
Lernpfad
Google Cloud Digital Leader
8 Std.
Wenn du in einem Datenteam arbeitest, kommt dir das sicher bekannt vor: Dein Backlog quillt über vor Ad-hoc-Anfragen. Fachbereiche brauchen ständig einfache Varianten vorhandener Reports und fragen: "Kannst du das nach Produktkategorie gruppieren?" oder "Wie sieht das im Vergleich zum Vormonat aus?" Während sie auf Antworten warten, stecken Data Engineers und Analysten in immer gleichen SQL-Aufgaben fest.
Mit Conversational Analytics in BigQuery kannst du diesen Flaschenhals endlich verlagern. Die Funktion bringt eine KI-gestützte Reasoning-Engine direkt ins BigQuery Studio. Nutzer stellen Fragen in natürlicher Sprache und erhalten sofort Daten, Diagramme und generiertes SQL.
In diesem Guide lernst du, wie du Conversational Analytics in BigQuery einrichtest und nutzt. Du baust, konfigurierst und verfeinerst eigene Data Agents, damit dein Unternehmen sicher mit seinen Daten chatten kann.
Conversational Analytics verschieben die Interaktion mit Daten von manuellen SQL-Abfragen hin zu Dialogen in natürlicher Sprache. Statt SELECT-Statements zu schreiben, chattest du mit einem Data Agent, der deinen Business-Kontext versteht und Antworten liefert, die auf deinen tatsächlichen Tabellen basieren.
Das ist weit mehr als ein einfacher Text-zu-SQL-Parser; es ist ein großer Schritt hin zu echter Datendemokratisierung.
So erhalten nicht-technische Nutzer eigenständig Echtzeit-Einblicke, und Datenprofis können Datensätze schneller erkunden und Reporting automatisieren.
Im Kern von BigQuerys Conversational Analytics steckt eine Reasoning-Engine, die von der Gemini-Modellfamilie angetrieben wird. Data Agents nutzen eine strukturierte, mehrstufige Pipeline, damit Einsichten in deinem spezifischen Datenkontext verankert sind:
Google Cloud bietet Conversational Analytics auf verschiedenen Ebenen deines Daten-Stacks. Der richtige Einstieg hängt von deinen Nutzergruppen und dem Ort deiner Business-Logik ab:
|
Funktion |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (über BigQuery Agents) |
|
Am besten geeignet für |
Datenteams, Analysten und Entwickler, die individuelle Anwendungen bauen |
Business-Nutzer, die kuratierte, dashboard-fähige Insights brauchen |
Business-Nutzer, die leichtgewichtiges BI-Reporting bevorzugen |
|
Grounding-Methode |
Direkte Warehouse-Schemas, Tabellenmetadaten und verifizierte Abfragen |
LookML (semantische Schicht) |
Direkt mit vorkonfigurierten BigQuery Data Agents verbunden |
|
Datenzugriff |
Kann strukturierte, prädiktive (ML) und unstrukturierte Daten analysieren |
Strikt strukturierte, modellierte Daten |
Strukturierte Daten |
|
Release-Status |
Preview (Stand Mai 2026) |
Allgemein verfügbar |
Preview |
Welchen Weg solltest du wählen?
Dieses Tutorial konzentriert sich auf BigQuery als schnellsten Weg für Datenteams, Agents dort zu prototypisieren und zu produktivieren, wo die Daten liegen.
Bevor du startest, ist es wichtig, die Architektur eines Data Agents zu verstehen. In der Google-Cloud-Umgebung ist ein Data Agent die zentrale Abstraktionsschicht. Er kombiniert BigQuery-Assets mit den Reasoning-Fähigkeiten der Gemini-Modelle.
Statt rohe Tabellen direkt freizugeben, konfiguriert ein Data Agent alles, was das Modell braucht, um Fragen zu interpretieren, sicheres SQL zu generieren und verlässliche Antworten zu liefern. Diese Kombination aus Datenquellen, Anweisungen und verifizierter Logik macht BigQuerys Conversational Analytics robuster als Standard-Text-zu-SQL-Tools.
Wissensquellen sind die Grundlage jedes Data Agents. Sie definieren exakt, auf welche Daten der Agent zugreifen und welche er abfragen darf.
Asset-Typen: Tables, Views und User Defined Functions (UDFs) können als Wissensquellen verbunden werden.
Skalierbarkeit: Mehrere Wissensquellen können mit einem einzigen Agent verknüpft werden. So kann der Agent Informationen aus verschiedenen Geschäftsbereichen kombinieren.
Zugriffskontrolle: Durch das Festlegen konkreter Wissensquellen stellst du sicher, dass der Agent nur innerhalb autorisierter Daten arbeitet.
Die Intelligenz eines Agents hängt vom bereitgestellten Kontext ab. Das ist der Schlüssel, damit ein generisches Modell die Sprache eines Unternehmens versteht.
Durch benutzerdefinierte Anweisungen, Synonyme und Business-Glossare wird der Agent in einer Domäne verankert. So kannst du ihm z. B. beibringen, dass "Top Customers" Nutzer mit einem Lifetime Value (LTV) über 1.000 $ sind.
Wichtige Grounding-Elemente:
Custom Instructions: Gib übergeordnete Leitlinien vor, etwa "Schließe interne Testkonten in Umsatzreports immer aus".
Business-Glossare: Übersetze technische Felder in Alltagssprache, z. B. store_id zu "Filiale".
Feld-Metadaten: Beschreibungen, die dem Agent die Feinheiten einzelner Variablen erklären, z. B. "Bruttoumsatz" versus "Nettogewinn".
Je besser deine Anweisungen und Metadaten, desto höher die Genauigkeit des Agents.
Verifizierte Abfragen (früher Golden Queries) sind vordefinierte Frage-Antwort-Paare, die als Referenz dienen. Durch das Mapping spezifischer Fragen auf fachlich geprüfte SQLs nutzt der Agent die richtigen Join-Pfade und Filter für kritische KPIs.
Diese Abfragen können BigQuery ML (BQML)-Funktionen enthalten. So kann der Agent fortgeschrittene Anforderungen erfüllen, etwa Churn-Prognosen oder Absatzvorhersagen – mit exakt den Modellparametern der Data Scientists. Nach der Verifizierung werden diese Assets über den Dataplex Universal Catalog verwaltet, was Organisationseinheitlichkeit sicherstellt.
Jetzt, da du die Bausteine kennst, lass uns deinen ersten Data Agent bauen und konfigurieren.
Stelle für dieses Tutorial sicher, dass du Folgendes mitbringst:
Bevor du deinen ersten Agent erstellst, musst du dein Google-Cloud-Projekt konfigurieren und sicherstellen, dass dein Nutzerkonto die nötigen Berechtigungen hat. Data Agents arbeiten als Schicht über deinen vorhandenen Daten. Korrektes IAM (Identity and Access Management) ist für Sicherheit und Funktionalität entscheidend.
