Track
Google Cloud Digital Leader
8 godz.
Jeśli pracuje Pan/Pani w zespole ds. danych, ten scenariusz zapewne brzmi znajomo: lista zadań pęka w szwach od doraźnych próśb. Użytkownicy biznesowi wciąż potrzebują prostych wariantów istniejących raportów, pytając: „Czy może Pan/Pani pogrupować to według kategorii produktu?” albo „Jak to wypada w porównaniu z zeszłym miesiącem?”. Czekając w kolejce na odpowiedź, inżynierowie i analitycy danych toną w powtarzalnych zadaniach SQL.
Dzięki Analityce Konwersacyjnej w BigQuery wreszcie można przesunąć wąskie gardło. Ta funkcja wprowadza do BigQuery Studio silnik wnioskowania oparty na AI, który pozwala użytkownikom zadawać pytania w języku naturalnym i natychmiast otrzymywać dane, wykresy oraz wygenerowany SQL.
W tym przewodniku dowie się Pan/Pani, jak skonfigurować i korzystać z analityki konwersacyjnej w BigQuery. Zbuduje Pan/Pani, skonfiguruje i dopracuje własnych agentów danych, aby Państwa organizacja mogła bezpiecznie „rozmawiać” z danymi.
Analityka konwersacyjna przesuwa interakcję z danymi z ręcznego pisania zapytań SQL do rozmów w języku naturalnym. Zamiast tworzyć instrukcje SELECT, rozmawia Pan/Pani z agentem danych, który rozumie kontekst biznesowy i zwraca odpowiedzi oparte na rzeczywistych tabelach.
To nie jest tylko podstawowy parser text-to-SQL; to znaczący krok w kierunku prawdziwej demokratyzacji danych.
Pozwala osobom nietechnicznym samodzielnie uzyskiwać wgląd w dane w czasie rzeczywistym, a specjalistom ds. danych zapewnia szybki sposób eksploracji zbiorów i automatyzacji raportowania.
Sercem analityki konwersacyjnej BigQuery jest silnik wnioskowania oparty na rodzinie modeli Gemini. Agenci danych korzystają ze strukturyzowanego, wieloetapowego potoku, aby zapewnić, że wnioski są oparte na Pana/Pani konkretnym kontekście danych:
Google Cloud oferuje analitykę konwersacyjną na różnych warstwach stosu danych. Wybór właściwego punktu zależy od użytkowników i miejsca, w którym żyje logika biznesowa:
|
Funkcja |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (przez BigQuery Agents) |
|
Najlepsze dla |
Zespoły danych, analitycy i deweloperzy budujący aplikacje niestandardowe |
Użytkownicy biznesowi potrzebujący nadzorowanych, gotowych do pulpitu wniosków |
Użytkownicy biznesowi preferujący lekkie raportowanie BI |
|
Metoda osadzenia w danych |
Bezpośrednie schematy hurtowni, metadane tabel i zweryfikowane zapytania |
LookML (warstwa semantyczna) |
Połączone bezpośrednio z gotowymi agentami danych BigQuery |
|
Dostęp do danych |
Może analizować dane ustrukturyzowane, predykcyjne (ML) i nieustrukturyzowane |
Ściśle ustrukturyzowane, zamodelowane dane |
Dane ustrukturyzowane |
|
Status wydania |
Podgląd (stan na maj 2026) |
Ogólnie dostępne |
Podgląd |
Którą ścieżkę wybrać?
Ten tutorial koncentruje się na BigQuery jako najszybszym sposobie dla zespołów danych na prototypowanie i wdrażanie agentów bezpośrednio tam, gdzie znajdują się dane.
Zanim przystąpi Pan/Pani do konfiguracji, ważne jest zrozumienie architektury agenta danych. W środowisku Google Cloud agent danych jest centralną warstwą abstrakcji. Łączy zasoby BigQuery z możliwościami wnioskowania rodziny modeli Gemini.
Zamiast bezpośrednio udostępniać surowe tabele, agent danych konfiguruje wszystko, czego model potrzebuje do interpretacji pytań, generowania bezpiecznego SQL i zwracania wiarygodnych odpowiedzi. To połączenie źródeł danych, instrukcji i zweryfikowanej logiki sprawia, że analityka konwersacyjna BigQuery jest bardziej niezawodna niż standardowe narzędzia text-to-SQL.
Źródła wiedzy to warstwa fundamentowa każdego agenta danych. Definiują dokładnie, do jakich danych agent może mieć dostęp i je odpytywać.
Typy zasobów: Tabele, Widoki i Funkcje zdefiniowane przez użytkownika (UDF) mogą być podłączone jako źródła wiedzy.
Skalowalność: Do jednego agenta można podłączyć wiele źródeł wiedzy. Pozwala to agentowi łączyć informacje z różnych obszarów biznesowych.
Kontrola dostępu: Zdefiniowanie konkretnych źródeł wiedzy zapewnia, że agent działa wyłącznie w obrębie autoryzowanych danych.
Inteligencja agenta zależy od dostarczonego kontekstu. To klucz do tego, by ogólny model zrozumiał język firmy.
Definiując niestandardowe instrukcje, synonimy i słowniki biznesowe, osadza się agenta w określonej domenie. Na przykład można nauczyć agenta, że „Najlepsi klienci” to użytkownicy o wartości życiowej (LTV) powyżej 1 000 USD.
Kluczowe elementy osadzenia:
Niestandardowe instrukcje: Dostarczają wytycznych wysokiego poziomu, np. „Zawsze wykluczaj wewnętrzne konta testowe z raportów przychodowych”.
Słowniki biznesowe: Mapują terminy techniczne na język naturalny, np. store_id na „Lokalizacja oddziału”.
Metadane pól: Opisy, które pomagają agentowi zrozumieć niuanse poszczególnych zmiennych, takich jak „Przychód brutto” versus „Zysk netto”.
Im lepsze instrukcje i metadane, tym wyższa dokładność agenta.
