Tracks
Google Cloud Digital Leader
8 ชม.
หากทำงานในทีมข้อมูล สถานการณ์นี้น่าจะคุ้นเคย: แบ็กลอกเต็มไปด้วยคำขอเฉพาะกิจ ผู้ใช้ธุรกิจมักต้องการรายงานแบบเดิมแต่เปลี่ยนเงื่อนไขเล็กน้อย เช่น “ช่วยจัดกลุ่มตามหมวดหมู่สินค้าได้ไหม?” หรือ “เทียบกับเดือนที่แล้วเป็นอย่างไร?” ระหว่างรอคิวคำตอบ วิศวกรและนักวิเคราะห์ข้อมูลต้องจมอยู่กับงาน SQL ซ้ำๆ
ด้วย Conversational Analytics ใน BigQuery คุณสามารถย้ายคอขวดนี้ได้เสียที ฟีเจอร์นี้นำเอาเอนจินให้เหตุผลที่ขับเคลื่อนด้วย AI มาไว้ใน BigQuery Studio โดยตรง ทำให้ผู้ใช้สามารถถามคำถามด้วยภาษาธรรมชาติและรับข้อมูล แผนภูมิ และ SQL ที่สร้างขึ้นได้ทันที
ในคู่มือนี้ คุณจะได้เรียนรู้วิธีตั้งค่าและใช้ Conversational Analytics ใน BigQuery คุณจะสร้าง กำหนดค่า และปรับแต่ง Data Agent ของตนเอง เพื่อให้องค์กรสามารถพูดคุยกับข้อมูลได้อย่างปลอดภัย
Conversational Analytics คือการเปลี่ยนจากการสืบค้นข้อมูลด้วย SQL แบบแมนนวลมาเป็นการสนทนาด้วยภาษาธรรมชาติ แทนที่จะเขียนคำสั่ง SELECT คุณสนทนากับ Data Agent ที่เข้าใจบริบทธุรกิจและส่งคำตอบที่อ้างอิงจากตารางจริงของคุณ
นี่ไม่ใช่แค่ตัวแปลงข้อความเป็น SQL พื้นๆ แต่เป็นก้าวสำคัญสู่การเข้าถึงข้อมูลสำหรับทุกคนอย่างแท้จริง
ช่วยให้ผู้ใช้ที่ไม่เชี่ยวชาญเทคนิคเข้าถึงอินไซต์แบบเรียลไทม์ได้อย่างอิสระ และช่วยให้มืออาชีพด้านข้อมูลสำรวจชุดข้อมูลและทำรายงานอัตโนมัติได้รวดเร็ว
หัวใจของ Conversational Analytics ใน BigQuery คือเอนจินให้เหตุผลที่ขับเคลื่อนด้วยโมเดลตระกูล Gemini Data Agent ใช้ไปป์ไลน์แบบมีโครงสร้างหลายขั้นตอนเพื่อให้มั่นใจว่าอินไซต์ตั้งอยู่บนบริบทข้อมูลเฉพาะของคุณ:
Google Cloud มี Conversational Analytics ให้ใช้งานในหลายชั้นของสแตกข้อมูล การเลือกจุดเริ่มต้นที่เหมาะสมขึ้นอยู่กับผู้ใช้ของคุณและตำแหน่งที่ตรรกะทางธุรกิจอาศัยอยู่:
|
ฟีเจอร์ |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (ผ่าน BigQuery Agents) |
|
เหมาะสำหรับ |
ทีมข้อมูล นักวิเคราะห์ และนักพัฒนาที่สร้างแอปพลิเคชันแบบกำหนดเอง |
ผู้ใช้ธุรกิจที่ต้องการอินไซต์พร้อมสำหรับแดชบอร์ดภายใต้การกำกับดูแล |
ผู้ใช้ธุรกิจที่ต้องการรายงาน BI แบบเบา |
|
วิธียึดโยงข้อมูล |
สคีมาคลังข้อมูลโดยตรง เมทาดาทาของตาราง และคิวรีที่ตรวจยืนยันแล้ว |
LookML (เลเยอร์เชิงความหมาย) |
เชื่อมต่อโดยตรงกับ BigQuery Data Agents ที่สร้างไว้ล่วงหน้า |
|