Geh so vor:
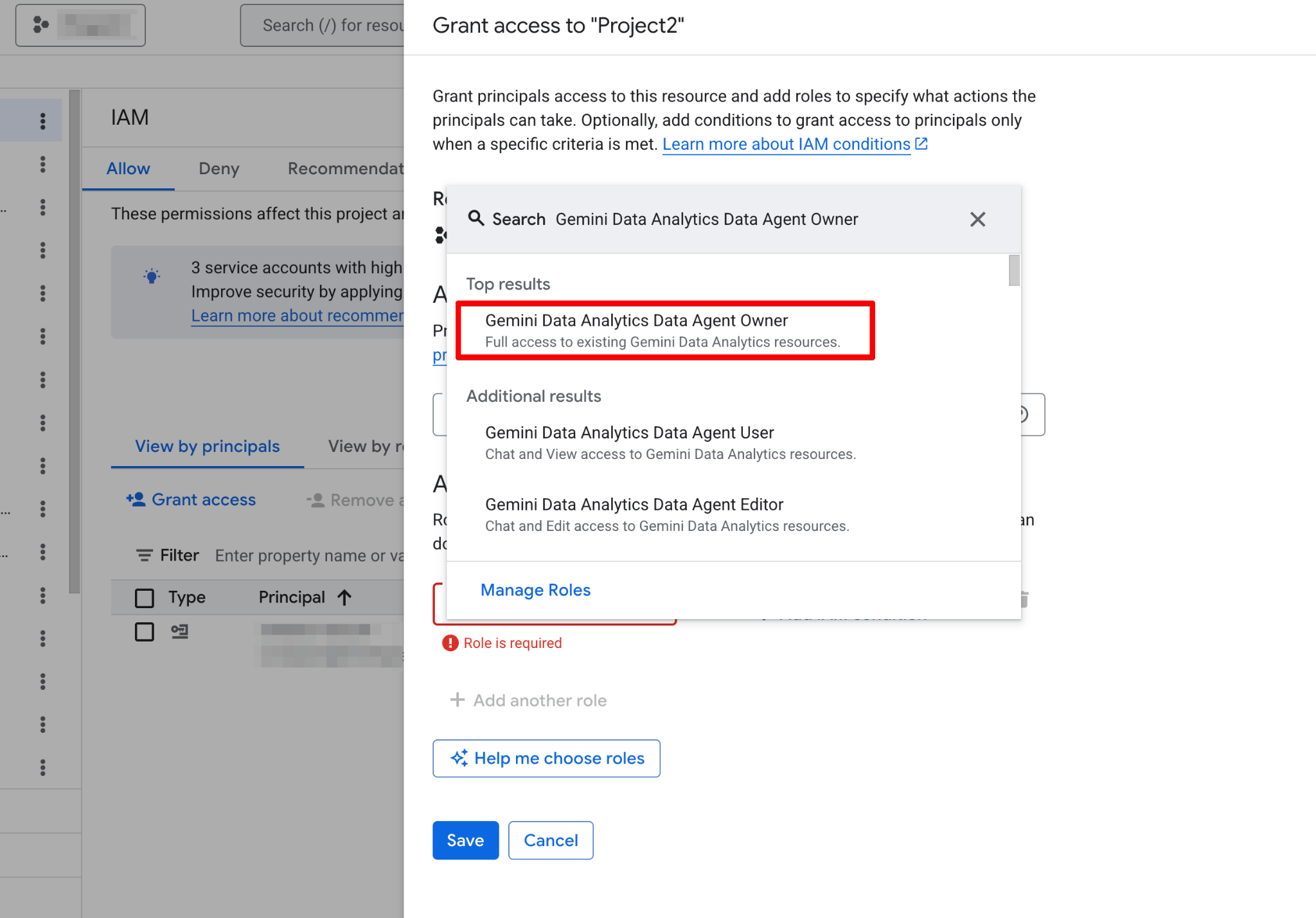
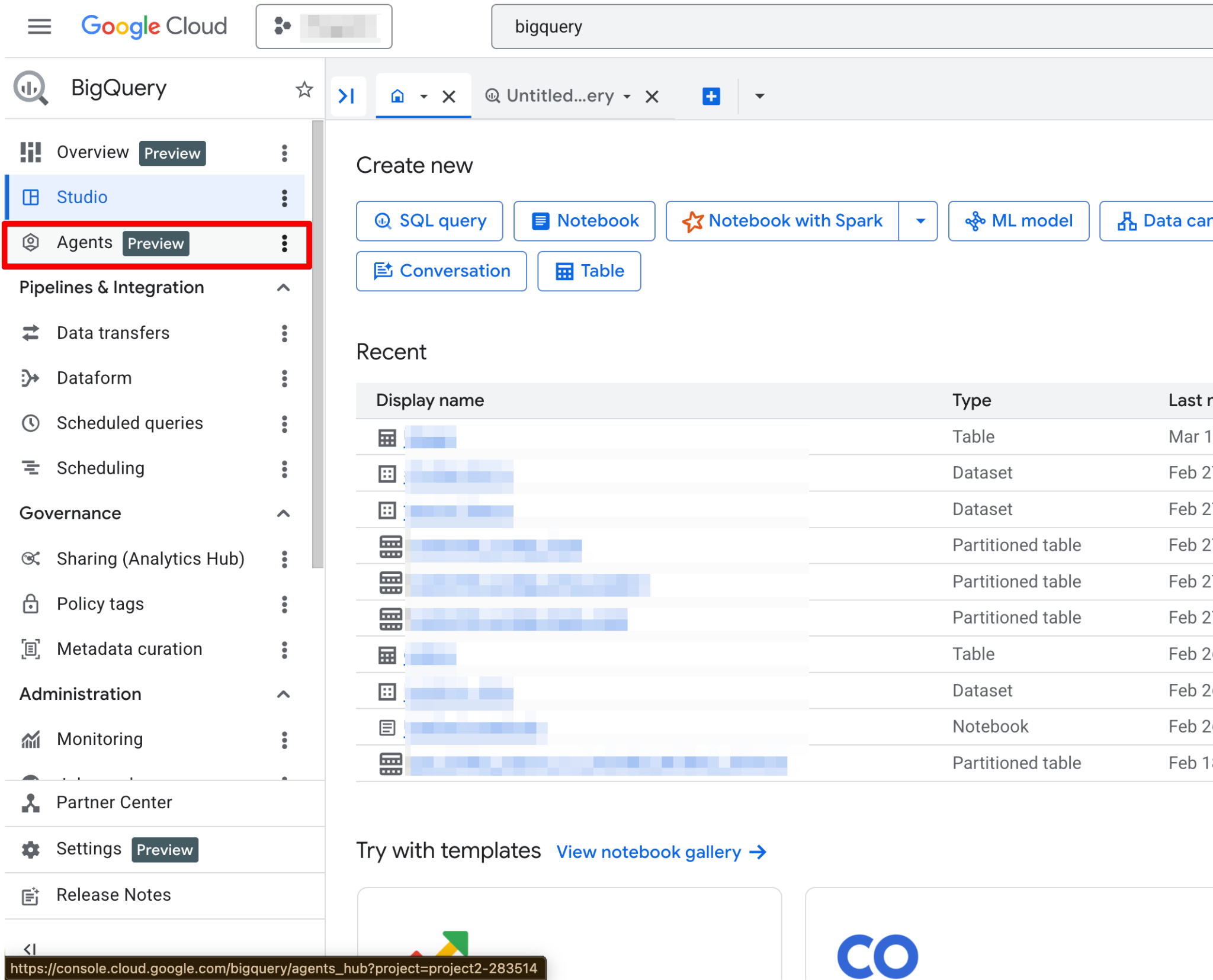
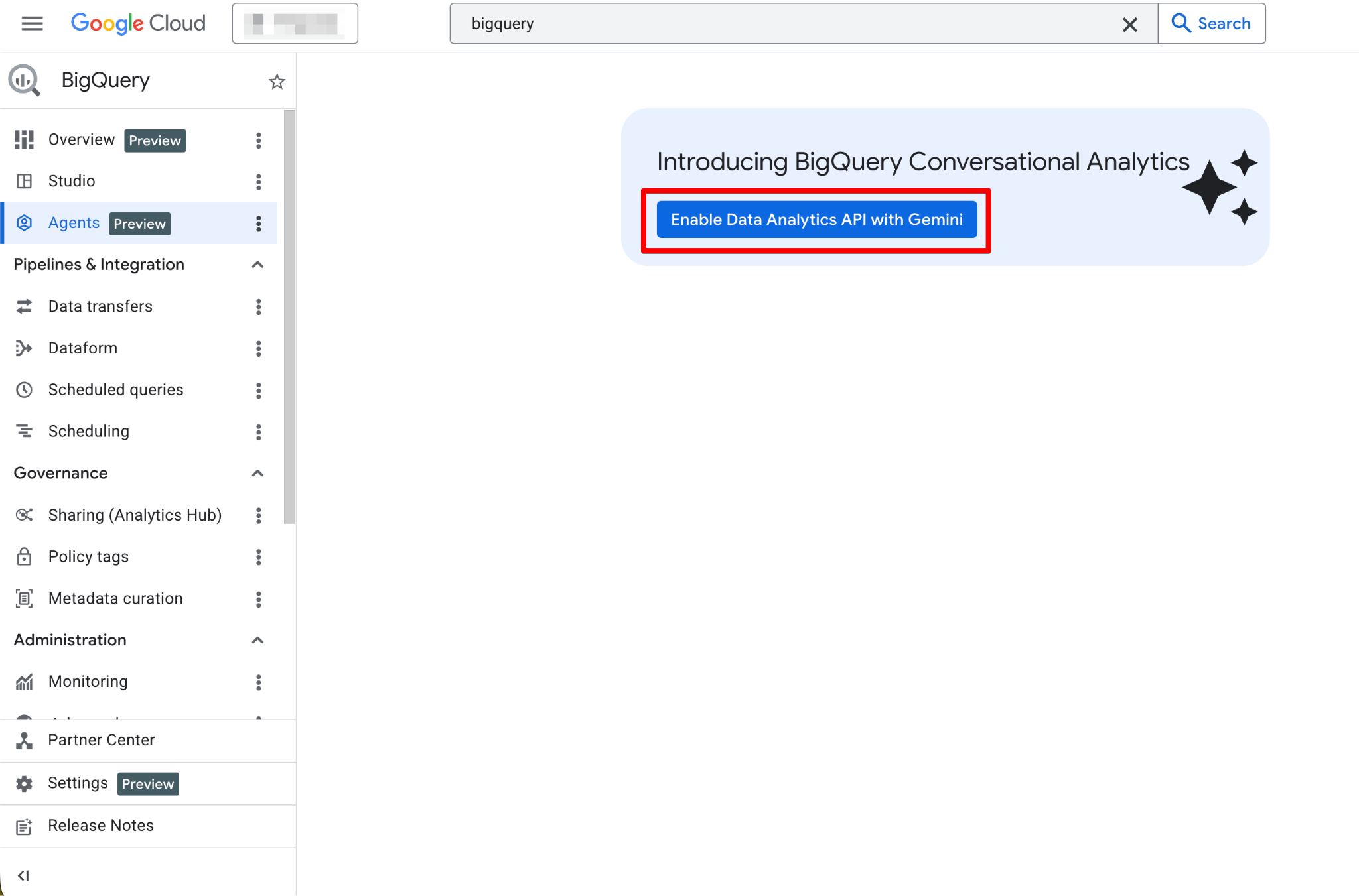
Nach der Aktivierung ist die Agents-Seite voll funktionsfähig. Du solltest nun die neue Agent-Seite sehen:
Der Agent Catalog dient zum Erstellen, Verwalten und Versionieren von Data Agents im BigQuery Studio.
