
Programma
Google Cloud Digital Leader
8 h
Se lavori in un team dati, questo scenario probabilmente ti suona familiare: il backlog è pieno di richieste ad hoc. Gli utenti di business hanno continuamente bisogno di semplici varianti di report esistenti e chiedono: "Puoi raggruppare per categoria di prodotto?" o "Come si confronta con il mese scorso?". Mentre aspettano in coda una risposta, data engineer e analisti sono sommersi da attività SQL ripetitive.
Con l’Analisi Conversazionale in BigQuery puoi finalmente spostare il collo di bottiglia. Questa funzionalità porta un motore di ragionamento basato su AI direttamente in BigQuery Studio, permettendo agli utenti di porre domande in linguaggio naturale e ricevere all’istante dati, grafici e SQL generato.
In questa guida imparerai a configurare e utilizzare l’analisi conversazionale in BigQuery. Creerai, configurerai e affinerai i tuoi agenti dati, così la tua organizzazione potrà dialogare in sicurezza con i propri dati.
L’analisi conversazionale sposta l’interazione con i dati dalle query SQL manuali a conversazioni in linguaggio naturale. Invece di scrivere istruzioni SELECT, dialoghi con un agente dati che comprende il tuo contesto di business e restituisce risposte basate sulle tue tabelle reali.
Non è un semplice parser text-to-SQL; è un passo importante verso la vera democratizzazione dei dati.
Consente agli utenti non tecnici di accedere in autonomia a insight in tempo reale e offre ai professionisti dei dati un modo rapido per esplorare i dataset e automatizzare i report.
Al cuore dell’analisi conversazionale di BigQuery c’è un motore di ragionamento basato sulla famiglia di modelli Gemini. Gli agenti dati usano una pipeline strutturata in più fasi per garantire che gli insight siano ancorati al tuo specifico contesto dati:
Google Cloud offre funzionalità di analisi conversazionale su diversi livelli del tuo stack dati. La scelta del punto d’ingresso dipende dagli utenti e da dove risiede la tua logica di business:
|
Funzionalità |
Analisi Conversazionale BigQuery |
Analisi Conversazionale Looker |
Data Studio (tramite BigQuery Agents) |
|
Ideale per |
Team dati, analisti e sviluppatori che creano applicazioni personalizzate |
Utenti di business che necessitano di insight governati e pronti per la dashboard |
Utenti di business che preferiscono reportistica BI leggera |
|
Metodo di grounding |
Schemi del data warehouse, metadati delle tabelle e query verificate |
LookML (strato semantico) |
Collegato direttamente ad agenti dati BigQuery preconfigurati |
|
Accesso ai dati |
Può analizzare dati strutturati, predittivi (ML) e non strutturati |
Dati rigorosamente strutturati e modellati |
Dati strutturati |
|
Stato di rilascio |
Preview (a maggio 2026) |
Generalmente disponibile |
Preview |
Quale strada dovresti scegliere?
Questo tutorial si concentra su BigQuery come il modo più rapido per i team dati di prototipare e portare in produzione agenti direttamente dove risiedono i dati.
È importante comprendere l’architettura di un agente dati prima di configurarlo. Nell’ambiente Google Cloud, un agente dati è il livello centrale di astrazione. Combina gli asset di BigQuery con le capacità di ragionamento della famiglia di modelli Gemini.
Invece di esporre direttamente le tabelle grezze, un agente dati configura tutto ciò di cui il modello ha bisogno per interpretare le domande, generare SQL sicuro e restituire risposte affidabili. Questa combinazione di fonti dati, istruzioni e logica verificata rende l’analisi conversazionale di BigQuery più affidabile dei normali strumenti text-to-SQL.
Le sorgenti di conoscenza sono il livello fondativo di qualsiasi agente dati. Definiscono esattamente a quali dati l’agente è autorizzato ad accedere e interrogare.
Tipi di asset: tabelle, viste e funzioni definite dall’utente (UDF) possono connettersi come sorgenti di conoscenza.
Scalabilità: più sorgenti di conoscenza possono connettersi a un singolo agente. Questo consente all’agente di combinare informazioni tra diverse aree di business.
Controllo degli accessi: definire sorgenti di conoscenza specifiche garantisce che l’agente operi solo all’interno dei dati autorizzati.
L’intelligenza di un agente dipende dal contesto fornito. Questo è fondamentale per far comprendere a un modello generico il linguaggio di un’azienda.
Definendo istruzioni personalizzate, sinonimi e glossari di business, l’agente è ancorato a un dominio specifico. Ad esempio, è possibile insegnare all’agente che "Top Customers" si riferisce a utenti con un valore di vita (LTV) superiore a 1.000 $.
Elementi chiave di grounding:
Istruzioni personalizzate: fornisci direttive di alto livello, come "Escludi sempre gli account di test interni dai report sui ricavi".
Glossari di business: mappa i termini tecnici nel linguaggio naturale, ad esempio store_id in "Sede filiale".
Metadati dei campi: descrizioni che aiutano l’agente a capire le sfumature di variabili specifiche, come "Ricavi lordi" rispetto a "Utile netto".
Più sono accurate istruzioni e metadati, maggiore sarà l’accuratezza dell’agente.
Le query verificate, in precedenza note come Golden Queries, sono coppie domanda-risposta predefinite che fungono da fonte di verità. Mappando domande specifiche a SQL validato da esperti, l’agente usa i percorsi di join e i filtri corretti per i KPI critici.
Queste query possono includere funzioni BigQuery ML (BQML). Ciò consente all’agente di gestire richieste avanzate, come generare previsioni di churn o previsioni di vendita, utilizzando esattamente i parametri di modello definiti dai data scientist. Una volta verificate, queste risorse sono gestite tramite il Dataplex Universal Catalog, garantendo coerenza in tutta l’organizzazione.
Ora che conosci i mattoni fondamentali, passiamo alla creazione e configurazione del tuo primo agente dati.