การเข้าถึงข้อมูล |
วิเคราะห์ข้อมูลเชิงโครงสร้าง คาดการณ์ (ML) และไม่เป็นโครงสร้างได้ |
ข้อมูลเชิงโครงสร้างที่โมเดลไว้เคร่งครัด |
ข้อมูลเชิงโครงสร้าง |
|
สถานะการเปิดตัว |
พรีวิว (ณ พฤษภาคม 2026) |
พร้อมใช้งานทั่วไป |
พรีวิว |
ควรเลือกเส้นทางใด?
บทเรียนนี้เน้นที่ BigQuery ซึ่งเป็นวิธีที่เร็วที่สุดสำหรับทีมข้อมูลในการสร้างต้นแบบและนำ Agent ขึ้นโปรดักชัน ณ แหล่งที่ข้อมูลอาศัยอยู่
ควรเข้าใจสถาปัตยกรรมของ Data Agent ก่อนตั้งค่า ในสภาพแวดล้อม Google Cloud Data Agent คือเลเยอร์นามธรรมส่วนกลาง ที่ผสานทรัพยากรของ BigQuery เข้ากับความสามารถในการให้เหตุผลของโมเดลตระกูล Gemini
แทนที่จะเปิดเผยตารางดิบโดยตรง Data Agent จะกำหนดค่าทุกสิ่งที่โมเดลต้องใช้ในการตีความคำถาม สร้าง SQL ที่ปลอดภัย และคืนคำตอบที่เชื่อถือได้ การผสานแหล่งข้อมูล คำสั่ง และตรรกะที่ตรวจยืนยันแล้วนี้ ทำให้ Conversational Analytics ของ BigQuery เชื่อถือได้มากกว่าเครื่องมือแปลงข้อความเป็น SQL ทั่วไป
แหล่งความรู้คือชั้นฐานของ Data Agent ใดๆ โดยกำหนดอย่างชัดเจนว่า Agent ได้รับอนุญาตให้เข้าถึงและสืบค้นข้อมูลใดบ้าง
ประเภททรัพยากร: ตาราง มุมมอง (Views) และฟังก์ชันที่ผู้ใช้กำหนด (UDF) สามารถเชื่อมต่อเป็นแหล่งความรู้ได้
การขยายสเกล: สามารถเชื่อมต่อหลายแหล่งความรู้กับ Agent เดียว ทำให้ Agent ผสานข้อมูลจากหลายด้านธุรกิจได้
การควบคุมการเข้าถึง: การกำหนดแหล่งความรู้เฉพาะช่วยให้แน่ใจว่า Agent ทำงานเฉพาะภายใต้ข้อมูลที่ได้รับอนุญาต
ความฉลาดของ Agent ขึ้นอยู่กับบริบทที่ให้ไว้ นี่คือกุญแจสำคัญในการทำให้โมเดลทั่วไปเข้าใจภาษาของบริษัท
ด้วยการกำหนดคำสั่งเฉพาะ คำพ้อง และอภิธานศัพท์ธุรกิจ Agent จะยึดโยงอยู่ในโดเมนเฉพาะ ตัวอย่างเช่น สามารถสอนได้ว่า “Top Customers” หมายถึงผู้ใช้ที่มีมูลค่าตลอดอายุการใช้งาน (LTV) มากกว่า $1,000
องค์ประกอบสำคัญสำหรับการยึดโยง:
คำสั่งแบบกำหนดเอง: ให้คำแนะนำระดับสูง เช่น “ตัดบัญชีทดสอบภายในออกจากรายงานรายได้เสมอ”
อภิธานศัพท์ธุรกิจ: แม็ปคำทางเทคนิคเป็นภาษาธรรมชาติ เช่น store_id เป็น “สาขา”
เมทาดาทาของฟิลด์: คำอธิบายช่วยให้ Agent เข้าใจความแตกต่างของตัวแปร เช่น “รายได้รวม” เทียบกับ “กำไรสุทธิ”
คำสั่งและเมทาดาทาดียิ่งขึ้น ความแม่นยำของ Agent ก็ยิ่งสูงขึ้น
Verified Queries (ชื่อเดิม Golden Queries) คือคู่คำถาม-คำตอบที่กำหนดไว้ล่วงหน้าซึ่งเป็นแหล่งความจริง โดยแม็ปคำถามเฉพาะกับ SQL ที่ผู้เชี่ยวชาญตรวจทานแล้ว Agent จะใช้เส้นทางการ Join และตัวกรองที่ถูกต้องสำหรับ KPI สำคัญ