Zweryfikowane zapytania, wcześniej znane jako Golden Queries, to predefiniowane pary pytanie–odpowiedź będące źródłem prawdy. Mapując konkretne pytania na ekspercko zweryfikowany SQL, agent stosuje właściwe ścieżki złączeń i filtry dla krytycznych KPI.
Zapytania te mogą obejmować funkcje BigQuery ML (BQML). Dzięki temu agent może obsługiwać zaawansowane prośby, takie jak generowanie predykcji churnu czy prognoz sprzedaży, z użyciem dokładnych parametrów modeli zdefiniowanych przez data scientistów. Po weryfikacji zasoby są zarządzane przez Dataplex Universal Catalog, co zapewnia spójność w całej organizacji.
Skoro zna już Pan/Pani elementy składowe, przejdźmy do faktycznego tworzenia i konfiguracji pierwszego agenta danych.
Aby podążać za naszym tutorialem, proszę upewnić się, że spełnione są następujące wymagania wstępne:
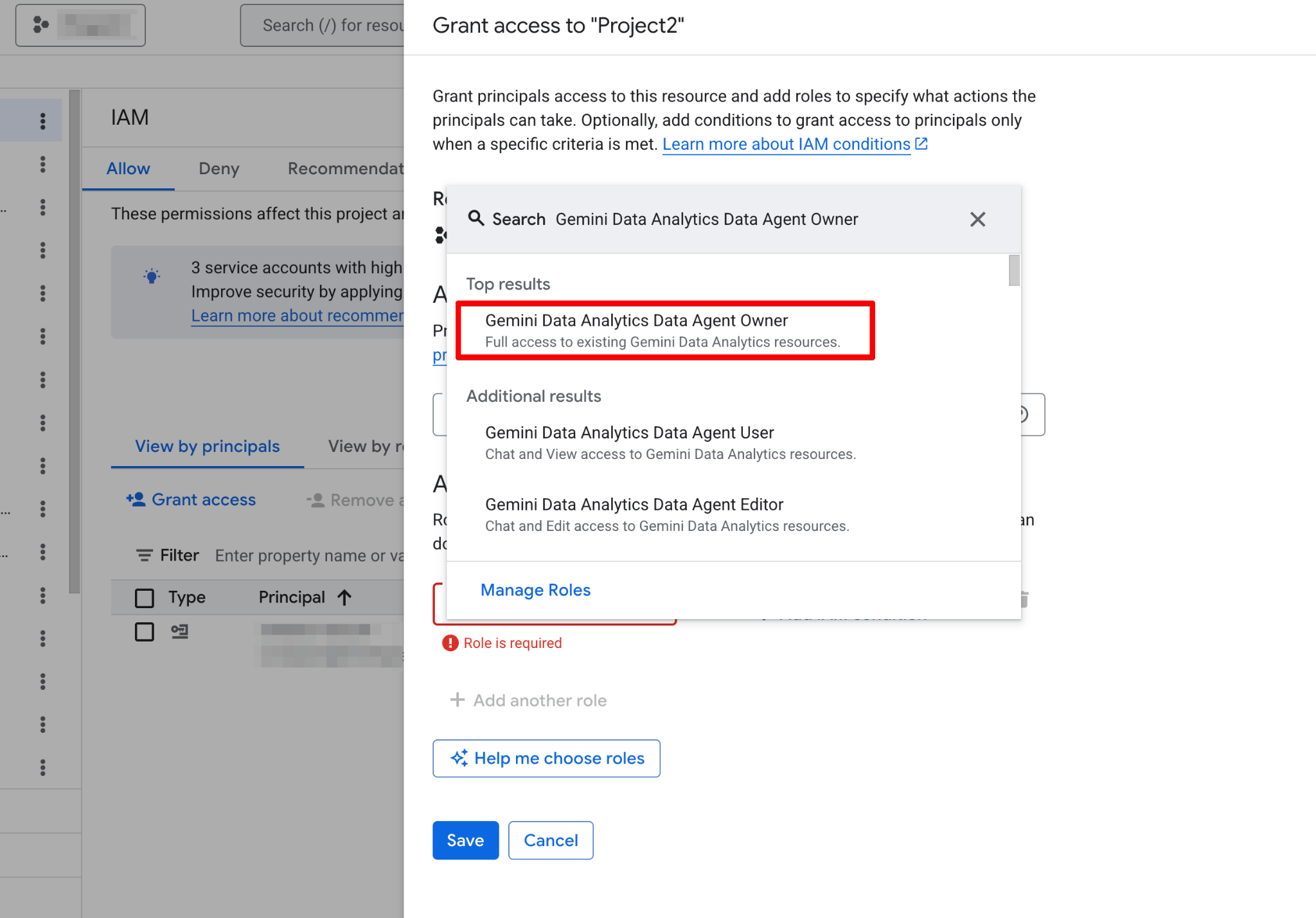
Zanim zbuduje Pan/Pani pierwszego agenta, należy skonfigurować projekt Google Cloud i upewnić się, że konto użytkownika ma wymagane uprawnienia. Agenci danych działają jako warstwa nad istniejącymi danymi, dlatego prawidłowa konfiguracja IAM (Identity and Access Management) jest kluczowa zarówno dla bezpieczeństwa, jak i funkcjonalności.