Per seguire il nostro tutorial, assicurati di avere i seguenti prerequisiti:
Prima di creare il tuo primo agente, devi configurare il progetto Google Cloud e assicurarti che il tuo account utente disponga delle autorizzazioni necessarie. I Data Agent operano come un livello sopra i tuoi dati esistenti, quindi una corretta configurazione IAM (Identity and Access Management) è fondamentale sia per la sicurezza che per la funzionalità.
Segui questi passaggi:
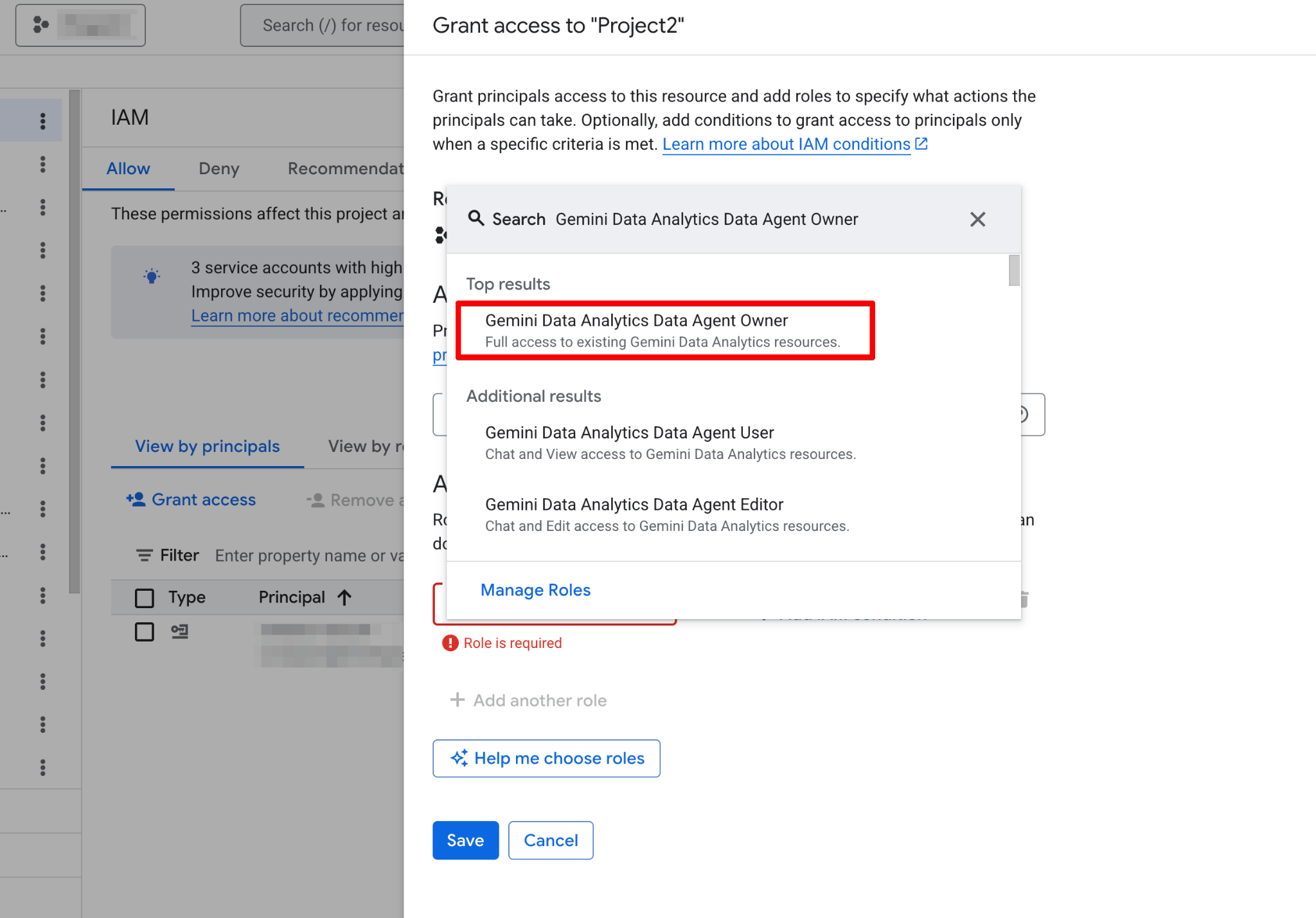
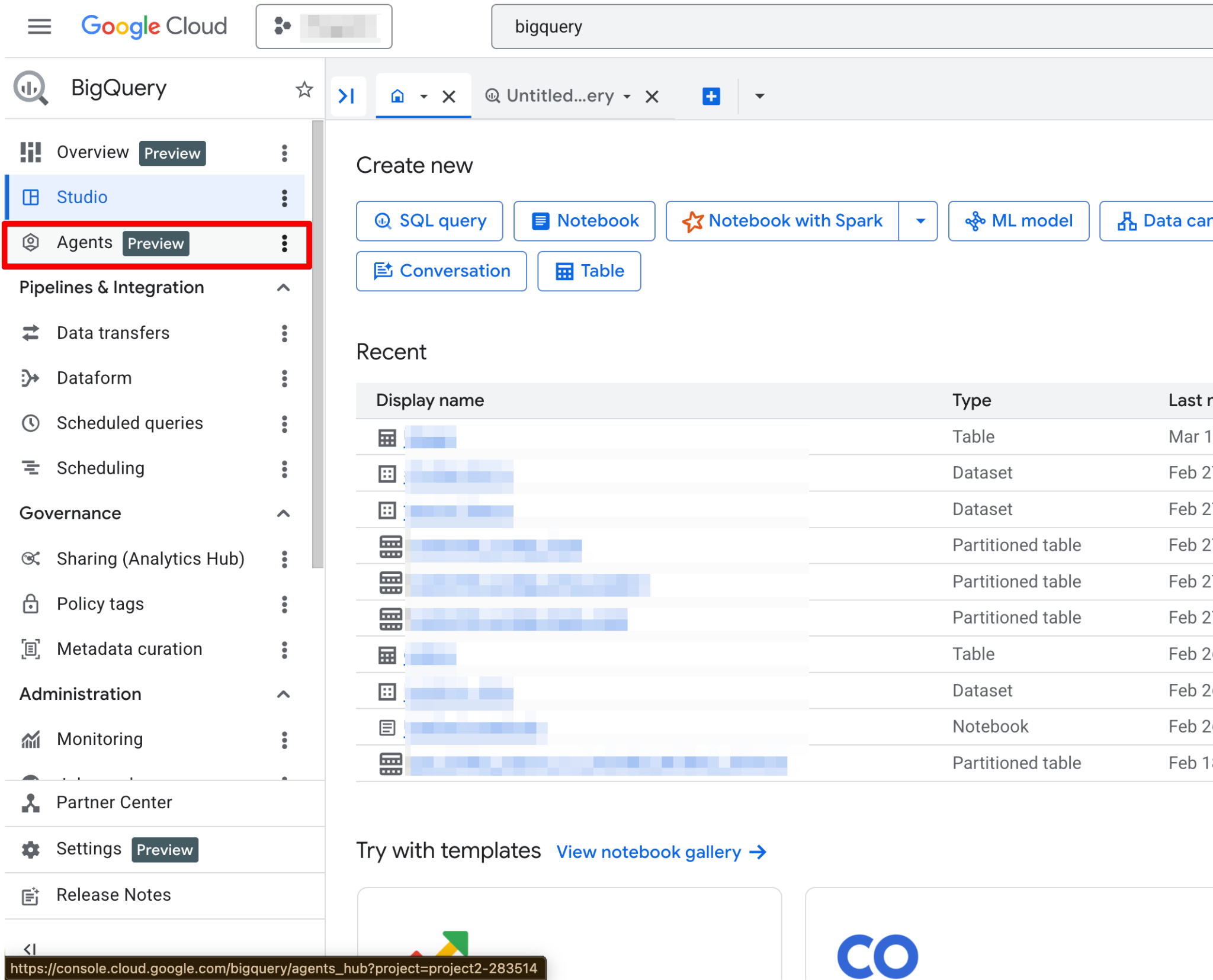
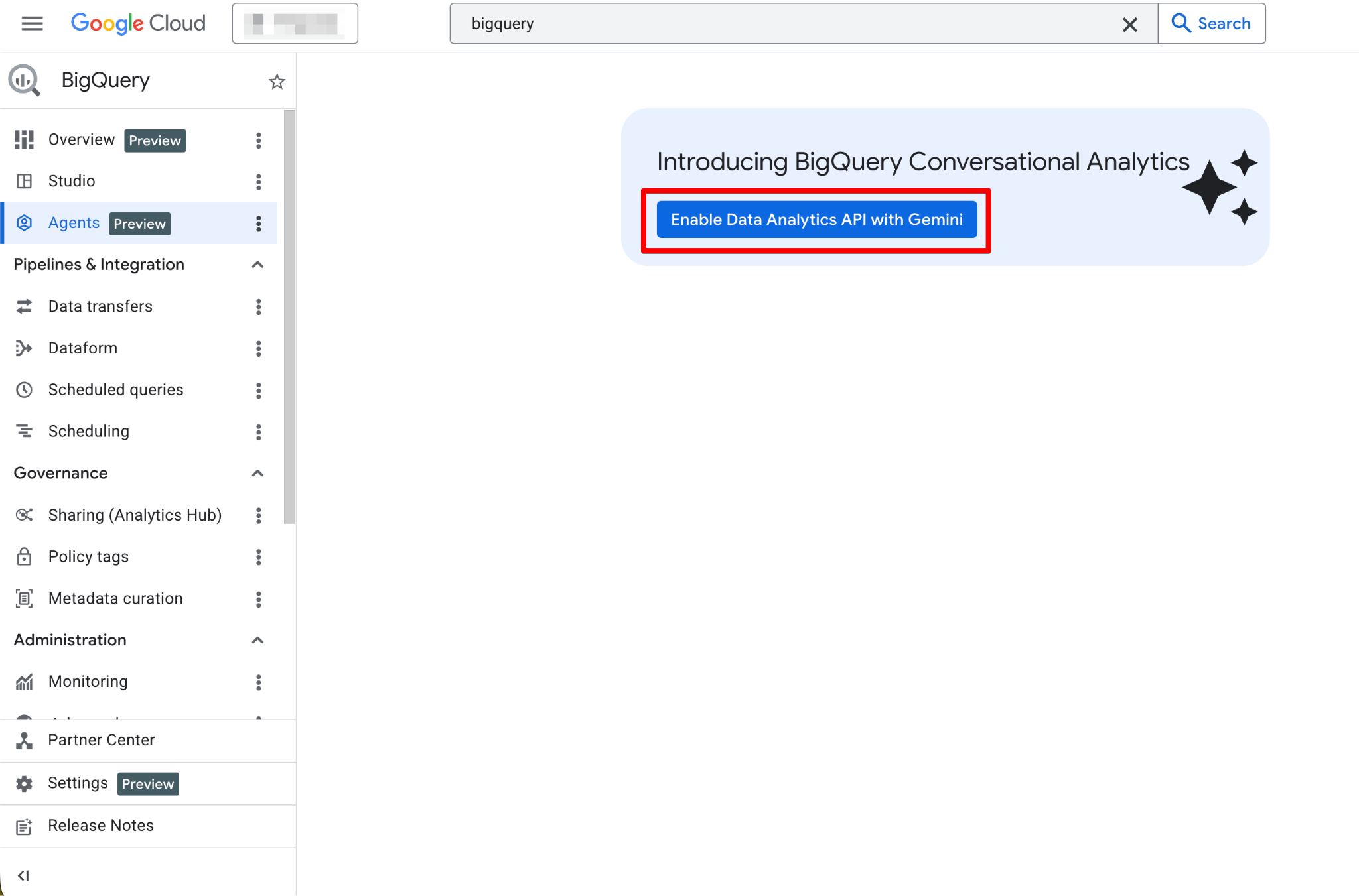
Una volta abilitate, la pagina Agents diventa completamente funzionale. Dovresti ora vedere la nuova pagina dell’agente:
L’Agent Catalog viene usato per creare, gestire e versionare i data agent all’interno di BigQuery Studio.