คิวรีเหล่านี้สามารถรวมฟังก์ชัน BigQuery ML (BQML) ได้ ทำให้ Agent จัดการคำขอขั้นสูง เช่น การคาดการณ์การยกเลิกหรือพยากรณ์ยอดขาย โดยใช้พารามิเตอร์โมเดลตามที่นักวิทยาศาสตร์ข้อมูลกำหนด เมื่อยืนยันแล้ว ทรัพยากรเหล่านี้จะถูกจัดการผ่าน Dataplex Universal Catalog เพื่อความสอดคล้องทั้งองค์กร
เมื่อเข้าใจองค์ประกอบหลักแล้ว ต่อไปมาลงมือสร้างและกำหนดค่า Data Agent ตัวแรกกัน
ก่อนเริ่มตามบทเรียน โปรดตรวจสอบว่ามีสิ่งต่อไปนี้:
ก่อนสร้าง Agent แรก ต้องกำหนดค่าโปรเจกต์ Google Cloud และตรวจสอบว่าบัญชีผู้ใช้มีสิทธิ์ที่จำเป็น Data Agents ทำงานเป็นเลเยอร์บนข้อมูลที่มีอยู่ ดังนั้นการกำหนดค่า IAM (Identity and Access Management) ที่ถูกต้องจึงสำคัญต่อความปลอดภัยและการทำงาน
ทำตามขั้นตอนนี้:
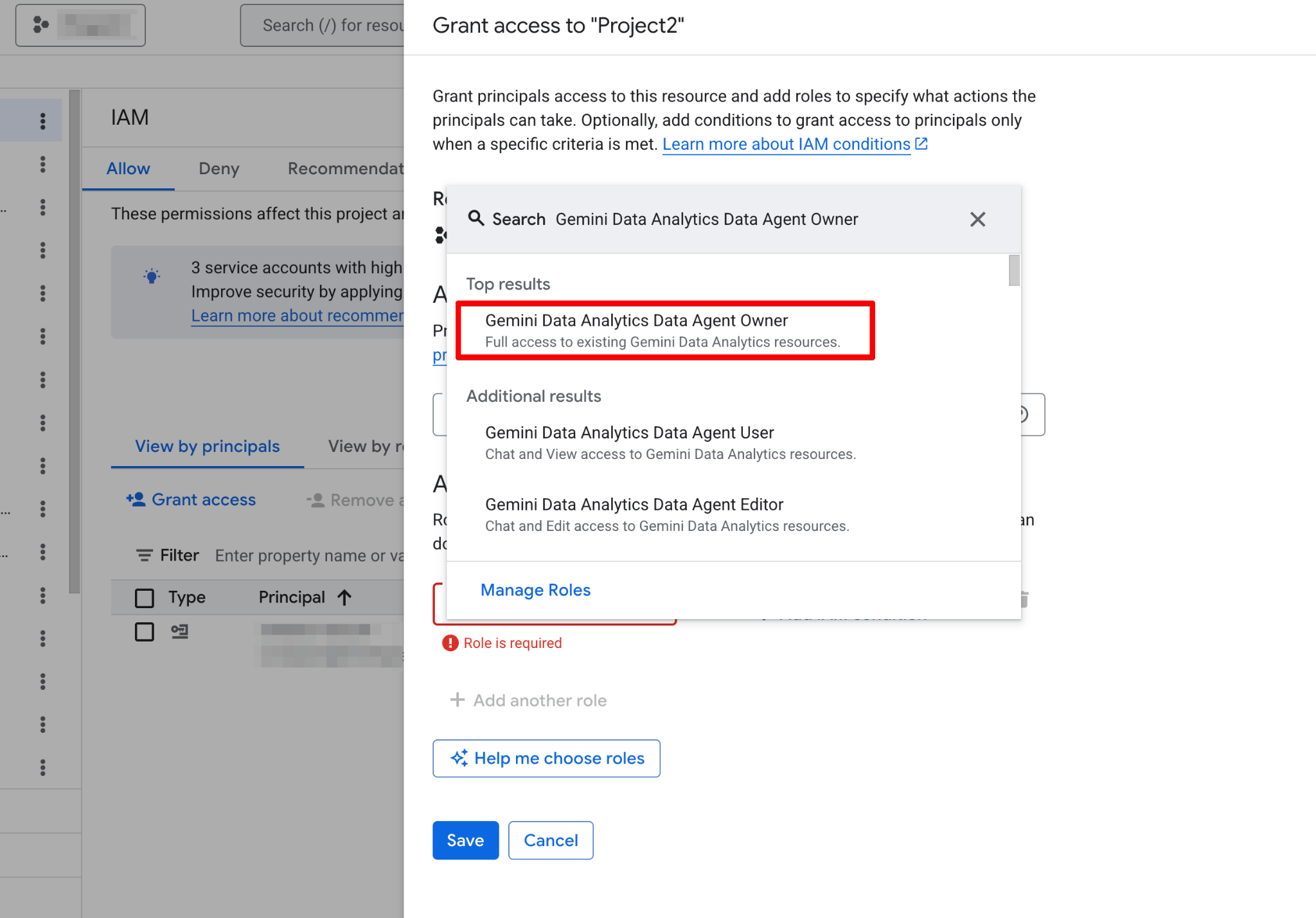
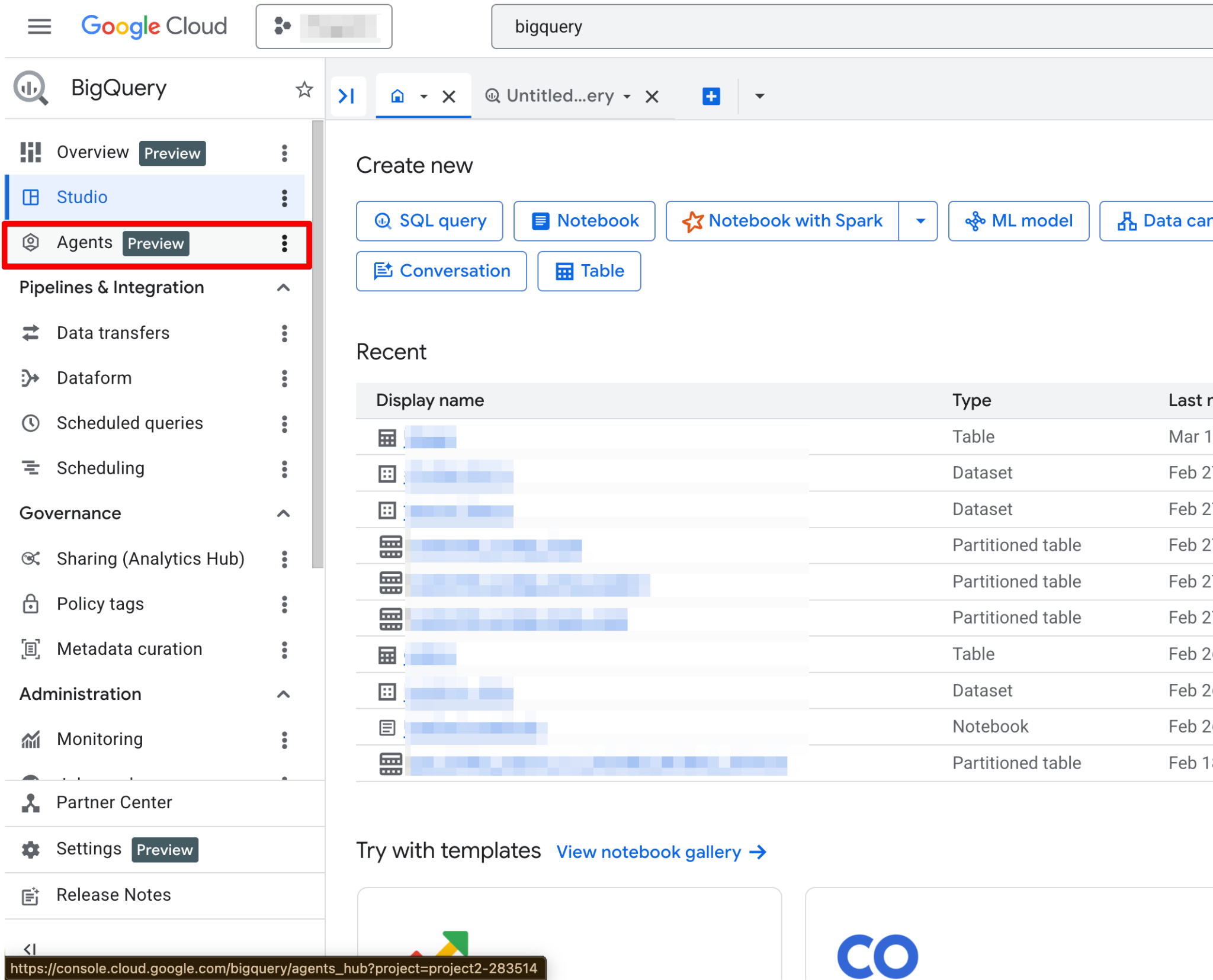
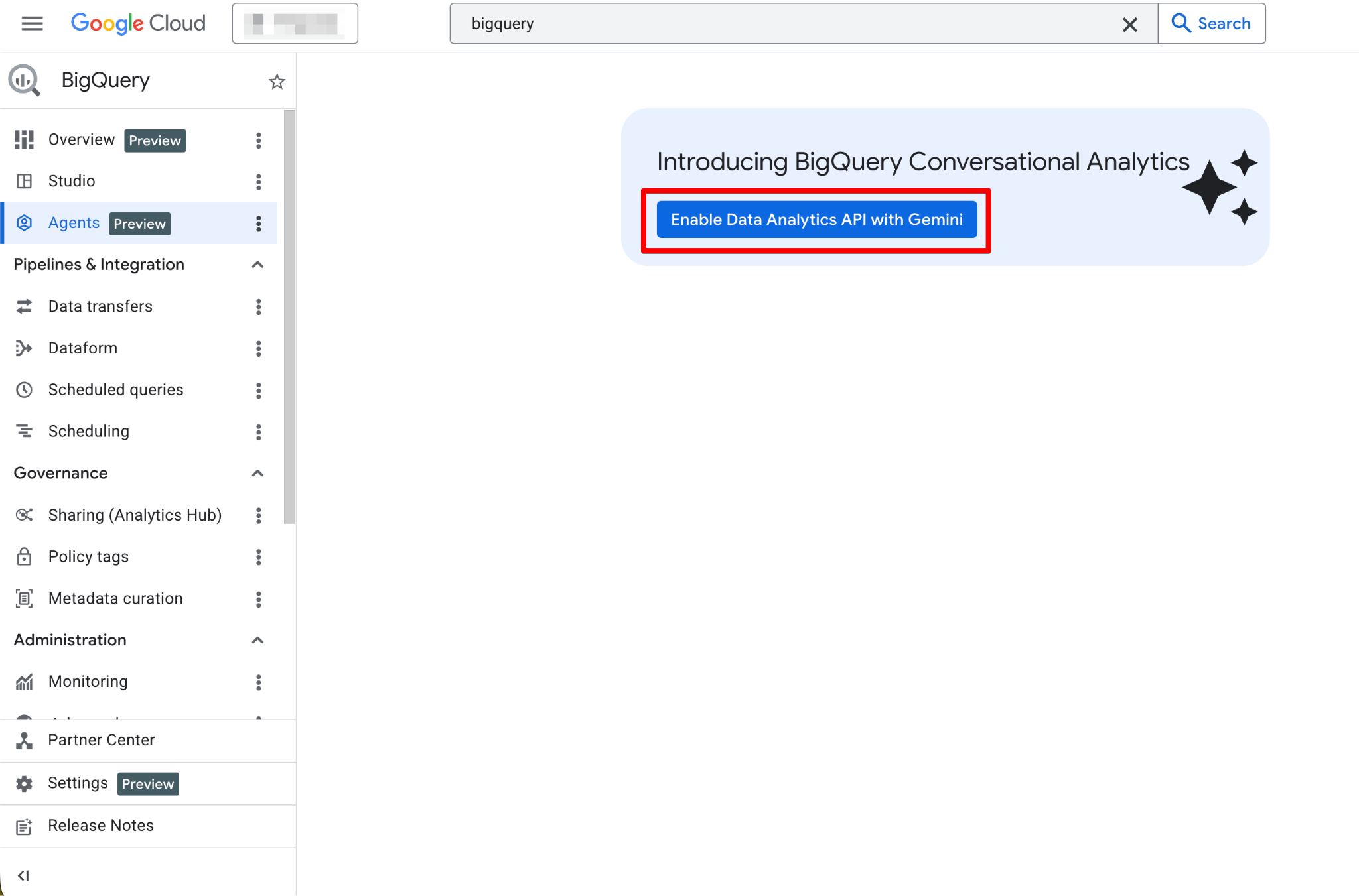
เมื่อเปิดใช้แล้ว หน้า Agents จะทำงานได้เต็มที่ ควรเห็นหน้าสร้าง Agent ใหม่ดังนี้:
Agent Catalog ใช้สำหรับสร้าง จัดการ และจัดเวอร์ชันของ Data Agent ภายใน BigQuery Studio
สิ่งที่พบใน Agent Catalog:
วงจรชีวิตของ Agent มีโครงสร้างดังนี้ (Draft → Created → Published):
คลิกการ์ดของ Agent ใดๆ เพื่อเปิด ดูรายละเอียด เริ่มสนทนา หรือแก้ไข (หากมีสิทธิ์ Owner) อินเทอร์เฟซยังมีแท็บ Conversations สำหรับจัดการแชตที่ผ่านมาโดยใช้งานกับ Agent หรือแหล่งข้อมูล
เมื่อวางรากฐานเรียบร้อย มาสร้าง Data Agent ตั้งแต่เริ่มกัน เราจะใช้ชุดข้อมูล bigquery-public-data.austin_bikeshare เพื่อแปลงข้อมูลทริปดิบเป็นอินเทอร์เฟซแบบสนทนา โดยใช้สองตาราง:
bikeshare_trips — ข้อมูลระดับทริปอย่างละเอียด
bikeshare_stations — เมทาดาทาของสถานี
เริ่มต้นสร้าง Agent
สองช่องนี้ช่วยให้ระบุ Agent ได้รวดเร็วภายหลัง เมื่อตั้งค่าแล้ว ก็พร้อมกำหนดสามองค์ประกอบหลักที่กล่าวไปก่อนหน้า: แหล่งความรู้ คำสั่ง และ (ภายหลัง) คิวรีที่ตรวจยืนยัน
แหล่งความรู้กำหนดโดยตรงว่า Agent เข้าถึงข้อมูลใดได้ ยิ่งแหล่งมีจำนวนน้อยและโฟกัสมากเท่าไร ความแม่นยำยิ่งดี ต้นทุนยิ่งต่ำ ในส่วน Knowledge sources ของ editor คลิก Add source ค้นหา austin_bikeshare และเลือก bikeshare_trips และ bikeshare_stations เป็นแหล่งข้อมูล
สำหรับแต่ละตารางที่เพิ่ม คลิก Customize.