Proszę wykonać te kroki:
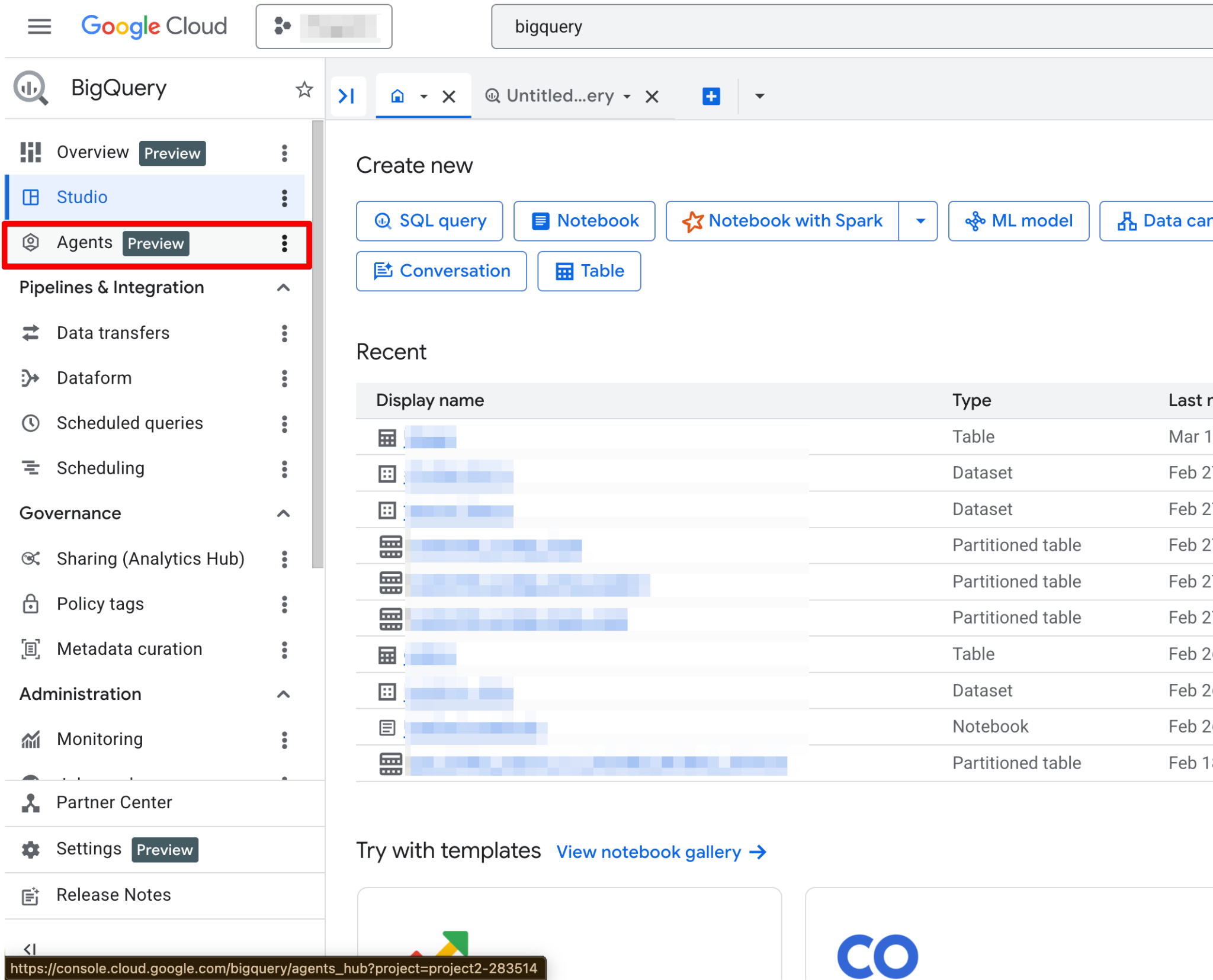
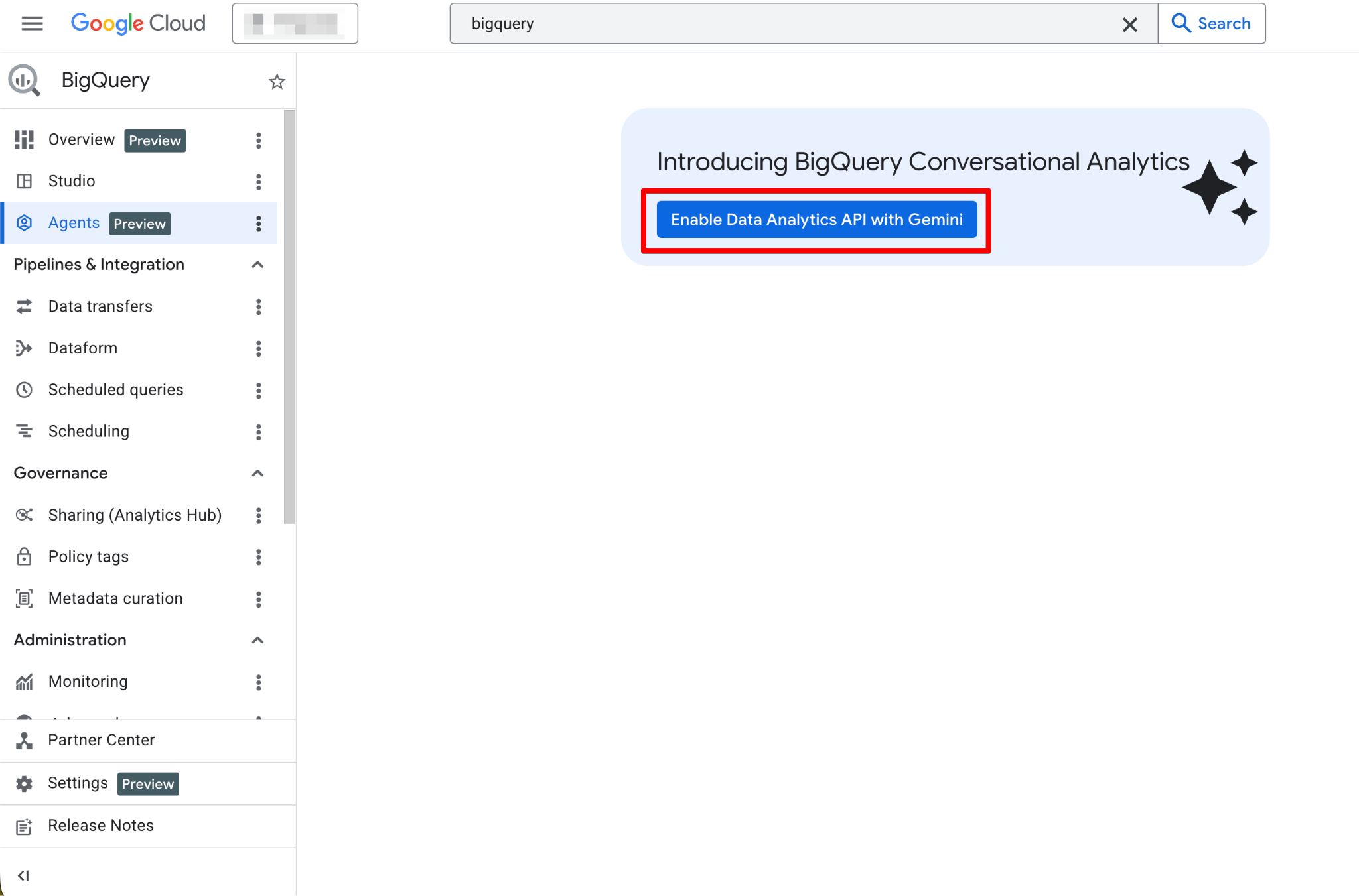
Po włączeniu strona Agents stanie się w pełni funkcjonalna. Powinna się teraz wyświetlić nowa strona agenta:
Agent Catalog służy do tworzenia, zarządzania i wersjonowania agentów danych w BigQuery Studio.