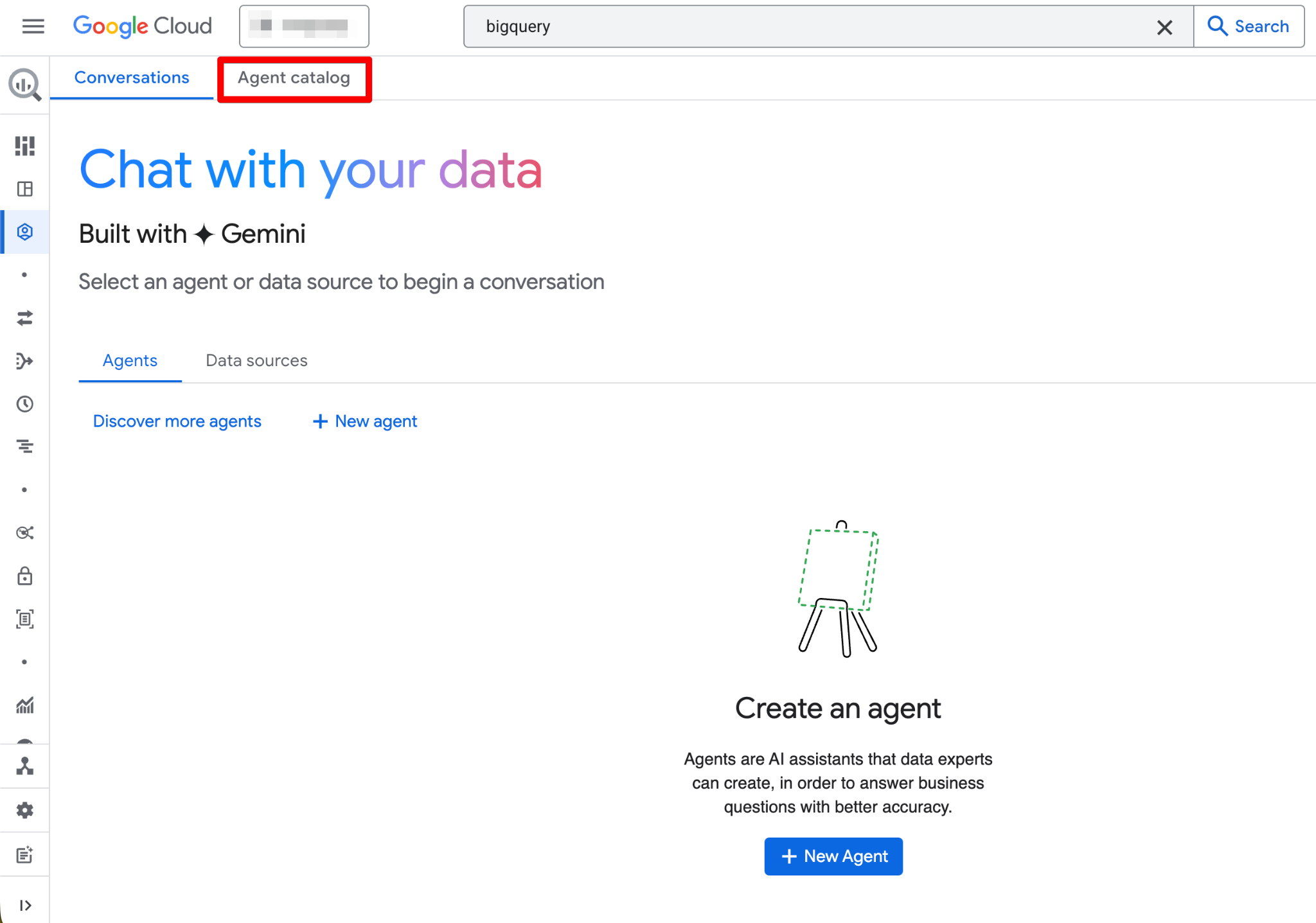
Das findest du im Agent Catalog:
Der Agent-Lebenszyklus folgt dieser Struktur (Draft → Created → Published):
Klicke auf eine Agent-Karte, um sie zu öffnen, Details anzusehen, ein Gespräch zu starten oder zu bearbeiten (wenn du Owner-Rechte hast). Die Oberfläche enthält außerdem einen Conversations-Tab, in dem du vergangene Chats mit Agents oder Datenquellen verwaltest.
Jetzt, wo die Basis steht, bauen wir einen Data Agent von Grund auf. Wir nutzen das Dataset bigquery-public-data.austin_bikeshare, um Rohdaten zu Fahrten in eine dialogfähige Oberfläche zu verwandeln. Wir verwenden zwei Tabellen:
bikeshare_trips — detaillierte Fahrdaten auf Trip-Ebene
bikeshare_stations — Stationsmetadaten
Agent-Erstellung starten
Diese beiden Felder helfen dir später bei der schnellen Identifikation. Danach konfigurierst du die drei Kernbausteine, die wir oben besprochen haben: Wissensquellen, Anweisungen und (später) verifizierte Abfragen.
Wissensquellen legen fest, auf welche Daten der Agent zugreifen darf. Je weniger und fokussierter, desto genauer und günstiger. Klicke im Bereich Knowledge sources auf Add source. Suche nach austin_bikeshare und wähle bikeshare_trips und bikeshare_stations als Quellen aus.
Klicke für jede hinzugefügte Tabelle auf Customize.
Gemini generiert automatisch eine Beschreibung und schlägt Spaltenmetadaten vor. Prüfe alles, übernehme korrekte Vorschläge, nimm Anpassungen vor und klicke auf Update.
Ein häufiger Fehler ist, auf einmal 50 Tabellen hinzuzufügen. Starte mit 2–3 Kerntabellen. So lässt sich die Logik des Agents leichter debuggen. Du kannst die Wissensbasis später jederzeit erweitern, sobald die Kernabfragen sitzen.
Als Nächstes verankerst du deinen Agent mit Anweisungen. Statt nur eine generische Prompt-Notiz zu schreiben (z. B. "Beantworte Fragen zu Sales"), erlaubt dir die Oberfläche des Data Agents in BigQuery, hochstrukturierte Kontexte zu hinterlegen, die die SQL-Generierung der KI leiten. Denk daran wie an das Onboarding eines neuen Analysten mit eurem genauen Data Dictionary.
Nutze das Feld Instructions für strukturierten Business-Kontext. Hier ist ein vollständiges, einsatzbereites Beispiel zum Einfügen:
Synonyme: Lege Alternativbegriffe für Spalten fest, damit der Agent natürlichsprachliche Varianten versteht. Beispiel: "Journey", "Ride" und "Commute" beziehen sich auf einen Datensatz in der Tabelle bikeshare_trips. "Dock", "Hub" oder "Station" bezieht sich auf einen Datensatz in bikeshare_stations.
Schlüsselfelder: Hebe die wichtigsten Felder für Analysen hervor. Das sagt dem Agent, welche Spalten bei allgemeinen Fragen Priorität haben. Beispiel: Priorisiere trip_id, start_station_name, end_station_name, subscriber_type, start_time und duration_minutes für Standardreports.
Ausgeschlossene Felder: Gib Spalten an, die der Data Agent strikt meiden soll. Ideal, um veraltete Spalten oder irrelevante Daten auszublenden. Beispiel: Nutze die Spalte bike_id in bikeshare_trips in der Regel nicht, da sie für Business-Fragen selten nötig ist.
Filter und Gruppierungen: Weisen den Agent an, Daten auf Standard-Weisen zu schneiden. Beispiel: Sofern nicht anders angegeben, schließe Fahrten mit duration_minutes < 1 immer aus (Fehlstarts oder Testrunden). Standardmäßig nach start_station_name gruppieren, wenn Nutzer nach „nach Station“ oder „Top-Stationen“ fragen.
Join-Beziehungen: Da unser Agent mehrere Tabellen nutzt, definiere die Verknüpfungen explizit. So rät der Agent nicht an falschen Fremdschlüsseln herum. Beispiel: Verbinde bikeshare_trips mit bikeshare_stations über bikeshare_trips.start_station_id = bikeshare_stations.station_id (analog für end_station_id).