Gemini จะสร้างคำอธิบายอัตโนมัติและแนะนำเมทาดาทาคอลัมน์ ตรวจสอบทั้งหมด ยอมรับคำแนะนำที่ถูกต้อง ปรับแก้ตามต้องการ แล้วคลิก Update
ข้อผิดพลาดที่พบบ่อยคือการเพิ่มตาราง 50 ตารางในครั้งเดียว ควรเริ่มจาก 2–3 ตารางหลัก จะช่วยให้แก้ไขตรรกะของ Agent ได้ง่าย คุณสามารถขยายแหล่งความรู้ภายหลังเมื่อคิวรีหลักแม่นยำแล้ว
ถัดไปคือการยึดโยง Agent ด้วยคำสั่ง แทนที่จะเขียนพรอมต์ทั่วไป (เช่น “ตอบคำถามเกี่ยวกับยอดขาย”) อินเทอร์เฟซของ Data Agent ใน BigQuery อนุญาตให้ให้บริบทที่มีโครงสร้างสูงเพื่อชี้นำการสร้างคิวรีของ AI จงคิดเสียว่าเหมือนปูพื้นฐานให้กับนักวิเคราะห์ใหม่ด้วยพจนานุกรมข้อมูลของบริษัทคุณ
ใช้ช่อง Instructions เพื่อให้บริบททางธุรกิจที่มีโครงสร้าง นี่คือตัวอย่างเต็มรูปแบบพร้อมใช้งานที่สามารถวางได้ทันที:
คำพ้อง: กำหนดคำทดแทนของคอลัมน์ เพื่อให้ Agent เข้าใจความหลากหลายของภาษาธรรมชาติ ตัวอย่าง: “Journey”, “Ride” และ “Commute” ล้วนหมายถึงเรคคอร์ดในตาราง bikeshare_trips ส่วน “Dock”, “Hub” หรือ “Station” หมายถึงเรคคอร์ดในตาราง bikeshare_stations
ฟิลด์สำคัญ: เน้นฟิลด์ที่สำคัญที่สุดสำหรับการวิเคราะห์ เพื่อบอก Agent ว่าควรให้ความสำคัญคอลัมน์ใดเมื่อคำถามของผู้ใช้กว้าง ตัวอย่าง: ให้ความสำคัญกับ trip_id, start_station_name, end_station_name, subscriber_type, start_time และ duration_minutes สำหรับรายงานทั่วไป
ฟิลด์ที่ยกเว้น: ระบุคอลัมน์ที่ Agent ควรหลีกเลี่ยงอย่างเคร่งครัด มีประโยชน์อย่างยิ่งในการซ่อนคอลัมน์ที่เลิกใช้หรือข้อมูลที่ไม่เกี่ยวข้อง ตัวอย่าง: ไม่ใช้คอลัมน์ bike_id ในตาราง bikeshare_trips สำหรับการวิเคราะห์ส่วนใหญ่ เนื่องจากแทบไม่จำเป็นต่อคำถามทางธุรกิจ
การกรองและการจัดกลุ่ม: สั่ง Agent เกี่ยวกับวิธีการแบ่งข้อมูลมาตรฐาน ตัวอย่าง: เว้นแต่ระบุเป็นอย่างอื่น ให้ตัดทริปที่ duration_minutes < 1 ออกเสมอ (เหล่านี้คือการเริ่มเทียมหรือการทดลองขี่) และจัดกลุ่มตาม start_station_name โดยปริยายเมื่อผู้ใช้ถามว่า “ตามสถานี” หรือ “สถานีอันดับต้นๆ”
