽ học cách thiết lập và sử dụng phân tích hội thoại trong BigQuery. Bạn sẽ xây dựng, cấu hình và tinh chỉnh tác vụ dữ liệu của riêng mình, để tổ chức của bạn có thể trò chuyện an toàn với dữ liệu của mình.
Phân tích hội thoại chuyển cách tương tác dữ liệu từ truy vấn SQL thủ công sang hội thoại ngôn ngữ tự nhiên. Thay vì viết các câu lệnh SELECT, bạn trò chuyện với một tác vụ dữ liệu hiểu bối cảnh doanh nghiệp của bạn và trả về câu trả lời dựa trên chính các bảng thực tế.
Đây không chỉ là một bộ phân tích text-to-SQL cơ bản; mà là một bước tiến sâu sắc hướng tới việc dân chủ hóa dữ liệu thực sự.
Nó cho phép người dùng không chuyên kỹ thuật truy cập thông tin chuyên sâu theo thời gian thực một cách độc lập, và mang đến cho các chuyên gia dữ liệu một cách nhanh chóng để khám phá tập dữ liệu và tự động hóa báo cáo.
Trung tâm của phân tích hội thoại trong BigQuery là một động cơ suy luận được hỗ trợ bởi họ mô hình Gemini. Các tác vụ dữ liệu sử dụng một quy trình có cấu trúc nhiều giai đoạn để đảm bảo thông tin chuyên sâu được dựa trên bối cảnh dữ liệu cụ thể của bạn:
Google Cloud cung cấp phân tích hội thoại trên các lớp khác nhau trong ngăn xếp dữ liệu của bạn. Lựa chọn điểm bắt đầu phù hợp phụ thuộc vào người dùng của bạn và nơi logic nghiệp vụ của bạn tồn tại:
|
Tính năng |
Conversational Analytics trong BigQuery |
Conversational Analytics trong Looker |
Data Studio (qua BigQuery Agents) |
|
Phù hợp nhất cho |
Nhóm dữ liệu, nhà phân tích và nhà phát triển xây dựng ứng dụng tùy chỉnh |
Người dùng nghiệp vụ cần thông tin chuyên sâu được quản trị, sẵn sàng cho bảng điều khiển |
Người dùng nghiệp vụ ưa thích báo cáo BI gọn nhẹ |
|
Phương thức nền tảng |
Lược đồ kho dữ liệu trực tiếp, siêu dữ liệu bảng và truy vấn đã được xác minh |
LookML (lớp ngữ nghĩa) |
Kết nối trực tiếp đến các tác vụ dữ liệu BigQuery dựng sẵn |
|
Truy cập dữ liệu |
Có thể phân tích dữ liệu có cấu trúc, dự đoán (ML) và phi cấu trúc |
Dữ liệu có cấu trúc, được mô hình hóa nghiêm ngặt |
Dữ liệu có cấu trúc |
|
Trạng thái phát hành |
Xem trước (tính đến tháng 5/2026) |
Phát hành chung |
Xem trước |
Bạn nên chọn lộ trình nào?
Hướng dẫn này tập trung vào BigQuery như cách nhanh nhất để các nhóm dữ liệu tạo mẫu và đưa tác vụ vào vận hành ngay tại nơi dữ liệu tồn tại.
Việc hiểu kiến trúc của một tác vụ dữ liệu trước khi thiết lập là rất quan trọng. Trong môi trường Google Cloud, tác vụ dữ liệu là lớp trừu tượng trung tâm. Nó kết hợp các tài nguyên BigQuery với khả năng suy luận của họ mô hình Gemini.
Thay vì phơi bày trực tiếp các bảng thô, một tác vụ dữ liệu cấu hình mọi thứ mô hình cần để diễn giải câu hỏi, tạo SQL an toàn và trả về câu trả lời đáng tin cậy. Sự kết hợp giữa nguồn dữ liệu, hướng dẫn và logic đã xác minh này khiến phân tích hội thoại của BigQuery đáng tin cậy hơn các công cụ text-to-SQL tiêu chuẩn.
Nguồn tri thức là lớp nền tảng của bất kỳ tác vụ dữ liệu nào. Chúng xác định chính xác dữ liệu nào tác vụ được phép truy cập và truy vấn.
Loại tài nguyên: Bảng (Tables), Chế độ xem (Views) và Hàm do người dùng định nghĩa (UDFs) có thể kết nối làm nguồn tri thức.
Khả năng mở rộng: Nhiều nguồn tri thức có thể kết nối với một tác vụ duy nhất. Điều này cho phép tác vụ kết hợp thông tin trên các mảng nghiệp vụ khác nhau.
Kiểm soát truy cập: Việc xác định các nguồn tri thức cụ thể đảm bảo tác vụ chỉ hoạt động trong phạm vi dữ liệu được ủy quyền.
Độ thông minh của một tác vụ phụ thuộc vào bối cảnh được cung cấp. Đây là chìa khóa giúp một mô hình chung hiểu ngôn ngữ của công ty.
Bằng cách định nghĩa hướng dẫn tùy chỉnh, từ đồng nghĩa và từ điển thuật ngữ doanh nghiệp, tác vụ được “neo” vào một miền cụ thể. Ví dụ, có thể dạy cho tác vụ rằng "Top Customers" là người dùng có giá trị vòng đời (LTV) trên 1.000 đô la.
Các thành phần nền tảng chính:
Hướng dẫn tùy chỉnh: Cung cấp chỉ thị cấp cao, như "Luôn loại trừ tài khoản thử nghiệm nội bộ khỏi báo cáo doanh thu."
Từ điển thuật ngữ doanh nghiệp: Ánh xạ thuật ngữ kỹ thuật sang ngôn ngữ tự nhiên, ví dụ, store_id sang "Địa điểm chi nhánh".
Siêu dữ liệu trường: Mô tả giúp tác vụ hiểu sắc thái của các biến cụ thể, như "Doanh thu gộp" so với "Lợi nhuận ròng".
Hướng dẫn và siêu dữ liệu của bạn càng tốt, độ chính xác của tác vụ càng cao.
Truy vấn đã xác minh, trước đây gọi là Golden Queries, là các cặp hỏi-đáp được định nghĩa sẵn và đóng vai trò nguồn chân lý. Bằng cách ánh xạ các câu hỏi cụ thể tới SQL đã được chuyên gia thẩm định, tác vụ sử dụng đúng đường nối bảng và bộ lọc cho các KPI quan trọng.
Các truy vấn này có thể bao gồm các hàm BigQuery ML (BQML). Điều này cho phép tác vụ xử lý các yêu cầu nâng cao, như tạo dự đoán rời bỏ hoặc dự báo doanh số, bằng đúng tham số mô hình do nhà khoa học dữ liệu định nghĩa. Khi đã xác minh, các tài nguyên này được quản lý qua Dataplex Universal Catalog, đảm bảo tính nhất quán trên toàn tổ chức.
Giờ bạn đã hiểu các khối xây dựng, hãy chuyển sang xây dựng và cấu hình tác vụ dữ liệu đầu tiên của bạn.