Du kannst alles oben zu einem kompakten Block im Feld Instructions zusammenführen. Hier ist eine polierte, sofort einsetzbare Version mit strukturierter Guidance:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).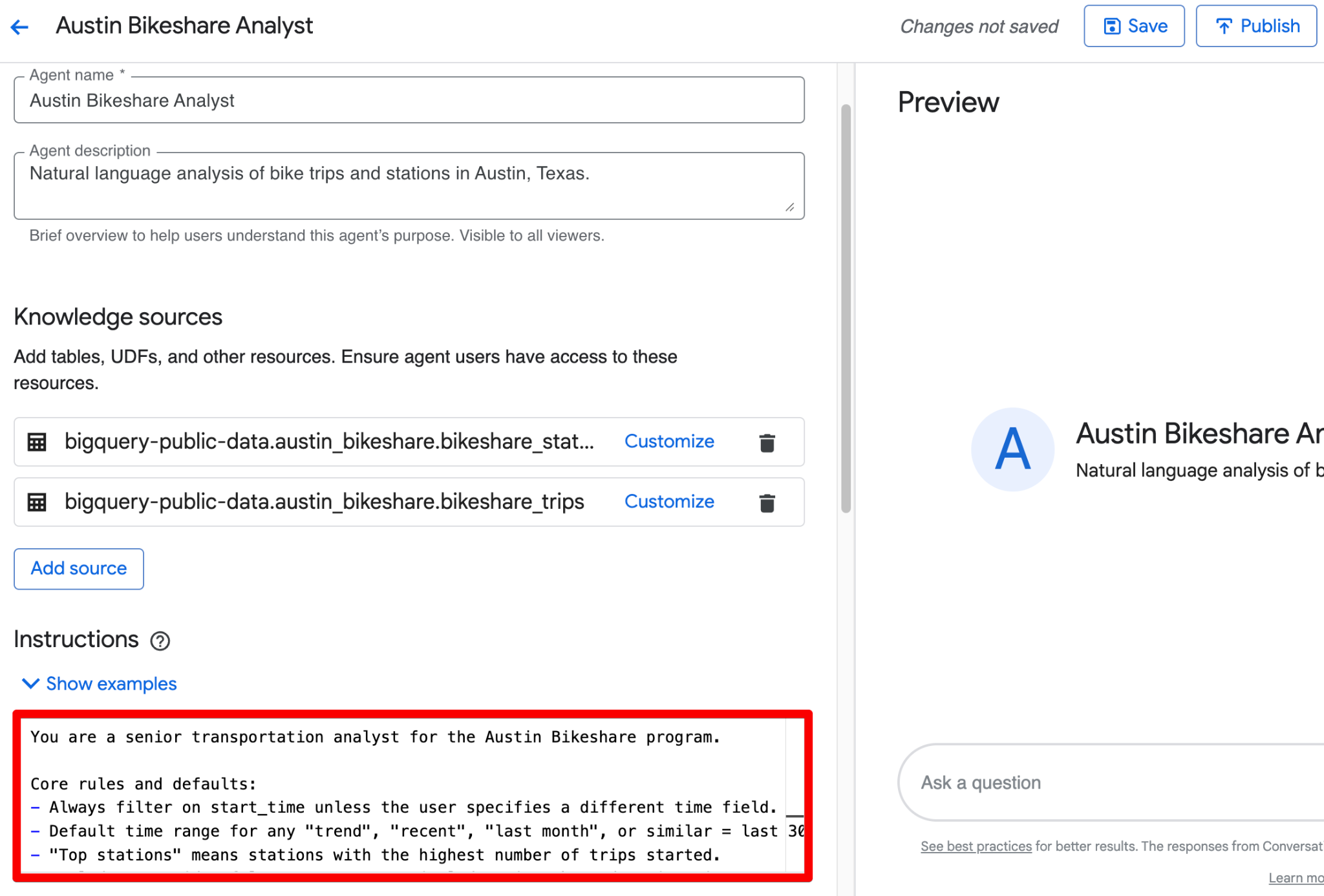
Warum das wichtig ist: Wenn du diese Felder leer lässt, kann eine vage Frage wie "Was waren unsere Top Sales?" dazu führen, dass der Agent falsche Tabellen joint, inaktive Konten berücksichtigt oder veraltete Daten einbezieht. Mit klar strukturierten Anweisungen in diesen fünf Kategorien stellst du sicher, dass generiertes SQL deiner etablierten Business-Logik strikt folgt.
Zusätzlich zu Anweisungen kannst (und solltest) du im Agent direkt Glossarbegriffe definieren. Sie helfen, Fachjargon, Abkürzungen und abgeleitete Konzepte konsistent zu interpretieren.
Klicke Add term im Bereich Glossary (meist in der Nähe der Instructions) und lege Begriffe mit Term, Definition und Synonymen (kommasepariert) an.
Empfohlene Glossarbegriffe für das Austin-Bikeshare-Dataset:
| Term | Definition | Synonyms |
duration_minutes |
Reisedauer in Minuten. Immer für nutzerseitige Antworten und Berechnungen verwenden | Fahrzeit, Trip-Länge, Dauer, Fahrtdauer |
ridership |
Gesamtanzahl (Count) gestarteter Fahrradtouren | Trips, Fahrten, Journeys, Fahrradnutzung, Pendleranzahl |
peak_hours |
Morgendliche (7–9) oder abendliche (16–19) Spitzenzeiten basierend auf der Stunde aus start_time |
Rushhour, Stoßzeiten, Hochlastzeiten |
subscriber_type |
Fahrtyp — Subscriber (Monats- oder Jahresabo) oder Customer (Einzelfahrt) | Nutzertyp, Mitgliedschaftstyp, Passinhaber, Mitglied, Gelegenheitsfahrer |
false_start |
Eine sehr kurze Fahrt (meist unter 1 Minute), wahrscheinlich Testrunde oder versehentliches Entsperren. Sollte normalerweise von Analysen ausgeschlossen werden | Testrunde, ungültige Fahrt, Kurzfahrt |
Du kannst bei Bedarf weitere Begriffe hinzufügen (z. B. für start_station_name, end_station_name oder abgeleitete Metriken wie „durchschnittliche Fahrtdauer“ oder „lange Fahrt“).
Mit Glossaren gilt: Wenn das Leadership die offizielle Definition von „Long Ride“ im nächsten Quartal auf 45 Minuten ändert, muss dein Data-Governance-Team es nur einmal in Dataplex aktualisieren. Jeder Data Agent, der an dieses Glossar angebunden ist, übernimmt die neue Logik sofort – konsistent in der ganzen Organisation.