ความสัมพันธ์การ Join: เนื่องจาก Agent ของเราดึงจากหลายตาราง จึงควรกำหนดวิธีเชื่อมต่ออย่างชัดเจน เพื่อไม่ให้ Agent เดาผิดคีย์ต่างประเทศ ตัวอย่าง: Join ตาราง bikeshare_trips กับ bikeshare_stations โดยแม็ป bikeshare_trips.start_station_id เข้ากับ bikeshare_stations.station_id (และในทำนองเดียวกันสำหรับ end_station_id)
รวมทั้งหมดข้างต้นเป็นบล็อกเดียวที่สะอาดในช่อง Instructions ได้เลย นี่คือเวอร์ชันปรับแต่งพร้อมวางที่รวมคำแนะนำแบบมีโครงสร้างไว้แล้ว:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).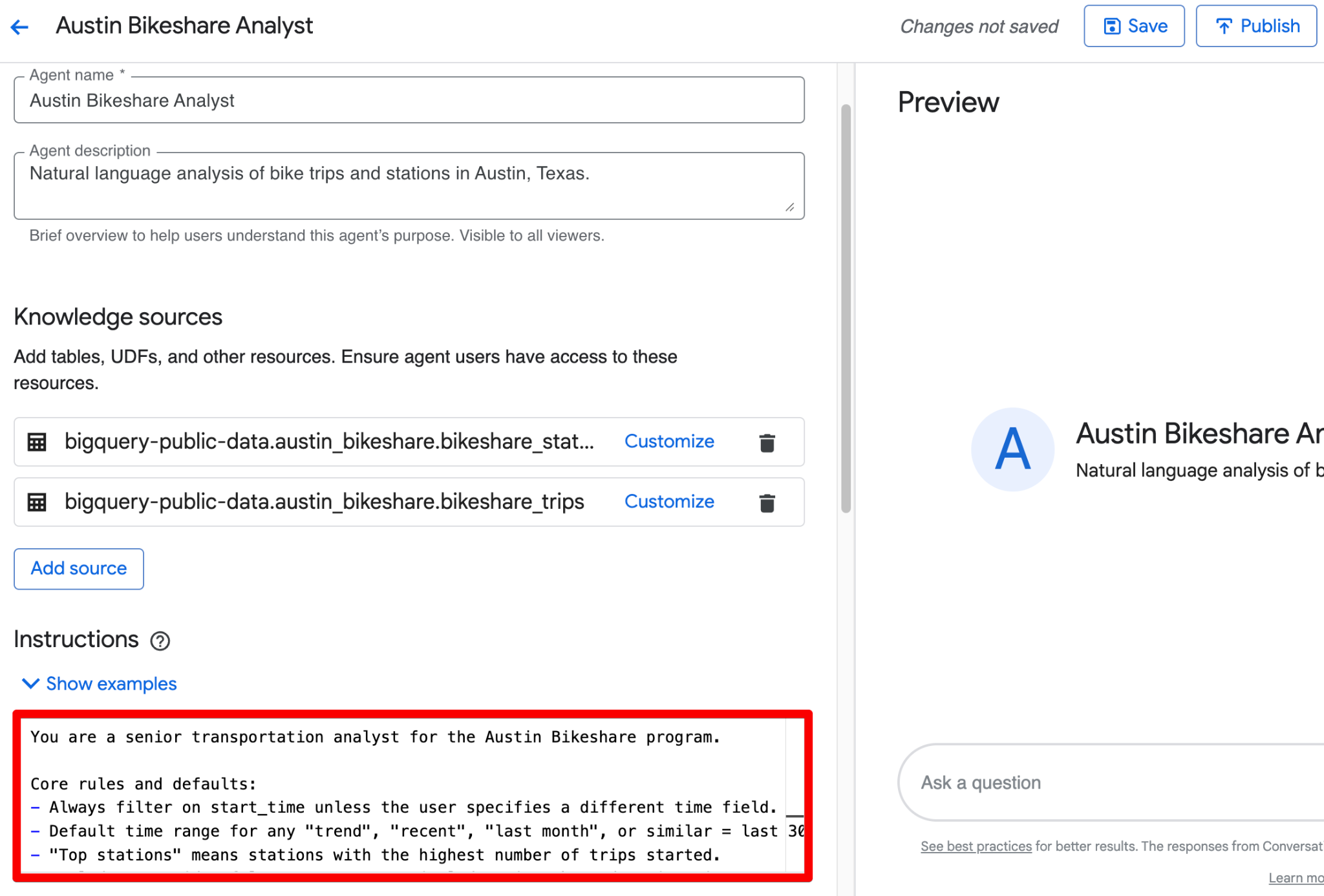
เหตุผลที่สำคัญ: หากปล่อยช่องเหล่านี้ว่างไว้ คำถามกำกวมอย่าง “ยอดขายสูงสุดของเราคืออะไร?” อาจทำให้ Agent Join ตารางผิด ดึงจากบัญชีที่ไม่ใช้งาน หรือรวมข้อมูลที่เลิกใช้แล้ว ด้วยการจัดโครงสร้างคำสั่งทั้งห้าหมวดนี้ คุณรับประกันได้ว่า SQL ที่สร้างจะยึดตามตรรกะธุรกิจที่กำหนดไว้
นอกเหนือจากคำสั่งแล้ว ควรกำหนดคำในอภิธานศัพท์โดยตรงใน Agent ด้วย เพื่อช่วยให้ Agent ตีความศัพท์ทางธุรกิจ ตัวย่อ และแนวคิดที่อนุมานได้อย่างสอดคล้อง
คลิก Add term ในส่วน Glossary (มักอยู่ใกล้ Instructions) และสร้างคำ โดยกำหนด term, definition และ synonyms (คั่นด้วยจุลภาค)
นี่คือคำที่แนะนำสำหรับชุดข้อมูล Austin Bikeshare:
| คำ | คำนิยาม | คำพ้อง |
duration_minutes |
ระยะเวลาทริปเป็นนาที ใช้ตัวนี้เสมอสำหรับคำตอบและการคำนวณที่ผู้ใช้เห็น | ride time, trip length, duration, ride duration |
ridership |
จำนวนนับของทริปจักรยานที่เริ่มต้นทั้งหมด | trips, rides, journeys, bike usage, commute count |
peak_hours |
ชั่วโมงเร่งด่วนเช้า (7-9) หรือเย็น (16-19) จากชั่วโมงที่ดึงออกมาจาก start_time |
rush hour, busy hours, high demand period |
subscriber_type |
ประเภทผู้ขับขี่ — Subscriber (ผู้ถือบัตรรายเดือนหรือรายปี) หรือ Customer (ขี่ครั้งเดียว | user type, membership type, pass holder, member, casual rider |
false_start |
ทริปสั้นมาก (มักน้อยกว่า 1 นาที) ที่น่าจะเป็นการทดลองขี่หรือปลดล็อกโดยไม่ตั้งใจ ควรตัดออกจากการวิเคราะห์ตามปกติ | test ride, invalid trip, short trip |