Để theo dõi hướng dẫn, vui lòng đảm bảo bạn có các điều kiện tiên quyết sau:
Trước khi xây dựng tác vụ đầu tiên, bạn phải cấu hình dự án Google Cloud và đảm bảo tài khoản người dùng của bạn có quyền cần thiết. Data Agents hoạt động như một lớp bên trên dữ liệu hiện có của bạn, vì vậy cấu hình IAM (Quản lý danh tính và truy cập) chính xác là rất quan trọng cho cả bảo mật lẫn chức năng.
Thực hiện theo các bước sau:
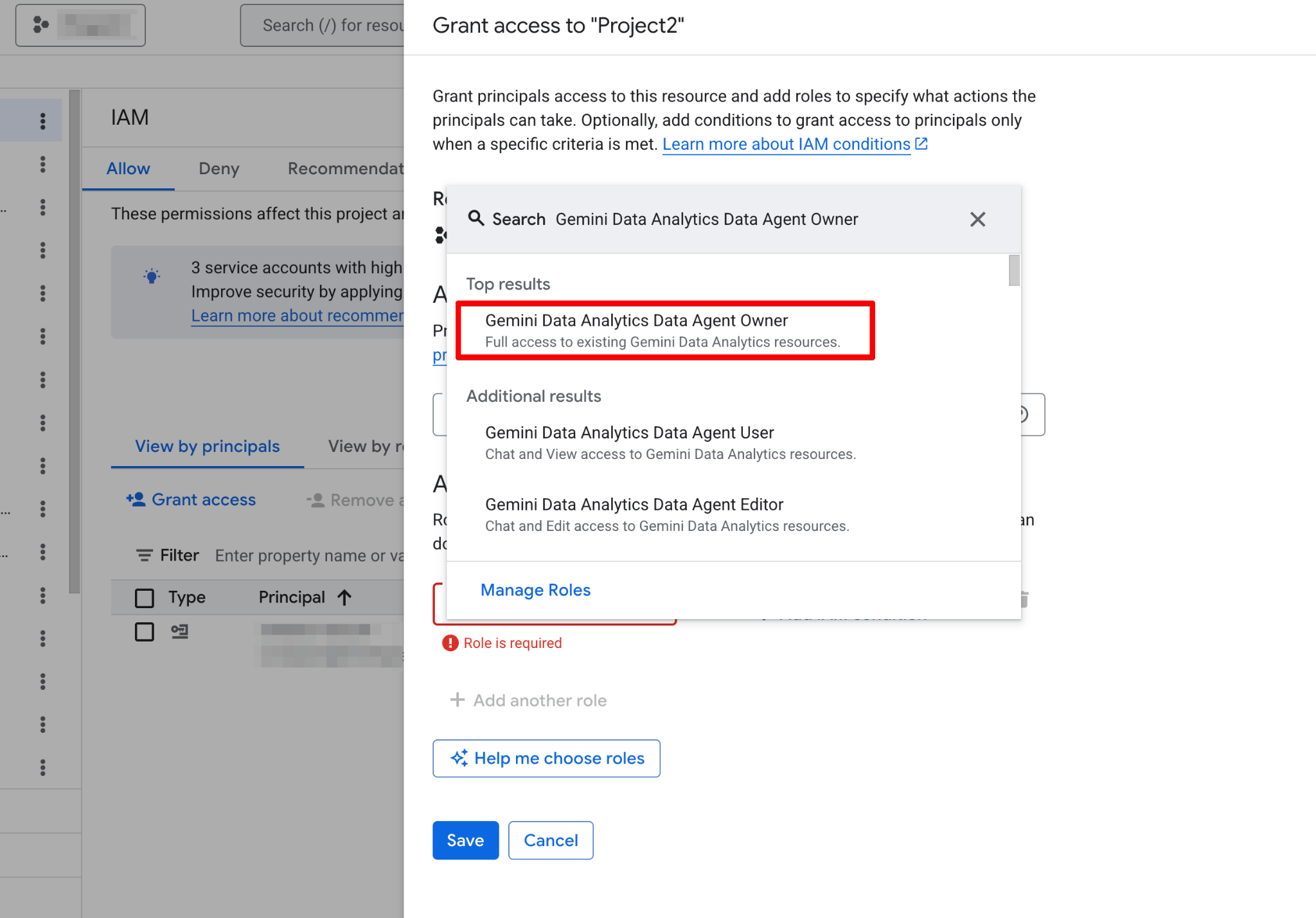
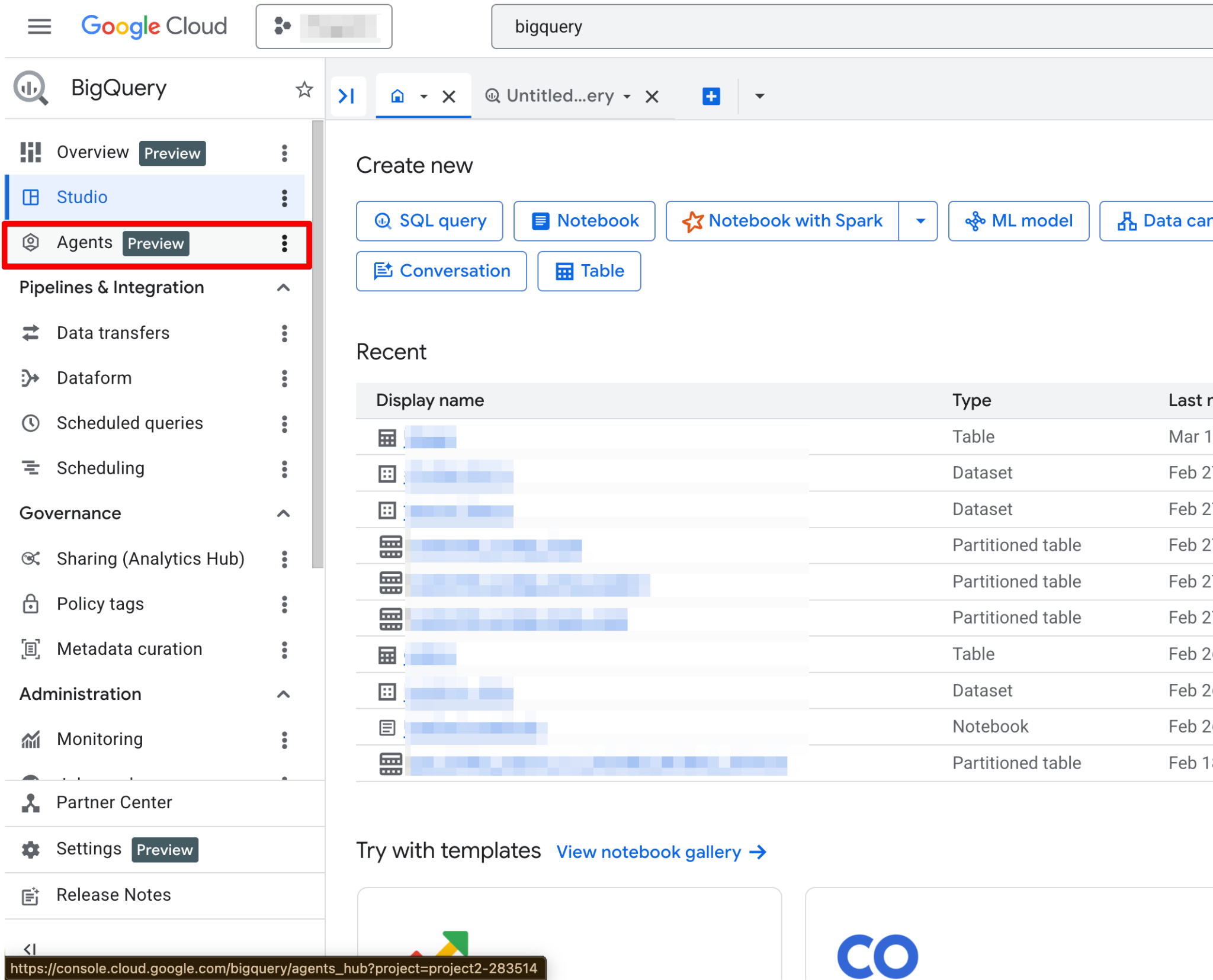
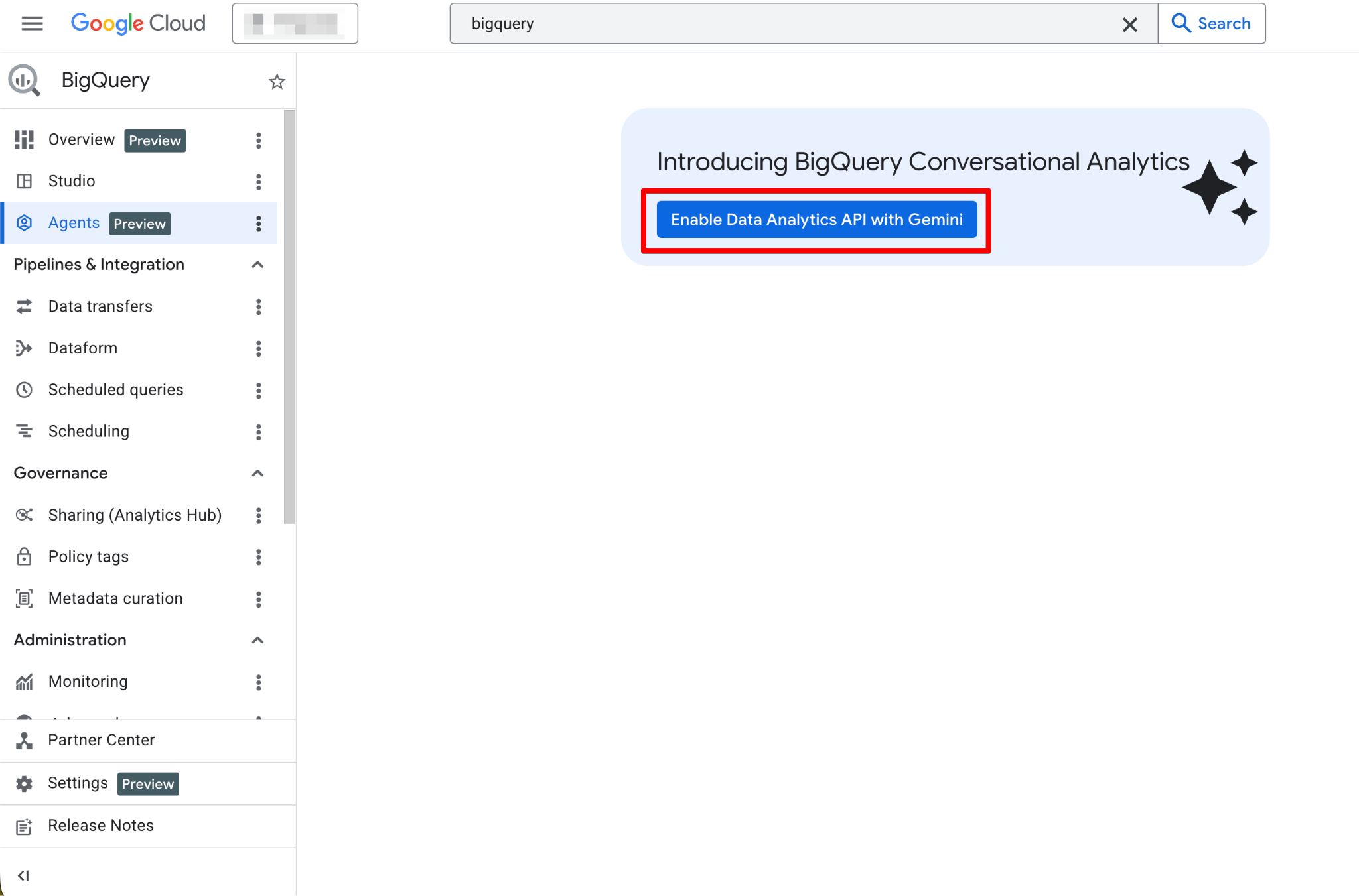
Khi đã bật, trang Agents sẽ hoạt động đầy đủ. Giờ bạn sẽ thấy trang tác vụ mới:
Agent Catalog được dùng để tạo, quản lý và tạo phiên bản các tác vụ dữ liệu trong BigQuery Studio.