Oto co znajdzie Pan/Pani w Agent Catalog:
Cykl życia agenta przebiega według schematu (Draft → Created → Published):
Kliknięcie dowolnej karty agenta otwiera ją, umożliwiając wyświetlenie szczegółów, rozpoczęcie rozmowy lub edycję (jeśli ma Pan/Pani uprawnienia Owner). Interfejs zawiera także kartę Conversations, w której można zarządzać wcześniejszymi czatami z agentami lub źródłami danych.
Gdy fundamenty są gotowe, zbudujmy agenta danych od podstaw. Użyjemy zbioru bigquery-public-data.austin_bikeshare, aby przekształcić surowe dane o przejazdach w interfejs konwersacyjny. Skorzystamy z dwóch tabel:
bikeshare_trips — szczegółowe dane na poziomie przejazdów
bikeshare_stations — metadane stacji
Rozpoczęcie tworzenia agenta
Te dwa pola pomogą szybko zidentyfikować agenta później. Gdy już są ustawione, można skonfigurować trzy kluczowe elementy, o których mówiliśmy wcześniej: źródła wiedzy, instrukcje i (później) zweryfikowane zapytania.
Źródła wiedzy definiują dokładnie, do jakich danych agent ma dostęp. Im mniej i im bardziej skupione źródła, tym lepsza dokładność i niższy koszt. W sekcji Knowledge sources edytora proszę kliknąć Add source. Wyszukać austin_bikeshare i wybrać bikeshare_trips oraz bikeshare_stations jako źródła.
Dla każdej dodanej tabeli proszę kliknąć Customize.
Gemini automatycznie wygeneruje opis i zaproponuje metadane kolumn. Proszę wszystko przejrzeć, zaakceptować trafne sugestie, wprowadzić poprawki i kliknąć Update.
Częsty błąd to dodanie od razu 50 tabel. Proszę zacząć od 2–3 kluczowych tabel. Ułatwia to debugowanie logiki agenta. Zawsze można rozszerzyć zakres wiedzy, gdy podstawowe zapytania będą poprawne.
Następnie należy ugruntować działanie agenta poprzez instrukcje. Zamiast wpisywać ogólny prompt (np. „Odpowiadaj na pytania o sprzedaży”), interfejs agenta danych BigQuery pozwala podać silnie ustrukturyzowany kontekst ukierunkowujący generowanie zapytań przez AI. Proszę myśleć o tym jak o onboardingu nowego analityka z dokładnym słownikiem danych firmy.
Proszę użyć pola Instructions, aby przekazać ustrukturyzowany kontekst biznesowy. Oto kompletny, gotowy do użycia przykład do wklejenia:
Synonimy: Proszę zdefiniować alternatywne terminy dla kolumn, aby agent rozumiał warianty języka naturalnego. Przykład: „Journey”, „Ride” i „Commute” odnoszą się do rekordu w tabeli bikeshare_trips. „Dock”, „Hub” lub „Station” odnosi się do rekordu w tabeli bikeshare_stations.
Kluczowe pola: Proszę wyróżnić najważniejsze pola do analizy. To wskazuje agentowi, które kolumny priorytetyzować, gdy pytanie użytkownika jest ogólne. Przykład: Priorytetyzuj trip_id, start_station_name, end_station_name, subscriber_type, start_time i duration_minutes dla raportowania ogólnego.
Pola wykluczone: Proszę wskazać kolumny, których agent ma bezwzględnie unikać. To niezwykle przydatne do ukrycia przestarzałych kolumn lub nieistotnych danych. Przykład: Nie używaj kolumny bike_id w tabeli bikeshare_trips w większości analiz, ponieważ rzadko jest potrzebna do pytań biznesowych.
Filtrowanie i grupowanie: Proszę poinstruować agenta o standardowych sposobach podziału danych. Przykład: O ile nie określono inaczej, zawsze filtruj przejazdy, gdzie duration_minutes < 1 (to fałszywe starty lub przejazdy testowe). Domyślnie grupuj dane po start_station_name, gdy użytkownik prosi o „według stacji” lub „najlepsze stacje”.
Relacje złączeń: Ponieważ nasz agent korzysta z wielu tabel, proszę jednoznacznie zdefiniować, jak są połączone. Zapobiega to błędnemu zgadywaniu kluczy obcych. Przykład: Łącz tabelę bikeshare_trips z tabelą bikeshare_stations dopasowując bikeshare_trips.start_station_id do bikeshare_stations.station_id (analogicznie dla end_station_id).