สามารถเพิ่มคำอื่นตามต้องการ (เช่น สำหรับ start_station_name, end_station_name หรือเมตริกที่คำนวณ เช่น “average trip duration” หรือ “long ride”)
ด้วยการใช้อภิธานศัพท์ หากผู้บริหารตัดสินใจเปลี่ยนคำนิยามทางการของ “Long Ride” เป็น 45 นาทีในไตรมาสหน้า ทีมกำกับดูแลข้อมูลเพียงอัปเดตครั้งเดียวใน Dataplex Data Agent ทุกตัวที่เชื่อมต่อกับอภิธานศัพท์นั้นจะรับตรรกะใหม่ทันที ทำให้คงความสอดคล้องทั่วทั้งองค์กร
เมื่อกำหนดค่าแหล่งความรู้ คำสั่ง และอภิธานศัพท์เรียบร้อย ถึงเวลาทดสอบ Agent ก่อนเผยแพร่
เลื่อนไปยังพาเนลพรีวิวทางขวา อินเทอร์เฟซแชตแบบสดนี้เปิดให้โต้ตอบกับ Agent แบบเรียลไทม์ระหว่างสร้าง สามารถถามคำถาม ทบทวนการให้เหตุผลของ Agent ตรวจสอบ SQL ที่สร้าง และไอเทอเรตได้รวดเร็ว
พรีวิวแสดง:
ลอง 4 คำถามตามลำดับความซับซ้อนที่เพิ่มขึ้น (ปรับให้สอดคล้องกับช่วงข้อมูลถึงปี 2024):
สิ่งที่คุณจะเห็นในคำตอบของ Agent:
สรุป — คำอธิบายผลลัพธ์ด้วยภาษาธรรมชาติ
ผลลัพธ์คิวรี — ตารางข้อมูลอ่านง่าย (เช่น จำนวนทริป สถานีอันดับต้นๆ หรือค่าเฉลี่ยระยะเวลา)
อินไซต์ — บูลเล็ตพอยต์สรุปแง่คิดในบริบทธุรกิจ
SQL ที่สร้าง — คลิก Open in Editor เพื่อดูคิวรี SQL ฉบับเต็มที่ Agent สร้าง (จะเห็นว่ากรองตาม start_time และใช้ duration_minutes >= 1 เพื่อตัดการเริ่มเทียมออก)
คำถามติดตามที่แนะนำ — พรอมต์ที่เป็นประโยชน์ด้านล่าง (เช่น “สถานีเริ่มต้น 10 อันดับในมิถุนายน 2024 คืออะไร?”, “พยากรณ์จำนวนทริปรายวัน…” เป็นต้น)
ภาพข้อมูล — แผนภูมิที่สร้างอัตโนมัติ (แท่งสำหรับการจัดอันดับ ดังเช่นตัวอย่างสถานี 5 อันดับ)
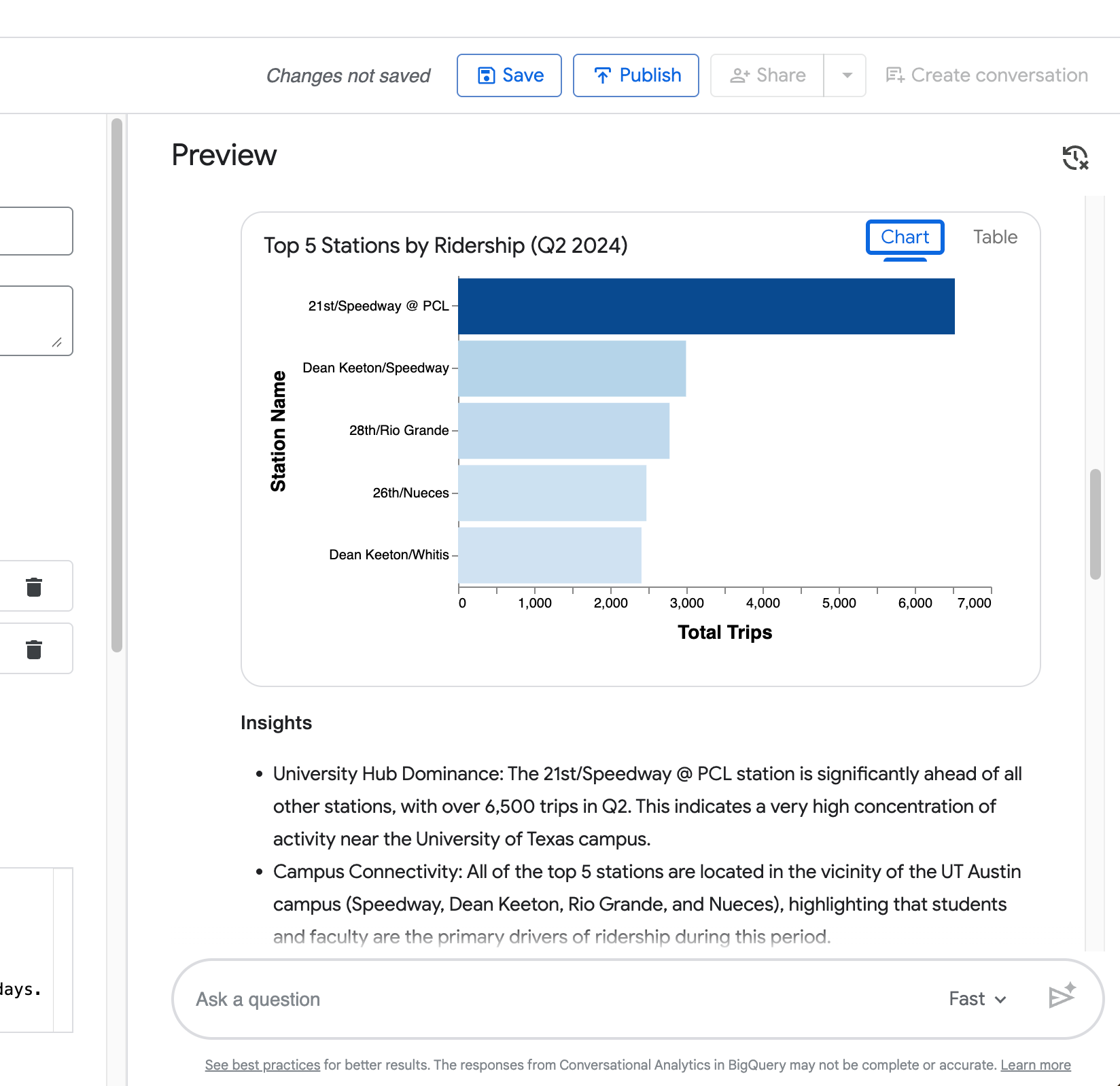
คำถามที่สี่ (“แสดงการเปรียบเทียบเดิมเฉพาะสถานี Zilker Park”) แสดงความสามารถของ Agent ในการจดจำบริบทจากคำถามก่อนหน้า
ดังภาพหน้าจอต่อไปนี้ จะเห็นว่ามีการจำกัดการเปรียบเทียบระยะเวลาในวันธรรมดากับสุดสัปดาห์ให้แคบลงเฉพาะ Zilker Park ได้อย่างถูกต้องโดยไม่ต้องพิมพ์คำขอซ้ำทั้งหมด
เคล็ดลับการทดสอบ:
เมื่อ Agent ให้คำตอบที่ชัดเจน แม่นยำ และมีโครงสร้างสม่ำเสมอ ให้คลิก Save ด้านบน จากนั้น Publish Agent “Austin Bikeshare Analyst” ของคุณก็พร้อมใช้งานแล้ว!