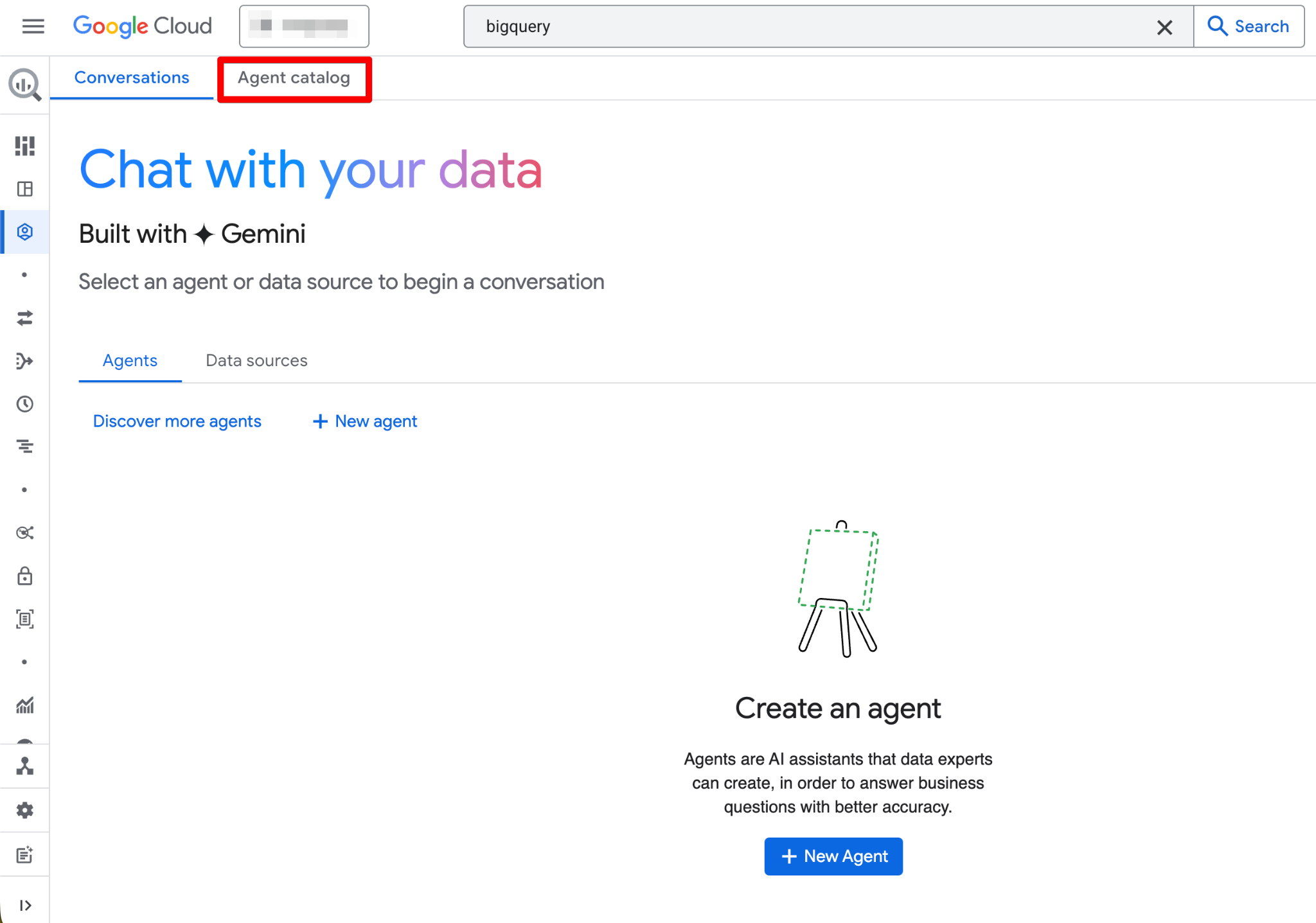
Bạn sẽ tìm thấy gì trong Agent Catalog:
Vòng đời của tác vụ tuân theo cấu trúc này (Draft → Created → Published):
Nhấp vào bất kỳ thẻ tác vụ nào để mở, xem chi tiết, bắt đầu hội thoại hoặc chỉnh sửa (nếu bạn có quyền Owner). Giao diện cũng có thẻ Conversations nơi bạn có thể quản lý các cuộc trò chuyện đã qua với tác vụ hoặc nguồn dữ liệu.
Khi nền tảng đã sẵn sàng, hãy xây dựng một Tác vụ Dữ liệu từ đầu. Chúng ta sẽ sử dụng bộ dữ liệu bigquery-public-data.austin_bikeshare để biến dữ liệu chuyến đi thô thành một giao diện hội thoại. Chúng ta sẽ dùng hai bảng:
bikeshare_trips — dữ liệu chi tiết cấp chuyến đi
bikeshare_stations — siêu dữ liệu trạm
Bắt đầu tạo tác vụ
Hai trường này giúp bạn nhanh chóng nhận diện tác vụ sau này. Khi đã thiết lập, bạn sẵn sàng cấu hình ba khối xây dựng cốt lõi đã đề cập: nguồn tri thức, hướng dẫn và (sau đó) truy vấn đã xác minh.
Nguồn tri thức xác định chính xác dữ liệu mà tác vụ có thể truy cập. Nguồn càng ít và tập trung, độ chính xác càng cao và chi phí càng thấp. Trong phần Knowledge sources của trình soạn thảo, nhấp Add source. Tìm austin_bikeshare và chọn bikeshare_trips và bikeshare_stations làm nguồn.
Với mỗi bảng bạn thêm, nhấp Customize.
Gemini sẽ tự động tạo mô tả và gợi ý siêu dữ liệu cột. Rà soát mọi thứ, chấp nhận các gợi ý chính xác, chỉnh sửa khi cần và nhấp Update.
Một sai lầm thường gặp là thêm 50 bảng cùng lúc. Hãy bắt đầu với 2–3 bảng cốt lõi. Điều này giúp dễ gỡ lỗi logic của tác vụ. Bạn luôn có thể mở rộng nguồn tri thức sau khi các truy vấn cốt lõi đã chính xác.
Tiếp theo, bạn cần “neo” tác vụ bằng các hướng dẫn. Thay vì chỉ viết một lời nhắc chung chung (ví dụ, "Trả lời câu hỏi về doanh số"), giao diện tác vụ dữ liệu của BigQuery cho phép bạn cung cấp bối cảnh có cấu trúc cao để định hướng AI khi tạo truy vấn. Hãy nghĩ đây là việc hướng dẫn nhập môn cho một nhà phân tích mới với từ điển dữ liệu chính xác của công ty bạn.
Sử dụng trường Instructions để cung cấp bối cảnh kinh doanh có cấu trúc. Đây là một ví dụ hoàn chỉnh, sẵn sàng dán:
Từ đồng nghĩa: Định nghĩa các thuật ngữ thay thế cho cột của bạn để tác vụ hiểu các biến thể ngôn ngữ tự nhiên. Ví dụ: "Journey", "Ride" và "Commute" đều chỉ một bản ghi trong bảng bikeshare_trips. "Dock", "Hub" hoặc "Station" chỉ một bản ghi trong bảng bikeshare_stations.
Trường chính: Nêu bật các trường quan trọng nhất cho phân tích. Điều này cho tác vụ biết nên ưu tiên cột nào khi câu hỏi của người dùng rộng. Ví dụ: Ưu tiên trip_id, start_station_name, end_station_name, subscriber_type, start_time và duration_minutes cho báo cáo tổng quan.
Trường loại trừ: Chỉ định các cột mà tác vụ dữ liệu phải tuyệt đối tránh. Điều này cực kỳ hữu ích để ẩn cột đã ngừng dùng hoặc dữ liệu không liên quan. Ví dụ: Không sử dụng cột bike_id trong bảng bikeshare_trips cho hầu hết phân tích, vì hiếm khi cần cho câu hỏi nghiệp vụ.
Lọc và nhóm: Hướng dẫn tác vụ cách phân tách dữ liệu tiêu chuẩn. Ví dụ: Trừ khi có chỉ định khác, luôn loại bỏ các chuyến đi mà duration_minutes < 1 (đây là khởi động giả hoặc chuyến thử). Mặc định nhóm dữ liệu theo start_station_name khi người dùng yêu cầu “theo trạm” hoặc “trạm hàng đầu”.
Quan hệ nối: Vì tác vụ của chúng ta lấy dữ liệu từ nhiều bảng, hãy định nghĩa rõ cách chúng kết nối. Điều này đảm bảo tác vụ không đoán sai khóa ngoại. Ví dụ: Nối bảng bikeshare_trips với bảng bikeshare_stations bằng cách khớp bikeshare_trips.start_station_id với bikeshare_stations.station_id (và tương tự cho end_station_id).