Sobald Wissensquellen, Anweisungen und Glossar stehen, ist es Zeit, deinen Agent vor der Veröffentlichung zu testen.
Scrolle rechts zur Preview. In dieser Live-Chat-Oberfläche interagierst du in Echtzeit mit deinem Agent, während du ihn baust. Du kannst Fragen stellen, die Begründung sehen, das generierte SQL prüfen und schnell iterieren.
Die Preview zeigt:
Probiere diese vier Abfragen mit steigender Komplexität (an den Datenbereich bis 2024 angepasst):
Das siehst du in der Antwort des Agents:
Zusammenfassung — Eine natürlichsprachliche Erklärung der Ergebnisse.
Abfrageergebnis — Eine übersichtliche Tabelle mit den Daten (z. B. Gesamtfahrten, Top-Stationen oder Durchschnittsdauer).
Insights — Stichpunkte, die die Ergebnisse im Business-Kontext einordnen.
Generiertes SQL — Klicke auf Open in Editor, um die vollständige vom Agent erstellte SQL-Abfrage zu sehen (mit Filter auf start_time und duration_minutes >= 1 zum Ausschluss von Fehlstarts).
Vorgeschlagene Rückfragen — Hilfreiche Prompts unten (z. B. „Was waren die Top 10 Startstationen im Juni 2024?“, „Prognostiziere die tägliche Anzahl an Fahrten…“ usw.).
Visualisierung — Ein automatisch generiertes Diagramm (Balken für Rankings, wie im Top-5-Stationen-Beispiel).
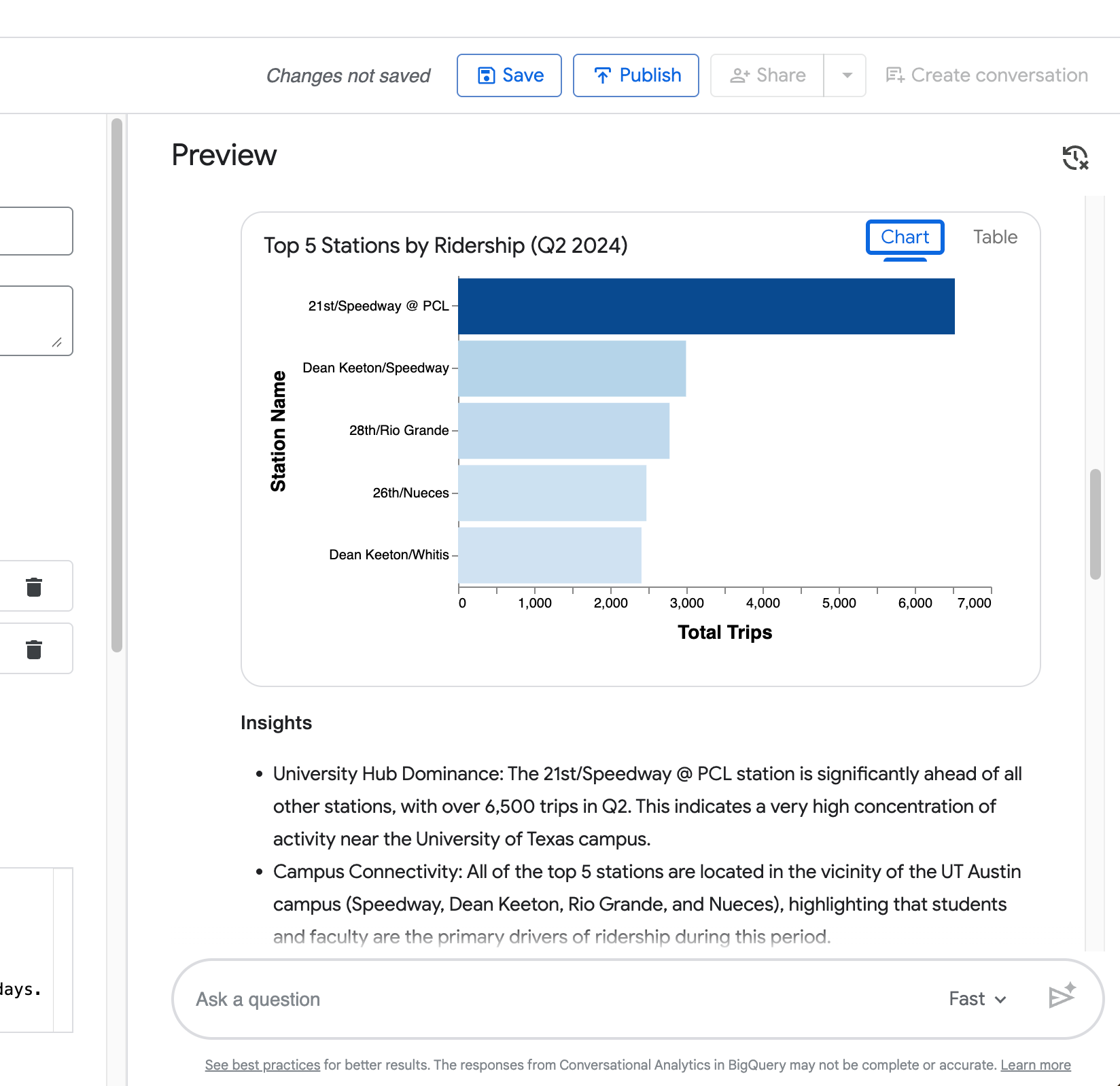
Deine vierte Abfrage („Zeig nun den gleichen Vergleich, aber nur für die Station Zilker Park“) demonstriert die Fähigkeit des Agents, Kontext aus der vorherigen Frage zu behalten.
Wie der folgende Screenshot zeigt, grenzt er den Vergleich Wochentage vs. Wochenende korrekt auf Zilker Park ein, ohne dass du die gesamte Anfrage wiederholen musst.
Testtipps:
Gibt der Agent konsistent klare, genaue und gut strukturierte Antworten, klicke oben auf Save und dann auf Publish. Dein Austin Bikeshare Analyst Agent ist jetzt einsatzbereit!
Auch mit guten Anweisungen und Glossarbegriffen kann dein Data Agent Geschäftsregeln gelegentlich falsch interpretieren oder inkonsistente Antworten erzeugen.
Verifizierte Abfragen lösen das Problem, indem du dem Agent explizit den korrekten Umgang mit wichtigen oder häufigen Fragen beibringst. Jede verifizierte Abfrage besteht aus einer natürlichsprachlichen Frage plus dem exakten SQL, das genutzt werden soll.
Sie dienen als hochwertige Beispiele, die das Reasoning des Agents verankern, und sind einer der wirksamsten Hebel auf dem Weg vom „geht so“ zum produktionsreifen Agent.