แม้มีคำสั่งและอภิธานศัพท์ที่ดี Data Agent อาจตีความกฎธุรกิจผิดหรือให้คำตอบไม่สอดคล้องเป็นครั้งคราว
Verified Queries แก้ปัญหานี้โดยเปิดโอกาสให้สอน Agent อย่างชัดเจนว่าควรจัดการคำถามสำคัญหรือคำถามที่พบบ่อยอย่างไร แต่ละรายการประกอบด้วยคำถามภาษาธรรมชาติคู่กับ SQL ที่ถูกต้องตามควรใช้
สิ่งเหล่านี้ทำหน้าที่เป็นตัวอย่างคุณภาพสูงที่ยึดตรรกะการให้เหตุผลของ Agent และเป็นหนึ่งในวิธีที่ได้ผลที่สุดในการยกระดับจาก Agent ที่ “พอใช้” ไปสู่ระดับพร้อมใช้งานจริง
ใน editor ของ Agent เลื่อนไปที่ส่วน Verified Queries คุณมี 2 วิธีง่ายๆ ในการเพิ่ม:
คลิก Add query จะเห็นหน้าจอ Add verified query ซึ่งคุณสามารถ:
คลิก View Gemini-generated suggestions จะเปิดหน้าจอ “Review suggested verified queries” ซึ่ง Gemini จะเสนอคำถามที่เกี่ยวข้องตามแหล่งความรู้ของคุณ
คุณสามารถ:
ตัวอย่าง Verified Query ที่ดีสำหรับชุดข้อมูล Austin Bikeshare:
Question:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;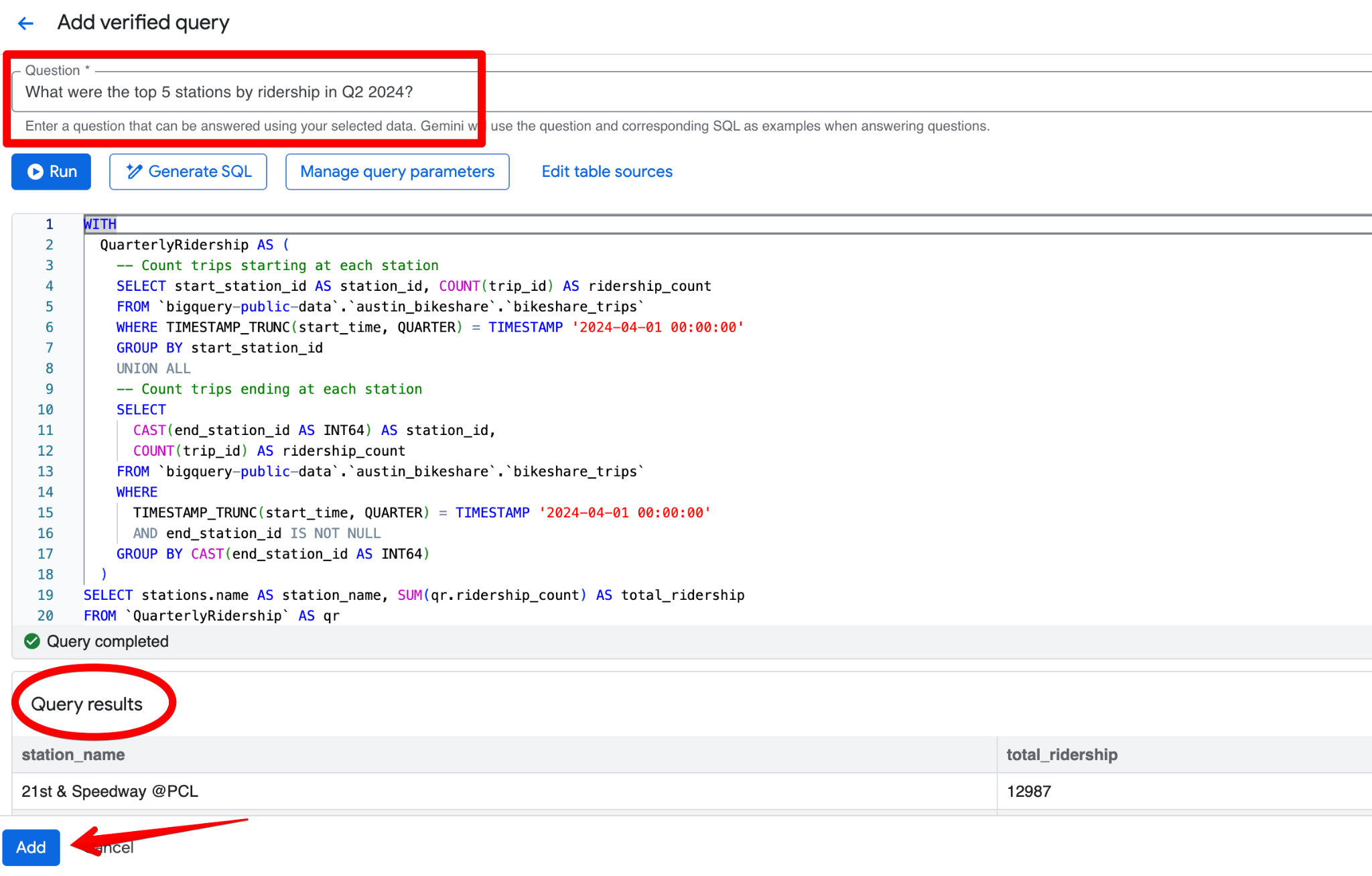
แม้ Agent ให้คำตอบที่สมเหตุสมผลตั้งแต่ครั้งแรก คุณยังสามารถทำให้แม่นยำและสอดคล้องขึ้นได้มากโดยทบทวน SQL ที่สร้างและเพิ่ม Verified Queries
ทำตามเวิร์กโฟลว์นี้:
สมมติว่าคุณถามว่า “ระยะเวลาทริปเฉลี่ยในมิถุนายน 2024 คือเท่าไร?” คำตอบแรก Agent คืนค่า 26.68 นาที และตัดทริปสั้นกว่า 1 นาทีอย่างถูกต้อง แต่กฎธุรกิจมาตรฐานของทีมคือให้ตัดทริปสั้นกว่า 5 นาทีแทน
เมื่อเปิด SQL ที่สร้าง (ผ่าน Open in Editor) จะเห็นตัวกรองเป็นเพียง duration_minutes >= 1
คลิก Add query ในส่วน Verified Queries แล้วสร้างรายการนี้:
Question:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes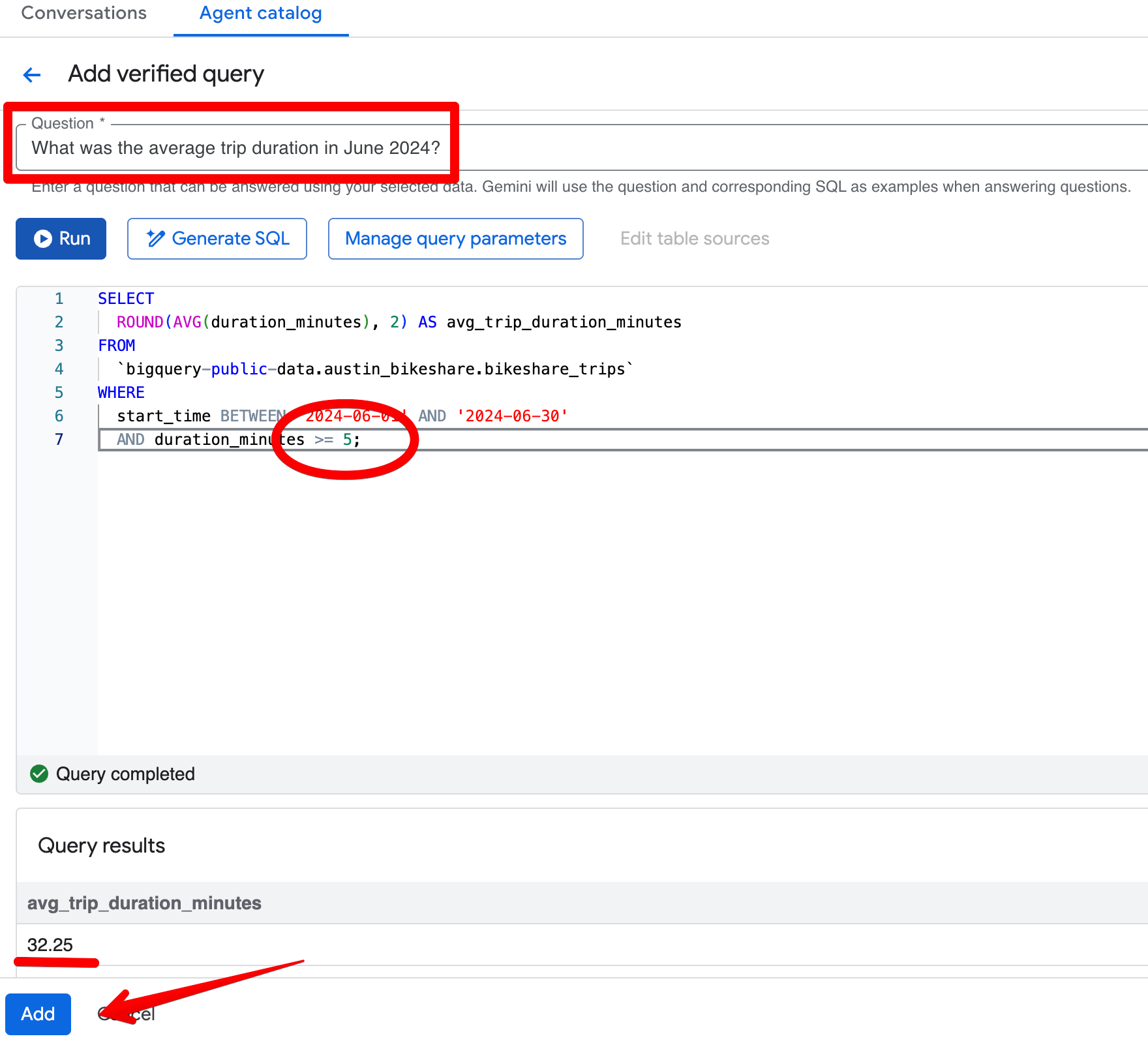
หลังบันทึก Verified Query ให้ถามคำถามเดิมในพรีวิวอีกครั้ง Agent จะคืนค่าประมาณ ~32.08 นาทีอย่างสม่ำเสมอและใช้เกณฑ์ 5 นาทีที่เข้มงวดขึ้น ผลลัพธ์จึงสอดคล้องกับมุมมองธุรกิจของคุณว่าทริป “ที่มีนัยสำคัญ” คืออะไร
Conversational Analytics ของ BigQuery โดดเด่นกว่าเครื่องมือข้อความเป็น SQL ทั่วไปด้วยการรองรับฟังก์ชัน BigQuery ML ดาต้าที่ไม่เป็นโครงสร้าง และการแชร์ได้ง่ายทั่วระบบนิเวศ Google Cloud
หนึ่งในความแตกต่างสำคัญคือความสามารถของ Agent ในการเรียกใช้ฟังก์ชัน BigQuery ML โดยตรงจากภาษาธรรมชาติ เพื่อก้าวข้ามรายงานย้อนหลังไปสู่ข้อมูลเชิงคาดการณ์
เช่น คุณสามารถขอให้ Data Agent พยากรณ์จำนวนทริปรายวันใน 30 วันถัดไปโดยอิงจากแนวโน้มปี 2024 โดยจะเรียกใช้ AI.FORECAST และสร้างพยากรณ์สำหรับเดือนกรกฎาคม 2024 พร้อมแผนภูมิที่แสดงทริปรายวันในอดีต (เส้นสีน้ำเงิน) และพยากรณ์ 30 วัน (เส้นสีส้ม) พร้อมช่วงความเชื่อมั่น 95% แบบแรเงา