Ecco cosa troverai nell’Agent Catalog:
Il ciclo di vita dell’agente segue questa struttura (Bozza → Creato → Pubblicato):
Fai clic su qualsiasi scheda agente per aprirla, visualizzare i dettagli, avviare una conversazione o modificare (se hai i permessi di Owner). L’interfaccia include anche una scheda Conversations in cui puoi gestire le chat passate con agenti o sorgenti dati.
Ora che le basi sono pronte, creiamo un Data Agent da zero. Useremo il dataset bigquery-public-data.austin_bikeshare per trasformare i dati grezzi dei viaggi in un’interfaccia conversazionale. Useremo due tabelle:
bikeshare_trips — dati dettagliati a livello di viaggio
bikeshare_stations — metadati delle stazioni
Avvio della creazione dell’agente
Questi due campi ti aiutano a identificare rapidamente l’agente in seguito. Una volta impostati, sei pronto a configurare i tre blocchi fondamentali visti prima: sorgenti di conoscenza, istruzioni e (più avanti) query verificate.
Le sorgenti di conoscenza definiscono esattamente a quali dati l’agente può accedere. Meno sono e più sono mirate, migliore sarà l’accuratezza e minore il costo. Nella sezione Knowledge sources dell’editor, fai clic su Add source. Cerca austin_bikeshare e seleziona bikeshare_trips e bikeshare_stations come sorgenti.
Per ogni tabella aggiunta, fai clic su Customize.
Gemini genererà automaticamente una descrizione e suggerirà metadati delle colonne. Rivedi tutto, accetta i suggerimenti corretti, apporta eventuali modifiche e fai clic su Update.
Un errore comune è aggiungere 50 tabelle in una volta. Inizia con 2–3 tabelle core. Questo rende più semplice il debug della logica dell’agente. Potrai sempre ampliare la conoscenza in seguito, una volta che le query principali sono accurate.
Ora devi ancorare il tuo agente con delle istruzioni. Invece di scrivere un semplice prompt generico (ad es. "Rispondi alle domande sulle vendite"), l’interfaccia del data agent di BigQuery ti consente di fornire un contesto altamente strutturato per guidare la generazione delle query dell’AI. Pensalo come l’onboarding di un nuovo analista con l’esatto data dictionary della tua azienda.
Usa il campo Instructions per fornire contesto di business strutturato. Ecco un esempio completo e pronto all’uso che puoi incollare:
Sinonimi: definisci termini alternativi per le tue colonne affinché l’agente comprenda le variazioni nel linguaggio naturale. Esempio: "Journey", "Ride" e "Commute" si riferiscono tutti a un record nella tabella bikeshare_trips. "Dock", "Hub" o "Station" si riferiscono a un record nella tabella bikeshare_stations.
Campi chiave: evidenzia i campi più importanti per l’analisi. Questo indica all’agente quali colonne priorizzare quando la domanda dell’utente è ampia. Esempio: dai priorità a trip_id, start_station_name, end_station_name, subscriber_type, start_time e duration_minutes per i report generali.
Campi esclusi: specifica colonne che l’agente deve evitare rigorosamente. È utilissimo per nascondere colonne deprecate o dati irrilevanti. Esempio: non usare la colonna bike_id nella tabella bikeshare_trips per la maggior parte delle analisi, poiché raramente necessaria per domande di business.
Filtri e raggruppamenti: istruisci l’agente sui modi standard per segmentare i dati. Esempio: se non diversamente specificato, escludi sempre i viaggi con duration_minutes < 1 (sono false partenze o corse di test). Di default, raggruppa i dati per start_station_name quando l’utente chiede "per stazione" o "stazioni top".
Relazioni di join: poiché il nostro agente attinge da più tabelle, definisci esplicitamente come si connettono. Questo assicura che l’agente non indovini le chiavi esterne sbagliate. Esempio: unisci la tabella bikeshare_trips alla tabella bikeshare_stations abbinando bikeshare_trips.start_station_id a bikeshare_stations.station_id (e analogamente per end_station_id).