Scrolle im Agent-Editor zum Bereich Verified Queries. Du hast zwei einfache Wege, verifizierte Abfragen hinzuzufügen:
Klicke auf Add query. Es erscheint der Screen Add verified query. Dort kannst du:
Klicke auf View Gemini-generated suggestions. Es öffnet sich „Review suggested verified queries“, wo Gemini passende Fragen basierend auf deinen Wissensquellen vorschlägt.
Du kannst:
Eine gute verifizierte Abfrage für das Austin-Bikeshare-Dataset könnte sein:
Question:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;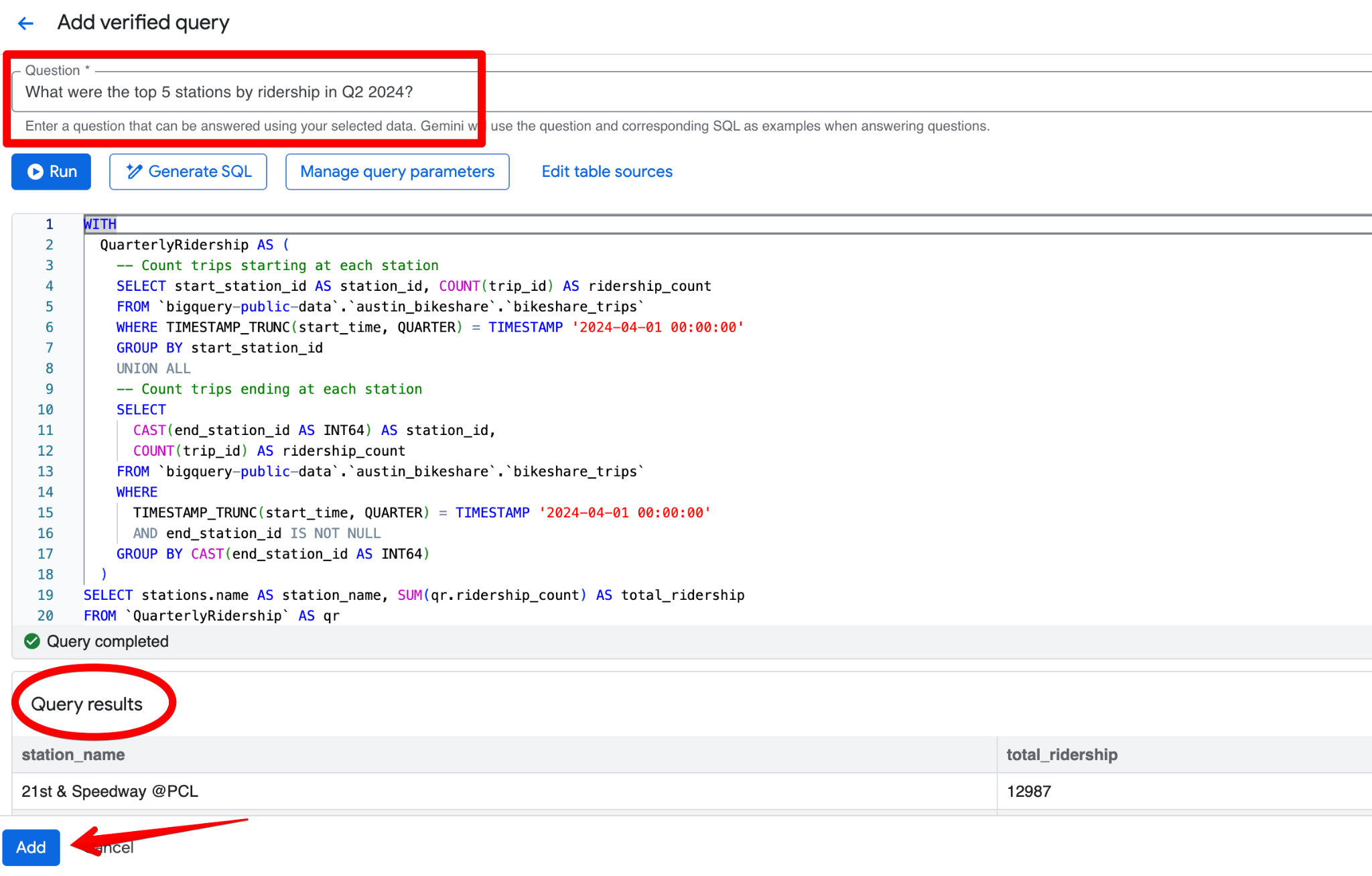
Selbst wenn der Agent beim ersten Versuch eine brauchbare Antwort liefert, kannst du ihn deutlich genauer und konsistenter machen, indem du das generierte SQL prüfst und verifizierte Abfragen hinzufügst.
Bewährter Workflow:
Angenommen, du fragst: „Wie lang war die durchschnittliche Fahrtdauer im Juni 2024?“ In der ersten Antwort liefert der Agent 26,68 Minuten und schließt Fahrten unter 1 Minute korrekt aus. Nun gilt in deinem Team aber die Regel, Fahrten unter 5 Minuten auszuschließen.
Öffnest du das generierte SQL (über Open in Editor), siehst du, dass nur duration_minutes >= 1 gefiltert wird.