อีกแนวทางหนึ่งที่อัลกอริทึมการเรียนรู้ของเครื่องมีประโยชน์คือการตรวจจับความผิดปกติของข้อมูล ตัวอย่างเมื่อคุณขอให้ Agent ตรวจจับความผิดปกติของ ridership รายวันในเดือนมิถุนายน 2024 ระบบจะเรียกใช้ AI.DETECT_ANOMALIES โดยเปรียบเทียบมิถุนายน 2024 กับเดือนก่อนๆ และคืนตารางอนุกรมเวลาและไลน์ชาร์ต
ในกรณีนี้ ไม่พบความผิดปกติอย่างเป็นทางการที่ระดับความเชื่อมั่น 95% แต่ไฮไลต์วันที่ 19 มิถุนายนว่าเกือบเป็นความผิดปกติ (ความน่าจะเป็น 92.1%) โดยมีการลดลงของ ridership อย่างเห็นได้ชัด
เครื่องมือ BI แบบสนทนาส่วนใหญ่จะล้มเหลวทันทีเมื่อข้อมูลไม่อยู่ในรูปแถวและคอลัมน์ แต่ BigQuery รองรับ Object Tables ซึ่งช่วยให้วิเคราะห์ข้อมูลที่ไม่เป็นโครงสร้าง (เช่น PDF รูปภาพ และล็อกข้อความดิบ) ที่เก็บใน Google Cloud Storage ได้
ด้วยความสามารถมัลติโหมดของ Gemini ที่ขับเคลื่อน Data Agent ทำให้สามารถให้เหตุผลข้ามทั้งเมตริกเชิงโครงสร้างและไฟล์ที่ไม่เป็นโครงสร้างพร้อมกัน นี่คือข้อแตกต่างมหาศาลและเป็นเอกลักษณ์ของ BigQuery
หากมีไฟล์ PDF แบบสำรวจผู้ขับขี่หรือรูปภาพตรวจสอบสถานีอยู่ใน Object Table เพียงถามว่า “สรุปข้อร้องเรียนหลักจากไฟล์ PDF แบบสำรวจผู้ขับขี่ไตรมาส 2/2024” Agent จะอ่านไฟล์ที่ไม่เป็นโครงสร้างและผสานข้อมูลกับข้อมูลทริปเชิงโครงสร้างของคุณ
ทีมข้อมูลของคุณสร้างและทดสอบ Data Agent ใน BigQuery Studio แต่ผู้ใช้ปลายทางอาจทำงานในแอปพลิเคชันอื่นโดยสิ้นเชิง Google ทำให้ง่ายต่อการแยก Agent ออกจาก GCP Console เพื่อให้เข้าถึงผู้ใช้ธุรกิจในที่ที่พวกเขาทำงานอยู่แล้ว
หากต้องการลองสร้างแอปแชตแบบกำหนดเองด้วยตนเอง สามารถอ่านเพิ่มเติมได้ใน Introduction to Conversational Analytics in BigQuery อย่างเป็นทางการ
หากมีหลักสำคัญเพียงข้อเดียวที่ควรจดจำ คือ Conversational Analytics ย้ายคอขวดด้านการวิเคราะห์จากการรอทีมข้อมูลมาเป็นเพียงการถามคำถามที่ถูกต้อง
การเปิดโอกาสให้เข้าถึงนี้ไม่ได้ทำให้ทีมข้อมูลหมดความสำคัญ แต่บทบาทกำลังเปลี่ยนไป AI Agent จะฉลาดเท่ากับรั้วกั้นที่คุณสร้าง ความแม่นยำและความปลอดภัยของ Data Agent ขึ้นอยู่กับคำสั่ง บริบท และสถาปัตยกรรมสคีมาที่คุณจัดให้โดยสิ้นเชิง
เพื่อสร้าง Agent แบบสนทนาที่มีประสิทธิภาพที่สุด ยังจำเป็นต้องเข้าใจคลังข้อมูลพื้นฐานอย่างลึกซึ้ง หากคุณหรือทีมต้องการเสริมทักษะสำคัญเหล่านี้และเชี่ยวชาญแพลตฟอร์มที่ขับเคลื่อนฟีเจอร์ AI เหล่านี้ ลองดูคอร์ส Introduction to BigQuery ของ DataCamp วันนี้!
คอร์สของ Google Cloud
Tracks
Courses
Courses