Wszystko powyższe można połączyć w jednym, przejrzystym bloku w polu Instructions. Oto dopracowana, gotowa do wklejenia wersja zawierająca ustrukturyzowane wskazówki:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).
Dlaczego to ważne: Jeśli te pola pozostaną puste, niejednoznaczne pytanie w rodzaju „Jakie były nasze najlepsze wyniki sprzedaży?” może skłonić agenta do niewłaściwego łączenia tabel, pobrania danych z nieaktywnych kont lub uwzględnienia przestarzałych danych. Strukturyzując instrukcje w tych pięciu kategoriach, zapewnia Pan/Pani, że generowany SQL ściśle trzyma się ustalonej logiki biznesowej.
Oprócz instrukcji może (i powinien) Pan/Pani zdefiniować pojęcia słownikowe bezpośrednio w agencie. Pomagają one agentowi konsekwentnie interpretować żargon biznesowy, skróty i pojęcia pochodne.
Proszę kliknąć Add term w sekcji Glossary (zwykle obok Instructions) i utworzyć pojęcia z hasłem, definicją oraz synonimami (oddzielonymi przecinkami).
Oto rekomendowane pojęcia słownikowe dla zbioru Austin Bikeshare:
| Termin | Definicja | Synonimy |
duration_minutes |
Czas trwania przejazdu w minutach. Zawsze używaj tego pola w odpowiedziach dla użytkowników i obliczeniach | czas jazdy, długość przejazdu, czas trwania, czas przejazdu |
ridership |
Łączna liczba (liczność) rozpoczętych przejazdów rowerowych | przejazdy, jazdy, podróże, wykorzystanie rowerów, liczba dojazdów |
peak_hours |
Poranne (7–9) lub wieczorne (16–19) godziny szczytu na podstawie godziny wyodrębnionej z start_time |
godziny szczytu, godziny największego ruchu, okres wysokiego popytu |
subscriber_type |
Typ użytkownika — Subskrybent (posiadacz abonamentu miesięcznego lub rocznego) lub Klient (pojedynczy przejazd | typ użytkownika, typ członkostwa, posiadacz karnetu, członek, rowerzysta okazjonalny |
false_start |
Bardzo krótki przejazd (zwykle poniżej 1 minuty), który prawdopodobnie jest jazdą testową lub przypadkowym odblokowaniem. Należy je zwykle wykluczać z analizy | jazda testowa, nieprawidłowy przejazd, krótki przejazd |
Można dodawać kolejne pojęcia w razie potrzeby (np. dla start_station_name, end_station_name lub metryk pochodnych, takich jak „średni czas przejazdu” czy „długi przejazd”).
Dzięki słownikom, jeśli kierownictwo zdecyduje w przyszłym kwartale zmienić oficjalną definicję „Długiego przejazdu” na 45 minut, zespół ds. ładu danych musi zaktualizować ją tylko raz w Dataplex. Każdy agent danych połączony z tym słownikiem natychmiast przyjmie nową logikę, utrzymując spójność w całej organizacji.
Gdy skonfiguruje Pan/Pani źródła wiedzy, instrukcje i pojęcia słownikowe, czas przetestować agenta przed publikacją.
Proszę przewinąć do prawej strony ekranu do panelu Preview. Ten interfejs czatu na żywo pozwala wchodzić w interakcję z agentem w czasie rzeczywistym podczas jego budowy. Można zadawać pytania, przeglądać rozumowanie agenta, sprawdzać wygenerowany SQL i szybko iterować.
Panel Preview pokazuje:
Proszę wypróbować te cztery zapytania o rosnącej złożoności (dostosowane do zakresu danych zbioru do 2024 r.):
Co zobaczy Pan/Pani w odpowiedzi agenta:
Podsumowanie — Wyjaśnienie wyników w języku naturalnym.
Wynik zapytania — Czysta tabela z danymi (np. łączna liczba przejazdów, najlepsze stacje lub średni czas).
Wnioski — Punktowe spostrzeżenia interpretujące wyniki w kontekście biznesowym.
Wygenerowany SQL — Proszę kliknąć Open in Editor, aby zobaczyć pełne zapytanie SQL utworzone przez agenta (zobaczy Pan/Pani poprawne filtrowanie po start_time i zastosowanie duration_minutes >= 1 w celu wykluczenia fałszywych startów).
Sugerowane pytania uzupełniające — Pomocne podpowiedzi na dole (np. „Jakie były top 10 stacji startowych w czerwcu 2024?”, „Prognozuj dzienną liczbę przejazdów…” itp.).
Wizualizacja — Automatycznie wygenerowany wykres (słupkowy dla rankingów, jak w przykładzie 5 najlepszych stacji).