Klicke bei Verified Queries auf Add query und erstelle diesen Eintrag:
Question:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes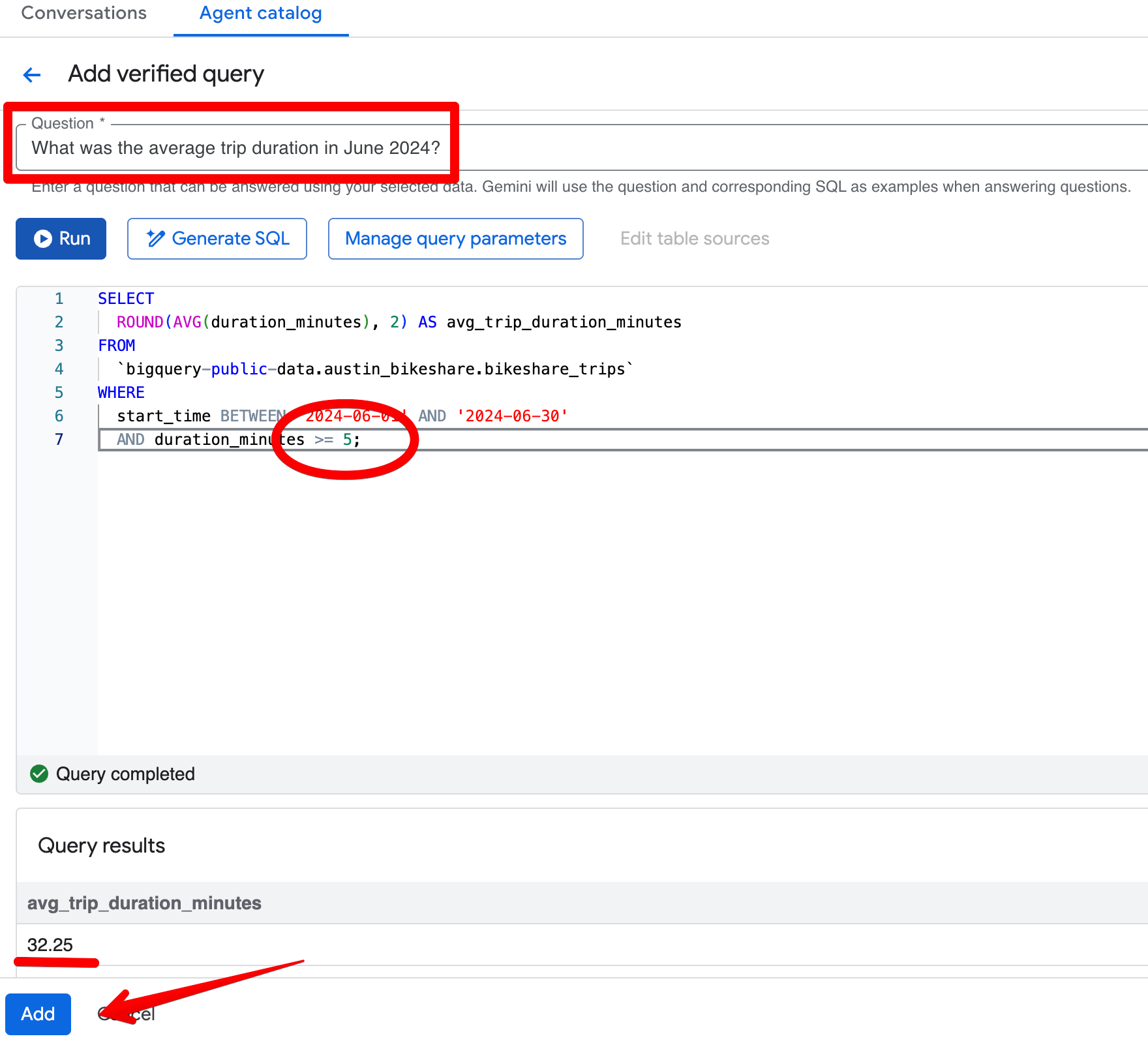
Nachdem du die verifizierte Abfrage gespeichert hast, stelle dieselbe Frage erneut in der Preview. Der Agent liefert nun konsistent ~32,08 Minuten und wendet deine strengere 5-Minuten-Schwelle an. Die Ergebnisse entsprechen damit stärker eurer Definition „aussagekräftiger“ Fahrten.
BigQuerys Conversational Analytics hebt sich von einfachen Text-zu-SQL-Tools ab: native Unterstützung für BigQuery-ML-Funktionen, unstrukturierte Daten und einfaches Teilen im Google-Cloud-Ökosystem.
Ein großer Unterschied ist die Fähigkeit des Agents, BigQuery-ML-Funktionen direkt aus natürlicher Sprache aufzurufen, um von rückblickendem Reporting zu vorausschauenden Insights zu kommen.
Du kannst den Data Agent beispielsweise bitten, die tägliche Anzahl an Fahrten für die nächsten 30 Tage auf Basis der Trends aus 2024 zu prognostizieren. Er löst dann AI.FORECAST aus und erzeugt eine Prognose für Juli 2024 inklusive Diagramm mit historischen Tageswerten (blaue Linie) und 30-Tage-Prognose (orange) samt schattiertem 95%-Konfidenzintervall.
ML-Algorithmen helfen auch, Auffälligkeiten in deinen Daten zu erkennen. Wenn du z. B. den Agent bittest, Anomalien in der täglichen Ridership im Juni 2024 zu finden, ruft er AI.DETECT_ANOMALIES auf, vergleicht Juni 2024 mit den Vormonaten und liefert eine Zeitreihe plus Liniendiagramm.
In diesem Fall wurden keine formalen Anomalien auf 95%-Konfidenzniveau markiert, aber der 19. Juni als Beinahe-Anomalie (92,1% Wahrscheinlichkeit) mit spürbarem Rückgang der Fahrten hervorgehoben.
Die meisten conversational BI-Tools geraten ins Stocken, sobald Daten nicht sauber in Zeilen und Spalten organisiert sind. BigQuery unterstützt jedoch Object Tables, mit denen du unstrukturierte Daten (z. B. PDFs, Bilder, Rohtext-Logs) aus Google Cloud Storage analysieren kannst.
Da der Data Agent von Geminis multimodalen Fähigkeiten angetrieben wird, kann er gleichzeitig über strukturierte Metriken und unstrukturierte Dateien schlussfolgern. Das ist ein enormer, einzigartiger Vorteil von BigQuery.
Wenn du Umfrage-PDFs der Fahrer:innen oder Stationsinspektionsbilder in einer Object Table hast, frage einfach: „Fasse die Hauptbeschwerden aus den Rider-Survey-PDFs von Q2 2024 zusammen.“ Der Agent liest die unstrukturierten Dateien und kombiniert die Informationen mit deinen strukturierten Fahrtdaten
Dein Datenteam baut und testet Data Agents im BigQuery Studio, aber deine Endnutzer arbeiten meist in anderen Anwendungen. Google macht es leicht, den Agent vom GCP-Console-Kontext zu entkoppeln, damit du Fachbereichen dort begegnest, wo sie arbeiten.
Wenn du selbst eine individuelle Chat-Anwendung bauen willst, kannst du auch mehr im offiziellen Introduction to Conversational Analytics in BigQuery nachlesen.
Wenn du eines mitnehmen solltest, dann das: Conversational Analytics verlagern den Analyse-Flaschenhals vom Warten auf das Datenteam hin zum Stellen der richtigen Frage.
Das bedeutet nicht, dass Datenteams überflüssig werden — ihre Rolle verändert sich. Ein KI-Agent ist nur so gut wie die Leitplanken, die du ihm gibst. Genauigkeit und Sicherheit deiner Data Agents hängen vollständig von den Anweisungen, dem Kontext und der Schema-Architektur ab, die du bereitstellst.
Um die wirkungsvollsten Conversational Agents zu bauen, brauchst du weiterhin ein tiefes Verständnis für dein Data Warehouse. Wenn du oder dein Team diese Kernkompetenzen ausbauen und die Plattform hinter diesen KI-Funktionen meistern wollt, sieh dir den Kurs Introduction to BigQuery von DataCamp an!
Google Cloud Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