Puoi combinare tutto quanto sopra in un unico blocco pulito nel campo Instructions. Ecco una versione rifinita e pronta da incollare che incorpora la guida strutturata:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).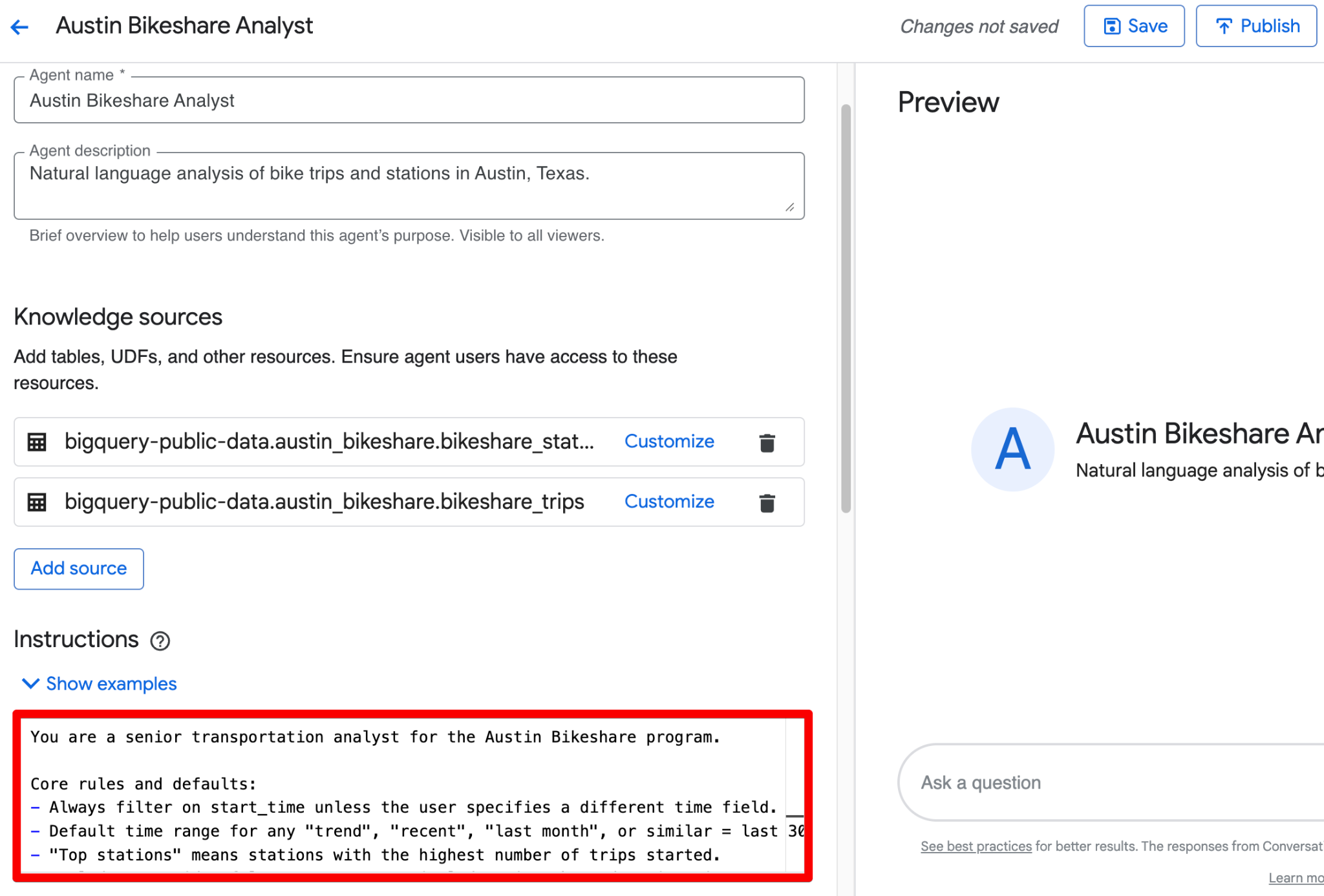
Perché è importante: Se lasci questi campi vuoti, una domanda ambigua come "Quali sono state le nostre vendite top?" potrebbe indurre l’agente a fare join con le tabelle sbagliate, attingere da account inattivi o includere dati deprecati. Strutturando le istruzioni in queste cinque categorie, ti assicuri che lo SQL generato aderisca rigorosamente alla tua logica di business stabilita.
Oltre alle istruzioni, puoi (e dovresti) definire i termini del glossario direttamente nell’agente. Questi aiutano l’agente a interpretare in modo coerente gergo aziendale, abbreviazioni e concetti derivati.
Fai clic su Add term nella sezione Glossary (in genere vicino a Instructions) e crea i termini con voce, definizione e sinonimi (separati da virgole).
Ecco i termini di glossario consigliati per il dataset Austin Bikeshare:
| Termine | Definizione | Sinonimi |
duration_minutes |
Durata del viaggio in minuti. Usa sempre questo campo per risposte e calcoli rivolti all’utente | tempo di corsa, durata del viaggio, durata, durata della corsa |
ridership |
Il numero totale (conteggio) di viaggi in bici avviati | viaggi, corse, tragitti, utilizzo biciclette, conteggio spostamenti |
peak_hours |
Ore di punta del mattino (7-9) o della sera (16-19) in base all’ora estratta da start_time |
ora di punta, ore di maggiore affluenza, periodo di alta domanda |
subscriber_type |
Tipo di utente — Subscriber (titolare di abbonamento mensile o annuale) o Customer (corsa singola | tipo utente, tipo di abbonamento, pass holder, membro, utente occasionale |
false_start |
Un viaggio molto breve (di solito inferiore a 1 minuto) probabilmente una corsa di test o uno sblocco accidentale. Questi dovrebbero normalmente essere esclusi dall’analisi | corsa di test, viaggio non valido, viaggio breve |
Puoi aggiungere altri termini secondo necessità (ad esempio per start_station_name, end_station_name o metriche derivate come “durata media del viaggio” o “corsa lunga”).
Usando i glossari, se la leadership decide di cambiare la definizione ufficiale di “Corsa lunga” a 45 minuti il prossimo trimestre, il team di data governance dovrà aggiornarla una sola volta in Dataplex. Ogni Data Agent collegato a quel glossario adotterà immediatamente la nuova logica, mantenendo la coerenza in tutta l’organizzazione.
Una volta configurate sorgenti di conoscenza, istruzioni e termini del glossario, è il momento di testare l’agente prima della pubblicazione.
Scorri sul lato destro dello schermo fino al riquadro Preview. Questa interfaccia chat live ti permette di interagire in tempo reale con l’agente mentre lo costruisci. Puoi fare domande, rivedere il ragionamento dell’agente, ispezionare lo SQL generato e iterare rapidamente.
Il riquadro Preview mostra:
Prova queste quattro query di complessità crescente (adattate all’intervallo dati del dataset fino al 2024):
Cosa vedrai nella risposta dell’agente:
Sintesi — Una spiegazione in linguaggio naturale dei risultati.
Risultato della query — Una tabella pulita con i dati (ad es., viaggi totali, stazioni principali o durata media).
Insight — Punti chiave che interpretano i risultati in un contesto di business.
SQL generato — Fai clic su Open in Editor per visualizzare la query SQL completa creata dall’agente (vedrai che filtra correttamente su start_time e applica duration_minutes >= 1 per escludere le false partenze).
Domande di follow-up suggerite — Prompt utili in fondo (ad es., “Quali sono state le 10 stazioni di partenza principali a giugno 2024?”, “Prevedi il numero giornaliero di viaggi…” ecc.).
Visualizzazione — Un grafico generato automaticamente (grafico a barre per le classifiche, come nel tuo esempio delle 5 stazioni top).