Bạn có thể kết hợp tất cả nội dung trên thành một khối gọn trong trường Instructions. Đây là phiên bản trau chuốt, sẵn sàng dán, kết hợp hướng dẫn có cấu trúc:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).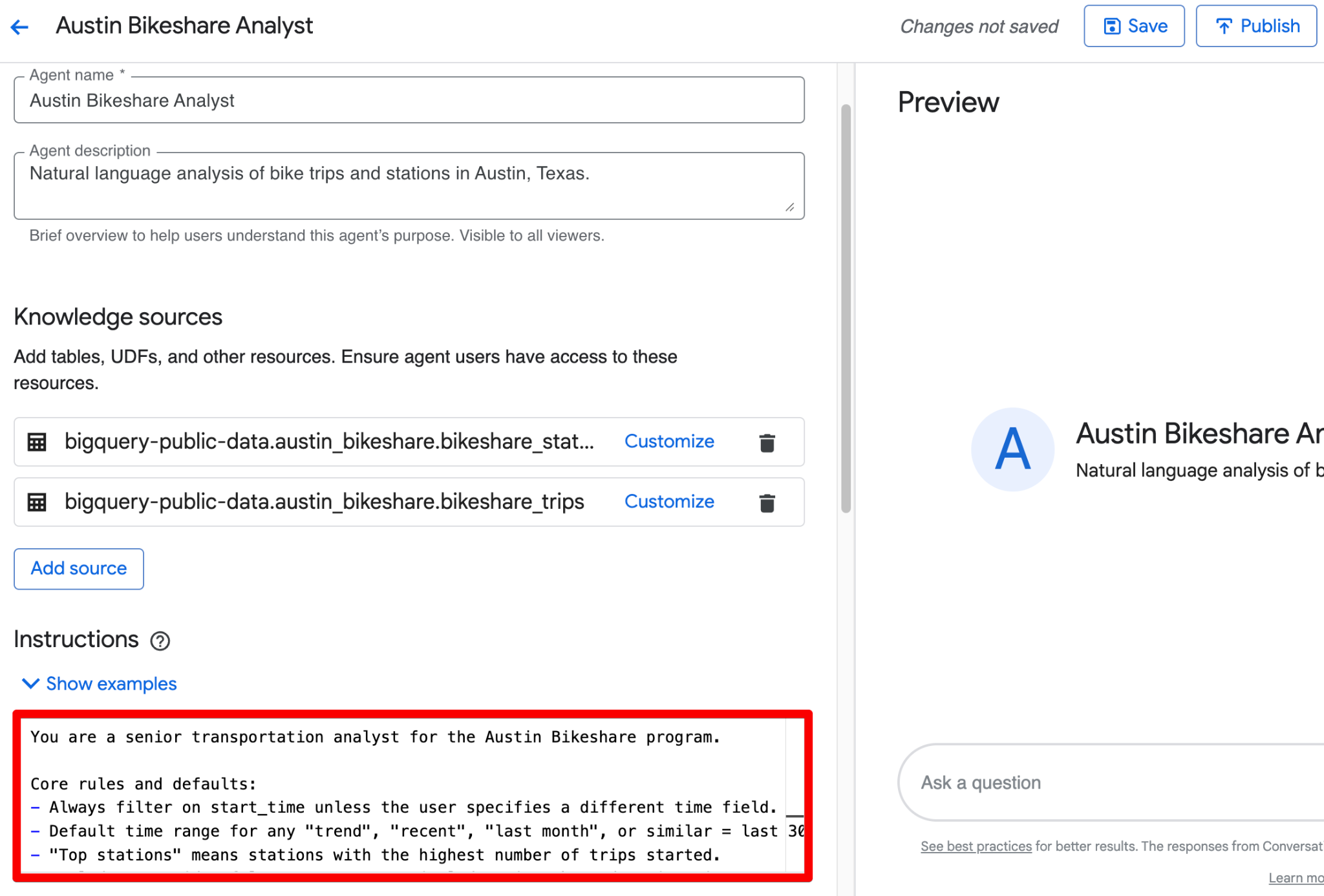
Tại sao điều này quan trọng: Nếu bạn để trống các trường này, một câu hỏi mơ hồ như "Doanh số hàng đầu của chúng ta là gì?" có thể khiến tác vụ nối sai bảng, lấy từ tài khoản không hoạt động hoặc bao gồm dữ liệu đã ngừng dùng. Bằng cách cấu trúc hướng dẫn của bạn theo năm nhóm này, bạn đảm bảo SQL được tạo ra tuân thủ chặt chẽ logic nghiệp vụ đã thiết lập.
Bên cạnh hướng dẫn, bạn có thể (và nên) định nghĩa các thuật ngữ từ điển trực tiếp trong tác vụ. Chúng giúp tác vụ diễn giải biệt ngữ doanh nghiệp, viết tắt và khái niệm suy dẫn một cách nhất quán.
Nhấp Add term trong phần Glossary (thường gần Instructions) và tạo thuật ngữ với tên, định nghĩa và từ đồng nghĩa (phân tách bằng dấu phẩy).
Dưới đây là các thuật ngữ từ điển khuyến nghị cho bộ dữ liệu Austin Bikeshare:
| Thuật ngữ | Định nghĩa | Từ đồng nghĩa |
duration_minutes |
Thời lượng chuyến đi tính bằng phút. Luôn dùng trường này cho câu trả lời và phép tính hướng tới người dùng | thời gian đi, độ dài chuyến, thời lượng, thời lượng chuyến |
ridership |
Tổng số (đếm) chuyến đi bằng xe đạp được bắt đầu | chuyến đi, lượt đi, hành trình, mức sử dụng xe đạp, số lượt đi lại |
peak_hours |
Khung giờ cao điểm buổi sáng (7–9) hoặc buổi chiều (16–19) dựa trên giờ trích xuất từ start_time |
giờ cao điểm, giờ bận rộn, giai đoạn nhu cầu cao |
subscriber_type |
Loại người đi — Subscriber (người sở hữu gói tháng hoặc năm) hoặc Customer (chuyến đi một lần | loại người dùng, loại thành viên, người giữ vé, thành viên, người đi không thường xuyên |
false_start |
Một chuyến đi rất ngắn (thường dưới 1 phút) có khả năng là chuyến thử hoặc mở khóa vô tình. Thông thường nên loại trừ khỏi phân tích | chuyến thử, chuyến không hợp lệ, chuyến ngắn |
Bạn có thể thêm nhiều thuật ngữ khác khi cần (ví dụ, cho start_station_name, end_station_name, hoặc các chỉ số suy dẫn như “thời lượng chuyến trung bình” hay “chuyến dài”).
Nhờ sử dụng từ điển thuật ngữ, nếu ban lãnh đạo quyết định thay đổi định nghĩa chính thức của “Chuyến đi dài” thành 45 phút trong quý tới, nhóm quản trị dữ liệu của bạn chỉ cần cập nhật một lần trong Dataplex. Mọi Data Agent được kết nối với từ điển đó sẽ ngay lập tức áp dụng logic mới, giúp bạn duy trì tính nhất quán trên toàn tổ chức.
Sau khi bạn đã cấu hình nguồn tri thức, hướng dẫn và thuật ngữ từ điển, đã đến lúc kiểm thử tác vụ trước khi xuất bản.