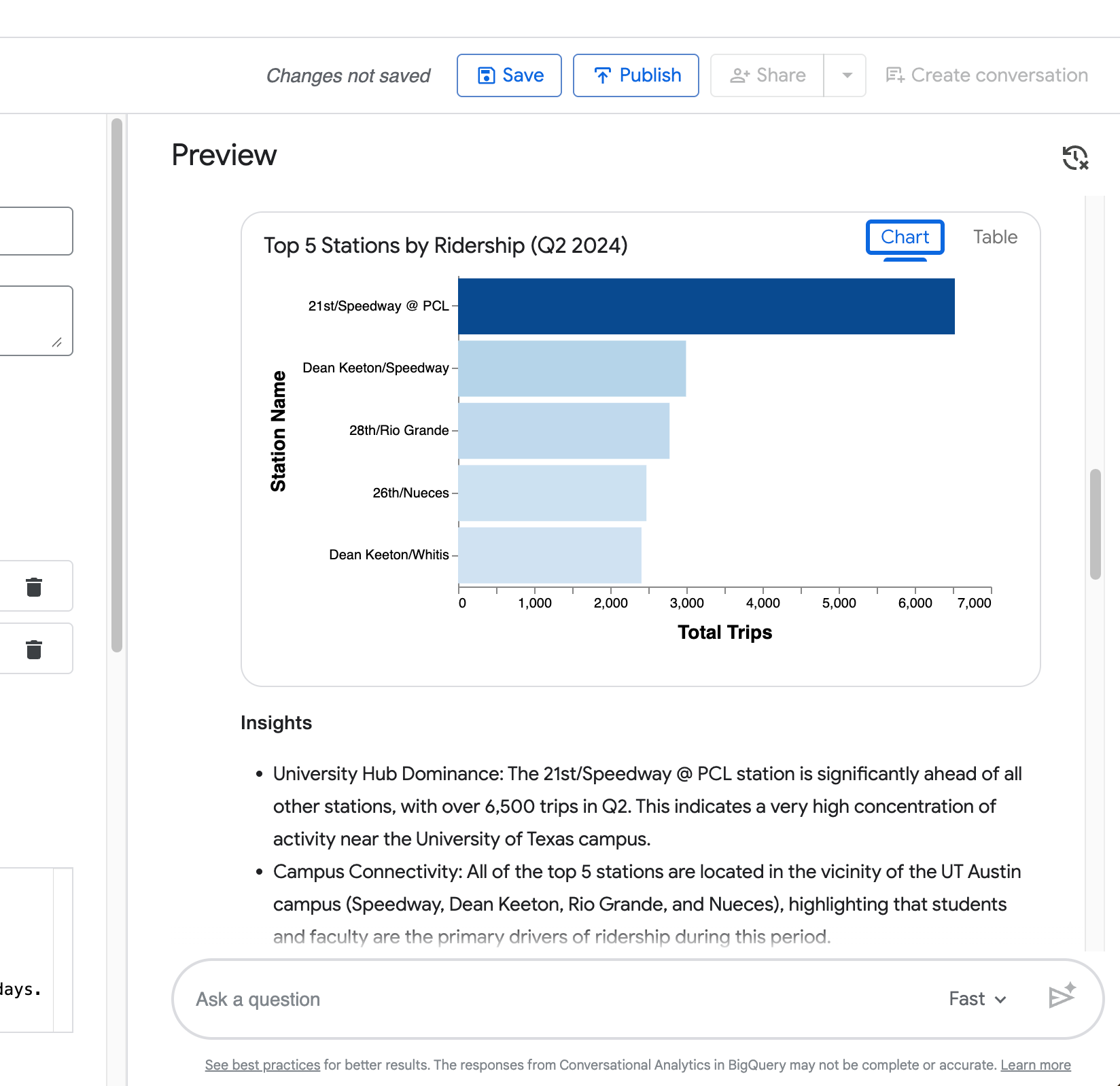
Czwarte zapytanie („Teraz pokaż to samo porównanie, ale tylko dla stacji Zilker Park”) pokazuje zdolność agenta do zachowywania kontekstu z poprzedniego pytania.
Jak widać na zrzucie ekranu poniżej, poprawnie zawęża porównanie czasu trwania w dni robocze vs weekendy do Zilker Park, bez konieczności powtarzania całej prośby.
Wskazówki do testów:
Gdy agent konsekwentnie udziela jasnych, dokładnych i dobrze ustrukturyzowanych odpowiedzi, proszę kliknąć Save u góry, a następnie Publish. Pana/Pani agent Austin Bikeshare Analyst jest gotowy do użycia!
Nawet przy dobrych instrukcjach i pojęciach słownikowych agent danych może czasem błędnie zinterpretować reguły biznesowe lub generować niespójne odpowiedzi.
Zweryfikowane zapytania rozwiązują to, pozwalając jednoznacznie nauczyć agenta właściwego postępowania z ważnymi lub często zadawanymi pytaniami. Każde zweryfikowane zapytanie składa się z pytania w języku naturalnym sparowanego z dokładnym SQL, którego należy użyć.
Służą jako wysokiej jakości przykłady kotwiczące rozumowanie agenta i są jednym z najskuteczniejszych sposobów przejścia od agenta „wystarczająco dobrego” do gotowego do produkcji.
W edytorze agenta proszę przewinąć do sekcji Verified Queries. Ma Pan/Pani dwa proste sposoby dodania zweryfikowanych zapytań:
Proszę kliknąć Add query. Zobaczy Pan/Pani ekran Add verified query, na którym można:
Proszę kliknąć View Gemini-generated suggestions. Otworzy to ekran „Review suggested verified queries”, na którym Gemini proponuje adekwatne pytania na podstawie Pana/Pani źródeł wiedzy.