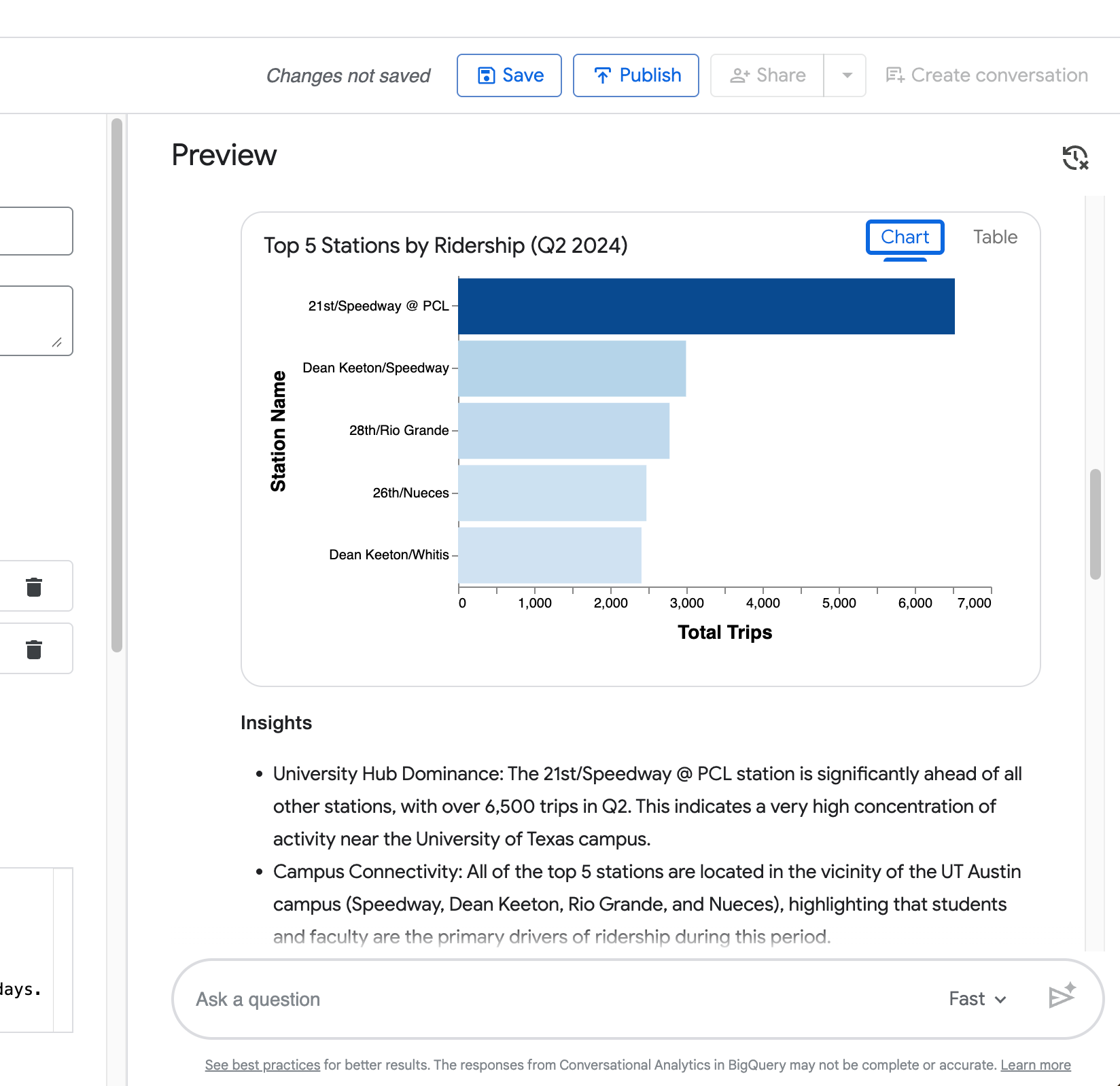
La tua quarta query (“Ora mostra lo stesso confronto ma solo per la stazione di Zilker Park”) dimostra la capacità dell’agente di mantenere il contesto della domanda precedente.
Come puoi vedere dallo screenshot seguente, restringe correttamente il confronto tra giorni feriali e weekend a Zilker Park senza che tu debba ripetere l’intera richiesta.
Suggerimenti per i test:
Quando l’agente fornisce con coerenza risposte chiare, accurate e ben strutturate, fai clic su Save in alto, quindi su Publish. Il tuo agente Austin Bikeshare Analyst è ora pronto all’uso!
Anche con buone istruzioni e termini di glossario, il tuo agente dati può comunque occasionalmente interpretare male le regole di business o generare risposte incoerenti.
Le query verificate risolvono questo problema permettendoti di insegnare esplicitamente all’agente il modo corretto di gestire le domande importanti o frequenti. Ogni query verificata consiste in una domanda in linguaggio naturale abbinata all’esatto SQL che deve essere usato.
Funzionano come esempi di alta qualità che ancorano il ragionamento dell’agente e sono uno dei modi più efficaci per passare da un agente “abbastanza buono” a uno pronto per la produzione.
Nell’editor dell’agente, scorri fino alla sezione Verified Queries. Hai due modi semplici per aggiungere query verificate:
Fai clic su Add query. Vedrai la schermata Add verified query, dove puoi:
Fai clic su View Gemini-generated suggestions. Si apre la schermata “Review suggested verified queries”, in cui Gemini propone domande pertinenti basate sulle tue sorgenti di conoscenza.