Cuộn sang bên phải màn hình tới khung Preview. Giao diện chat trực tiếp này cho phép bạn tương tác với tác vụ theo thời gian thực khi bạn xây dựng nó. Bạn có thể đặt câu hỏi, rà soát lập luận của tác vụ, kiểm tra SQL được tạo và lặp lại nhanh chóng.
Khung Preview hiển thị:
Hãy thử bốn truy vấn tăng dần độ phức tạp này (điều chỉnh phù hợp với phạm vi dữ liệu của bộ dữ liệu tới năm 2024):
Bạn sẽ thấy gì trong phản hồi của tác vụ:
Tóm tắt — Giải thích kết quả bằng ngôn ngữ tự nhiên.
Kết quả truy vấn — Bảng dữ liệu gọn gàng (ví dụ, tổng số chuyến, trạm hàng đầu hoặc thời lượng trung bình).
Thông tin chuyên sâu — Các gạch đầu dòng rút ra ý nghĩa theo bối cảnh nghiệp vụ.
SQL được tạo — Nhấp Open in Editor để xem toàn bộ truy vấn SQL do tác vụ tạo (bạn sẽ thấy nó lọc đúng theo start_time và áp dụng duration_minutes >= 1 để loại chuyến khởi động giả).
Gợi ý câu hỏi tiếp theo — Gợi ý hữu ích ở cuối (ví dụ, “Top 10 trạm khởi hành trong tháng 6/2024 là gì?”, “Dự báo số chuyến theo ngày…”).
Hình ảnh trực quan — Biểu đồ được tạo tự động (biểu đồ cột cho xếp hạng, như trong ví dụ top 5 trạm).
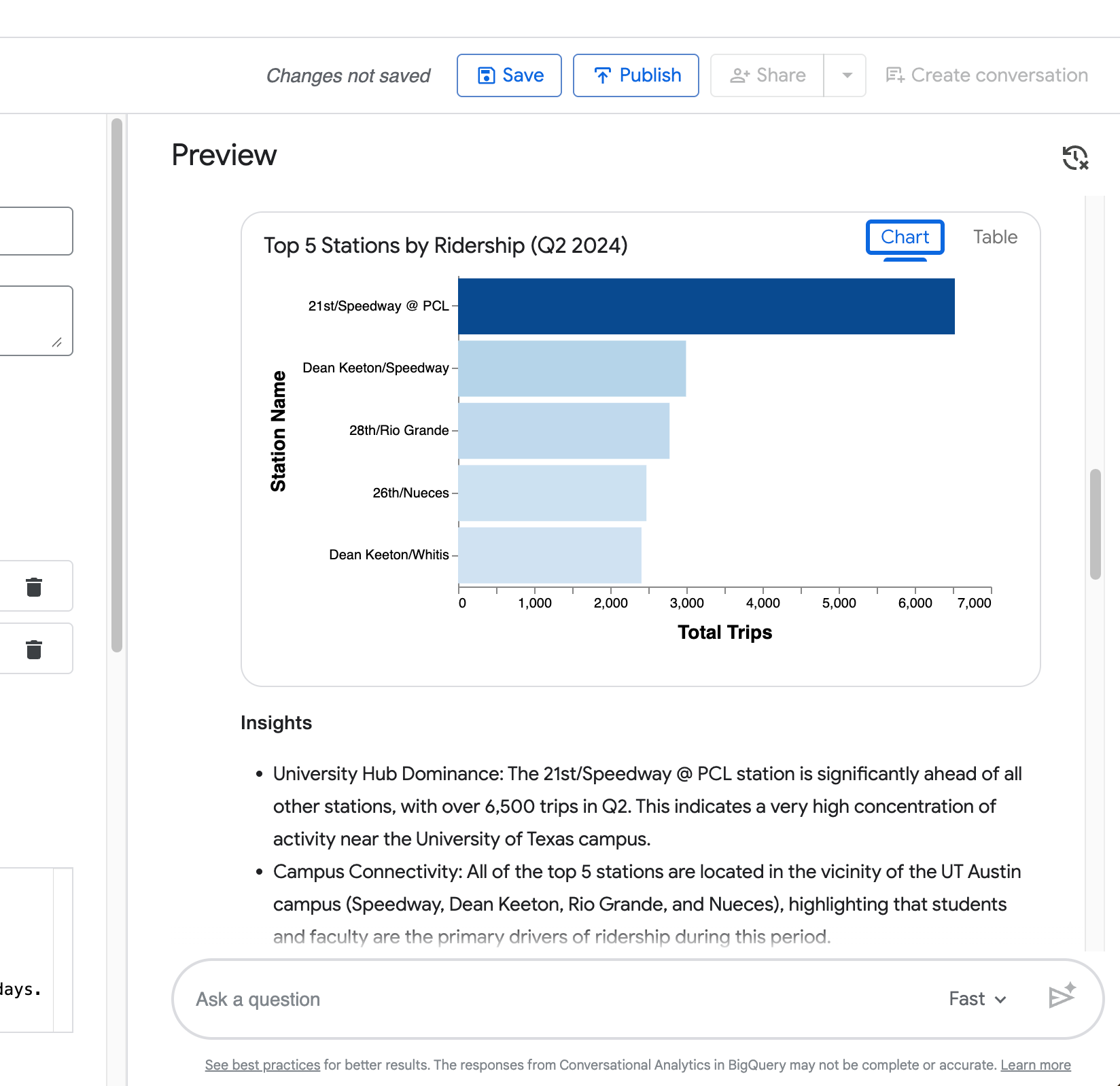
Truy vấn thứ tư của bạn (“Giờ hãy hiển thị cùng phép so sánh nhưng chỉ cho trạm Zilker Park”) thể hiện khả năng của tác vụ trong việc ghi nhớ ngữ cảnh từ câu hỏi trước.
Như bạn thấy ở ảnh chụp màn hình sau, nó thu hẹp đúng phép so sánh thời lượng ngày thường vs cuối tuần tới Zilker Park mà không cần bạn lặp lại đầy đủ yêu cầu.
Mẹo kiểm thử:
Khi tác vụ liên tục đưa ra câu trả lời rõ ràng, chính xác và có cấu trúc tốt, nhấp Save ở trên cùng, rồi Publish. Tác vụ Austin Bikeshare Analyst của bạn giờ đã sẵn sàng sử dụng!
Ngay cả với hướng dẫn và thuật ngữ từ điển tốt, tác vụ dữ liệu của bạn đôi khi vẫn có thể diễn giải sai quy tắc nghiệp vụ hoặc tạo câu trả lời không nhất quán.
Truy vấn đã xác minh giải quyết vấn đề này bằng cách cho phép bạn dạy tường minh cho tác vụ cách xử lý đúng các câu hỏi quan trọng hoặc thường gặp. Mỗi truy vấn đã xác minh gồm một câu hỏi ngôn ngữ tự nhiên ghép với SQL chính xác cần dùng.
Chúng đóng vai trò ví dụ chất lượng cao để “neo” lập luận của tác vụ và là một trong những cách hiệu quả nhất để chuyển từ tác vụ “tạm ổn” sang sẵn sàng vận hành.