Można:
Dobre zweryfikowane zapytanie dla zbioru Austin Bikeshare mogłoby brzmieć:
Pytanie:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;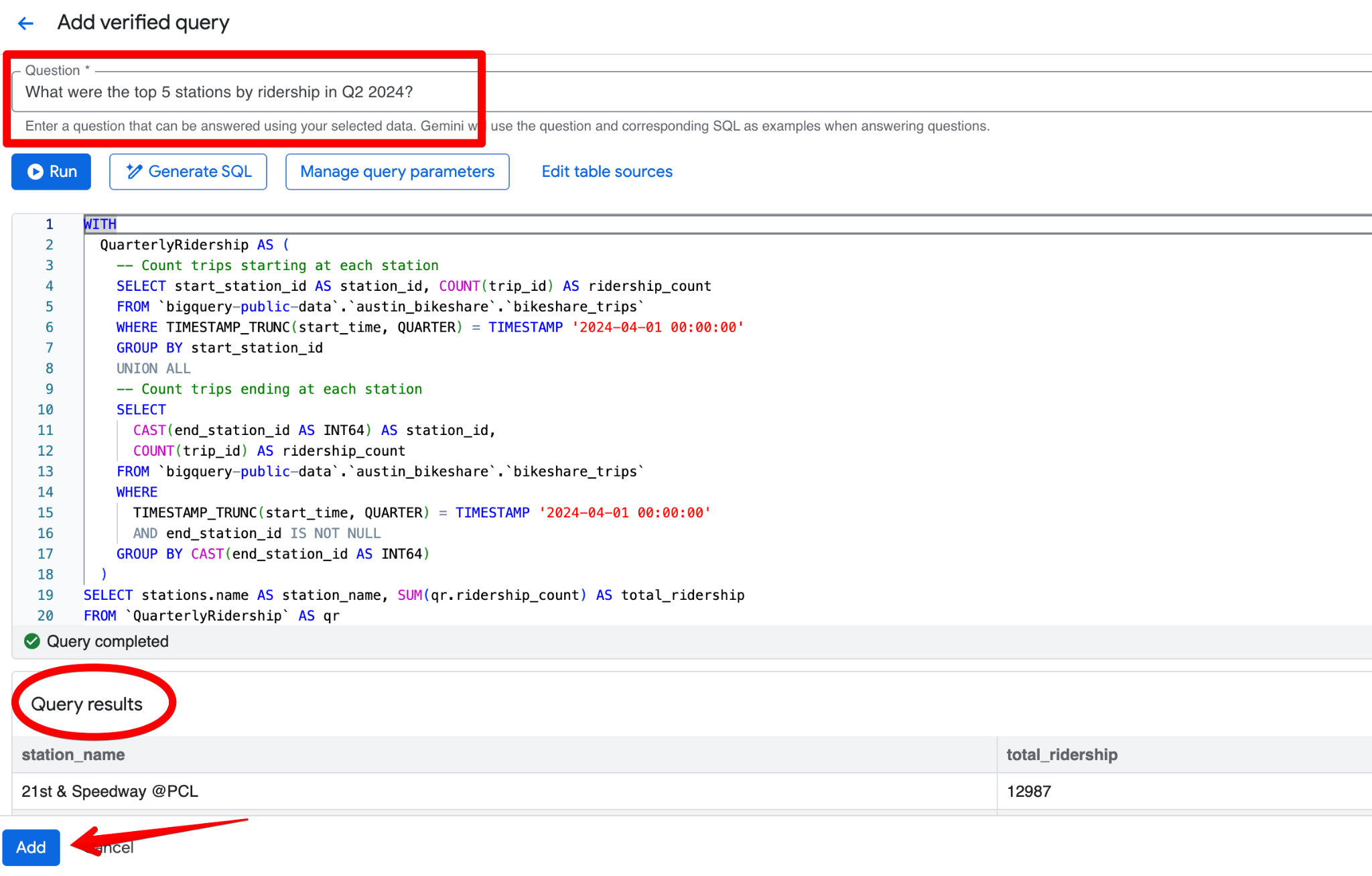
Nawet jeśli agent poda rozsądną odpowiedź za pierwszym razem, można znacząco zwiększyć jej dokładność i spójność, przeglądając generowany SQL i dodając zweryfikowane zapytania.
Proszę postępować według praktycznego schematu:
Załóżmy, że zapytał(a) Pan/Pani: „Jaki był średni czas przejazdu w czerwcu 2024?” W początkowej odpowiedzi agent zwraca 26,68 minuty i poprawnie wyklucza przejazdy krótsze niż 1 minuta. Załóżmy teraz, że standardową regułą biznesową zespołu jest wykluczanie przejazdów krótszych niż 5 minut.
Po otwarciu wygenerowanego SQL (przez Open in Editor) widać, że filtr to tylko duration_minutes >= 1.
Proszę kliknąć Add query w sekcji Verified Queries i utworzyć następującą pozycję:
Pytanie:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes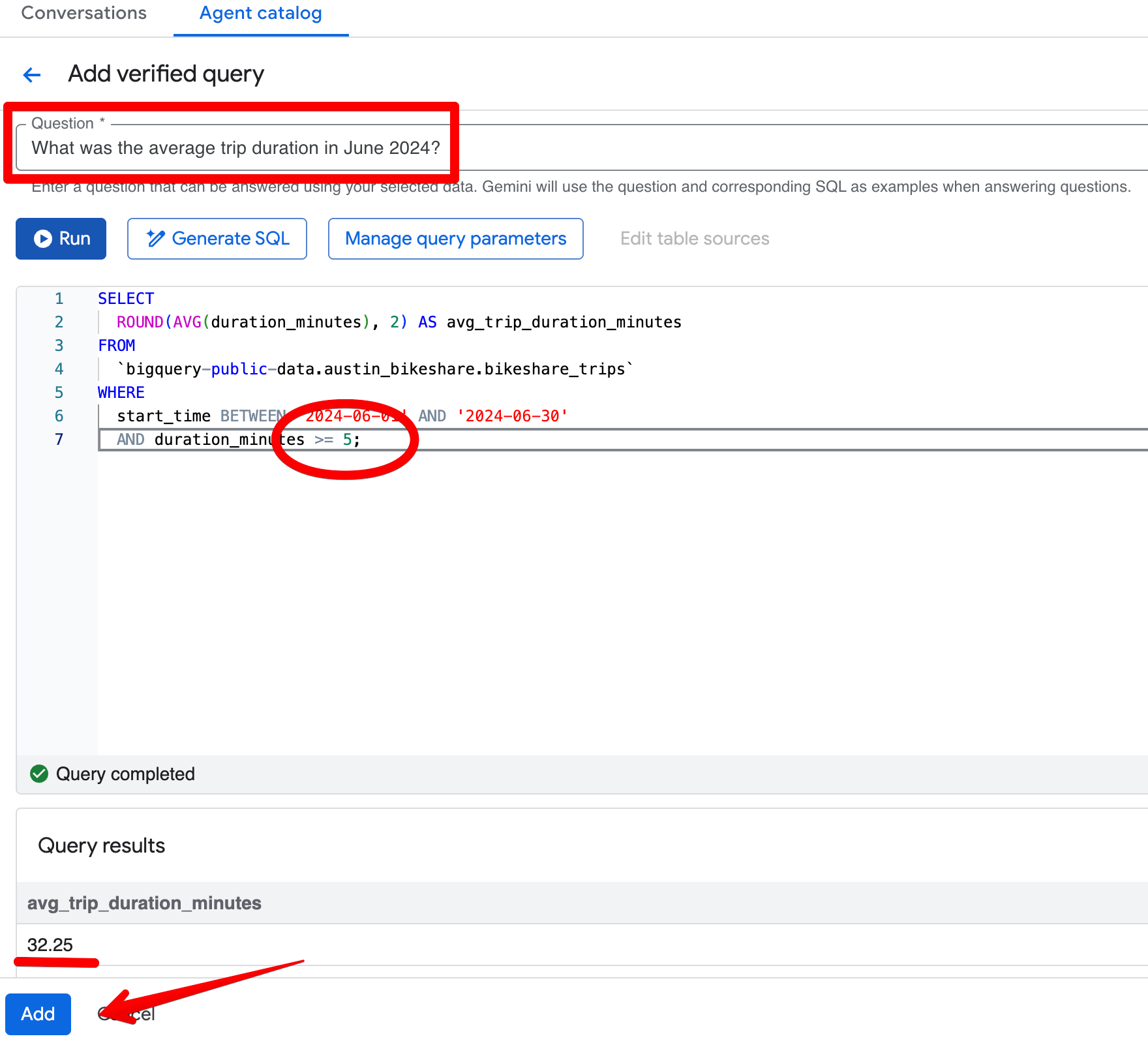
Po zapisaniu zweryfikowanego zapytania proszę ponownie zadać to samo pytanie w panelu Preview. Agent będzie teraz konsekwentnie zwracał ~32,08 minuty i stosował surowszy próg 5 minut. Wyniki staną się bardziej zgodne z biznesową definicją „istotnych” przejazdów.
Analityka konwersacyjna BigQuery wyróżnia się na tle prostych narzędzi text-to-SQL dzięki natywnemu wsparciu funkcji BigQuery ML, danych nieustrukturyzowanych oraz łatwemu udostępnianiu w całym ekosystemie Google Cloud.
Jednym z największych wyróżników jest zdolność agenta do wywoływania funkcji BigQuery ML bezpośrednio z języka naturalnego, co pozwala wyjść poza raportowanie retrospektywne ku wglądom prognostycznym.
Na przykład można poprosić agenta danych o przewidzenie dziennej liczby przejazdów na następne 30 dni na podstawie trendów z 2024 r. Agent wywoła AI.FORECAST i wygeneruje prognozę na lipiec 2024 wraz z czytelnym wykresem pokazującym historyczne dzienne przejazdy (niebieska linia) i 30-dniową prognozę (pomarańczowa linia) z zacieniowanym 95% przedziałem ufności.
Innym sposobem, w jaki algorytmy uczenia maszynowego mogą być pomocne, jest wykrywanie nieprawidłowości w danych. Gdy na przykład poprosi Pan/Pani agenta o wykrycie anomalii w dziennych przejazdach w czerwcu 2024, wywoła on AI.DETECT_ANOMALIES, porównując czerwiec 2024 do wcześniejszych miesięcy, i zwróci tabelę szeregu czasowego oraz wykres liniowy.