Puoi:
Un buon esempio di query verificata per il dataset Austin Bikeshare potrebbe essere:
Domanda:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;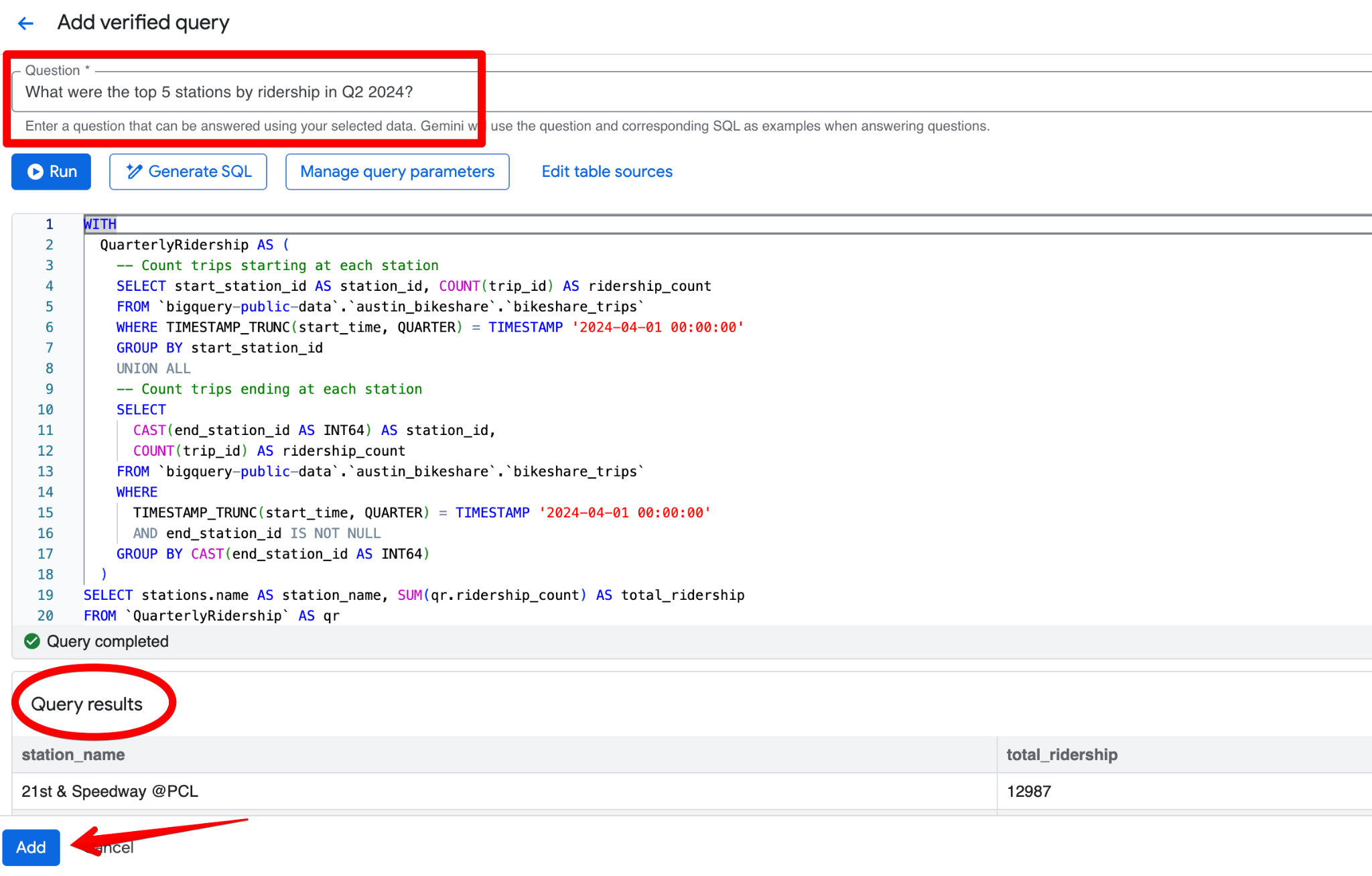
Anche quando l’agente fornisce una risposta ragionevole al primo tentativo, puoi renderla significativamente più accurata e coerente rivedendo lo SQL generato e aggiungendo query verificate.
Segui questo workflow pratico:
Poniamo che tu abbia chiesto: “Qual è stata la durata media del viaggio a giugno 2024?”. Nella risposta iniziale, l’agente restituisce 26,68 minuti ed esclude correttamente i viaggi più brevi di 1 minuto. Ora, supponiamo che la regola di business standard del team sia escludere qualsiasi viaggio più breve di 5 minuti.
Quando apri lo SQL generato (tramite Open in Editor), vedi che il filtro è solo duration_minutes >= 1.
Fai clic su Add query nella sezione Verified Queries e crea questa voce:
Domanda:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes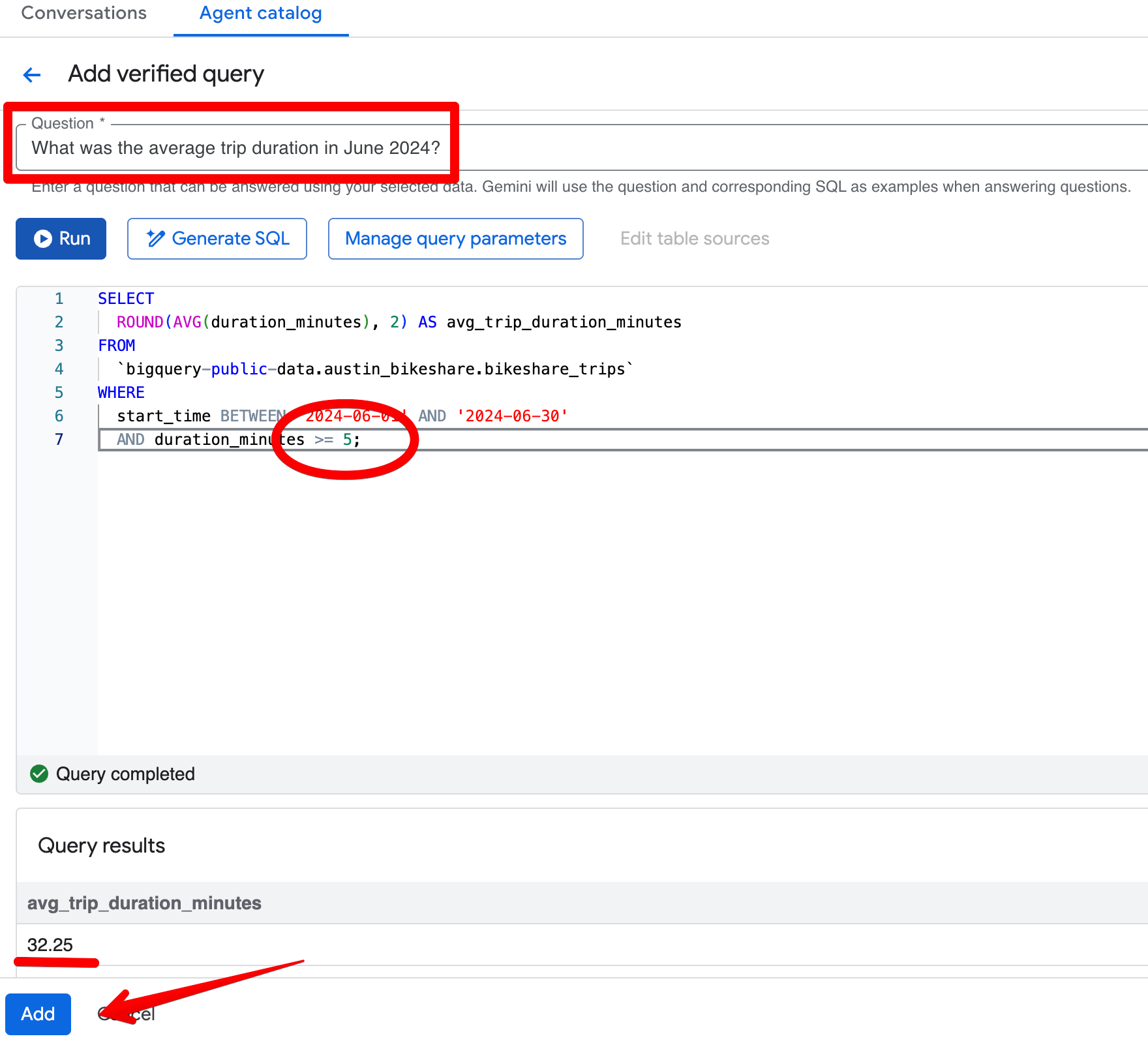
Dopo aver salvato la query verificata, riponi la stessa domanda nel riquadro Preview. L’agente ora restituisce con coerenza ~32,08 minuti e applica la tua soglia più restrittiva di 5 minuti. I risultati diventano più allineati alla tua visione di viaggi “significativi”.
L’analisi conversazionale di BigQuery si distingue dai semplici strumenti text-to-SQL grazie al supporto nativo delle funzioni BigQuery ML, dei dati non strutturati e alla condivisione semplice in tutto l’ecosistema Google Cloud.
Uno dei maggiori elementi distintivi è la capacità dell’agente di richiamare direttamente le funzioni BigQuery ML dal linguaggio naturale, andando oltre il reporting retrospettivo verso insight predittivi.
Per esempio, puoi chiedere a un agente dati di prevedere il numero giornaliero di viaggi per i prossimi 30 giorni sulla base dei trend del 2024. Richiamerà AI.FORECAST e genererà una previsione per luglio 2024 insieme a un bellissimo grafico che mostra i viaggi giornalieri storici (linea blu) e la previsione a 30 giorni (linea arancione) con un intervallo di confidenza al 95% ombreggiato.
Un altro modo in cui gli algoritmi di machine learning possono essere utili è rilevando se qualcosa non va nei tuoi dati. Quando, ad esempio, chiedi a un agente di rilevare anomalie nella ridership giornaliera durante giugno 2024, richiamerà AI.DETECT_ANOMALIES, confrontando giugno 2024 con i mesi precedenti, e restituirà una tabella di serie temporale più un grafico a linee.