Trong trình soạn thảo tác vụ, cuộn tới phần Verified Queries. Bạn có hai cách dễ dàng để thêm truy vấn đã xác minh:
Nhấp Add query. Bạn sẽ thấy màn hình Add verified query, nơi bạn có thể:
Nhấp View Gemini-generated suggestions. Màn hình “Review suggested verified queries” sẽ mở, nơi Gemini đề xuất các câu hỏi liên quan dựa trên nguồn tri thức của bạn.
Bạn có thể:
Một truy vấn đã xác minh tốt cho bộ dữ liệu Austin Bikeshare có thể là:
Câu hỏi:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;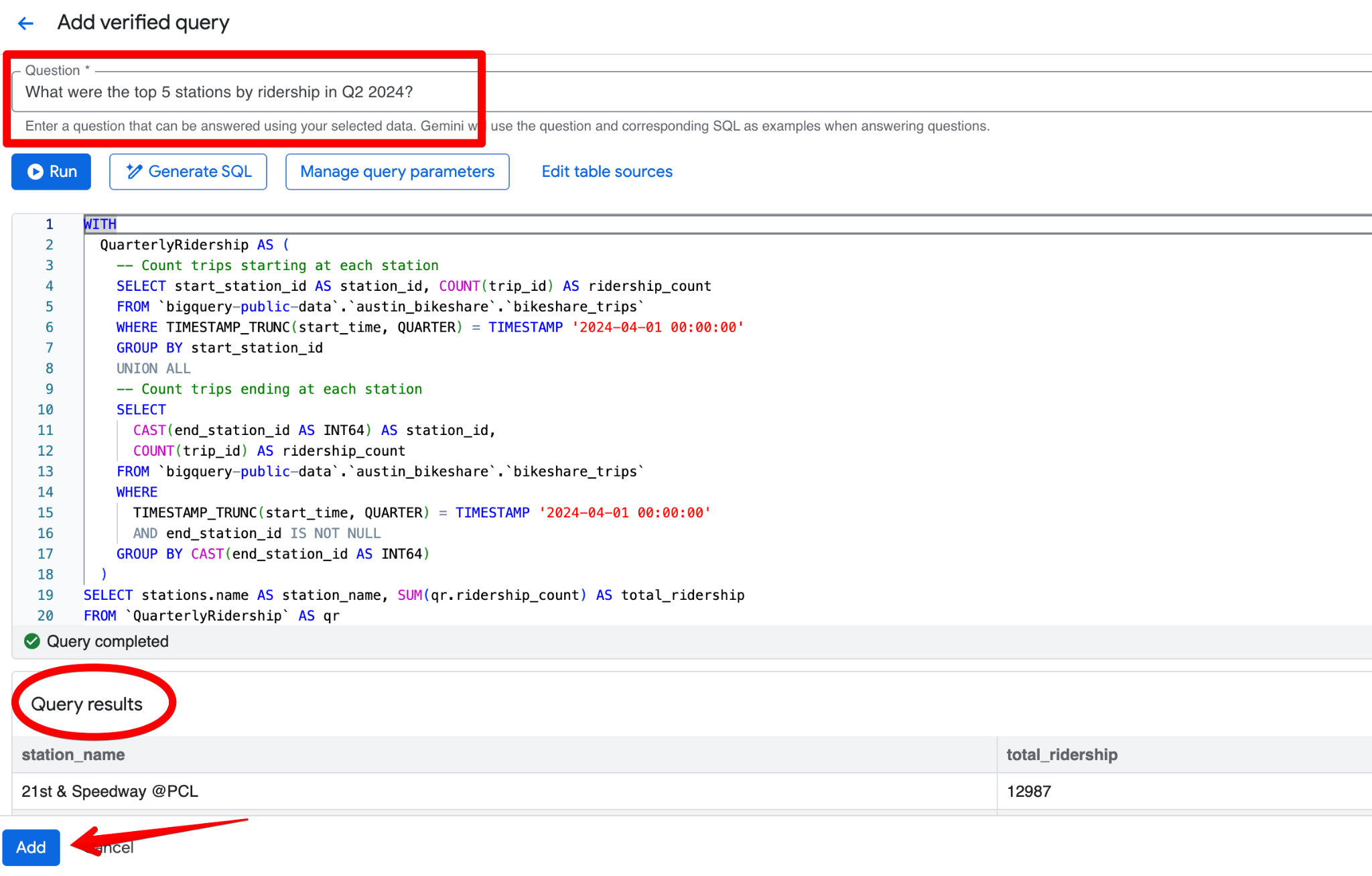
Ngay cả khi tác vụ đưa ra câu trả lời hợp lý ngay lần đầu, bạn vẫn có thể khiến nó chính xác và nhất quán hơn đáng kể bằng cách rà soát SQL được tạo và thêm truy vấn đã xác minh.
Hãy làm theo quy trình thực tế sau:
Giả sử, bạn hỏi, “Thời lượng chuyến đi trung bình trong tháng 6/2024 là bao nhiêu?” Ở phản hồi ban đầu, tác vụ trả về 26,68 phút và đúng là loại trừ chuyến dưới 1 phút. Bây giờ, giả sử quy tắc nghiệp vụ tiêu chuẩn của nhóm là loại trừ mọi chuyến dưới 5 phút.
Khi bạn mở SQL được tạo (qua Open in Editor), bạn thấy bộ lọc chỉ là duration_minutes >= 1.