W tym przypadku nie oznaczono formalnych anomalii na poziomie ufności 95%, ale wyróżniono 19 czerwca jako niemal-anomalię (prawdopodobieństwo 92,1%) ze zauważalnym spadkiem liczby przejazdów.
Większość narzędzi konwersacyjnych BI zawodzi w momencie, gdy dane nie są schludnie ułożone w wiersze i kolumny. BigQuery obsługuje jednak Object Tables, które umożliwiają analizę danych nieustrukturyzowanych (takich jak PDF-y, obrazy i surowe logi tekstowe) przechowywanych w Google Cloud Storage.
Ponieważ agent danych jest zasilany multimodalnymi możliwościami Gemini, potrafi jednocześnie wnioskować zarówno na podstawie ustrukturyzowanych metryk, jak i nieustrukturyzowanych plików. To ogromny, unikalny wyróżnik BigQuery.
Jeśli ma Pan/Pani PDF-y z ankietami użytkowników lub obrazy inspekcji stacji w tabeli obiektów, wystarczy zapytać: „Proszę podsumować główne skargi z PDF-ów ankiety użytkowników z Q2 2024”. Agent odczyta pliki nieustrukturyzowane i połączy informacje z ustrukturyzowanymi danymi o przejazdach
Zespół danych buduje i testuje agentów w BigQuery Studio, ale użytkownicy końcowi często pracują w innych aplikacjach. Google ułatwia oddzielenie agenta od konsoli GCP, aby dotrzeć do użytkowników biznesowych tam, gdzie już pracują.
Jeśli chce Pan/Pani samodzielnie spróbować zbudować niestandardową aplikację czatową, może Pan/Pani także przeczytać więcej w oficjalnym Introduction to Conversational Analytics in BigQuery.
Jeśli jest jedna kluczowa zasada do zapamiętania, to ta: analityka konwersacyjna przesuwa wąskie gardło analityczne z oczekiwania na zespół danych na po prostu zadanie właściwego pytania.
Ta demokratyzacja nie oznacza, że zespoły danych są zbędne, ale ich rola się zmienia. Agent AI jest tak inteligentny, jak zabezpieczenia, które Pan/Pani wokół niego zbuduje. Dokładność i bezpieczeństwo agentów danych w pełni zależą od dostarczonych instrukcji, kontekstu i architektury schematów.
Aby zbudować najbardziej efektywnych agentów konwersacyjnych, wciąż potrzebna jest solidna znajomość bazowej hurtowni danych. Jeśli Pan/Pani lub zespół chce wzmocnić te kluczowe umiejętności i opanować platformę napędzającą te funkcje AI, proszę sprawdzić dziś kurs DataCamp Introduction to BigQuery!
Kursy Google Cloud
Track
course
course