In questo caso, non ha segnalato anomalie formali al 95% di confidenza ma ha evidenziato il 19 giugno come quasi-anomalia (probabilità 92,1%) con un calo evidente della ridership.
La maggior parte degli strumenti di BI conversazionale va in crisi nel momento in cui i dati non sono ordinatamente organizzati in righe e colonne. BigQuery, invece, supporta le Object Tables, che ti permettono di analizzare dati non strutturati (come PDF, immagini e log di testo grezzi) archiviati in Google Cloud Storage.
Poiché il Data Agent è alimentato dalle capacità multimodali di Gemini, può ragionare contemporaneamente sia sulle metriche strutturate sia sui file non strutturati. Questo è un enorme e unico elemento distintivo per BigQuery.
Se hai PDF di sondaggi dei rider o immagini di ispezioni delle stazioni in una object table, chiedi semplicemente: “Riepiloga i principali reclami dai PDF del sondaggio dei rider del Q2 2024.” L’agente leggerà i file non strutturati e combinerà le informazioni con i tuoi dati strutturati sui viaggi
Il tuo team dati crea e testa i Data Agent in BigQuery Studio, ma i tuoi utenti finali probabilmente lavorano in applicazioni completamente diverse. Google semplifica la disaccoppiamento dell’agente dalla GCP Console così da incontrare gli utenti di business dove già operano.
Se vuoi provare a creare da solo un’applicazione di chat personalizzata, puoi also read more in the official Introduction to Conversational Analytics in BigQuery.
Se c’è un principio chiave da ricordare, è questo: l’analisi conversazionale sposta il collo di bottiglia analitico dall’attesa del team dati al semplice porre la domanda giusta.
Questa democratizzazione non significa che i team dati siano superflui, ma che il loro ruolo sta cambiando. Un agente AI è intelligente solo quanto i binari di sicurezza che costruisci attorno a lui. L’accuratezza e la sicurezza dei tuoi agenti dati dipendono interamente dalle istruzioni, dal contesto e dall’architettura dello schema che fornisci.
Per costruire agenti conversazionali davvero efficaci, serve comunque una solida padronanza del data warehouse sottostante. Se tu o il tuo team volete rafforzare queste competenze di base e padroneggiare la piattaforma che alimenta queste funzionalità AI, dai un’occhiata al corso Introduction to BigQuery di DataCamp oggi stesso!
Corsi Google Cloud
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