Nhấp Add query trong phần Verified Queries và tạo mục sau:
Câu hỏi:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes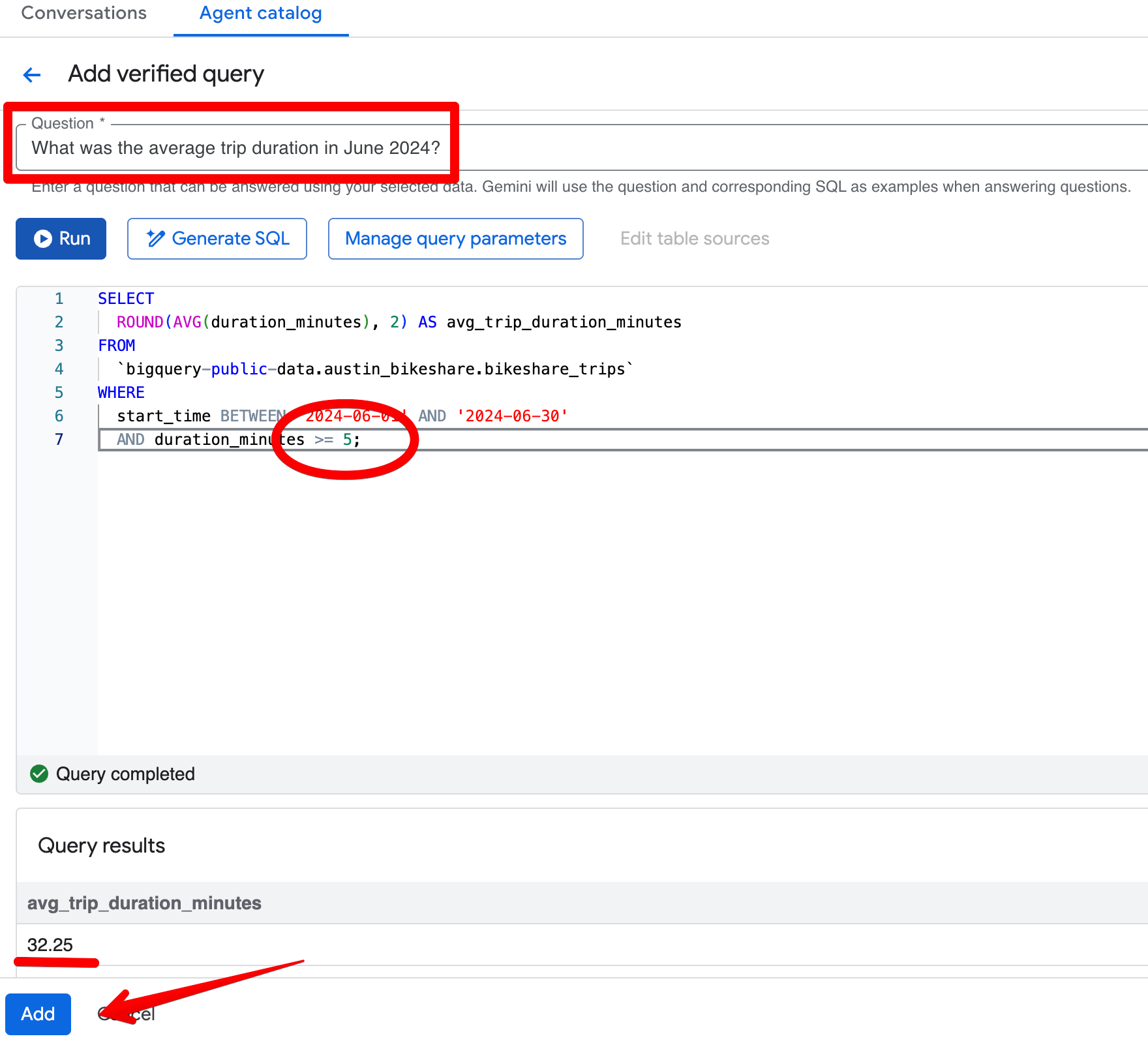
Sau khi lưu truy vấn đã xác minh, hãy hỏi lại cùng câu hỏi trong khung Preview. Giờ tác vụ liên tục trả về khoảng ~32,08 phút và áp dụng ngưỡng nghiêm ngặt 5 phút của bạn. Kết quả trở nên phù hợp hơn với quan điểm nghiệp vụ về các chuyến đi “có ý nghĩa”.
Phân tích hội thoại của BigQuery nổi bật so với các công cụ text-to-SQL đơn giản nhờ hỗ trợ nguyên bản các hàm BigQuery ML, dữ liệu phi cấu trúc và chia sẻ dễ dàng trên hệ sinh thái Google Cloud.
Một trong những điểm khác biệt lớn nhất là khả năng của tác vụ gọi trực tiếp các hàm BigQuery ML từ ngôn ngữ tự nhiên, vượt ra ngoài báo cáo hồi cứu để tiến tới thông tin chuyên sâu hướng tới tương lai.
Chẳng hạn, bạn có thể yêu cầu một tác vụ dữ liệu dự đoán số chuyến theo ngày trong 30 ngày tới dựa trên xu hướng năm 2024. Tác vụ sẽ kích hoạt AI.FORECAST và tạo dự báo cho tháng 7/2024 cùng một biểu đồ đẹp hiển thị số chuyến theo ngày trong lịch sử (đường màu xanh) và dự báo 30 ngày (đường màu cam) với khoảng tin cậy 95% được tô bóng.
Một cách hữu ích khác của các thuật toán học máy là phát hiện điều bất thường trong dữ liệu của bạn. Khi bạn, ví dụ, yêu cầu tác vụ phát hiện bất thường trong ridership theo ngày trong tháng 6/2024, nó sẽ gọi AI.DETECT_ANOMALIES, so sánh tháng 6/2024 với các tháng trước và trả về bảng chuỗi thời gian kèm biểu đồ đường.
Trong trường hợp này, không có bất thường chính thức ở mức tin cậy 95% nhưng đánh dấu ngày 19/6 là gần bất thường (xác suất 92,1%) với mức giảm rõ rệt về ridership.
Hầu hết công cụ BI hội thoại sẽ “thất bại” ngay khi dữ liệu không được tổ chức gọn gàng thành hàng và cột. Tuy nhiên, BigQuery hỗ trợ Object Tables, cho phép bạn phân tích dữ liệu phi cấu trúc (như PDF, hình ảnh và nhật ký văn bản thô) được lưu trong Google Cloud Storage.
Vì Data Agent được cung cấp sức mạnh bởi khả năng đa phương thức của Gemini, nó có thể suy luận đồng thời cả các chỉ số có cấu trúc và tệp phi cấu trúc của bạn. Đây là một điểm khác biệt lớn, độc đáo của BigQuery.
Nếu bạn có các PDF khảo sát người đi hoặc hình ảnh kiểm tra trạm trong một object table, chỉ cần hỏi, “Tóm tắt các phàn nàn chính từ các PDF khảo sát người đi quý 2/2024.” Tác vụ sẽ đọc các tệp phi cấu trúc và kết hợp thông tin với dữ liệu chuyến đi có cấu trúc của bạn
Nhóm dữ liệu của bạn xây dựng và kiểm thử Data Agents trong BigQuery Studio, nhưng người dùng cuối của bạn có thể sử dụng các ứng dụng hoàn toàn khác. Google giúp dễ dàng tách tác vụ khỏi GCP Console để bạn có thể phục vụ người dùng nghiệp vụ ngay nơi họ đang làm việc.
Nếu bạn muốn tự thử xây dựng một ứng dụng chat tùy chỉnh, bạn cũng có thể đọc thêm trong tài liệu chính thức Giới thiệu về Conversational Analytics trong BigQuery.
Nếu chỉ rút ra một nguyên tắc then chốt, thì đó là: phân tích hội thoại chuyển điểm nghẽn phân tích từ việc chờ đợi nhóm dữ liệu sang việc chỉ cần đặt đúng câu hỏi.
Sự dân chủ hóa này không có nghĩa là các nhóm dữ liệu trở nên lỗi thời, mà vai trò của họ đang thay đổi. Một tác vụ AI chỉ thông minh tương xứng với hàng rào bảo vệ bạn xây quanh nó. Độ chính xác và an toàn của các tác vụ dữ liệu của bạn hoàn toàn phụ thuộc vào hướng dẫn, bối cảnh và kiến trúc lược đồ bạn cung cấp.
Để xây dựng các tác vụ hội thoại hiệu quả nhất, bạn vẫn cần nắm vững kho dữ liệu nền tảng. Nếu bạn hoặc nhóm của bạn muốn củng cố những kỹ năng cốt lõi đó và làm chủ nền tảng cung cấp sức mạnh cho các tính năng AI này, hãy xem khóa học Introduction to BigQuery của DataCamp ngay hôm nay!
Khóa học Google Cloud
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút